This article demonstrates the implementation of a database layer, and how the C++ wrapper classes can be used to implement a layered design, separating the internal details of working with multiple related tables and the rest of the application. This is an example that can be used to implement a multi-threaded server, where each thread works with its own ESE session.
Related articles:
Introduction
In this, my second article about my C++ wrapper library for the Windows ESE C API, we will go through the design of a database layer for an application using ESE as storage.
The library was designed to facilitate modularity but does not attempt to force you into a particular pattern. Ese::Table and Ese::Database can be used just fine in the way I described in my previous article, but, on the other hand, it would be nice to be able to derive a database from Ese::Database, and the various tables from Ese::Table.
For this example, we will use ESE to store a recursive structure of catalogs, where each catalog can contain sub-catalogs and assets. An asset can have several sensors connected to it, and for each sensor we want to store a timeseries of sensor values:
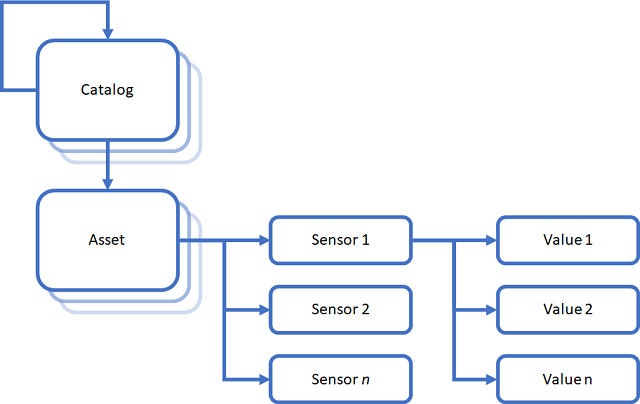
To implement this, we use the following set of enums, structs and classes – indentation indicates inheritance:
Engine: Class for holding the Ese::Instance and managing Session objectsSession: Holds an Ese::Session and provides the interface to the operations that can be performed on the databaseDatabase: Derived from Ese::DatabaseNamed: Simple struct with two fields – Guid Id and std::string Name
- Owned: Adds a field –
Guid Owner
SensorCatalogItemBase: Adds a field – CatalogItemType Type
CatalogItem: std::variant<Catalog, Asset>CatalogItemType: enum with the values Unknown, Catalog and AssetOwnedTable<T>: template class derived from Ese::Table
SensorTable: Table used to store data for Sensor objectsCatalogItemTable: Table used to store data for Catalog and Asset objects
SensorValue: struct with four fields – Guid Sensor, DateTime Timestamp, Int64 Flags and Double ValueSensorPoint: struct with three fields – DateTime Timestamp, Int64 Flags and Double ValueSensorValueTable: Table used to store data for SensorValue objects
There are also some additional requirements:
- The
Owner field of a CatalogItem must either be an empty Guid or a Guid identifying a Catalog, setting up a recursive structure where a Catalog can contain Asset objects and other Catalog objects. - The
Owner field of a Sensor must identify an Asset. - A
Name should always be unique among objects sharing the same owner.
Engine
The primary purpose of engine is to hold the Ese::Instance for the application, and to manage its sessions:

The engine is initialized using a reference to an EngineOptions object:
struct EngineOptions
{
std::string Database;
std::string SystemPath;
std::string LogFilePath;
bool Create = false;
bool Replace = false;
bool Unsafe = false;
bool RunTests = false;
};
The ParseOptions(…) is implemented in HExOptionParser.h and uses boost::program_options to parse the command line arguments and initialize the EngineOptions object. The function can easily be extended to support more elaborate configuration, The Engine class processes the options during construction:
class Engine
{
...
public:
Engine( const EngineOptions& options, const char* instanceName )
: options_( options ), instance_( instanceName )
{
ProcessOptions( );
}
private:
...
void ProcessOptions( )
{
instance_.SetCreatePathIfNotExist( );
instance_.SetExceptionAction( Ese::ExceptionAction::None );
instance_.SetSystemPath( options_.SystemPath );
instance_.SetLogFilePath( options_.LogFilePath );
instance_.SetMaxVersionPageCount( 262144 );
if ( options_.Create )
{
auto session = std::make_unique<Session>( *this, 1, true );
sessions_.emplace( 1, std::move( session ) );
}
}
...
