Using the .NET Core implementation of TcpClient to develop a client for a multi-threaded server developed in C++ that uses the Windows Extensible Storage Engine (ESE) as its database engine. The server uses an I/O completion port with a thread-pool to process client request.
Introduction
This is the fourth article about a pet project I am working on. While it is a work in progress, I feel some things are starting to fall into place.
At this point, I have a C++ framework that makes it easy to create a multithreaded server that communicates using TCP/IP.
Since a server without a client is rather pointless, I thought it would be interesting to create a client library using C# for .NET Core that can be used with the server.
I hope you will find it interesting too – because it performs rather well:
Wrote 527040 records in 1,7029398 seconds, 309488,33305792726 records per second.
Wrote 527040 records in 1,7059422 seconds, 308943,64416332514 records per second.
Retrieved 1054080 records in 1,4269109 seconds, 738714,6597590642 records per second.
Retrieved 1054080 records in 1,4674932 seconds, 718286,1222116736 records per second.
The server stores data using Microsofts’ extensible storage engine (ESE).
Using the System.Net.Sockets.TcpClient is really easy, and if we disregard the DTO classes for the data-model, the client is implemented in just above 600 lines of C# code. I think that is rather neat because:
- The client implements 21 methods that can be used to:
- connect to the server
- disconnect from the server
- test the performance of just sending data to the server, without updating the database
- perform CRUD on the data-model implemented by the server, updating the database
- There is a decent level of error handling, including throwing exceptions on the .NET side for exceptions thrown by the C++ code on the server.
The data-model implemented by the server is the one I created for Using C++ to Simplify the Extensible Storage Engine (ESE) API - Part 2.
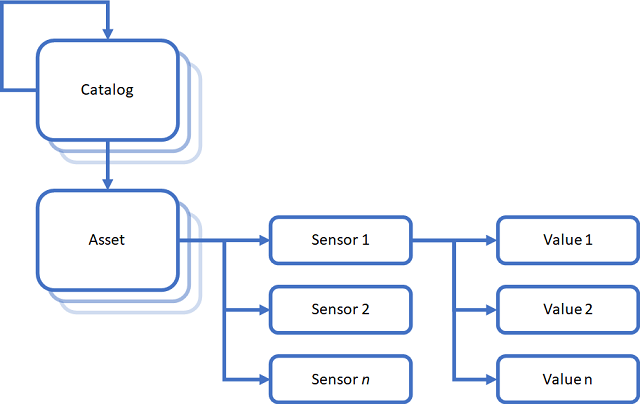
The client and server exchange data using a custom binary format that is efficient and easy to implement.
I know you have heard this one before:
There are only 10 types of people in the world: those who understand binary, and those who don't.
but these days it is easy to forget that computers only understand binary data. Sure, you can use Snappy, or something similar, to compress JSON and XML to reduce bandwidth requirements, but that adds to the cost of generating and processing the data – as if the cost of parsing and generating text isn’t high enough. If you have tried writing an efficient parser for floating point numbers, you will know what I mean.
JSON and XML are excellent for exchanging data with other parties because these formats are so broadly supported across platforms and technology stacks, but once the data is inside your pond, you should do as Google, Microsoft, and any other big cloud operator; and use Protocol Buffers, or something similar, to serialize and deserialize your data:
- Protocol Buffers: According to the FAQ “Protocol buffers are used by practically everyone inside Google”
- Bond: According to the github page for the project “Bond is broadly used at Microsoft in high scale services.”
- Apache Thrift: Originally created by Facebook
- FlatBuffers: Originally created at Google for game development and other performance-critical applications.
- Cap’n Proto: Written by Kenton Varda, the primary author of Protocol Buffers version 2
Your mileage will obviously vary, but for a cloud deployment, you could cut the costs of running back-end services by more than 90% and provide a more responsive service at the same time.
Binary vs JSON
Most will find this pretty obvious, but if you are in doubt: Here are the numbers to back the above claim, generated by the C# program that is used to demonstrate how to use the C# client library to work with the server.
