This article demonstrates efficient techniques for fast Oracle Database access using both ODP.NET with .NET 5.0 and the Oracle Call Interface (OCI) from native C++.
Introduction
The ability to efficiently create, retrieve, update and delete data in a database from a client or server application is often the most performance critical part of a solution, and according to DB-Engines.com, the Oracle Database is the most popular database server in the world.
The Oracle Database server is widely used by companies in the:
- Electric utility industry
- Oil and gas industry
- Finance and investment industry
I believe the primary reasons for Oracle's popularity are:
- Reliability
- Capacity
- Flexibility
- Performance
The first three points are something you get out of the box, while the fourth is something that can prove to be somewhat elusive.
Imagine that your task is to create a real-time analytics application for the stock market, and that the traders will make decisions that will make or break the company based on the timely results provided by your application.
The total number of trades on Nasdaq for December the 1st was 30 910 548, and most of those trades where probably made in the hour after the market opened or in the hour before closing time. Large volumes of trades are probably made in bursts of activity, so this is something your solution is required to handle gracefully too.
A typical .NET application, inserting one row at the time, can insert about 3 500 rows per second, which is far less than what is requires from your solution. While getting the data into the database is quite important, it is the algorithms that will be applied to the data that is the real purpose of your solution. Anything that goes into the database will be read thousands of times – and everything must be executed as fast as possible to have a practical value for the trading desk.
This article will demonstrate how to insert more than 1 200 000 rows per second into an Oracle database, and how to read more than 3 600 000 rows per second – without any changes to the database. How you communicate with the Oracle database really matters when it comes to performance.
I will explain how to use the Oracle Call Interface to
- perform basic create, retrieve, update, and delete (CRUD) operations with optimistic locking,
- bind data to variables in SQL statements,
- pass input data efficiently,
- process query results efficiently,
- insert 100 000 000 rows into a table using a single database call, and
- update 100 000 000 rows in a table using a single database call
The article also demonstrates how ODP.Net can be used with .NET 5.0 to perform many of the same operations. ODP.Net can be used to implement almost anything that can be implemented using OCI, but OCI always outperforms ODP.Net. Performance can sometimes be crucial to the success of an application, and for cloud-based deployment, it has a huge impact on the cost of day-to-day operations. The article will explain how to use ODP.Net to
- perform basic create, retrieve, update, and delete (CRUD) operations with optimistic locking,
- bind data to variables in SQL statements,
- pass input data efficiently,
- insert 1 000 000 rows into a table using a single database call, and
- update 1 000 000 rows in a table using a single database call
The Oracle Call Interface (OCI) is an API for creating applications in C or C++ that interact with the Oracle database. By using the OCI API, we get access to the full range of database operations that are possible with Oracle Database, including SQL statement processing and object manipulation.
The Oracle Call Interface provides significant advantages over other methods for accessing an Oracle Database:
- More fine-grained control over all aspects of application design and program execution
- Faster connection pooling, session pooling, and statement caching that enable development of cost-effective and highly scalable applications
- Executes dynamic SQL more efficiently
- Dynamic binding and defining using callbacks functions
- Extensive description functionality to expose the layers of server metadata
- Efficient asynchronous event notification for registered client applications
- Enhanced array data manipulation language (DML) capability for array inserts, updates, and deletes
- Optimization of queries using transparent prefetch buffers to reduce roundtrips
- Ability to associate commit requests with executes to reduce server roundtrips
- Data type mapping and manipulation functions, for manipulating data attributes of Oracle types
- Data loading functions, for loading data directly into the database without using SQL statements
- External procedure functions, for writing C callbacks from PL/SQL
According to Oracle:
Oracle Call Interface (OCI) is the comprehensive, high performance, native C language interface to Oracle Database for custom or packaged applications.
OCI is highly reliable. Oracle tools such as SQL*Plus, Real Application Testing (RAT), SQL*Loader, and Data-Pump all use OCI. OCI provides the foundation on which other language-specific interfaces such as Oracle JDBC-OCI, Oracle Data Provider for Net (ODP.Net), Oracle Precompilers, Oracle ODBC, and Oracle C++ Call Interface (OCCI) drivers are built. OCI is also used by leading scripting language drivers such as node-oracledb for Node.js, PHP OCI8, ruby-oci8, Perl DBD::Oracle, Python cx_Oracle, and the statistical programming language R's ROracle driver.
