Superficial introduction into terrors of U++ framework design: When C++ feels like a completely different language.
Table of Contents
Considered Harmful
Memory leaks! Dangling pointers! Buffer overruns!
C++ is one scary language, is not it?
Yet, a substantial number of modern top-tier applications are written in C++ as its advantages outweight its supposed shortcomings.
But those problems exist and affect the productivity and reliability. If you think about it, you can track it down as:
- Every new statement is an opportunity for a memory leak.
- Every delete statement or pointer assignment is an opportunity for a dangling pointer.
- Every instance of pointer arithmetic is an opportunity for a buffer overrun.
So let us hear what U++ has to say about it:
If It Hurts, Don't Do It
In U++, new and delete statements are considered unsafe. They are certainly still needed sometimes, but usually only at the implementation level. Interfaces strictly avoid any raw heap data to be passed around, heap should be just implementation detail.
On the application level, almost all heap management is provided by destructors and containers.
Pointer arithmetic is a little bit harder problem to crack. U++ partial solution is to provide operator[] to all U++ containers, which transforms the problem of pointer arithmetic into index arithmetic. Still, index arithmetic is usually easier to express, check and debug (at least I prefer to know that I am at index 5 instead of at position 0xac34bef). Also, indices never get invalidated, unlike iterators to std::vector (which is just another variant of dangling pointer problem).
In practice, this programming style is not only safer, but with other tricks leads to much more compact and simpler code. It is quite common for thousands of lines of U++ application code to be completely clean of any new/delete statements and pointer arithmetics and often even pointers.
All is Fair in Love, War and C++ Optimizations
C++ is a great language at its core performance. However, each time it gets compared to e.g. Java, results are not quite favorable. For us, such humiliation is inexcusable.
In reality, it does not take long to find the culprit: It is something called the "C++ standard library".
One issue is that most implementations are lacking in optimization, that probably could even be solved. What cannot be solved is the fact that C++ standard library is in fact defined in a way that can only be satisfied using specific implementation which is not always the best one.
Take for example std::map. If you read the documentation, you will find some fine print there: "No iterators or references are invalidated". Now that seems reasonable if you implement std::map using the binary tree of nodes. Unfortunately, such implementation might lack in performance in comparison to e.g. B-trees where this guarantee cannot be satisfied. Now ask yourself: When was the last time when not invalidating the reference to the std::map item solved anything important in your code? Is it really worth sacrificing the performance for it?
The Forbidden Fruit
It was discovered long time ago both by us and some really smart people that there is an important group of types that can be moved in the memory using plain memcpy even when C++ standard does not allow it (they are not PODs). Many complex and useful value types can be easily constructed in this way, including the one really important, String.
Why is this important? Well, the most effective data structure for the most uses is dynamic array, e.g., std::vector. In fact, it is so effective and versatile that most U++ containers are kind of dynamic array in one form or another.
Dynamic array needs to move its content when changing the capacity and even with move contructors introduced with C++11, memcpy is a much faster way how to achieve this task. Additionally, while insert/remove of element in the middle has O(n) complexity, it is still very useful and using memmove for this task easily results in 5 times speedup of the operation.
We have decided that this kind of speedup is really worth the trouble. Actually, quite a lot of trouble:
We made a Vector class that has this as requirement - it can only store elements that can be moved in memory by memcpy, nothing else. That however means that we cannot use existing infrastructure of C++ Standard library. E.g., we definitely cannot store std::string into Upp::Vector, as we have no guarantees about its internal workings. But worry not, no love is lost there: we have taken this opportunity to optimize everything and e.g. Upp::String is much faster than std::string.
The fine print: The requirement for the type to be moved around in memory with memcpy (and stored in Vector) is that: It has no virtual methods, none of its methods stores any references to its member variables into non-local variables and all of its member variables satisfy the same requirement.
Put Some Flavor into that C++
So if the Upp::Vector is quite limited in element types it can store, how are we supposed to handle those that do not fit?