First, we send a bunch of records to the server, without storing the data, just to get an idea about how this performs:
Sendt 527040000 records in 31.4532607 seconds, 16756291.343746118 records per second.
The server received one thousand batches of 527 040 SensorPoint objects, that were placed in a std::vector<SensorPoint> object, ready for further processing on the server.
Then we serialize and send the same amount of data as JSON to the server:
Serialized and sendt 527040000 records as JSON in 462,185403 seconds,
1140321,6037958688 records per second.
The server received one thousand batches of 527 040 SensorPoint objects as JSON that were placed in a std::string object, ready for parsing. This used quite a bit more time than sending the binary payload.
A point I would like to make: Normally, it is not the network transfer of the JSON data that makes this so expensive, it is the process of generating the JSON.
Just serializing data to JSON, sending it nowhere:
Serialized 527040000 records to JSON in 419,02034 seconds,
1257790,970242638 records per second.
makes it clear that more than 90% of the time was spent serializing the data to JSON, and not transmitting and receiving the data on the server.
Converting the JSON data back into a form that can be used by a computer program costs even more:
Deserialized 527040000 records from JSON in 618,1851519 seconds,
852560,108213754 records per second.
Serializing, sending, and deserializing the data using the binary format created for the server is more than 33 times as efficient as doing the same thing using JSON, and this is knowledge that can be used to cut costs.
To perform these experiments yourself, you need to build two of the provided projects:
ExampleSocketServer02Harlinn.Examples.TestTcpClient.Net
To run the server, use the following command:
ExampleSocketServer02.exe -c -r -t -u F:\Database\ESE\Test\Database.edb
where “F:\Database\ESE\Test\Database.edb” is the path to the database directory. Harlinn.Examples.TestTcpClient.Net does not take any arguments, just execute it from the command-line to see the output written to the console.
Building the Code
Instructions for building the code are provided in Build.md located in the $(SolutionDir)Readme folder.
The ESE tests use an environment variable HCC_TEST_DATA_ROOT, and this must be set to the full path to a directory where the tests can create a database. Make sure there is at least 10 GB of free space on the drive containig this directory.
TcpClient
If you have tried using the TcpClient earlier, and been disappointed by its performance, that is probably because you have tried to perform many small read and write operations using the NetworkStream directly. Reading and writing small fragments of data is typical for data serialization and deserialization, so anything that can improve the performance for this is important. Fortunately, .NET provides a nice solution for this problem out of the box: System.IO.BufferedStream
void InitializeSession(ulong id)
{
_sessionId = id;
var networkStream = GetNetworkStream();
_bufferedStream = new System.IO.BufferedStream(networkStream, ushort.MaxValue / 2);
_reader = new BinaryReader(_bufferedStream, System.Text.Encoding.Default, true);
_writer = new BinaryWriter(_bufferedStream, System.Text.Encoding.Default, true);
}
The client puts a BufferedStream between the BinaryReader and BinaryWriter objects that will be used to serialize and deserialize the data, and this really improves the performance, a lot!
Using BinaryReader and BinaryWriter for serialization is, as you know, a straightforward process:
public class Named : IReadWrite
{
Guid _id;
string _name;
...
public virtual void Read(BinaryReader reader)
{
_id = reader.ReadGuid();
_name = reader.ReadString();
}
public virtual void Write(BinaryWriter writer)
{
writer.Write(_id);
writer.Write(_name);
}
}
On the C++ side of things, we also have a BinaryReader class and a BinaryWriter class, that works well with their .NET counterparts as long as the default encoding is used for character and string data.
Each C# client-side implementation performs the same sequence of tasks:
- Write the request:
- Write a byte containing the
RequestReplyType identifying the function to call on the server. - Write the session id and the request id.
- Write the parameters, if any, to the function.
- Call
Flush() on the BinaryWriter to causing the BufferedStream to flush any buffered data to the NetworkStream ensuring that everything written so far is sent to the server.
- Read the reply from the server:
- Read a byte containing the
RequestReplyType identifying the function that was called on the server, or RequestReplyType.Fault indicating that the reply contains error information. - If the
RequestReplyType matches the one that was sent:
- Read the session id and the request id from the reply, check that they match what was sent to the server.