};
We use the CreateSession( ) function of the Engine class to create session objects. If this is the first call to CreateSession( ), the function checks if the session used to create the database is available. Subsequent calls will always create a new session object:
Session* CreateSession( )
{
std::lock_guard lockGuard( criticalSection_ );
if ( sessions_.size( ) == 1 && sessionCounter_ == 0 )
{
++sessionCounter_;
auto result = sessions_[1].get();
return result;
}
else
{
auto id = ++sessionCounter_;
auto session = std::make_unique<Session>( *this, id, false );
auto result = session.get( );
sessions_.emplace( id, std::move( session ) );
return result;
}
}
Implementing the main(…) function is now trivial:
int main( int argc, char* argv[] )
{
try
{
EngineOptions options;
if ( ParseOptions( argc, argv, options ) )
{
Engine engine( options, "TestInstance" );
auto session = engine.CreateSession( );
if ( options.RunTests )
{
RunTests( *session );
}
session->Close( );
}
}
catch ( std::exception& exc )
{
std::string message = exc.what( );
printf( "Exception: %s", message.c_str( ) );
}
return 0;
}
Session
The Session class provides the interface between the database specific code and the rest of the application, shielding the intricacies of working with the ESE database from the rest of the application:
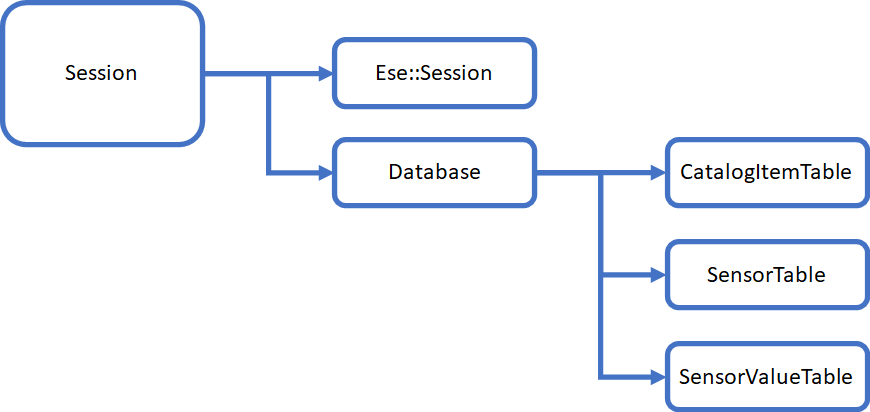
The Session class has only a few member variables:
class Session
{
Engine& engine_;
Int64 id_;
Ese::Session eseSession_;
Database eseDatabase_;
public:
Session( Engine& engine, Int64 id, bool createDatabase );
...
}
Where engine_ holds a reference to the Engine that owns it, providing access to the EngineOptions that is relevant for the Session instance too. id_ is an integer, generated by the Engine class, that uniquely identifies the session, which is often useful when designing client/server solutions, and eseSession_ holds an Ese::Session object created by Ese::Instance::BeginSession().
Database
With this in place, we can go into the details of the Database class:
class Database : public Ese::Database
{
...
private:
CatalogItemTable catalogItemTable_;
SensorTable sensorTable_;
SensorValueTable sensorValueTable_;
public:
...
}
The Database class is derived from Ese::Database, and has three member variables, one for each table that will be used by this example.
