Behavior Driven Development is an extended approach of Traditional Test-Driven Development and an add-on to automated software testing. This article sheds light on the internal insights of BDD and Cucumber-JVM in particular.
Bit of a Theory
Keeping aside the fancy terms for end-to-end test writing such as reusability, maintainability, and scalability, I always prefer to have a simple definition for writing them. That is, test cases should be written and arranged in a way that they can run any number of times, in any sequence, and with a variety of different datasets. However, it is not as simple as it sounds. This kind of test writing approach demands different teams to collaborate to discuss product behavior from the very first day. Therefore, Behavior Driven Development is based on a fair collaboration among three amigos (Business Analysts, Developer, and Tester) to its entirety.
Intriguingly, the primary reason for the popularity of BDD testing is its non-technical, clear, and concise, plain English [or any other international language of your choice [1]] language. This way, a business owner can play a significant yet prompt role by specifying the requirement in a language which is understood not just by different teams (developers and testers) but also by the testing framework as well.
In our case of Cucumber-JVM, the commonly understandable language is Gherkin, which shapes the overall concept. Gherkin is a language with no technical barriers; it forces an entire team to write unambiguous requirement-based test specifications based on creative collaboration rather technical specifics. Therefore, BDD embraces the idea of making things go straight by making requirements clearer and direct from stakeholders to the tester.
$ cucumber --i18n help
Reference
Prerequisite
As stated initially, this article intends to exemplify the implementation of the BDD testing approach in a Java environment using Cucumber with an in-depth focus of its language Gherkin. Therefore, readers should have an intermediate knowledge of Java, including basic OOP concepts, understanding of a build tool (Maven or Gradle). Moreover, managing dependencies and usage of FileInputStream for reading out the values from properties will also be required.
Disclaimer
In case you do not fulfill these prerequisites, have some courage to do some reverse engineering to understand the written code and build some understanding on top of the ground, which is provided in this article from the Git repository.
Practical Insights
Before we dive into the practical insights by examining various examples using Gherkin Syntax and Cucumber-JVM Structure, allow me to talk to briefly showcase the high-level view of the project, which we will build by following along this article.
Though the project structure in Figure 1 is quite self explanatory, I will spend a few minutes to describe it anyway. To start with, there must be two major folders – main and test. main contains all the automation framework related code, which should be modular and scalable depending upon the application dynamics, which is under test. In contrast, the test folder is only for the test cases and their metadata.
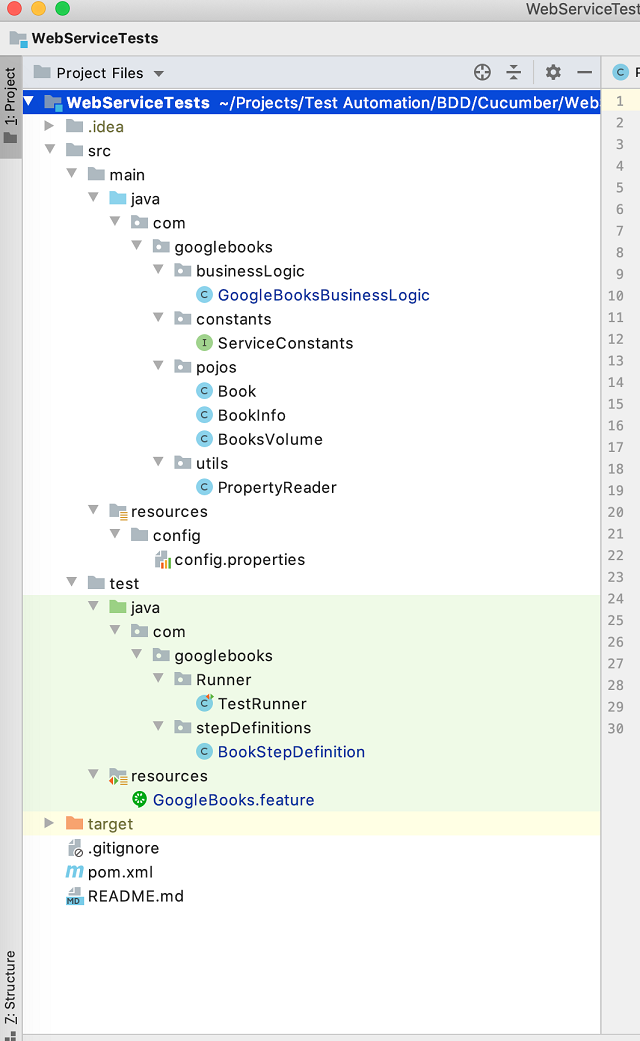
Syntactical Overview – Writing Tests in Gherkin
The .feature file in the test/resources folder is for the test specification, and it is recommended to have one file per feature for the sake of modularity and readability. As the main idea of writing test specifications in Gherkin is to make the overall testing understandable for all the members (especially for the ones without much tech knowledge); therefore, it has three prime syntax elements without which a test would not be marked as completed. These are, Given, When, Then. Nevertheless, the whole test case has to have a Scenario or Scenario Outline [2] at the top of the test script, defining the main goal or task of the entire script. Also, Gherkin supports one or more And statements in a test script. This way, more or less, the primary keywords of Gherkin are listed here.
