Here we’ll adapt our code for detecting persons in video streams.
From the previous articles in this series, we have the Python code for detecting humans in images using SSD DNN models. And we’ve shown that this code can be launched on a Raspberry Pi device. In this article, we’ll adapt our code for detecting persons in video streams.
We’ll use video files in the mp4 format as our video "stream" data. It is the simplest way of testing the detection algorithm. First of all, we can use data from any camera – or download a video clip from the Internet. Second, we can repeat the experiment with the same input data multiple times, which is an important aspect of the testing. The Raspberry Pi device features a camera module, and we could use it for testing the detection algorithm on a live video stream. However, it would be almost impossible to test the algorithm multiple times under the same conditions because it is very hard to exactly repeat a scene for the live camera.
We already have some utility classes for handling Caffe DNN models, processing images, and drawing detections on them. Also, have the main class, SSD, which receives a frame (image) and detects persons in it. Now, using the existing code, let’s write a new Python class for video processing:
class VideoSSD:
def __init__(self, ssd):
self.ssd = ssd
def detect(self, video, class_num, min_confidence):
detection_num = 0;
fps = FPS()
capture = cv2.VideoCapture(video)
while(True):
(ret, frame) = capture.read()
if frame is None:
break
fps.start()
obj_data = self.ssd.detect(frame)
persons = self.ssd.get_objects(frame, obj_data, class_num, min_confidence)
fps.stop()
p_count = len(persons)
detection_num += p_count
if len(persons)>0:
Utils.draw_objects(persons, "PERSON", (0, 0, 255), frame)
cv2.imshow('Person detection',frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
capture.release()
cv2.destroyAllWindows()
f = fps.fps()
return (detection_num, f)
The VideoSSD class is initialized with an instance of the SSD class, which is used in the video processor for person detection. The main detect method has three input arguments: video – a full path to the video file, class_num – the class number to detect, and min_confidence - the threshold of the class detection. In this method, we first initialize the fps object for performance evaluation and create VideoCapture from the cv2 module. Then we loop over all the frames in the video stream, detect persons in each of the frames, count all the detected persons, and calculate the performance. The code can be modified for use with a live camera instead of a video file. All you need to do is modify the initialization of cv2.VideoCapture for the appropriate parameters.
The detect method returns a tuple that contains the total number of the detected persons and the average FPS. Note that we do not save the frames with the detected persons to a file (the way we did for the detections in images). We just draw the detections in the frames and show them in the GUI window by calling the cv2.imshow method. So we’ll see the detections on the screen.
Now let’s write the code for detecting persons in a video file:
proto_file = r"/home/pi/Desktop/PI_RPD/mobilenet.prototxt"
model_file = r"/home/pi/Desktop/PI_RPD/mobilenet.caffemodel"
ssd_net = CaffeModelLoader.load(proto_file, model_file)
print("Caffe model loaded from: "+model_file)
proc_frame_size = 300
ssd_proc = FrameProcessor(proc_frame_size, 1.0/127.5, 127.5)
person_class = 15
ssd = SSD(ssd_proc, ssd_net)
video_file = r"/home/pi/Desktop/PI_RPD/video/person_1.mp4"
video_ssd = VideoSSD(ssd)
(detections, fps) = video_ssd.detect(video_file, person_class, 0.5)
print ("Detection count:"+str(detections))
print ("FPS:"+str(fps))
Running the above code on the Raspberry Pi 3B device against a test video, we get the following results: the total detection count is 54; the average FPS is about 1.27.
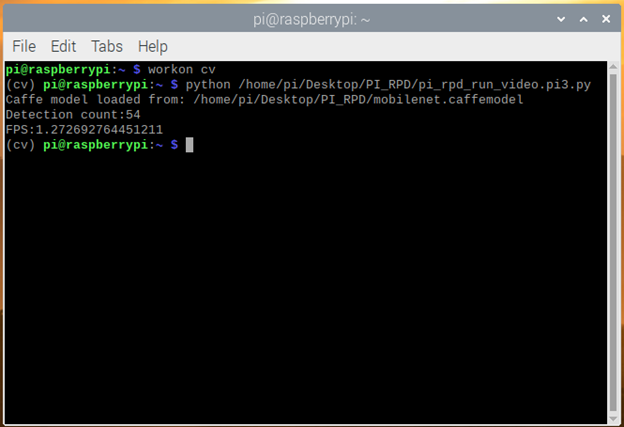
While running the program, we see the GUI window with detections of the persons. Here is the saved screen video:
As you can see from the video, detections are very slow because the processing unit needs about 0.8 seconds per frame. That’s the same performance we benchmarked while processing still images… but it looks slow for video processing.
At this point, we should ask ourselves if it is enough to process one frame in 0.8 seconds to realize a real-time person detection. The answer depends on the detection purpose. If the goal is to count all the customers who had entered a shopping center, the answer is "No." But if we are developing a video surveillance system, and the goal is to just inform the operator of an intruder appearance, the answer would be "Yes." Let’s note that on our test video, each person appears for several seconds. If we can process one frame in a second, we can detect the person’s appearance with a high probability.
Looks like we can use the AI models for detecting a person’s appearance on live cameras. However, our person detection code is not geared for real-time, because it processes all the frames, which makes it slow.
Next Steps
In the next article, we’ll modify the code for real-time processing on an edge device.

