Here we will try to overcome the limitations imposed by R-CNN and will also get an estimate of the number of people present in an area.
Previously, we implemented R-CNN for object detection. Although these object detection algorithms work well when detecting faces, they do not work well when the target objects are not clearly visible. Moreover, since it uses the sliding window technique, the search becomes exhaustive and hurts performance. In this article, we will learn to implement deep neural networks to estimate the number of people in a crowd or a line using density mapping.
We will use the ShangaiTech dataset. The dataset has two parts. For this article, we’ll only be working with part B to train our model for crowds and then test it on our custom dataset. You can choose to work with either of the parts; the code will work fine with either one.
Let’s start by importing the required libraries.
import os
import cv2
import csv
import math
import random
import numpy as np
from scipy.io import loadmat
from keras import backend as K
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from keras.callbacks import ModelCheckpoint
from keras.models import load_model, load_model, Model
from keras.layers import Conv2D, MaxPooling2D, Concatenate, Input
Preprocessing the Input Data
Our dataset contains two subdirectories: test_data and train_data. Both directories contain images along with their corresponding ground truths. We can’t use the data in its raw format, so we’ll have to do some pre-processing. Since we’ll be using the counting-by-density CNN approach, we need ground-truth data to be a density map too. Here, we’ll try to compute ground-truth density maps from given ground-truth files.
Let’s first define our function for generating density maps for input images.
def get_density_map(image, points):
image_density = np.zeros_like(image, dtype=np.float64)
height, width = image_density.shape
if points is None:
return image_density
if points.shape[0] == 1:
x1 = max(0, min(width-1, round(points[0, 0])))
y1 = max(0, min(height-1, round(points[0, 1])))
image_density[y1, x1] = 255
return image_density
for j in range(points.shape[0]):
frame_size = 15
sigma = 4.0
Height = np.multiply(cv2.getGaussianKernel(frame_size, sigma), (cv2.getGaussianKernel(frame_size, sigma)).T)
x = min(width-1, max(0, abs(int(math.floor(points[j, 0])))))
y = min(height-1, max(0, abs(int(math.floor(points[j, 1])))))
if x >= width or y >= height:
continue
x1 = x - frame_size//2 + 0
y1 = y - frame_size//2 + 0
x2 = x + frame_size//2 + 1
y2 = y + frame_size//2 + 1
dfx1, dfy1, dfx2, dfy2 = 0, 0, 0, 0
change_Height = False
if x1 < 0:
dfx1 = abs(x1) + 0
x1 = 0
change_Height = True
if y1 < 0:
dfy1 = abs(y1) + 0
y1 = 0
change_Height = True
if x2 > width:
dfx2 = x2 - width
x2 = width
change_Height = True
if y2 > height:
dfy2 = y2 - height
y2 = height
change_Height = True
x1h, y1h, x2h, y2h = 1 + dfx1, 1 + dfy1, frame_size - dfx2, frame_size - dfy2
if change_Height is True:
Height = np.multiply(cv2.getGaussianKernel(y2h-y1h+1, sigma), (cv2.getGaussianKernel(x2h-x1h+1, sigma)).T)
image_density[y1:y2, x1:x2] += Height
return image_density
Now we’re in a position to create our testing and validation data. Specify the directories of the input image files, input ground truth files, testing and validation images, and label and output paths.
input_images_path = ''.join(['./ShanghaiTech/part_B/train_data/images/'])
output_path = './ShanghaiTech/processed_trainval/'
training_images_path = ''.join((output_path, '/training_images/'))
training_densities_path = ''.join((output_path, '/training_densities/'))
validation_images_path = ''.join((output_path, '/validation_images/'))
validation_densities_path = ''.join((output_path, '/valalidation_densities/'))
ground_truth_path = ''.join(['./ShanghaiTech/part_B/train_data/ground-truth/'])
for i in [output_path, training_images_path, training_densities_path, validation_images_path, validation_densities_path]:
if not os.path.exists(i):
os.makedirs(i)
Now we’ll iterate over all the training images and compute their density map. We will use ground truth files to compute the density map for each image file separately and save it as a corresponding csv file.