The constructor for Session is implemented like this:
inline Session::Session( Engine& engine, Int64 id, bool createDatabase )
: engine_( engine ), id_( id )
{
auto& instance = engine_.Instance( );
auto& options = engine_.Options( );
eseSession_ = instance.BeginSession( );
if ( createDatabase )
{
Ese::CreateDatabaseFlags createDatabaseFlags = Ese::CreateDatabaseFlags::None;
if ( options.Replace )
{
createDatabaseFlags |= Ese::CreateDatabaseFlags::OverwriteExisting;
}
if ( options.Unsafe )
{
createDatabaseFlags |= Ese::CreateDatabaseFlags::RecoveryOff |
Ese::CreateDatabaseFlags::ShadowingOff;
}
eseDatabase_ = eseSession_.CreateDatabase<Database>( options.Database,
createDatabaseFlags );
}
else
{
eseSession_.AttachDatabase( options.Database );
eseDatabase_ = eseSession_.OpenDatabase<Database>( options.Database );
}
}
where the third parameter to the Session constructor tells it to either create a new database or open an existing one.
Calling Ese::Session::CreateDatabase(…) like this:
eseDatabase_ = eseSession_.CreateDatabase<Database>( options.Database, createDatabaseFlags );
will cause the implementation of the CreateDatabase<T>(…) template function to call our implementation of Database::OnDatabaseCreated( ):
void OnDatabaseCreated( )
{
BeginTransaction( );
catalogItemTable_ = CreateTable<CatalogItemTable>( CatalogItemTable::TableName );
sensorTable_ = CreateTable<SensorTable>( SensorTable::TableName );
sensorValueTable_ = CreateTable<SensorValueTable>( SensorValueTable::TableName );
CommitTransaction( );
}
Where each call to CreateTable<T>(...) will cause the template function to call the T::OnTableCreated() on the new instance of T right after creating it.
void OnTableCreated( )
{
Base::OnTableCreated( );
idColumnId_ = AddGuid( IdColumnName );
ownerColumnId_ = AddGuid( OwnerColumnName );
nameColumnId_ = AddText( NameColumnName );
CreateIndex( DerivedT::PrimaryIndexName, Ese::IndexFlags::Primary, "+Id\0", 5 );
CreateIndex( DerivedT::OwnerAndNameIndexName,
Ese::IndexFlags::Unique,
"+Owner\0+Name\0", 14 );
SetCurrentIndex( DerivedT::PrimaryIndexName );
}
Allowing us to add the columns and create the indexes for the table as shown above. Here, the second call to the CreateIndex(…) function ensures that ESE will handle the requirement that: “A Name should always be unique among objects sharing the same owner.”
Similarly,
eseDatabase_ = eseSession_.OpenDatabase<Database>( options.Database );
will cause the implementation of the OpenDatabase<T>(...) template function to call the T::OnDatabaseOpened() function on the new instance of T right after creating it.
void OnDatabaseOpened( )
{
catalogItemTable_ = OpenTable<CatalogItemTable>( CatalogItemTable::TableName,
Ese::OpenTableFlags::Updatable );
sensorTable_ = OpenTable<SensorTable>( SensorTable::TableName,
Ese::OpenTableFlags::Updatable );
sensorValueTable_ = OpenTable<SensorValueTable>( SensorValueTable::TableName,
Ese::OpenTableFlags::Updatable );
}
Where each call to OpenTable<T>(…) will cause the template function to call the T::OnTableOpened() on the new instance of T right after creating it.
void OnTableOpened( )
{
Base::OnTableOpened( );
idColumnId_ = GetColumnId( IdColumnName );
ownerColumnId_ = GetColumnId( OwnerColumnName );
nameColumnId_ = GetColumnId( NameColumnName );
SetCurrentIndex( DerivedT::PrimaryIndexName );
}
Allowing us to initialize the column ids and set the current index.
This pattern makes it easy to integrate our own Table and Database types with the library.
Session and Table Design
When working with ESE, and most other NoSQL database engines, we must take care of many of the “business-rules” in code. We can, as we did above, use an index to handle “A Name should always be unique among objects sharing the same owner.”, while “The Owner field of a CatalogItem must either be an empty Guid or a Guid identifying a Catalog” must be handled in code:
Catalog CreateOrRetrieveCatalog( const Guid& owningCatalogId, const std::string& name )
{
if ( owningCatalogId.empty( ) == false && CatalogExists( owningCatalogId ) == false )
{
throw std::exception( "Invalid catalog id" );
}
auto& catalogItems = CatalogItems( );
return catalogItems.CreateOrRetrieveCatalog( owningCatalogId, name );
}
Not particularly difficult but adds to the importance of working through a well defined interface that is responsible for ensuring that those rules are handled correctly.
