Here we'll select(for further work) two SSD models, one based on MobileNet and another one based on SqueezeNet.
In the introductory article of this series, we discussed a simple way of creating a DL person detector for edge devices, which was finding an appropriate DNN model and writing the code for launching it on a device. In this article, we’ll discuss the pros and cons of the existing DNN approaches and select a pre-trained model for further experimentation.
We’ve mentioned three modern DL techniques for object detection in images: Faster-RCNN, Single-Shot Detector (SSD), and You Only Look Once (YOLO). Each of these techniques has advantages and drawbacks we should take into account in order to select the one that best suits our specific purpose.
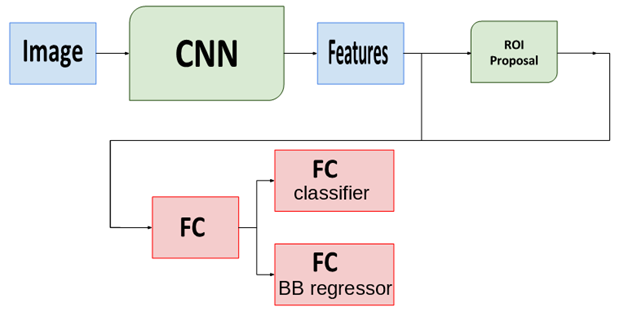
Faster-RCNN uses a convolutional neural network along with the Region-Proposal block and fully connected (FC) layers. CNN is the first block of the network; its job is to extract features from the image. The following block – Region-Proposal network – is responsible for suggesting Regions-of-Interest (ROI) for possible object locations. The final block – the FC layers – is intended for bounding box (BB) regression and object classification for each of the boxes. Here is a simple scheme of the Faster-RCNN algorithm:
The SSD method is similar to Faster-RCNN. After the CNN feature extractor, it contains a Multi-Box detector, which allows bounding box detection and object classification in a single forward pass. This is why it is considered to be faster than Faster-RCNN.
The YOLO technique is based on the Darknet framework. Instead of scanning an image over the different locations and scales, it divides the entire image into a grid of cells and analyses each cell, scoring each cell’s probability of belonging to a certain class. This makes the YOLO algorithm very fast.
Consideration of the speed alone would make YOLO the obvious choice. But there is one more thing to consider before we make the decision – the algorithm precision. The concept of precision for object detection is more complex than that for object classification. Here, we must evaluate not only the classification error, but also the error of the object’s bounding box location.
The main precision measure for object detection is Intersection over Union (IoU) – the ratio of intersection and union of ground-truth and the detected bounding boxes. Because we can have many classes to locate and classify, the mean Average Precision (mAP) is used to compute the accuracy for the entire dataset. The mAP value is commonly evaluated for IoU=0.5, and is denoted as "mAP@0.5."
We won’t go too deep into the theory of measurements of the object detection precision. We’ll just compare the three competing DL methods in terms of mAP@0.5: the higher this value is, the more precise is the model.
Search the Internet for precision values of the various Faster-RCNN, SSD, and YOLO models – and you will find a lot of drastically different results. This is because there are many pre-trained DNN models for each detection method. For example, the SSD technology can use the different CNN models for feature extraction, and each of these models can be trained with the different datasets: ImageNet, COCO, VOC, and others.
A complete comparison of all existing models’ precision metrics is not our goal. Our testing of the three methods with the same dataset showed that the best precision could be achieved with the Faster-RCNN method, slightly lower precision – with the SSD models, and the least precise results – with the YOLO network.
It appears that the faster the object detection method is, the less precision it provides. Thus we choose the happy medium – the SSD models, which can provide enough speed with sufficient precision.
Next, we looked for a ready-to-use SSD model that would be:
- Small enough to run on Raspberry Pi with its limited computing resources
- Trained to detect humans (the model may be able to detect other classes of objects as well - but its human detection accuracy is what matters for the application we’re creating)
We’ve found two suitable SSD models. The first one was based on the MobileNet CNN, and the second used a pre-trained SqueezeNet as the feature extractor. Both models have been trained using the COCO dataset and could detect objects of twenty different classes, including humans, cars, dogs, and others. Each model was about 20 MB in size – very small compared to the common size of 200-500 MB for models used on high-performance processors. So these two looked like the right choice for our purposes.
Next Steps
In the next article, we’ll showcase the Python code for launching these models and detect humans in images.