seed = 95461354
random.seed(seed)
n = 400
val_test_num = math.ceil(n*0.1)
indices = list(range(1, n+1))
random.shuffle(indices)
for idx in range(1, n+1):
i = indices[idx-1]
image_info = loadmat(''.join((ground_truth_path, 'GT_IMG_', str(i), '.mat')))['image_info']
input_image = ''.join((input_images_path, 'IMG_',str(i), '.jpg'))
img = cv2.imread(input_image, 0)
height, width = img.shape
new_width, new_height = width / 8, height / 8
new_width, new_height = int(new_width / 8) * 8, int(new_height / 8) * 8
annotation_Points = image_info[0][0][0][0][0] - 1
if width <= new_width * 2:
img = cv2.resize(img, [h, new_width*2+1], interpolation=cv2.INTER_LANCZOS4)
annotation_Points[:, 0] = annotation_Points[:, 0] * 2 * new_width / width
if height <= new_height * 2:
img = cv2.resize(img, [new_height*2+1, w], interpolation=cv2.INTER_LANCZOS4)
annotation_Points[:, 1] = annotation_Points[:,1] * 2 * new_height / height
height, width = img.shape
x_width, y_width = new_width + 1, width - new_width
x_height, y_height = new_height + 1, height - new_height
image_density = get_density_map(img, annotation_Points)
for j in range(1, 10):
x = math.floor((y_width - x_width) * random.random() + x_width)
y = math.floor((y_height - x_height) * random.random() + x_height)
x1, y1 = x - new_width, y - new_height
x2, y2 = x + new_width - 1, y + new_height - 1
base_image = im[y1-1:y2, x1-1:x2]
base_image_density = image_density[y1-1:y2, x1-1:x2]
base_image_annPoints = annotation_Points[
list(
set(np.where(np.squeeze(annotation_Points[:,0]) > x1)[0].tolist()) &
set(np.where(np.squeeze(annotation_Points[:,0]) < x2)[0].tolist()) &
set(np.where(np.squeeze(annotation_Points[:,1]) > y1)[0].tolist()) &
set(np.where(np.squeeze(annotation_Points[:,1]) < y2)[0].tolist())
)
]
base_image_annPoints[:, 0] = base_image_annPoints[:, 0] - x1
base_image_annPoints[:, 1] = base_image_annPoints[:, 1] - y1
img_idx = ''.join((str(i), '_',str(j)))
if idx < val_test_num:
cv2.imwrite(''.join([validation_images_path, img_idx, '.jpg']), base_image)
with open(''.join([validation_densities_path, img_idx, '.csv']), 'w', newline='') as output:
writer = csv.writer(output)
writer.writerows(base_image_density)
else:
cv2.imwrite(''.join([training_images_path, img_idx, '.jpg']), base_image)
with open(''.join([training_densities_path, img_idx, '.csv']), 'w', newline='') as output:
writer = csv.writer(output)
writer.writerows(base_image_density)
print("Successfully processed files!")
Following the same pattern, we need to process our testing data as well.
images_path = ''.join(['./ShanghaiTech/part_B/test_data/images/'])
ground_truth_path = ''.join(['./ShanghaiTech/part_B/test_data/ground-truth/'])
ground_truth_csv = ''.join(['./ShanghaiTech/part_B/test_data/ground-truth_csv/'])
n = 316
for i in range(1, n+1):
image_info = loadmat(''.join((ground_truth_path, 'GT_IMG_', str(i), '.mat')))['image_info']
input_img = ''.join((images_path, 'IMG_', str(i), '.jpg'))
img = cv2.imread(input_img, 0)
annotationPoints = image_info[0][0][0][0][0] - 1
image_density = get_density_map(img, annotationPoints)
with open(''.join([ground_truth_csv, 'IMG_', str(i), '.csv']), 'w', newline='') as output:
writer = csv.writer(output)
writer.writerows(image_density)
print("Successfully processed files!")
Training the Model
Once the above step is completed, our data is ready and we can load it to train our model. We will now define a function that’ll load images and labels based on the data.