The application uses a simple set of structs for the datatypes for catalogs, assets and sensors:
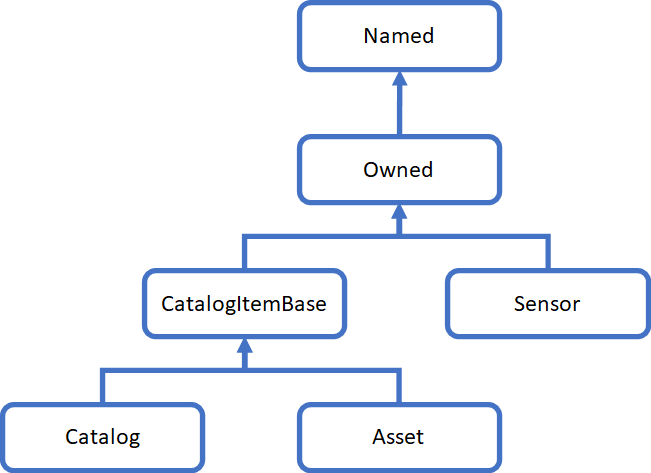
Given this inheritance hierarchy, it seems worthwhile to explore our options for code reuse.
For this example, we end up deciding that we will have one table for catalog and asset objects, and one table for sensor objects. Now, it would be awfully nice if those two tables could reuse a common implementation provided by a base class, giving us this inheritance diagram for the tables:
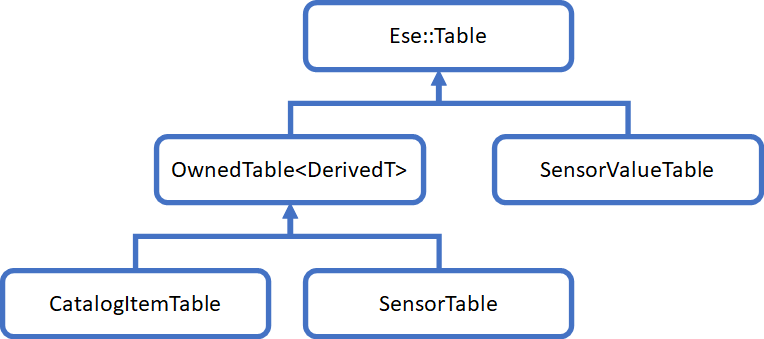
OwnedTable
The template class OwnedTable implements the functionality required to support the Id, Owner, and Name columns, and the implementations of OnTableCreated( ) and OnTableOpened( ) shown earlier are members of this template.
OwnedTable implements a set of functions allowing us to read and write column values:
Guid Id( ) const
{
Guid result;
Read( idColumnId_, result );
return result;
}
void SetId( const Guid& id ) const
{
SetColumn( idColumnId_, id );
}
Where the implementations for the Owner and Name columns are implemented similarly.
This implementation of the MoveTo(…) function allows us to find rows by Owner and Name:
bool MoveTo( const Guid& ownerId, const char* name ) const
{
SetCurrentIndex( DerivedT::OwnerAndNameIndexName );
MakeKey( ownerId, Ese::KeyFlags::NewKey );
MakeKey( name );
auto rc = Seek( Ese::SeekFlags::Equal );
return rc >= Ese::Result::Success;
}
While the index ensures that any combination of the Owner and Name columns stored in the database uniquely identifies a row in the table, we still need to set DerivedT::OwnerAndNameIndexName as the current index, as this affects how MakeKey(...) maps the search key to the columns of the table.
By passing Ese::SeekFlags::Equal to Seek(…), we tell ESE that we want an exact match for our search criteria.
