Here we are using the Proximal Policy Optimisation (PPO) algorithm. We look at: the history of the humanoid environment for reinforcement learning, an introduction to Proximal Policy Optimisation (PPO), and the particular learning parameters that we override.
Introduction
History of the Humanoid Environment for Reinforcement Learning
A Humanoid environment was originally created by Tassa et al. for their 2012 paper "Synthesis and Stabilization of Complex Behaviors through Online Trajectory Optimization."
As part of that paper, the authors created the MuJoCo physics simulator. Most research into learning humanoid locomotion with reinforcement learning uses the MuJoCo environment.
However, MuJoCo is commercial software and you require a licence to use it. There are free academic and 30-day trial licences available, but in these articles we will be using a similar humanoid environment that has been created on top of the open source Bullet physics simulation engine.
The Bullet Humanoid environment is a bit more challenging than the MuJoCo ones because it is based on some tweaks that Roboschool made, imposing more realistic energy costs subtracted from the reward. Due to these differences, the rewards we will obtain in these articles are not directly comparable to those obtained from MuJoCo.
As before, let’s inspect the environment to see what we are up against.
>>> import gym
>>> import pybullet_envs
>>> env = gym.make(HumanoidBulletEnv-v0')
>>> env.observation_space
Box(44,)
>>> env.action_space
Box(17,)
So this represents another step up from the most complicated environment we have seen so far, increasing the dimensionality of the observation space from 28 in the Ant to 44 and, more importantly, raising the action space from 8 to 17.
There’s also the small matter of stability. The Ant is quite stable by nature, having a leg at each corner. In contrast, the Humanoid has to balance on two legs. The policy has to do a lot of work just to stop the agent from falling over, let alone learning to walk.
Introduction to Proximal Policy Optimisation (PPO)
Proximal Policy Optimisation was first proposed in the paper Proximal Policy Optimization Algorithms by Schulman et al.
PPO gathers trajectories of some set horizon length (that is, it performs what it believes to be the correct action according to the current state of the policy), then performs stochastic gradient descent on mini-batches of those trajectories for a specified number of epochs.
Note that PPO is an on-policy algorithm, meaning that at each stage it must be working with results obtained from the current partly trained policy. It does not work by sampling from a buffer of old results as we had seen with other algorithms.
Code
The code follows the typical pattern I have used elsewhere. The training parameters are based on those for this tuned example, which is known to work well with the Humanoid environment.
The particular learning parameters that we override are as follows:
gamma – The discount factor of the Markov Decision Process.lambda – The lambda parameter to pass to the Generalized Advantage Estimator (GAE). This represents a trade-off between bias and variance.clip_param – The PPO clipping parameter, which is used by the surrogate loss function to prevent the policy from being updated too aggressively.kl_coeff – The initial coefficient for KL divergence penalty. Like clip_param, it is used to prevent the policy from changing too quickly. This is used together with the kl_target parameter, although we leave that at its default value of 0.01.num_sgd_iter – The number of epochs to execute per training batch. SGD refers to stochastic gradient descent.lr – The learning rate. In this case, how big the steps should be when performing stochastic gradient descent.sgd_minibatch_size – The minibatch size within each epoch.train_batch_size – The number of samples in each batch passed to stochastic gradient descent.model/free_log_std – The description of this parameter in RLlib’s documentation is "For DiagGaussian action distributions, make the second half of the model outputs floating bias variables instead of state-dependent. This only has an effect [if] using the default fully connected net." I don’t claim to understand what that means!batch_mode – Whether to roll out truncated or full episodes from the workers.observation_filter – We apply a MeanStdFilter, which normalises observations based on the states it has seen.
import pyvirtualdisplay
_display = pyvirtualdisplay.Display(visible=False, size=(1400, 900))
_ = _display.start()
import ray
from ray import tune
from ray.rllib.agents.ppo import PPOTrainer
import pybullet_envs
ray.shutdown()
ray.init(include_webui=False, ignore_reinit_error=True)
ENV = 'HumanoidBulletEnv-v0'
import gym
from ray.tune.registry import register_env
def make_env(env_config):
import pybullet_envs
return gym.make('HumanoidBulletEnv-v0')
register_env('HumanoidBulletEnv-v0', make_env)
TARGET_REWARD = 6000
TRAINER = PPOTrainer
tune.run(
TRAINER,
stop={"episode_reward_mean": TARGET_REWARD},
config={
"env": ENV,
"num_workers": 21,
"num_gpus": 1,
"monitor": True,
"evaluation_num_episodes": 50,
"gamma": 0.995,
"lambda": 0.95,
"clip_param": 0.2,
"kl_coeff": 1.0,
"num_sgd_iter": 20,
"lr": .0001,
"sgd_minibatch_size": 32768,
"train_batch_size": 320_000,
"model": {
"free_log_std": True,
},
"batch_mode": "complete_episodes",
"observation_filter": "MeanStdFilter",
}
)
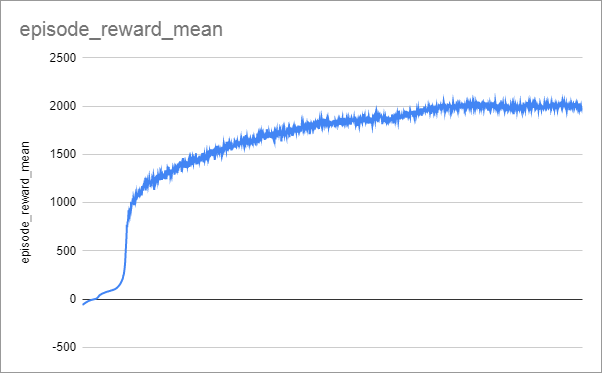
Graph
I left this running for a good while: 67 hours using 22 CPU cores. You might prefer to limit TARGET_REWARD to 2000.
Video
As you can see, the agent has learned to lean back and trot along.

Next time
In the next article we will adapt our code to train the Humanoid environment using a different algorithm: Soft Actor-Critic (SAC).