def x_y_generator(images_path, labels_path, batch_size=64):
break_point = 0
t = 0
images_path = np.squeeze(images_path).tolist() if isinstance(images_path, np.ndarray) else images_path
labels_path = np.squeeze(labels_path).tolist() if isinstance(labels_path, np.ndarray) else labels_path
data_length = len(labels_path)
while True:
if not break_point:
x = []
y = []
inner_iteration = batch_size
else:
t = 0
inner_iteration = batch_size - data_length % batch_size
for i in range(inner_iteration):
if t >= data_length:
break_point = 1
break
else:
break_point = 0
img = (cv2.imread(images_path[t], 0) - 127.5) / 128
density_map = np.loadtxt(labels_path[t], delimiter=',')
std = 4
quarter_den = np.zeros((np.asarray(density_map.shape).astype(int)//std).tolist())
for r in range(quarter_den.shape[0]):
for c in range(quarter_den.shape[1]):
quarter_den[r, c] = np.sum(density_map[r*std:(r+1)*std, c*std:(c+1)*std])
x.append(img.reshape(*img.shape, 1))
y.append(quarter_den.reshape(*quarter_den.shape, 1))
t += 1
if not break_point:
x, y = np.asarray(x), np.asarray(y)
yield x, y
We can use the function below to read our training, validation, and testing data.
train_generator = x_y_generator(train_paths, train_labels, batch_size=len(train_paths))
training_img, train_labels = train_generator.__next__()
validation_generator = x_y_generator(validation_paths, validation_labels, batch_size=len(validation_paths))
validating_img, validation_labels = validation_generator.__next__()
test_generator = x_y_generator(test_paths, test_labels, batch_size=len(test_paths))
testing_img, test_labels = test_generator.__next__()
Our data is ready, so we can now define our neural network. We’ll implement a multi-column convolutional neural network. It contains three columns of convolutional neural networks with different filter sizes. The idea is to feed an image as input to our neural network and get a density map with the overall crowd count as output. Since the three columns correspond to different filter sizes, the features learned by each CNN column are adaptive to variations in people’s sizes and can be easily used in crowded places or queues.
def Multi_Column_CNN(input_shape=None):
inputs = Input(shape=input_shape)
conv_1 = Conv2D(16, (9, 9), padding='same', activation='relu')(inputs)
conv_1 = MaxPooling2D(2)(conv_1)
conv_1 = (conv_1)
conv_1 = Conv2D(32, (7, 7), padding='same', activation='relu')(conv_1)
conv_1 = MaxPooling2D(2)(conv_1)
conv_1 = Conv2D(16, (7, 7), padding='same', activation='relu')(conv_1)
conv_1 = Conv2D(8, (7, 7), padding='same', activation='relu')(conv_1)
conv_2 = Conv2D(20, (7, 7), padding='same', activation='relu')(inputs)
conv_2 = MaxPooling2D(2)(conv_2)
conv_2 = (conv_2)
conv_2 = Conv2D(40, (5, 5), padding='same', activation='relu')(conv_2)
conv_2 = MaxPooling2D(2)(conv_2)
conv_2 = Conv2D(20, (5, 5), padding='same', activation='relu')(conv_2)
conv_2 = Conv2D(10, (5, 5), padding='same', activation='relu')(conv_2)
conv_3 = Conv2D(24, (5, 5), padding='same', activation='relu')(inputs)
conv_3 = MaxPooling2D(2)(conv_3)
conv_3 = (conv_3)
conv_3 = Conv2D(48, (3, 3), padding='same', activation='relu')(conv_3)
conv_3 = MaxPooling2D(2)(conv_3)
conv_3 = Conv2D(24, (3, 3), padding='same', activation='relu')(conv_3)
conv_3 = Conv2D(12, (3, 3), padding='same', activation='relu')(conv_3)
conv_merge = Concatenate(axis=-1)([conv_1, conv_2, conv_3])
density_map = Conv2D(1, (1, 1), padding='same')(conv_merge)
model = Model(inputs=inputs, outputs=density_map)
return model
With our model in place, let’s also define metrics to measure the performance of our model. We will use Standard Mean Squared Error and Mean Absolute Error.
def mean_absolute_error(labels, predictions):
return K.sum(K.abs(labels - predictions)) / 1
def mean_square_error(labels, predictions):
return K.sum(K.square(labels - predictions)) / 1
Let’s now train our model. We’ll also use ModelCheckpoint from Keras to save the computational resources and only save the best model for both training and validation.
best_validation = ModelCheckpoint(
filepath= 'mcnn_val.hdf5', monitor='val_loss', verbose=1, save_best_only=True, mode='min'
)
best_training = ModelCheckpoint(
filepath= 'mcnn_train.hdf5', monitor='loss', verbose=1, save_best_only=True, mode='min'
)
input_shape = (None, None, 1)
model = Multi_Column_CNN(input_shape)
model.compile(loss='mean_squared_error', optimizer='adam', metrics=[mean_absolute_error, mean_square_error])
history = model.fit(
x=training_img, y=train_labels, batch_size=1, epochs=100,
validation_data=(validating_img, validation_labels),
callbacks=[best_validation, best_training]
)
The amount of time it takes the model to train depends on the resources you are using. Once the model is trained, you can move on to testing.