Well, meet the Array. This is implementation equivalent of std::vector<std::unique_ptr<T>>, but the interface and usage semantics is exactly the same as for the Vector - to the degree that going from Vector to Array is mostly the act of rewriting "Vector" to "Array". Unlike Vector (and std::vector), it has none requirements on the element types stored. In fact, it can even store elements that are derived from T:
Array<Stream> input_files;
FileIn& f = input_files.Create<FileIn>();
The above code demonstrates another cornerstone of U++ design: inplace creation. Instead of creating an instance of object (on the heap) and adding it to the container, the preferred method is to create the instance directly in the container. This avoids any confusion about ownership of an object - it is always the container that owns it. (And yes, I am well aware about std:: emplace methods and it is the same thing. The difference is in emphasis, in U++, inplace creation is always the one to consider first.)
With Array / Vector dichotomy, U++ actually solves two important problems: Performance with Vector and avoiding manual heap management and significant number of pointers with Array.
The idea does not stop with Array / Vector, all relevant U++ containers are available in these two flavors, so there are queue-like containers BiVector and BiArray, maps VectorMap and ArrayMap and so on.
Be Explicit
There are situations when the content of container has to be moved somewhere else. Just like with standard library containers since C++ 11, there are two options in U++ - you can copy the content, or move it (std::move), leaving the source empty after the move.
However, unlike std:: containers, U++ containers do support "default" copy even if it is available. You can do
std::vector<int> x, y;
....
x = y;
but then, you can accidentally do possibly time consuming copy operation even when what you actually needed is to move the data.
That is why U++ requires you have to state yourself clearly when transferring the container content:
Vector<int> x, y;
....
x = clone(y); x = pick(y); x = y;
In reality, you can always count on container having pick operation while clone is available only if the element supports it.
Let's Index It
U++ associative containers are based on unusual concept: Index container.
You can think of Index as dynamic array, similar to Upp::Vector or std::vector, with one crazy twist:
It has the Find method that returns the index of the element with given value:
Index<int> n;
n.Add(21); n.Add(31); n.Add(12); n.Add(31);
int i = n.Find(31); i = n.FindNext(i); i = n.Find(5);
Index uses hashing to implement this, so the Find operation is in fact very fast (like 5-10 times faster than std::map).
Index can provide similar services as std::set or std::multi_set but the ability to return the index has a lot of other uses. The primary example is the implementation of key-value maps in U++: VectorMap and ArrayMap are just a thin interface layer over the Index of keys and the Vector or Array of values.
Random Access for Everybody
With Index approach to associative containers, another funny idea becomes possible:
All important containers can now have random access, means they always have operator[](int i) to access elements with index.
This is good as real world problems are usually "random addressed" as well: Think about real world examples like tables (cells have row/column coordinates) or texts (position in text from the start, line number).
It also makes it possible to avoid using iterators most of time. As iterators are form of pointer and the iteration is a kind of pointer arithmetics, this improves reliability.
Syntax Candystore++
C++ has operator overloading. That is a good thing, depending on whom you ask. U++ does not hesitate to use it. Worse: U++ does not hesitate to actually abuse it whenever there is a chance to make the code simpler and/or more readable.
Whether you will like it or hate it depends on whether you would rather like to issue SQL statements from C++ like this:
SqlQuery query;
query.prepare("INSERT INTO employee (id, name, salary) "
"VALUES (:id, :name, :salary)");
query.bindValue(":id", 1004);
query.bindValue(":name", "John Smith");
query.bindValue(":salary", 64000);
query.exec();
or you would be OK with this:
SQL * Insert(EMPLOYEE)(ID, 1004)(NAME, "John Smith")(SALARY, 64000);
If you cannot stand massive operator overloading and like the first version more then we are sorry that we have wasted your time, this crazy framework is not for you.
For the rest of us, operator overloading here adds compile times checks of your SQL statements, makes code shorter and cleaner, makes SQL injection attacks impossible and even irons out dialect differences between various SQL engines. I guess that is more than worth the uneasy feeling about operator overloading.