- Feature
- Scenario and Scenario Outline
- Background
- Given, When, Then, And, But
- Example and Examples
I will leave the study and theoretical understanding to you, as the official document is quite helpful in this matter.
Scenario Vs. Scenario Outline
A Scenario is the high-level, one-liner definition of the executable test specification. It has steps which are Given, When, Then. However, if we have to run the same test case for multiple examples then our Scenario would have to repeat itself with the hard-coded values, which cannot be preferable in general.
Alternatively, a Scenario Outline can be used to repeat the same scenario with multiple data examples. Therefore, a Scenario Outline can better understand as ‘parametrized methods.’
Take the following example from its official documentation:
Example 1

Clearly, Example1 is not a good example because redundancy is never preferable specially when it is playing only with the hard-code values.
Example 2
In example2, things seem explanatory and logical.
Google Books Web Service
In this section, we will be looking into the code snippets which are taken from the demo project which I have created for this article. Now we will discuss the code which is written to test the functionality of a sample Web Service – Google Books.
Writing the Executable Specification
Please note that I will explain only one end-to-end Example of a test case. The rest will be on you to understand by going through the git repository of this project.
// src/test/resources/GoogleBooks.feature
Feature: Google Book Searching from https://www.googleapis.com/books/v1/volumes?q={ID}
Scenario Outline: Verify that the response status code is 200 and content type is JSON.
Given webService endpoint is up
When user sends a get request to webService endpoint using following details
| ID | <ID> |
Then verify <statusCode> and <contentType> from webService endpoint response
Examples:
| ID | statusCode | contentType |
| 1 | 200 | "application/json; charset=UTF-8" |
| 9546 | 200 | "application/json; charset=UTF-8" |
| 9 | 200 | "application/json; charset=UTF-8" |
Firstly, you will create the feature file (in the test/resources folder) for every intended feature to be tested and give it a description by using the Feature keyword. Note that we can have multiple Scenarios (or Scenarios Outlines) under a Feature keyword, which would, of course, be functionally relatable with each other.
Take a Scenario (or Scenarios Outline) as a parent code block – it has all the next statements inside its scope, so we call them steps.
Next, we have Given, When, Then, along with more than one data example. The Given keyword is ensuring that the given web service endpoint is up; this is the provided state from onwards we have to test some functionality.
Then we have a When statement, which is to test a specific user action – that is, sending get a request to the base URL of Web Service with a unique request ID. As the requested ID is unique and every page request will have different IDs, we will make it a parameter so that we can pass multiple IDs and run the underlined example scenario multiple times for each given ID.
Finally, we have a Then statement along with the Examples table. This ensures the intended behavior, which is expected once the user action specified in the When block is performed. Of course, the <statusCode> and <contentType> are the expected behavior we want to verify that is why we have passed them as parameters and defined in the Examples section. To know more about the working of Example Mapping, go through this official read.
Writing the Respective Step Definition File
Once we write executable specification (that is a test script written in Gherkin in simple words), we have to write its step definition file (that is Java code with public methods for every step written under the Scenario (or the Scenario Outline) in the feature file). Yeah, you get it right. This means you will have a separate step definition file per every feature file. In alternative and simpler words, the step definition file is a Java Class with dedicated functions for every Given, When, Then statement written in the feature file.