- Read the reply data if any is expected from the server.
- If the
RequestReplyType is equal to RequestReplyType.Fault:
- Read the error information sent by the server and throw an exception.
- If the
RequestReplyType is anything else:
A typical call to the server is implemented like this:
public CatalogItem GetCatalogItem(Guid itemId)
{
lock (_syncObj)
{
const RequestReplyType requestReplyType = RequestReplyType.GetCatalogItem;
CatalogItem result = null;
var requestId = WriteRequest(requestReplyType, itemId);
ReadAndValidateReplyHeader(requestReplyType, requestId);
var reader = Reader;
var found = reader.ReadBoolean();
if (found)
{
result = CatalogItemFactory.Read(reader);
}
return result;
}
}
Each of the methods implemented by the client library is about as simple as the above piece of code.
The server writes a boolean value to the stream, which is set to true if it found the requested CatalogItem. CatalogItem is the base class for the Catalog and Asset classes, and the CatalogItemFactory reads a 16-bit value indicating which one it is, creates and object of that type, which then deserializes the rest of the data from the stream for that type:
public static CatalogItem Create(CatalogItemType kind)
{
switch (kind)
{
case CatalogItemType.Catalog:
return new Catalog();
case CatalogItemType.Asset:
return new Asset();
default:
throw new Exception("Unsupported catalog item type");
}
}
public static CatalogItem Read(BinaryReader reader)
{
var kind = CatalogItem.ReadKind(reader);
var result = Create(kind);
result.Read(reader);
return result;
}
Pretty simple, but also a powerful technique that can be used to handle deserialization for types belonging to large inheritance hierarchies.
In the implementation of GetCatalogItem, I call WriteRequest:
ulong WriteRequest(RequestReplyType requestReplyType, Guid id)
{
var result = WriteSessionHeader(requestReplyType);
var writer = Writer;
writer.Write(id);
writer.Flush();
return result;
}
passing RequestReplyType.GetCatalogItem for the requestReplyType parameter, and I will get to that shortly.
The call to writer.Flush() is really important because this will cause the BufferedStream to write the contents of its buffer to the NetworkStream. This is also the last thing the client does before waiting for a reply from the server.
ulong WriteSessionHeader(RequestReplyType requestReplyType)
{
RequireValidSession();
var requestId = NewRequest();
var writer = Writer;
writer.Write((byte)requestReplyType);
writer.Write(_sessionId);
writer.Write(requestId);
return requestId;
}
WriteSessionHeader is the method that writes the start of a request to the server, starting with writing the value of the requestReplyType parameter as a single byte indicating which function it wants the server to perform. Next comes a 64-bit integer identifying the session on the server, and then a 64-bit counter identifying the request made by this client to the server.
The RequestReplyType, session id and request id will be included in the header of the reply from the server, so we will know that something did not get seriously mixed up server-side. The server uses a thread-pool, where the sessions are not tied to a particular thread, so I put this into the protocol as a way to verify this, and that is the task performed by ReadAndValidateReplyHeader:
void ReadAndValidateReplyHeader(RequestReplyType requestReplyType, ulong expectedRequestId)
{
var reader = Reader;
var replyType = (RequestReplyType)reader.ReadByte();
if (replyType != requestReplyType)
{
HandleInvalidReplyType(replyType, requestReplyType);
}
else if (replyType == RequestReplyType.Fault)
{
HandleFault(reader);
}
ulong sessionId = reader.ReadUInt64();
if (sessionId != _sessionId)
{
var message = string.Format("Invalid session id: {0}, expected:{1} ",
sessionId, _sessionId);
throw new Exception(message);
}
ulong requestId = reader.ReadUInt64();
if (requestId != expectedRequestId)
{
var message = string.Format("Invalid request id: {0}, expected:{1} ",
requestId, expectedRequestId);
throw new Exception(message);
}
}
The HandleFault method throws a plain vanilla Exception containing the error message from the server:
void HandleFault(BinaryReader reader)
{
var faultReply = new Types.FaultReply();
faultReply.Read(reader);
throw new Exception(faultReply.Message);
}
The above is not much, but it goes a long way when it comes to establishing a decent mechanism for passing errors from the server to the client.