Testing the Model
As a basic level of testing, we can plot the loss over our training data and validation data.
val_loss, loss = history.history['val_loss'], history.history['loss']
loss = np.asarray(loss)
plt.plot(loss, 'b')
plt.legend(['loss'])
plt.show()
plt.plot(val_loss, 'r')
plt.legend(['val_loss'])
plt.show()
Our trained model shows the following loss plots:
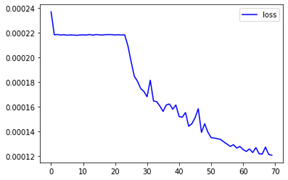

Loss charts look fine, but let’s get the predictions on the images to see if our model can count the number of people in the image accurately.
from keras import models
model = models.load_model('./ShanghaiTech/part_B/weights/mcnn_val.hdf5', custom_objects={'mean_absolute_error': mean_absolute_error, 'mean_square_error': mean_square_error })
absolute_error = []
squared_error = []
num_test = 50
for i in range(testing_img.shape[0])[:num_test]:
inputs = np.reshape(testing_img[i], [1, *testing_img[i].shape[:2], 1])
outputs = np.squeeze(model.predict(inputs))
density_map = np.squeeze(test_labels[i])
count = np.sum(density_map)
prediction = np.sum(outputs)
fg, (ax0, ax1) = plt.subplots(1, 2, figsize=(16, 5))
plt.suptitle(' '.join([
'count:', str(round(count, 2)),
'prediction:', str(round(prediction, 2))
]))
ax0.imshow(np.squeeze(inputs))
ax1.imshow(density_map * (255 / (np.max(density_map) - np.min(density_map))))
plt.show()
absolute_error.append(abs(count - prediction))
square_error.append((count - prediction) ** 2)
mean_absolute_error = np.mean(absolute_error)
mean_square_error = np.mean(square_error)
print('mean_absolute_error:', mean_absolute_error, 'mean_square_error:', mean_square_error)
And here are a few of the (good) predicted results:
Our model is doing fine at this stage, but how does it perform with counting people in queues? There’s no open source dataset available to train and test the model specifically for queue length, so we’ll need to generate our very own dataset.
Creating a Custom Dataset for Queue Length
Remembering the basics, we just need some images along with their corresponding ground truths for the dataset. We can simply collect the images from Google search. No big deal, right? But how do we generate ground truth files? There are various tools available to annotate the images, including web-based boundary-box annotators, head-annotators, or some specialized tools provided by cloud vendors, such as AWS SageMaker. You can choose whichever one you want to generate ground truth files. I’ll stick to the very basics here and generate the ground truths using MATLAB. In order to generate ground truth files using MATLAB, save your images in a directory called “images” and run the following script:
filePath = fullfile('images', '/*.jpg');
ImageFiles = dir(filePath);
n = length(ImageFiles)
read_images_path = 'images/';
store_gt_path = 'ground-truth/';
t = 0; %number of files initially in training set
for i=1:n
img = imread([read_path 'IMG_' num2str(i+t) '.jpg']);
img = imresize(im, [768 1024]);
imwrite(img,[read_images_path 'IMG_' num2str(i+t) '.jpg'], 'jpg');
figure
imshow(img)
[x,y] = getpts;
image_info{1,1}.location = [x y];
image_info{1,1}.number = size(x,1);
save([store_gt_path 'GT_IMG_' num2str(t+i) '.mat'], 'image_info')
close
end
When the scripts run, it will iterate over all the images in the images directory and show them on screen one at a time. When an image is displayed, click on the person’s head in the image, then press Enter to move on to the next image.
Testing on a Custom Dataset
Once you have your dataset ready, load your trained model and test it. Here are few results I obtained after testing:
Our model is doing fine. Please note here that these are some of the ‘good’ results. Your results might be a little different.
What’s Next?
In this article, we learned to estimate the number of people present in an image. You might come across some very bad results as well, but I’ll leave the fine tuning of the model to you. Moreover, the density map obtained here can be further fed into a fully connected network to get a more accurate prediction for the number of people in a lineup.
In the next article of this series, we will compare training our models from scratch with more advanced and pre-trained approaches like YOLO.