In other news, we also like the meaning of operator<< as "append" and see no reason why it should only work with streams:
Vector<int> x;
String s;
x << 1 << 2 << 3;
s << "And the values in the container are: " << x;
In addition to that, we have assigned a new meaning to some operators here and there, e.g.
EditString edit; edit <<= "Hello"; String s = ~edit;
Another syntax sugar often used is method chaining, where methods are returning *this instead of void - this is, for example, quite useful for setting up widgets.
EditString x;
TopWindow win;
win << x.SetFont(Serif(20))
.SetColor(LtCyan())
.SetFilter([](int c) { return ToUpper(c); })
.HSizePos().TopPos(10);
Nice and compact, right?
The Life and Death of GUI Widget
The pervasive wisdom of all major GUI toolkits is that GUI widgets (e.g., editor field) have to be allocated on the heap, then inserted into its parent (e.g., main window) and the parent then becomes the owner: when parent is destroyed, it deletes its children.
In U++, widgets are completely owned by the client code. They are often trivially created as local or member variables and are destroyed by normal destructor when going out of scope.
Adding widget to the parent simply means that parent knows about the widget and starts presenting it in the GUI. When parent is destroyed before the widget, nothing serious happens, widget is parent-less again. When widget is destroyed before the parent, widget is removed from parent and if the parent is displayed on the screen at that time, widget simply disappears.
Minimal U++ example demonstrating parent window with a child widget is this code:
GUI_APP_MAIN
{
TopWindow win; LineEdit x; x.SizePos(); win << x; win.Run(); }
Aside from parent widgets not owning its children, GUI also does not own any windows. All widgets exist independently from the fact whether they are active in the GUI or not.
The Age of Lambda
Every single C/C++ GUI framework seems to struggle with a relatively simple problem: When the user presses the button (or does some other noteworthy action), how is this action reported to the client code?
Solutions vary from bad to worse. Older frameworks used to assign some integer event ID to the action and pass it to some parent's virtual method. Many even invented the concept of relatively ugly message maps. Others declared C++ unworthy of such a complicated concept and introduced a language extensions and preprocesor.
Meanwhile, the trivial solution was possible at least since C++ 98 compliant compilers emerged which can support full callable object abstraction (e.g. boost::function, which then became std::function) as the only thing really needed here is just the code that represents the client action and nothing else.
Of course, since C++ 11, things are even better with lambdas. Since then the whole button issue is reduced to:
GUI_APP_MAIN
{
TopWindow win;
Button b;
b.SetLabel("Press me!");
b << [] { Exclamation("Ouch!"); };
win << b.VCenterPos().HCenterPos();
win.Run();
}
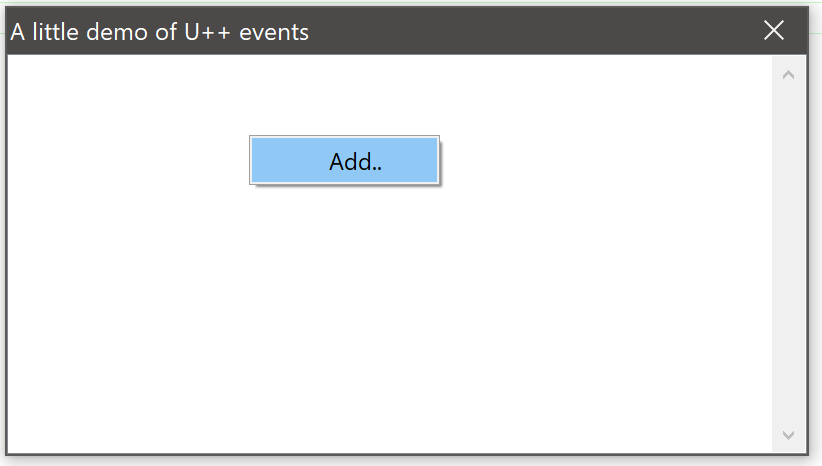
With lambdas, you can now write quite ridiculously complex applications without even defining a single class, method or a function:
GUI_APP_MAIN
{
ArrayCtrl list;
list.NoHeader().AddColumn();
list.WhenBar = [&](Bar& bar) { bar.Add("Add..", [&] { String s;
if(EditText(s, "Add", "Text"))
list.Add(s);
});
};
TopWindow win;
win << list.SizePos();
win.SetRect(0, 0, 800, 400);
win.Title("A little demo of U++ events").Run();
}

On the Importance of the Value
C++ is statically typed and we love that. But check this dialog:
Here are four widgets with some natural "value": First is String, second is double, third Date and that option is bool. What if we wanted to have a single virtual method interface in widget's base class interface that would allow us to treat the widget value in a uniform way? Yeah, you got it right, we need some type that can store either String or double or....