Using the TcpClient this way is remarkably easy, and the code for the method that retrieved 738 714 records per second from the server is equally simple:
public SensorPoint[] GetSensorPoints(Guid sensorId,
DateTime intervalStart, DateTime intervalEnd)
{
lock (_syncObj)
{
const RequestReplyType requestReplyType = RequestReplyType.GetSensorPoints;
var requestId = WriteRequest(requestReplyType, sensorId, intervalStart, intervalEnd);
ReadAndValidateReplyHeader(requestReplyType, requestId);
var reader = Reader;
var count = reader.ReadInt32();
var result = new SensorPoint[count];
for (int i = 0; i < count; i++)
{
result[i].Read(reader);
}
return result;
}
}
Once we know that we have a valid reply, we retrieve the number of records to read from the stream, and since SensorPoint implements the IReadWrite interface, it knows how to deserialize itself.
Server::TcpSimpleListener
The code for this article is based on the code I created for the last article about ESE. I have made a few minor modifications to that code, and nearly everything else required to implement a working server example is provided in a single header file: ServerEngine.h.
Once you have built the ExampleSocketServer02 project, run the server using the following command:
ExampleSocketServer02.exe -c -r -t -u F:\Database\ESE\Test\Database.edb
The implementation of the main function is straightforward:
int main( int argc, char* argv[] )
{
try
{
EngineOptions options;
if ( ParseOptions( argc, argv, options ) )
{
ServerEngine engine( options, "TestInstance" );
WSA wsa;
constexpr size_t ThreadPoolSize = 12;
constexpr size_t SocketCount = 200;
IO::Context context( ThreadPoolSize );
Address address( options.Port );
Server::TcpSimpleListener<Protocol>
listener( context, address, SocketCount, &engine );
context.Start( );
puts( "Press enter to exit" );
while ( getc( stdin ) != '\n' );
context.Stop( );
}
}
catch ( std::exception& exc )
{
std::string message = exc.what( );
printf( "Exception: %s", message.c_str( ) );
}
return 0;
}
This server implementation uses the template:
template <typename ProtocolT>
class TcpSimpleListener : public TcpListener<TcpSimpleListener<ProtocolT>,
TcpSimpleConnectionHandler<TcpSimpleListener<ProtocolT>, ProtocolT> >
{
public:
using Base = TcpListener<TcpSimpleListener<ProtocolT>,
TcpSimpleConnectionHandler<TcpSimpleListener<ProtocolT>, ProtocolT> >;
template<typename ...Args>
TcpSimpleListener( IO::Context& context,
const Address& listenAddress,
size_t clientSocketCount,
Args&&... args )
: Base( context, listenAddress, clientSocketCount, std::forward<Args>( args )... )
{
}
};
which can be instantiated for a protocol implementation. Any class that implements a template function with the following signature can be used:
template<IO::StreamReader StreamReaderT, IO::StreamWriter StreamWriterT>
bool Process( IO::BinaryReader<StreamReaderT>& requestReader,
IO::BinaryWriter<StreamWriterT>& replyWriter )
{
...
}
The framework will create an instance of the class specified by the ProtocolT template parameter for each connection, storing the arguments provided through args in a std::tuple<> that will be used to pass those arguments to the contructor of the ProtocolT type.
Just like for the C# client, we have a IO::BinaryReader<> and a IO::BinaryWriter<> that will be used for serialization and deserialization. The actual handling of the protocol is performed by the Protocol class.
Reads and writes are buffered, and writes to the underlying socket are fully asynchronous, while reads from the socket are partially asynchronous. The write buffers comes from a pool of buffers that is shared between all the connection handlers, while there is a single read buffer is for each connection handler. Writes are queued, enabling a protocol implementation to generate a large amount of output without waiting for the client to catch up.
