Here we'll set up your sample application, set up the model, figure out how to handle classification requests in your application, and add our converted ResNet model to the project.
Introduction
Deep neural networks are awesome at tasks like image classification. Results that would have taken millions of dollars and an entire research team a decade ago are now easily available to anyone with a half-decent GPU. However, deep neural networks have a downside. They can be very heavy and slow, so they don’t always run well on mobile devices. Fortunately, Core ML offers a solution: it enables you to create slim models that run well on iOS devices.
In this article series, we’ll show you how to use Core ML in two ways. First, you’ll learn how to convert a pre-trained image classifier model to a Core ML and use it in an iOS app. Then, you’ll train your own Machine Learning (ML) model and use it to make a Not Hotdog app – just like the one you might have seen in HBO’s Silicon Valley.
Having converted a ResNet model to the Core ML format in the previous article, we’ll now use it in a simple iOS application.
Set Up Your Sample Application
To focus on our main task at hand - showcasing the use of the converted ResNet model - we’ll "borrow" the sample image classification app available at Apple’s developer site. When you open the downloaded app project in Xcode, a short and "to the point" description displays:
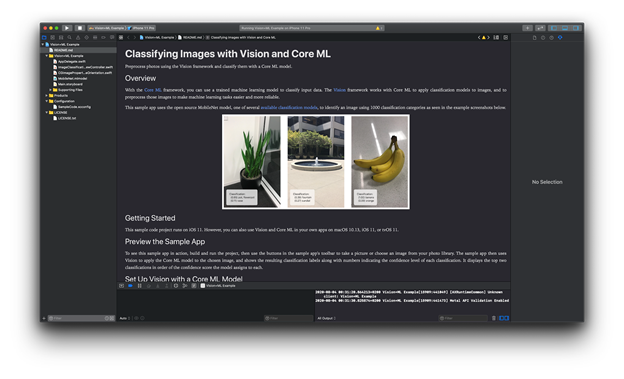
Have a look - this description may answer quite a few of your questions. To run the sample app on an iOS device, you need to go through the usual steps of setting the team and unique bundle identifier. We recommend that you run the app on a real device to be able to use the device’s camera.
The sample application has three main methods (in ImageClassificationViewController) that handle the ML processing.
Set Up the Model
Model setup and assignment to the lazily initialized classificationRequest variable:
lazy var classificationRequest: VNCoreMLRequest = {
do {
/*
Use the Swift class `MobileNet` Core ML generates from the model.
To use a different Core ML classifier model, add it to the project
and replace `MobileNet` with that model's generated Swift class.
*/
let model = try VNCoreMLModel(for: MobileNet().model)
let request = VNCoreMLRequest(model: model, completionHandler: { [weak self] request, error in
self?.processClassifications(for: request, error: error)
})
request.imageCropAndScaleOption = .centerCrop
return request
} catch {
fatalError("Failed to load Vision ML model: \(error)")
}
}()
The most important line in the above code snippet is the model assignment (let model = (…)). In many scenarios, this would be the only line to update when switching to a different model.
Note the VN prefix in the class names. It means that the classes are part of the Vision framework. This framework provides a high-level API designed to handle computer vision tasks, such as face and body detection, rectangle detection, body and hand pose detection, text detection, and many more. Apart from these high-level APIs, which internally use models created by Apple, the Vision framework also exposes an API that comes handy when using custom Core ML models for ML image analysis.
While you can use Core ML directly, having the Vision layer removes a burden of trivial tasks such as image scaling and cropping, conversion of color space and orientation, and so on.
In our sample application, a single line of code handles all of the required tasks:
request.imageCropAndScaleOption = .centerCrop
Each time the model classification is completed, the processClassifications method is called to update the UI accordingly.
Handle Classification Request in Your Application
The next method, updateClassifications, is called by other application components to initiate an image classification:
func updateClassifications(for image: UIImage) {
classificationLabel.text = "Classifying..."
let orientation = CGImagePropertyOrientation(image.imageOrientation)
guard let ciImage = CIImage(image: image) else { fatalError("Unable to create \(CIImage.self) from \(image).") }
DispatchQueue.global(qos: .userInitiated).async {
let handler = VNImageRequestHandler(ciImage: ciImage, orientation: orientation)
do {
try handler.perform([self.classificationRequest])
} catch {
/*
This handler catches general image processing errors. The `classificationRequest`'s
completion handler `processClassifications(_:error:)` catches errors specific
to processing that request.
*/
print("Failed to perform classification.\n\(error.localizedDescription)")
}
}
}
This method accepts a single parameter, image, and internally invokes the classificationRequest configured previously, in a thread-safe way.
Display Classification Results
The last of the "main" methods is responsible for updating the UI with the classification results:
func processClassifications(for request: VNRequest, error: Error?) {
DispatchQueue.main.async {
guard let results = request.results else {
self.classificationLabel.text = "Unable to classify image.\n\(error!.localizedDescription)"
return
}
// The `results` will always be `VNClassificationObservation`s, as specified by the Core ML model in this project.
let classifications = results as! [VNClassificationObservation]
if classifications.isEmpty {
self.classificationLabel.text = "Nothing recognized."
} else {
// Display top classifications ranked by confidence in the UI.
let topClassifications = classifications.prefix(2)
let descriptions = topClassifications.map { classification in
// Formats the classification for display; e.g. "(0.37) cliff, drop, drop-off".
return String(format: " (%.2f) %@", classification.confidence, classification.identifier)
}
self.classificationLabel.text = "Classification:\n" + descriptions.joined(separator: "\n")
}
}
}
This method displays the top two predicted labels with the highest model confidence (let topClassifications = classifications.prefix(2)).
The remaining methods handle the camera and the captured pictures. They are not specific to ML.
Inspec MobileNet Model
If you click the MobileNet.mlmodel file in the explorer, you can examine the model details:

Apart from the Inputs and Outputs definition, a fair amount of metadata is presented there: authors, detailed description, and the license.
Add the Model to the Application
Now it is time to add our converted ResNet model to the project. The simplest way to do this is to drag it from the Finder and drop it in the Xcode’s explorer. Remember that this only links the model to the application; the model is not physically copied to the project folder. If you want to keep the new model with the rest of the application, you need to copy it there manually before linking it.
After this step, you can take a look at the ResNet model description:
In our case, only name, type, size, inputs, and outputs are specified. If you think about distributing the model, you should consider filling these fields with meaningful information. This can be done using the coremltools Python library.
Run Your App With the Converted ResNet Model
To use the converted model you have dragged and dropped into the Xcode project, we need to change a single line of code in the ImageClassificationViewController.swift file:
Because during the conversion we selected "13" as the minimum iOS version, you need to change the target platform settings accordingly:
After making the above change, you can use the ResNet model to run predictions right away:
One difference between the MobileNet and ResNet models is clearly visible: MobileNet returns labels with confidence probabilities (thanks to the softmax layer) while ResNet returns "raw," unscaled neural network output. If needed, this could be fixed either by adding a custom layer to the ResNet model or by calculating softmax on the returned results within the app.
Summary
We now have a sample application working smoothly with our converted ResNet image classification model. It proves that iOS 13 devices are capable of successfully running not only reduced "mobile" ML models, but also the original (large) ones.
Looks like we can use any image classification model (including the converted ones) in iOS apps. To reach the goal of this series, all we need now is a model that can detect hot dogs. Both MobileNet and ResNet models are already capable of detecting hot dogs, but the interesting task here is understanding how they can do it. In the next article, we’ll start data preparation for this new, custom model, to be later trained using the Create ML framework.