Now you could say this is a special situation and introduce some limited type just to handle some of GUI widgets.
But I say: This is important and this issue pops everywhere! Think JSON. Think SQL. Think EVERYWHERE!
That is why we have put a lot of effort into developing and optimizing the Value type. This type is designed to be able to store any type of value and even arrays of Values and maps of Values to Values. All relevant U++ types are created to be "Value" compatible, they have implicit casts to and from Value.
By all I mean: int, double, int64, bool, String, Date, Time, Complex, Color, Uuid, Point, Size, Rect, Pointf, Sizef, Rectf, Font, Drawing, Painting, Image. Well that is almost all of U++ normal value types, but Value is also designed to be extensible: You can make your own type Value compatible quite easily.
Not so accidentally, Value is a superset of JSON data model, which makes possible:
Value v = ParseJSON(R"--(
{ "items" : [ 1, 2, 3 ] }
)--");
int x = v["items"][1];
Having single Value type for all dynamic values allows for a nice synergy between various parts of U++. E.g., consider mixing SQL with GUI like this:
EditDate d;
d <<= SQL % Select(DATE_SOLD).From(SALES).Where(ID == id);
Considerable effort was invested into optimizing Value over years, both for the memory consumption and the speed. For example:
Vector<Value> x;
x << String("Hello world!") << 1.23 << 123 << GetSysDate() << Point(12, 34) << Magenta();
creates just a single 96 bytes memory block:
+0 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 00 00 00 0C Hello world!....
+16 AE 47 E1 7A 14 AE F3 3F 00 00 00 00 00 02 00 00 .G.z...?........
+32 7B 00 00 00 00 00 00 00 C0 81 0B 00 00 01 00 00 {...............
+48 09 0A E4 07 01 00 00 00 A8 58 14 40 00 04 00 00 .........X.@....
+64 0C 00 00 00 22 00 00 00 00 00 00 00 00 49 00 00 ...."........I..
+80 80 00 FF 00 00 00 00 00 00 00 00 00 00 27 00 00 .............'..
About Nothing
Let us revisit the dialog from the previous section once more:
Now the number field is empty. That can be considered as an user error and dialog might not allow such value (and yes, you can have that in U++ too), but very often, this just means "I do not know" or "I do not care" and widgets somehow need to signal the empty value to the client code.
Once again, we could deal with that by some limited extension to the widget interface OR we could deal for this situation once and for all. Inspired by SQL, we have introduced the concept of Null values - these are values that are empty.
Now for some dirty tricks: While introducing Null for more complex types like Date or Point is relatively simple, the problem is fundamental types, namely int, double and int64. Here, there are two choices - create some new Int / Double / Int64 encapsulation types with some "Null" bool option or you can do something crazy.
As you have expected, we went for crazy: We have taken the minimal value of these types, e.g. -2147483648 for int, and declared it Null. That reduces the range of int value in relevant contexts to -2147483647 .. 2147483647, but on the other hand, we have avoided having two different types for integer value. Choosing the minimal possible value has the advantage in sorting as it eventually puts Null values first.
Once again, defining Null in the U++ core library improves interoperability between various modules, e.g.:
EditDate d;
...