When Protocol::Process(…) returns false, the framework will close the connection, and when it returns true, it will begin a new asynchronous read operation after flushing all outstanding writes in the write queue for the connection.
The framework calls the Protocol::Process(…) whenever there is data available for processing. The implementation pf Protocol only knows about the ServerEngine, and the IO::BinaryReader<> and IO::BinaryWriter<> objects. This ensures that the implementation of Protocol is transport independent, which is nice.
The Protocol::Process(…) function just reads the byte identifying the function to call and uses a switch to call the implementation:
template<IO::StreamReader StreamReaderT, IO::StreamWriter StreamWriterT>
bool Process( IO::BinaryReader<StreamReaderT>& requestReader,
IO::BinaryWriter<StreamWriterT>& replyWriter )
{
bool result = true;
auto requestType = ReadRequestType( requestReader );
switch ( requestType )
{
...
case RequestReplyType::CloseSession:
{
CloseSession( requestReader, replyWriter );
result = false;
}
break;
case RequestReplyType::GetCatalogItem:
{
GetCatalogItem( requestReader, replyWriter );
}
break;
...
}
return result;
}
Each server-side function implementation performs the same sequence of tasks:
- Read the session id and the request id.
- Read the expected parameters, if any, to the function.
- Use the session id to find the session implementation.
- If this is a valid session:
- Lock the session.
- Perform the requested operation using the
session object. - If everything goes as expected:
- Reply to the client by writing the reply header
- Write a byte containing the value of
RequestReplyType identifying the function. - Write the session id and the request id.
- Write the reply data if any is produced by the function
- If an exception was caught:
- Write a byte containing the value of
RequestReplyType::Fault - Write the session id
- Write the error code
- Write the error message
- If this is not a valid session
- Write an error reply to the client, using the same format as for an exception
Since you already know the client-side implementation of GetCatalogItem, it should be easy to understand its server-side counterpart:
template<IO::StreamReader StreamReaderT, IO::StreamWriter StreamWriterT>
void GetCatalogItem( IO::BinaryReader<StreamReaderT>& requestReader,
IO::BinaryWriter<StreamWriterT>& replyWriter )
{
constexpr RequestReplyType ReplyType = RequestReplyType::GetCatalogItem;
auto [sessionId, requestId] = ReadSessionRequestHeader( requestReader );
auto itemId = requestReader.ReadGuid( );
auto* session = engine_.FindSession( sessionId );
if ( session )
{
SERVERSESSION_TRY
{
CatalogItem catalogItem;
auto found = session->GetCatalogItem( itemId, catalogItem );
WriteReplyHeader<ReplyType>( replyWriter, sessionId, requestId );
replyWriter.Write( found );
if ( found )
{
Write( replyWriter, catalogItem );
}
}
SERVERSESSION_CATCH( );
}
else
{
InvalidSession( replyWriter, sessionId );
}
}
ReadSessionRequestHeader just reads the session id and request id using the BinaryReader:
template<IO::StreamReader StreamReaderT>
std::pair<UInt64, UInt64> ReadSessionRequestHeader( IO::BinaryReader<StreamReaderT>& reader )
{
auto sessionId = reader.ReadUInt64( );
auto requestId = reader.ReadUInt64( );
return { sessionId, requestId };
}
Then the implementation reads the single parameter, itemId, from the stream.
At this point, we are done reading request information, and it is time to retrieve the session. If found, we lock on the session, and if not, this is reported back to the client by the InvalidSession function.
#define SERVERSESSION_TRY std::unique_lock lock( *session ); try
SERVERSESSION_TRY is a macro that locks the session and starts a try/catch block. Any exception thrown by the implementation will be caught by SERVERSESSION_CATCH(), which will write the appropriate error information to the reply stream.