To make it easier to work with the Oracle Call Interface (OCI) API, I have written the Harlinn.OCI C++ library which is packaged as a windows DLL.
Building the Code
Instructions for building the code are provided in Build.md located in the $(SolutionDir)Readme folder.
Harlinn.OCI
The primary advantage of using the Oracle Call Interface and C++ is performance. This advantage is not something you will get just because you are using C++ and OCI, it is something you may achieve through a well-reasoned design. With the Harlinn.OCI library, I try to achieve two goals:
- Ease of use
- Fine-grained control of how data is exchanged with the Oracle RDBMS through the Oracle Call Interface. This can make a huge difference in the performance of your OCI client application.
Ease of Use
Using C# and ODP.Net, we can easily connect to an Oracle RDBMS:
static void Main(string[] args)
{
var connectionString = GetConnectionString(args);
var connection = new OracleConnection(connectionString);
using (connection)
{
connection.Open();
using (var command = connection.CreateCommand())
{
command.CommandText = "SELECT * FROM ALL_USERS";
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
var userName = reader.GetString(0);
Console.Out.WriteLine(userName);
}
}
}
}
}
Harlinn.OCI provides an API that you will find as easy to use as ODP.Net:
EnvironmentOptions options;
Environment environment( options );
auto server = environment.CreateServer( );
auto serviceContext = server.CreateServiceContext( Username, Password, Alias );
serviceContext.SessionBegin( );
std::wstring sql =
L"SELECT * FROM ALL_USERS";
auto statement = serviceContext.CreateStatement( sql );
auto reader = statement.ExecuteReader<DataReader>( );
while ( reader->Read( ) )
{
auto userName = reader->As<std::wstring>( 0 );
auto userId = reader->As<Int64>( 1 );
auto created = reader->As<DateTime>( 2 );
}
serviceContext.SessionEnd( );
Calling a server-side function:
std::wstring sql =
L"BEGIN"\
L" :result := SYSTIMESTAMP();" \
L"END;";
auto statement = serviceContext.CreateStatement( sql );
auto result = statement.Bind<DateTime>( 1 );
statement.Execute( 1 );
auto dateTime = result->As<DateTime>( );
or inserting a row:
std::optional<std::wstring> description;
if ( ownedObjectType.Description( ).length( ) )
{
description = ownedObjectType.Description( );
}
constexpr wchar_t SQL[] = L"INSERT INTO OwnedObjectType(Id, Name, OptimisticLock, "
L"Created, Description) "\
L"VALUES(:1,:2,0,:3,:4)";
static std::wstring sql( SQL );
auto statement = serviceContext_.CreateStatement( sql,
ownedObjectType.Id( ),
ownedObjectType.Name( ),
ownedObjectType.Created( ),
description );
statement.Execute( );
are all operations that can be easily implemented with the library. Harlinn.OCI implements a thin, yet feature rich, layer around the OCI C API.
Harlinn.OCI depends on the Harlinn.Common.Core library, for implementations of basic datatypes such as Guid, DateTime and TimeSpan.
Create, Retrieve, Update and Delete (CRUD)
Basic CRUD is the heart and soul of many applications, and this is a simple, yet typical, table:
CREATE TABLE SimpleTest1
(
Id NUMBER(19) NOT NULL,
OptimisticLock NUMBER(19) DEFAULT 0 NOT NULL,
Name NVARCHAR2(128) NOT NULL,
Description NVARCHAR2(1024),
CONSTRAINT PK_SimpleTest1 PRIMARY KEY(Id),
CONSTRAINT UNQ_SimpleTest1 UNIQUE(Name)
);
Description:
- The
Id column is the primary key for the table, mandating that a unique value must be stored for each row in the table. - The
OptimisticLock column is used to implement optimistic locking, a widely used technique for guarding against inadvertent overwrites by multiple concurrent users. If an application can do the following:
User1 retrieves a row of data.User2 retrieves the same row of data.User2 updates column value and updates the row in the database.User1 updates the same column value and updates the row in the database, overwriting the change made by User2.
then this is almost always a design bug.