SQL * Update(SALES)(DATE_SOLD, ~d).Where(ID == id);
Two for the Price of One
Another example of U++ shenanigans is the way in which it deals with binary serialization.
struct SensorRecord {
String name;
double altitude;
double temperature;
}
DataStream& operator<<(DataStream& in, SensorRecord& m)
{
in >> m.name >> m.altitude >> m.temperature;
return out;
}
DataStream& operator<<(DataStream& out, const SensorRecord& m)
{
out << m.name << m.altitude << m.temperature;
return out;
}
If you look really carefully at it, you might notice something... Yes, these function bodies are in fact exactly the same! The only difference is that there is "<<" in one of them and ">>" in the other one.
Now we poor chaps at U++ team were thinking for only a 20 seconds before declaring: Why have two functions if you can have just one?
struct SensorRecord {
String name;
double altitude;
double temperature;
void Serialize(Stream& s) { s % name % altitude % temperature; }
};
Single Serialize method in U++ provides the recipe for both loading and storing. As neither operator<< or operator>> would fit here, so we have hijacked operator%, which sort of invokes bidirectional character of operation in the best visual tradition of C++ operator abuse introduced by standard C++ streams.
Also note that there is no specialized DataStream class in U++. Thing is, the only real information such class provides over the stream class is the direction of process (load or store) and this is a single bit that can be easily stored in the Stream base abstract class. The advantage, besides having one less class to worry about, are better chances for optimizations as base operator% methods for primitive types can now be defined directly in the Stream.
Generic template of operator% then provides this serialization operator to every type with Serialize method. Providing Serialize method is a common practice for U++ classes, including containers, which makes the whole serialization business trivial:
struct SensorRecords {
Array<SensorRecord> records;
void Serialize(Stream& s) { s % records; } };
The Common Good
Serialize is an example of "U++ common method", something that integrates the type with common U++ mechanisms. There are many more such common features:
class Foo : public ValueType<Foo, 323, Moveable<Foo> > {
......
public:
String ToString() const; hash_t GetHashValue() const; bool IsNullInstance() const;
void Serialize(Stream& s); void Jsonize(JsonIO& jio); void Xmlize(XmlIO& xio);
Foo(const Nuller&);
operator Value() const; Foo(const Value& q); };
Note that this has nothing to do with base classes or virtual methods (usually...), these common methods are used through various templates. Providing these features as methods is more convenient than what C++ standard library wants us to do.
Resourceful C++
There are things that are best done typing the code. But everybody who has ever tried to create the raster image in the text editor can tell you that it is usually quite tedious process. Hence, we tend to use some visual design tools to do that:
Now when nice pictures get designed, we somehow need to get them into the application. Here, approaches differ.
Some say it is best to put them into files (usually .png), those files into folders that ship with the application, then add (a lot) of code to load the files into some internal objects. Good luck with that if your application needs more than 100 icons.
Others are using some form "resource" file which assigns some IDs to images, you are then using these IDs to identify the image.
What we in U++ do is to actually #include the file with images into C++ and the main result of that is the existence of class with static methods that return images. In other words, instead of filenames or some IDs, we have static C++ methods:
#include <CtrlLib/CtrlLib.h>
#define IMAGECLASS DemoImg
#define IMAGEFILE <Demo/Demo.iml>
#include <Draw/iml.h>
using namespace Upp;
struct MyApp : TopWindow {
virtual void Paint(Draw& w) {
w.DrawRect(GetSize(), White());
w.DrawImage(10, 10, DemoImg::MyImage());
}
};
GUI_APP_MAIN
{
MyApp().Run();
}
Dialog Templates are... Templates
Another resource that typical gets designed instead of created in the code is the layout of dialogs.
Now some frameworks describe the layout of elements in the code in logical way with things like grids and groupings, and that is ok and works fine, even if it might be a bit limiting and tedious process.
However, using visual designers for dialogs is another common practice and can be quite productive and this what U++ uses too.
Once the dialog is designed using some visual tool:
The same question as with graphics reappears: How to store this design with the application and connect it with the code?