#define SERVERSESSION_CATCH() \
catch ( const Core::Exception& ex ) \
{ \
WriteFault( replyWriter, sessionId, ex ); \
} \
catch ( const std::exception& exc ) \
{ \
WriteFault( replyWriter, sessionId, exc ); \
} \
catch ( const ThreadAbortException& ) \
{ \
throw; \
} \
catch ( ... ) \
{ \
UnknownException( replyWriter, sessionId ); \
}
The above works well as long as nothing has been written to the reply. If something goes wrong while serializing the reply, that will indicate that something is seriously wrong with the state of the socket, causing the error reporting functions to throw too – which will cause the server implementation to reset the connection.
With a lock on a valid session in place, the implementation of GetCatalogItem just calls the implementation of the GetCatalogItem on the session object, and then writes the result to the reply stream.
ServerEngine and ServerSession
The ServerEngine class is derived from template<typename D, typename T> class EngineT, where D is the derived type ServerEngine, and T is the ServerSession type.
By using the curiously recurring template pattern, the EngineT template can pass a reference to its derived type to the constructor for the session implementation. The ServerEngine class does not provide any functionality beyond what is implemented by the EngineT template, but the template needs to know what kind of session objects it is going to manage.
Similarly, ServerSession is derived from template<typename T> class SessionT, where T is the SessionEngine class. The ServerSession adds some critical pieces of functionality, that is required to be able to safely lock the session while processing client requests by threads from the thread-pool.
The ServerSession class uses the CriticalSection from the Synchronization with Visual C++ and the Windows API article.
class ServerSession : public SessionT<ServerEngine>
{
...
std::unique_ptr<CriticalSection> criticalSection_;
public:
...
};
The reason for using a unique_ptr<> to hold the CriticalSection, is that the CriticalSection will have a lifetime that goes slightly beyond the lifetime of the session:
void Close( )
{
std::unique_lock lock( *criticalSection_ );
auto ciriticalSection = std::move( criticalSection_ );
Base::Close( );
}
Base::Close() will close the ESE session handle, and then tell the ServerEngine to destroy the session, and we need to allow the destructor for lock to safely call unlock() on the critical section, so it cannot just go away until the lock goes out of scope.
The ServerSession implements the C++ BasicLockable requirement that describes the minimal characteristics of types that provide exclusive blocking.
void lock( ) const
{
criticalSection_->Enter( );
auto& eseSession = EseSession( );
UInt64 context = (UInt64)this;
eseSession.SetContext( context );
printf( "Set context: %llu\n", context );
}
The lock() function calls Enter() on the CriticalSecion, before calling SetContext(…) on the ESE session associating the session with the current thread. This association overrides the default behavior of ESE where an entire transaction for a given session must occur within same thread.
The unlock() function removes the association with the current thread, before releasing the lock held on the critical section.
void unlock( ) const
{
auto& eseSession = EseSession( );
eseSession.ResetContext( );
criticalSection_->Leave( );
UInt64 context = (UInt64)this;
printf( "Reset context: %llu\n", context );
}
The above implementations of lock() and unlock() allows the session to be served by one thread from the thread-pool for one call, an another thread for the next.
Using the C# Client Library
The download includes the source code for the executable that was used to test the C# client library, and here are a few “high-lights”.
The main class of the client library is called Session, and the following snippet creates a session object and connects to the server:
void Connect()
{
_session = new Session("localhost", 42000);
_session.Connect();
}
To close the connection:
void Disconnect()
{
if (_session != null)
{
_session.Close();
}
_session = null;
}
To build a data-data model, we first need to create on or more catalogs at the root of the catalog structure:
var catalog = _session.CreateOrRetrieveCatalog(Guid.Empty, name);
Passing an empty Guid indicates that this will be a root catalog, otherwise the Guid has to identify an existing catalog.