- The
Name column provides an alternative key to the rows in the table. - The
Description column holds data that is of interest to the solution that uses the database to manage its data.
A numeric primary key is often generated using an Oracle database sequence object:
CREATE SEQUENCE SimpleTest1Seq;
This assures that unique keys will be created for concurrent inserts by multiple database client applications.
Optimistic Locking
Nearly all software solutions that use a database server to store data must be able to handle multiple concurrent sessions. At any point in time, you can expect multiple processes or users to retrieve and update the database. Since multiple processes or users are updating the information in the database, it is only a matter of time before two separate processes or users will try to update the same piece of data concurrently.
Optimistic Locking is a minimalistic strategy for preventing unintentional updates to a row based on a version number stored in one of the columns of the row. When the software attempts to update or delete a row, it is filtered on the version number to make sure the row has not been updated between time the row was retrieved from the database, and the update or delete. Updates must ensure that changes to the column for the version number are atomic.
It is called optimistic locking because it assumes that most updates and deletes will succeed; and when they do not, the software must be able to handle this appropriately.
How to correctly handle situations where the optimistic lock prevents an update, or a delete, depends on the use-case. An interactive solution may retrieve the updated row from the database and let the user decide whether to overwrite it or abandon her modifications, while an automated system may implement a more complex solution, or store the rejected update elsewhere for manual intervention. The important thing is to maintain consistency while making sure that information is not inadvertently lost.
Optimistic locking is particularly useful for high-volume solutions; and web, and other multitier-tier architectures where the software is unable to maintain a dedicated connection to the database on behalf of the user. In these situations, the client cannot maintain database locks as the connections are taken from a pool and the client may not be using the same connection from one server request to the next.
The main downside of optimistic locking is that it is row oriented, and many real-world solutions requires synchronization that goes beyond a single row.
Even when you end up using a more powerful lock management solution, optimistic locking will almost certainly help to uncover programming errors during development, deployment, and operation.
The alternative to optimistic locking in called pessimistic locking, it is not last write wins. Pessimistic locking requires an active system component that maintains the locks, such as table or row level locking implemented by the database server, or a dedicated distributed lock server. Database locks are usually tied to the database session but can also be under control of a distributed transaction manager.
The Oracle database provides the DBMS_LOCK package, which can be used to implement pessimistic locking. The maximum lifetime of a lock is limited to the lifetime of the session used to create it.
Basic CRUD using ODP.Net
Implementing basic CRUD using ODP.Net is a straightforward process, and the code illustrates how to implement optimistic locking using atomic operations in plain DML.
The full code is located under DotNet\Examples\ODP\Harlinn.Examples.ODP.Basics01.
Create
To insert a new record into the database, we must perform the following steps:
- Create an
OracleCommand object. - Assign an INSERT data manipulation language (DML) statement with variable placeholders to the
CommandText property of the OracleCommand object. - Create and Bind
OracleParameter objects to each of the variable placeholders. - Call the
ExecuteNonQuery() member function of the OracleCommand object to execute the DML statement on the database server.
The two first placeholders :1 and :2 are created for the Name and Description column, respectively; while the third placeholder is for the value of the Id column that will be generated by the call to SimpleTest1Seq.NextVal inside the DML as specified by the trailing ‘RETURNING Id INTO :3’. The OptimisticLock column gets assigned 0 marking this as the initial version of the row:
public SimpleTest1Data Insert(string name, string description = null)
{
using (var command = _connection.CreateCommand())
{
command.CommandText = "INSERT INTO SimpleTest1
(Id, OptimisticLock, Name, Description ) "
+ "VALUES(SimpleTest1Seq.NextVal,0,:1,:2) RETURNING Id INTO :3";
OracleParameter nameParameter = new OracleParameter();
nameParameter.OracleDbType = OracleDbType.NVarchar2;
nameParameter.Value = name;
OracleParameter descriptionParameter = new OracleParameter();
descriptionParameter.OracleDbType = OracleDbType.NVarchar2;
descriptionParameter.Value = string.IsNullOrWhiteSpace(description) ?