Once again, various approaches are used and it usually ends with some dynamic dialog loader and integer or text IDs of widgets to identify them.
As you might have expected, U++ does something completely different. Just like with graphics, once you design the layout, you import it directly into the C++ using some nasty preprocessor tricks.
However, unlike raster images, the final product here is a template class definition which adds widgets to any base class and provides a function to place and setup them:
#include <CtrlLib/CtrlLib.h>
using namespace Upp;
#define LAYOUTFILE <Demo/Demo.lay>
#include <CtrlCore/lay.h>
GUI_APP_MAIN
{
WithDemoLayout<TopWindow> dlg; CtrlLayoutOKCancel(dlg, "My Dialog"); if(dlg.Execute() == IDOK)
PromptOK(String() << "Text is: " << ~dlg.text);
}
This tightly couples the design with C++: There are no external representations, no IDs, no dialog loading from resources. The widget names in the design are the member variable names in C++ and everything is direct and trivial.
Note: The reason why this is a template rather than just a class is that you not always use layout for whole dialogs, but also for parts of dialogs, e.g., tabbed dialog panes. It is therefore necessary to define the base class, which is the template parameter.
TheIDE
TheIDE is a standard development environment for U++ framework.
Now let me be clear:
I understand that providing standard IDE for U++ is probably something that many consider a major setback into trying U++. Yes there are many other IDE environments, some substantially more polished, and yes people like the choice here.
So why bother?
You might guess that the reason is the integration of visual designers for dialogs and images, but there is one much more important issue:
We want to make the U++ and U++ based code modular and truly platform independent.
U++ rejects the classical concept of "libraries" (something you have to build, then add to your include / library paths and with something like -l option to your commandline).
Instead, U++ modules are organized into "packages". Package is a single folder that contains source files together with some meta-information that describes the relation with other packages and optionally some other build related information. In TheIDE, you can setup this metainfomation in the Package organizer dialog:
In the above dialog, you can see as an example the definition of CtrlCore package (which is a package that provides basic GUI encapsulation). Look at the biggest pane and notice the "Uses" section first. This defines on which other packages CtrlCore depends (these are Draw, plugin\bmp, RichText and Painter).
Other sections (Libraries, Link options, pkg-config) in this case define what host platform libraries are to be linked with the application. Also note the "when" column with conditions to activate the line.
Now one thing to notice is that there are no include paths or library paths in package definition. That is for a good reason: Package should be platform agnostic, should compile on any computer and (ideally) any supported host platform without changing anything.
Therefore, another piece of puzzle is something called "Build method". This is basically a description of your local setup and this is the place where you add various paths and additional compiler options:
Thing to note is that only "external" header files paths have to be listed in the build method; for package headers, trivial mechanism and standardized way to make #includes makes sure they are always available.
All that said, U++ also provides commandline builder umk, so if you really insist, you can edit the package metainformation directly, use TheIDE just to edit dialog templates and images and continue using emacs like all real programmers do.
BLITZ Build
Another awesome feature that TheIDE provides is the automated single compilation unit technology: BLITZ.
It tries to combine the whole package into single file for the compiler to speed up compilation - the speedup comes from the fact that include files are processed just once.
The process is automated: U++ can decide which files can be part of this single compilation unit and even tries to resolve some issue that might hinder the process (e.g., undefines macros defined in .cpp file).
All this is then combined with another, this time well known, feature: C++ compiler is invoked in parallel on multicore CPUs (think -j option of gmake). The final speedup is summarized in this screenshot from my Ryzen 2700x machine:
11 seconds to completely rebuild a C++ GUI framework? I bet you miss your makefiles already.
All's Well that Ends Well
This lengthy rant is now closing 30KB which is probably a sign to stop.
If you have read as far as here, thank you for your attention!
I hope you have enjoyed the ride and that it is now a little bit more clear now what is meant by "U++ is designed around some rather extreme principles to maximise both developer productivity and performance" statement.
Useful Links
History
- 9th November, 2020: Initial version