Once we have a catalog, we can add an Asset:
var asset = _session.CreateOrRetrieveAsset(catalog.Id, name);
and then we can create a Sensor:
var sensor = _session.CreateOrRetrieveSensor(asset.Id, name);
With a Sensor object in place, we can store a timeseries of SensorPoint data for the sensor:
SensorPoint[] GenerateSensorPoints(Sensor sensor, TimeSpan offset )
{
var points = GenerateSensorPoints(offset);
var stopwatch = new System.Diagnostics.Stopwatch();
stopwatch.Start();
_session.StoreSensorPoints(sensor.Id, points);
stopwatch.Stop();
var seconds = stopwatch.Elapsed.TotalSeconds;
var pointsPerSecond = points.Length / seconds;
Console.Out.WriteLine("Wrote {0} records in {1} seconds, {2} records per second.",
points.Length, seconds, pointsPerSecond);
return points;
}
retrieving timeseries data for an interval is done using:
_points1Retrieved = _session.GetSensorPoints(_sensor1a.Id, _intervalStart, _intervalEnd);
The End
Hopefully, you learned something interesting, and useful, from this article. My hope is that I was able to provide enough information here to get you interested in trying out alternatives for serializing and desrializing data sent between the components of your solutions.
Personally, I really like the performance I can get out of FlatBuffers and Cap’n Proto, and Microsofts’ Bond has features, such as inheritance, that I find highly desirable.
Apache Thrift and Goggles’ Protocol Buffers are the ones most widely used, with larger eco-systems surrounding them.
Each have their strengths, and by writing this article, my goal was to provide a few insights that will help you pick the one that is right for your projects.
As this pet project moves forwards, I will try to find ways to integrate at least one them with the server framework.
So, until next time: Happy coding!
History
- 18th September, 2020
- 19th September, 2020
- Fixed misssing inline for two functions in HCCEse.h, and the ESE tests now use an environment variable,
HCC_TEST_DATA_ROOT, to configure where the test database will be created
- 6th October, 2020
- Bug fixes, cleaned up most of the unit tests
- 7th October, 2020
- More unit tests for the
Harlinn.Common.Core library
- 11th October, 2020
- More unit tests for the
Harlinn.Common.Core library
- 13th October, 2020
- More unit tests for the
Harlinn.Common.Core library, and two new examples for the Harlinn.Windows library
- 17th October, 2020
- Fix for
TimerQueue and TimerQueueTimer, more unit tests for the Harlinn.Common.Core library
- 18th December, 2020:
- Bug fixes for
IO::FileStream - Initial http server development support
- Synchronous server: $(SolutionDir)Examples\Core\HTTP\Server\HttpServerEx01
- Asyncronous server: $(SolutionDir)Examples\Core\HTTP\Server\HttpServerEx02
- Simplified asynchronous I/O, Timers, Work and events for Windows waitable kernel objects using Windows thread pool API: $(SolutionDir)Examples\Core\ThreadPools\HExTpEx01
- 1st January, 2021
- Improved support for asychronous server development
- New design for working with sockets
- Concept based stream implementations
- 11th February, 2021
- Bug fixes
- Initial C++ ODBC support
- 25th February, 2021
- Updated LMDB
- Updated xxHash
- Added the initial implementation of very fast hash based indexes for large complex keys using LMDB
- Fast asychronous logging - nearly done :-)
- 3rd March, 2021:
- New authorization related classes
SecurityId: Wrapper for SID and related operationsExplicitAccess: Wrapper for EXCPLICIT_ACCESSTrustee: Wrapper for TRUSTEESecurityIdAndDomain: Holds the result from LookupAccountNameLocalUniqueId: Wrapper for LUIDAccessMask: Makes it easy to inspect the rights assigned to an ACCESS_MASK
AccessMaskT<>
EventWaitHandleAccessMask: Inspect and manipulate the rights of an EventWaitHandleMutexAccessMask: Inspect and manipulate the rights of a MutexSemaphoreAccessMask: Inspect and manipulate the rights of a SemaphoreWaitableTimerAccessMask: Inspect and manipulate the rights of a WaitableTimerFileAccessMask: Inspect and manipulate file related rightsDirectoryAccessMask: Inspect and manipulate directory related rightsPipeAccessMask: Inspect and manipulate pipe related rightsThreadAccessMask: Inspect and manipulate thread related rightsProcessAccessMask: Inspect and manipulate process related rights