DBNull.Value : description;
OracleParameter idParameter = new OracleParameter();
idParameter.OracleDbType = OracleDbType.Int64;
command.Parameters.Add(nameParameter);
command.Parameters.Add(descriptionParameter);
command.Parameters.Add(idParameter);
command.ExecuteNonQuery();
var idValue = (OracleDecimal)idParameter.Value;
var result = new SimpleTest1Data(idValue.ToInt64(), name, description );
return result;
}
}
Retrieve
The steps for preparing an OracleCommand object for retrieving the data for a particular row is nearly identical to those for we used to insert a new record, except that this time, we must
- assign a structured query language (SQL) statement with a single variable placeholder to the
CommandText property of the OracleCommand object. - bind the value for the
:1 placeholder in the WHERE clause to the value of the Id column for the row we are looking for. - call
ExecuteReader(…) on the OracleCommand object to execute the query on the database server. The query results are made available to the client application through the OracleDataReader object returned by ExecuteReader(…).
Since we already know the value of the Id column, we only ask for the OptimisticLock, Name and Description columns. The value of the Id column is guaranteed to uniquely identify a single row in the SimpleTest1 table, so we only execute reader.Read() once, and if it returns true, we know that the query was able to locate the requested row. The OptimisticLock and Name columns cannot be NULL, while the Description column can – which we check by calling IsDBNull. Each column for the current row is identified by its 0 based offset into the select-list:
public SimpleTest1Data Select(long id)
{
using (var command = _connection.CreateCommand())
{
command.CommandText = "SELECT OptimisticLock, Name, Description FROM SimpleTest1 "+
"WHERE Id = :1";
OracleParameter idParameter = new OracleParameter();
idParameter.OracleDbType = OracleDbType.Int64;
idParameter.Value = id;
command.Parameters.Add(idParameter);
using (var reader = command.ExecuteReader(System.Data.CommandBehavior.SingleRow))
{
if (reader.Read())
{
var optimisticLock = reader.GetInt64(0);
var name = reader.GetString(1);
string description = null;
if (reader.IsDBNull(2) == false)
{
description = reader.GetString(2);
}
var result = new SimpleTest1Data(id, optimisticLock, name, description);
return result;
}
else
{
return null;
}
}
}
}
Update
Again, we use an OracleCommand object, assigning an UPDATE DML statement to the CommandText property. This time, the variable placeholders are only for input variables.
The row is not updated unless the Id column matches the value bound to the third variable placeholder and the OptimisticLock column matches the value bound to the fourth variable placeholder. This will prevent the DML from updating the row if it has been updated by another user or process; and as a side effect, we also know that the next value for the OptimisticLock column, after a successful update, will be the previous value incremented by 1.
The DML statement can at most update a single row in the SimpleTest1 table and since ExecuteNonQuery() returns the number of rows that was altered by the DML statement, we can safely assume that a return value greater than 0 means that the update succeeded, while 0 means that either the row is deleted or the value for the OptimisticLock column has been changed by another update:
public bool Update(SimpleTest1Data data)
{
using (var command = _connection.CreateCommand())
{
command.CommandText = "UPDATE SimpleTest1 "+
"SET OptimisticLock=OptimisticLock+1, Name=:1, Description=:2 "+
"WHERE Id=:3 AND OptimisticLock=:4";
var id = data.Id;
var optimisticLock = data.OptimisticLock;
var name = data.Name;
var description = data.Description;
OracleParameter nameParameter = new OracleParameter();
nameParameter.OracleDbType = OracleDbType.NVarchar2;
nameParameter.Value = name;
OracleParameter descriptionParameter = new OracleParameter();
descriptionParameter.OracleDbType = OracleDbType.NVarchar2;
descriptionParameter.Value = string.IsNullOrWhiteSpace(description) ?