The template uses the curiously recurring template pattern to retrieve the name of the index from the derived class, allowing the derived classes to specify an appropriate name.
To support search by the primary key for the table, we implement:
bool MoveTo( const Guid& id ) const
{
MakeKey( id, Ese::KeyFlags::NewKey );
auto rc = Seek( Ese::SeekFlags::Equal );
return rc >= Ese::Result::Success;
}
Which is similar to the first MoveTo(…) overload, but here we expect the primary index to be the current index when constructing the search key and calling Seek(…).
We also want to be able to select all rows that have the same Owner:
bool FilterByOwner( const Guid& ownerId ) const
{
SetCurrentIndex( DerivedT::OwnerAndNameIndexName );
MakeKey( ownerId, Ese::KeyFlags::NewKey );
MakeKey( "" );
auto rc = Seek( Ese::SeekFlags::GreaterOrEqual );
if ( rc >= Ese::Result::Success && Owner() == ownerId )
{
MakeKey( ownerId, Ese::KeyFlags::NewKey | Ese::KeyFlags::FullColumnEndLimit );
SetIndexRange( Ese::IndexRengeFlags::Inclusive | Ese::IndexRengeFlags::UpperLimit );
return true;
}
return false;
}
The last call to MakeKey(…) sets up a wildcard filter. Ese::KeyFlags::FullColumnEndLimit specifies that the search key should be created in so that any key columns that come after the current key column are treated as wildcards. This means that the search key can be used to match index entries that have the following:
- The exact values provided for this key column and all previous key columns of the index
- Any values for subsequent key columns of the index
This option should be used when creating wildcard search keys used to find the index entries closest to the end of an index. The end of the index is the index entry that is found when moving to the last row in that index.
This is used by the implementation of the SensorTable to implement:
void GetSensors(const Guid& assetId, std::vector<Sensor>& sensors ) const
{
sensors.clear( );
if ( FilterByOwner( assetId ) )
{
do
{
Read( sensors.emplace_back( ) );
} while ( MoveNext( ) );
}
}
The GetSensor(…) function retrieves all the sensors attached to an asset, and it was now trivial to implement.
Deleting Catalogs and Assets
There is one thing that tends to get complicated when working with a database engine such as ESE and that is deleting data. When we delete a catalog, we must also make sure everything else gets cleaned up:
- Values must be deleted from the
SensorValueTable - Sensors must be deleted from the
SensorTable - Assets belonging either directly or indirectly to the catalog must be deleted
- Sub-catalogs must be deleted
While not particularly difficult to implement, the trick is to remember that this will not happen automagically through a cascaded delete, but must be handled in code:
bool DeleteCatalogItem( const Guid& itemId ) const
{
auto& catalogItems = CatalogItems( );
auto& sensors = Sensors( );
auto& values = Values( );
if ( catalogItems.MoveTo( itemId ) )
{
auto itemType = catalogItems.ItemType( );
switch ( itemType )
{
case CatalogItemType::Catalog:
{
while ( catalogItems.MoveToFirstChild( itemId ) )
{
auto childId = catalogItems.Id( );
DeleteCatalogItem( childId );
}
catalogItems.SetCurrentIndex( CatalogItemTable::PrimaryIndexName );
if ( catalogItems.MoveTo( itemId ) )
{
catalogItems.Delete( );
}
return true;
}
break;
case CatalogItemType::Asset:
{
if ( sensors.FilterByOwner( itemId ) )
{
do
{
auto sensorId = sensors.Id( );
values.Delete( sensorId );
sensors.Delete( );
} while ( sensors.MoveNext() );
}
catalogItems.SetCurrentIndex( CatalogItemTable::PrimaryIndexName );
catalogItems.Delete( );
return true;
}
break;
}
}
return false;
}
Switching indexes has a price when it comes to performance, so care should be taken to limit the number of times this is done. The data-layer tries to switch back from the secondary indexes, to the primary index, whenever it has completed operations that rely on the secondary indexes. This way, the operations that rely on the primary indexes do not have to set the index.