GenericMapping: Wrapper for GENERIC_MAPPINGAccessControlEntry: This is a set of tiny classes that wraps the ACE structures
AccessControlEntryBase<,>
AccessAllowedAccessControlEntryAccessDeniedAccessControlEntrySystemAuditAccessControlEntrySystemAlarmAccessControlEntrySystemResourceAttributeAccessControlEntrySystemScopedPolicyIdAccessControlEntrySystemMandatoryLabelAccessControlEntrySystemProcessTrustLabelAccessControlEntrySystemAccessFilterAccessControlEntryAccessDeniedCallbackAccessControlEntrySystemAuditCallbackAccessControlEntrySystemAlarmCallbackAccessControlEntry
ObjectAccessControlEntryBase<,>
AccessAllowedObjectAccessControlEntryAccessDeniedObjectAccessControlEntrySystemAuditObjectAccessControlEntrySystemAlarmObjectAccessControlEntryAccessAllowedCallbackObjectAccessControlEntryAccessDeniedCallbackObjectAccessControlEntrySystemAuditCallbackObjectAccessControlEntrySystemAlarmCallbackObjectAccessControlEntry
AccessControlList: Wrapper for ACLPrivilegeSet: Wrapper for PRIVILEGE_SETSecurityDescriptor: Early stage implementation of wrapper for SECURITY_DESCRIPTORSecurityAttributes: Very early stage implementation of wrapper for SECURITY_ATTRIBUTESToken: Early stage implementation of wrapper for an access tokenDomainObject
User: Information about a local, workgroup or domain userComputer: Information about a local, workgroup or domain computerGroup: local, workgroup or domain group
Users: vector of User objectsGroups: vector of Group objects
- 14th March, 2021 - More work on security related stuff:
Token: A wrapper for a Windows access token with a number of supporting classes like:
TokenAccessMask: An access mask implmentation for the access rights of a Windows access token.TokenGroups: A wrapper/binary compatible replacement for the Windows TOKEN_GROUPS type with a C++ container style interface.TokenPrivileges: A wrapper/binary compatible replacement for the TOKEN_PRIVILEGES type with a C++ container style interface.TokenStatistics: A binary compatible replacement for the Windows TOKEN_STATISTICS type using types implemented by the library such as LocalUniqueId, TokenType and ImpersonationLevel.TokenGroupsAndPrivileges: A Wrapper/binary compatible replacement for the Windows TOKEN_GROUPS_AND_PRIVILEGES type.TokenAccessInformation: A wrapper/binary compatible replacement for the Windows TOKEN_ACCESS_INFORMATION type.TokenMandatoryLabel: A wrapper for the Windows TOKEN_MANDATORY_LABEL type.
SecurityPackage: Provides access to information about a Windows security package.SecurityPackages: An std::unordered_map of information about the security packages installed on the system.CredentialsHandle: A wrapper for the Windows CredHandle type.SecurityContext: A wrapper for the Windows CtxtHandle typeCrypto::Blob and Crypto::BlobT: C++ style _CRYPTOAPI_BLOB replacementCertificateContext: A wrapper for the Windows PCCERT_CONTEXT type, provides access to a X.509 certificate.CertificateChain: A wrapper for the Windows PCCERT_CHAIN_CONTEXT type which contains an array of simple certificate chains and a trust status structure that indicates summary validity data on all of the connected simple chains.ServerOcspResponseContext: Contains an encoded OCSP response.ServerOcspResponse: Represents a handle to an OCSP response associated with a server certificate chain.CertificateChainEngine: Represents a chain engine for an application.CertificateTrustList: A wrapper for the Windows PCCTL_CONTEXT type which contains both the encoded and decoded representations of a CTL. It also contains an opened HCRYPTMSG handle to the decoded, cryptographically signed message containing the CTL_INFO as its inner content.CertificateRevocationList: Contains both the encoded and decoded representations of a certificate revocation list (CRL)CertificateStore: A storage for certificates, certificate revocation lists (CRLs), and certificate trust lists (CTLs).
- 23rd of March, 2021:
- Updated to Visual Studio 16.9.2
- Build fixes
SecurityDescriptor: Implemented serialization for security descriptors, enabling persistence of authorization data.

