Here we look at: What is SAC, and the meanings of the various learning parameters we have overridden in the code I used for learning the Humanoid environment with SAC.
What is SAC?
Soft Actor-Critic (SAC) was proposed in the paper "Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor" by Haarnoja et al.
Remember that Proximal Policy Optimisation (PPO) from the previous article is an on-policy algorithm, meaning that it can only learn from the states, actions, and rewards of the current policy. SAC, in contrast, is an off-policy algorithm: It optimises a stochastic policy like PPO, but does so using a buffer of stored experiences.
SAC uses something called entropy regularization, which means it tries to balance generating a large expected return with maintaining a degree of randomness in the policy. Or, as stated in the paper, "to succeed at the task while acting as randomly as possible." This increases the amount of exploration that takes place, which can be beneficial particularly in complex environments.
We will use the SAC algorithm exclusively for the rest of this series of articles. Although it seems to learn well, it’s possible that PPO (or some other algorithm) might have done even better. If you have the time and resources, you might like to try some different algorithms for everything that follows and see how these compare to the performance I got with SAC as a baseline.
Code
Here is the code I used for learning the Humanoid environment with SAC.
The specific learning parameters are based on those from this GitHub repo.
These are the meanings of the various learning parameters we have overridden:
actor_learning_rate – The learning rate for learning a policy.critic_learning_rate – The learning rate for learning a value function for evaluating the policy.entropy_learning_rate – The learning rate for maximising the entropy of the stochastic actor.train_batch_size – The number of records to sample from the experience buffer for training.target_network_update_freq – The number of training steps at which the target network should be updated.learning_starts – The number of steps of the model to sample before attempting to learn anything. Prevents overfitting on early experiences.buffer_size – The size of the experience buffer to maintain.observation_filter – As with PPO in the previous article, we apply a MeanStdFilter, which normalises observations based on the states that it has seen.
import pyvirtualdisplay
_display = pyvirtualdisplay.Display(visible=False, size=(1400, 900))
_ = _display.start()
import gym
import ray
from ray import tune
from ray.rllib.agents.sac import SACTrainer
from ray.tune.registry import register_env
ray.shutdown()
ray.init(include_webui=False, ignore_reinit_error=True)
ENV = 'HumanoidBulletEnv-v0'
def make_env(env_config):
import pybullet_envs
env = gym.make(ENV)
return env
register_env(ENV, make_env)
TARGET_REWARD = 6000
TRAINER = SACTrainer
tune.run(
TRAINER,
stop={"episode_reward_mean": TARGET_REWARD},
config={
"env": ENV,
"num_workers": 11,
"num_gpus": 1,
"monitor": True,
"evaluation_num_episodes": 50,
"optimization": {
"actor_learning_rate": 1e-3,
"critic_learning_rate": 1e-3,
"entropy_learning_rate": 3e-4,
},
"train_batch_size": 128,
"target_network_update_freq": 1,
"learning_starts": 1000,
"buffer_size": 1_000_000,
"observation_filter": "MeanStdFilter",
}
)
Graph
Training progress looked like this (running over 46 hours) on 12 CPU cores:
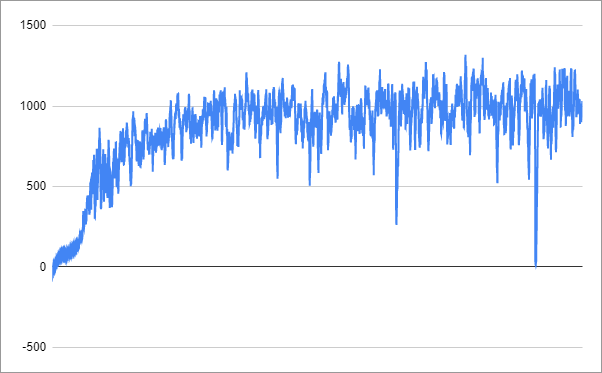
You might find you can get equally good results in less than half the time simply by setting the target result to 1200.
Video
Here is the video of the trained agent tottering along nicely (using the largest video file instead of the most recent iteration of the training, to try to capture the agent at its best):

The policy seems to have chosen not to use the knee joints at all, giving the agent a robotic appearance, such as might have been seen a long time ago in a galaxy far away!
Next time
In the next article we will have a bit of fun subverting the Humanoid environment, training on it in a way that was not intended. Specifically, we will try to train our agent to run backwards instead of forwards.