Looking Up Sensor Values
The SensorValueTable has four columns, matching the four fields of the SensorValue struct:
struct SensorValue
{
Guid Sensor;
DateTime Timestamp;
Int64 Flags = 0;
Double Value = 0.0;
};
When searching for the current value for a particular point in time, we want the row that matches that point in time exactly, or we want the row with the maximum timestamp less than the point in time we request a row for. This is way easier to implement with ESE than it would be for an SQL based database:
bool MoveTo( const Guid& sensorId,
const DateTime& timestamp,
bool exactMatchRequired = true ) const
{
MakeKey( sensorId, Ese::KeyFlags::NewKey );
MakeKey( timestamp );
auto rc = Seek( exactMatchRequired? Ese::SeekFlags::Equal : Ese::SeekFlags::LessOrEqual );
return rc >= Ese::Result::Success;
}
When passing false for the third parameter, we get the functionality described above, while using the default allows us to implement:
bool Write(const Guid& sensorId, const SensorPoint& point ) const
{
if ( MoveTo( sensorId, point.Timestamp ) )
{
ReplaceValue( point );
return false;
}
else
{
InsertValue( sensorId, point );
return true;
}
}
in a way that ensures that an exact match for an existing timestamp will result in a replace, otherwise the function will insert a new row into the table.
There is also a Filter function that allows us to find the values for an interval:
bool Filter( const Guid& sensorId,
const DateTime& startTimestamp,
const DateTime& endTimestamp ) const
{
MakeKey( sensorId, Ese::KeyFlags::NewKey );
MakeKey( startTimestamp );
auto rc = Seek( Ese::SeekFlags::LessOrEqual );
if ( rc >= Ese::Result::Success )
{
MakeKey( sensorId, Ese::KeyFlags::NewKey );
MakeKey( endTimestamp );
SetIndexRange( Ese::IndexRengeFlags::UpperLimit );
return true;
}
else
{
return false;
}
}
With this in place, it is easy to implement the relevant functions required to retrieve the timeseries data:
void GetSensorPoints( const Guid& sensorId, std::vector<SensorPoint>& sensorPoints ) const
{
sensorPoints.clear( );
if ( Filter( sensorId ) )
{
do
{
Read( sensorPoints.emplace_back() );
} while ( MoveNext( ) );
}
}
void GetSensorPoints( const Guid& sensorId,
const DateTime& startTimestamp,
const DateTime& endTimestamp,
std::vector<SensorPoint>& sensorPoints ) const
{
sensorPoints.clear( );
if ( Filter( sensorId, startTimestamp, endTimestamp ) )
{
do
{
Read( sensorPoints.emplace_back( ) );
} while ( MoveNext( ) );
}
}
void GetSensorPoints( const Guid& sensorId,
const DateTime& startTimestamp,
std::vector<SensorPoint>& sensorPoints ) const
{
GetSensorPoints( sensorId, startTimestamp, DateTime::MaxValue( ), sensorPoints );
}
Implementing the function to insert or update a set of values is also equally trivial:
void Write( const Guid& sensorId, const std::vector<SensorPoint>& sensorPoints ) const
{
for ( const auto& sensorPoint : sensorPoints )
{
Write( sensorId, sensorPoint );
}
}
Using the data-layer
Using the Session class to perform operations is about as easy as it gets, the BuildStructure(…) function below creates a simple hierarchy of catalogs, assets and sensors:
size_t BuildStructure( Session& session,
size_t numberOfCatalogs,
size_t numberOfAssetsPerCatalog,
size_t numberOfSensorsPerAsset )
{
Guid empty;
size_t result = 0;
auto transaction = session.StartTransaction( );
for ( size_t i = 0; i < numberOfCatalogs; i++ )
{
auto catalogName = GetCatalogName( i + 1 );
auto catalog = session.CreateOrRetrieveCatalog( empty, catalogName );
result++;
for ( size_t j = 0; j < numberOfAssetsPerCatalog; j++ )
{
auto assetName = GetAssetName( j + 1 );
auto asset = session.CreateOrRetrieveAsset( catalog.Id, assetName );
result++;
for ( size_t k = 0; k < numberOfSensorsPerAsset; k++ )
{
auto sensorName = GetSensorName( k + 1 );
Sensor sensor = session.CreateOrRetrieveSensor( asset.Id, sensorName );
result++;
}
}
}
transaction.Commit( );
return result;
}
Unless we call Commit() on the transaction object, it will roll back any changes made to the database since the call to StartTransaction(). This way, any exception will cause the entire transaction to be rolled back.