@Given("webService endpoint is up")
public void webserviceEndpointIsUp() {
requestSpecification = new RequestSpecBuilder().
setBaseUri(prop.getProperty(BASE_URL)).
build();
}
@When("user sends a get request to webService endpoint using following details")
public void userSendsAGetRequestToWebServiceEndpointUsingID(Map<String, String> data) {
String ID = data.get("ID");
System.out.println("The current ID is: " + ID);
String pathParameters = "?q" + "=" + ID;
response = given().
spec(requestSpecification).
when().
get(pathParameters);
booksVolumePojo = GoogleBooksBusinessLogic.getBooksVolumeResponseObject(response);
}
@Then("verify {int} and {string} from webService endpoint response")
public void verifyResponseStatusCodeAndContentTypeFromWebServiceEndpointResponse
(int statusCode, String contentType) {
Assert.assertEquals(statusCode, response.getStatusCode());
Assert.assertEquals(contentType, response.getContentType());
}
The above code, the snippet is the step definition for the above given Gherkin test specification example. Take a moment to map the wording of Given in the feature file with its @Given definition in the above sample. Likewise, do the mapping for When and Then. The below image can help you do so.
Mapping of a test from Feature file to its Step definition
Writing Cucumber Test Runner Class – The Glue Code
Up until this point, you should definitely be thinking about one major miss, which I have not talked about yet. That is the mapping code, or any bridge class, or in more Cucumber-JVM oriented terms, the glue code. We need the following glue code to make a mapping reference between feature files and the respective step definition files.
package com.googlebooks.Runner;
import io.cucumber.junit.Cucumber;
import io.cucumber.junit.CucumberOptions;
import org.junit.runner.RunWith;
@RunWith(Cucumber.class)
@CucumberOptions(glue = {"com.googlebooks.stepDefinitions"}, features = "src/test/resources",
plugin = {"pretty", "html:target/site/cucumber-pretty",
"json:target/cucumber.json"})
public class TestRunner {
}
Some Extra Stuff
I have explained enough to this point to get you started with Cucumber-JVM and having your first experience of writing simple tests in Gherkin. However, I do not want you to scratch your head and wonder why there is much other stuff in the linked git repository (if you are convinced to at least look at it). Therefore, I thought of adding this section as a complementary part for you. So, please enjoy it and try to understand the few last things.
Figure 1 is for the project structure. There are a few folders that might confuse you; however, they bring modularity and scalability in our testing project (framework). Here goes the explanation of these components.
Business Logic Class
public class GoogleBooksBusinessLogic {
public static BooksVolume getBooksVolumeResponseObject(Response jsonResponse){
BooksVolume booksVolumePojo = jsonResponse.getBody().as(BooksVolume.class);
System.out.println("String representation of booksVolume response pojo " +
booksVolumePojo.toString());
return booksVolumePojo;
}
}
The business logic layer is to cover an approach or a way of handling some internal, application/business-specific requirements. Such as conversion of data from one form to another somewhere to access it centrally. In the code above, we are converting the JSON response, which is received from our Web Service to a Java Pojo – `BooksVolume`. I will be calling this function where I need to parse the response from JSON to Java object. Please note that for demo purposes, I have used only one Example, that is why you see only one conversion here. You may have many such conversions and logic implementation in big projects. Apart from other advantages, this conversion allows me to reuse this converted Json response to Java Object in multiple test cases, which requires working on the same response. Moreover, it will make the code clean as once you get the converted Java object, the rest of the code flow will follow the same Pojo structure to make following Object-Oriented rules easy for you.
Property Reader Class
public class PropertyReader {
protected static Properties prop;
public PropertyReader() {
try{
prop = new Properties();
FileInputStream ipStream = new FileInputStream(System.getProperty("user.dir") +
"/src/main/resources"
+ "/config/config.properties");
prop.load(ipStream);
}
catch (IOException exc){
exc.printStackTrace();
}
}
}
What do you guess about its functionality by looking at its code and name? Of course, it is for reading out common properties that are externally configurable such as base URLs, IPs, ports, and many other variables that should not be the part of project compilation, hence keeping it in the resource folder of our codebase. Here, our configuration file is saved with an extension of .properties. Therefore, you will extend any class which will have to read properties from the PropertyReader class, such as our `BookStepDefinition` class.
Running Your Project
For the execution of your test cases, you need to run mvn test in your terminal.
Following is the build output I get by scrolling my window to its most down.
Homework Exercises
This project is meant to design and explain to get you a kickstart with BDD and Cucumber-JVM in particular. Therefore, if you really want to write good Gherkin tests, add the following changes in the project.
- Add proper logging by using the logging library of your choice, such as
slf4j. - Add a few more scenarios – gherkin tests in the feature file and their step definition in the definition file.
- Add variables in properties readers if necessary.
- Explore reporting libraries and serenity documentation features provided by BDD. The Cucumber was initially being designed for Ruby, so give a thorough look at how Cucumber-JVM offers different implementation of BDD than BDD in Ruby.
History
- 4th September, 2020: Initial version