Retrieving the catalog, asset, and sensor data created by BuildStructure(...):
size_t ReadStructure( Session& session, std::vector<CatalogData>& result )
{
size_t count = 0;
Guid root;
std::vector<CatalogItem> catalogItems;
session.GetCatalogItems( root, catalogItems );
count += catalogItems.size( );
for ( auto& catalogItem : catalogItems )
{
auto& catalog = std::get<Catalog>( catalogItem );
CatalogData& catalogData = result.emplace_back();
catalogData.Assign(catalog);
std::vector<CatalogItem> assets;
session.GetCatalogItems( catalogData.Id, assets );
count += assets.size( );
for ( auto& assetItem : assets )
{
auto& asset = std::get<Asset>( assetItem );
AssetData& assetData = catalogData.Assets.emplace_back();
assetData.Assign( asset );
session.GetSensors( assetData.Id, assetData.Sensors );
count += assetData.Sensors.size( );
}
}
return count;
}
Retrieving sensor values for an interval:
size_t ReadSensorDataForInterval( Session& session, std::vector<Sensor>& sensors )
{
DateTime start( 2020, 1, 10 );
DateTime end( 2020, 1, 25 );
size_t result = 0;
std::vector<SensorPoint> points;
points.reserve( 25000 );
for ( auto& sensor : sensors )
{
session.GetSensorPoints( sensor.Id, start, end, points );
result += points.size( );
}
return result;
}
Testing the data-layer
To conclude this article, here is a short description of how the database layer is used by the implementation of RunTests(…). For debug builds RunTests(…) generates a limited dataset compared to the one created for release builds, and release builds does not test the delete functionality as that takes way too much time to complete for the large dataset.
Release builds of RunTests(…) calls the following functions:
BuildStructure: Creates 10 catalogs, 10 assets per catalog and 10 sensors per asset.ReadStructure: Reads the full structure into memory by retrieving all the catalogs, then retrieve the assets for each catalog, and finally retrieve the sensors for each asset.ReadSensors: Reads all the sensors into memory.GenerateSensorData: Iterates over all the sensors and writes one-month worth of data with a resolution of one minute for release builds, and one day for debug builds, to the database.GetCatalogItemCount: Iterates over all the rows in the CatalogItemTable and returns the count.GetSensorCount: Iterates over all the rows in the SensorTable and returns the count.GetSensorValueCount: Iterates over all the rows in the SensorValueTable and returns the count.ReadAllSensorData: Iterates over all the sensors and reads all the values for a sensor into memory.ReadSensorDataForInterval: Iterates over all the sensors and reads the values for the interval starting at the 10th of the month, until the 25th of the month, for a sensor into memory.ReadSensorDataForIntervalWithCheck: Same as the previous one and verifies that the data is within the requested interval, and in order.
For debug builds, it also calls:
DeleteCatalog: Deletes one catalog, which should also delete the assets belonging to the catalog, the sensors belonging to each of the assets, and all the sensor values for the sensors.- Then, to allow us to see that
DeleteCatalog performed the expected operations, RunTests(…) calls:
GetCatalogItemCountGetSensorCountGetSensorValueCount
This demonstrated how the library can be used to implement the database layer for a “real” application, creating, searching, and retrieving, updating; and deleting rows in the database.
History
- 2nd September, 2020 - Initial posting
- 6th October, 2020 - Bug fixes, cleaned up most of the unit tests
- 7th October, 2020 - More unit tests for the
Harlinn.Common.Core library