DBNull.Value : description;
OracleParameter idParameter = new OracleParameter();
idParameter.OracleDbType = OracleDbType.Int64;
idParameter.Value = id;
OracleParameter optimisticLockParameter = new OracleParameter();
optimisticLockParameter.OracleDbType = OracleDbType.Int64;
optimisticLockParameter.Value = optimisticLock;
command.Parameters.Add(nameParameter);
command.Parameters.Add(descriptionParameter);
command.Parameters.Add(idParameter);
command.Parameters.Add(optimisticLockParameter);
if (command.ExecuteNonQuery() > 0)
{
data.OptimisticLock = optimisticLock + 1;
return true;
}
else
{
return false;
}
}
}
Delete
The logic behind the DELETE DML statement is nearly identical to the logic for updating a row:
public bool Delete(SimpleTest1Data data)
{
using (var command = _connection.CreateCommand())
{
command.CommandText = "DELETE FROM SimpleTest1 " +
"WHERE Id=:1 AND OptimisticLock=:2";
var id = data.Id;
var optimisticLock = data.OptimisticLock;
OracleParameter idParameter = new OracleParameter();
idParameter.OracleDbType = OracleDbType.Int64;
idParameter.Value = id;
OracleParameter optimisticLockParameter = new OracleParameter();
optimisticLockParameter.OracleDbType = OracleDbType.Int64;
optimisticLockParameter.Value = optimisticLock;
command.Parameters.Add(idParameter);
command.Parameters.Add(optimisticLockParameter);
if (command.ExecuteNonQuery() > 0)
{
return true;
}
else
{
return false;
}
}
}
A Simple Test
To put it all together, the example below creates a hundred rows in the database, retrieves the stored rows and verifies that they contain the expected data. Then it deletes a third of the rows, expecting each call to Delete(…) to return true – indicating a successful delete operation, before calling Delete(…) once more for the same objects. This time, expecting each call to return false, indicating that the row was already deleted by the first iteration over the objects.
public void Execute()
{
Clear();
var originalItems = new Dictionary<long, SimpleTest1Data>( );
int RowCount = 100;
using (var transaction = _connection.BeginTransaction())
{
for (int i = 0; i < RowCount; ++i)
{
var name = $"Name{i + 1}";
var description = i % 2 == 0 ? null : $"Description{i + 1}";
var data = Insert(name, description);
originalItems.Add(data.Id, data);
}
transaction.Commit();
}
var databaseItems = Select();
foreach (var entry in originalItems)
{
var originalItem = entry.Value;
if (databaseItems.ContainsKey(originalItem.Id))
{
var databaseItem = databaseItems[originalItem.Id];
if (originalItem.Equals(databaseItem) == false)
{
throw new Exception($"The original item {originalItem} "+
$"is not equal to the item {databaseItem} "+
"retrieved from the database.");
}
}
else
{
throw new Exception($"Did not retrieve {originalItem} from "+
"the database.");
}
}
using (var transaction = _connection.BeginTransaction())
{
foreach (var entry in originalItems)
{
var data = entry.Value;
if (string.IsNullOrWhiteSpace(data.Description))
{
data.Description = "Updated Description";
if (Update(data) == false)
{
var changedData = Select(data.Id);
if (changedData != null)
{
throw new Exception($"Unable to update {data}, the "+
$"row has been updated by another user {changedData}");
}
else
{
throw new Exception($"Unable to update {data}, the "+
$"row has been deleted by another user");
}
}
}
}
transaction.Commit();
}
int rowsToDeleteCount = RowCount/3;
var itemsToDelete = originalItems.Values.Take(rowsToDeleteCount).ToList();
using (var transaction = _connection.BeginTransaction())
{
foreach (var item in itemsToDelete)
{
if (Delete(item) == false)
{
throw new Exception($"Unable to delete {item}, the row has "
+"been deleted by another user");
}
}
transaction.Commit();
}
foreach (var item in itemsToDelete)
{
if ( Delete(item) )
{
throw new Exception($"It appears {item}, was not deleted");
}
}
}
Basic CRUD using Harlinn.OCI
Implementing basic CRUD using Harlinn.OCI is also a straightforward process, and the code again illustrates how to properly implement optimistic locking using atomic operations in plain DML.
The full code is located under Examples\OCI\HOCIBasics01.
Create
To insert a new record into the database, we must perform the following steps:
- Create an
OCI::Statement object by calling CreateStatement(…) on the service context. The first argument is the INSERT data manipulation language (DML) statement with variable placeholders for the Name, Description and finally the server generated value for the Id column. The second and third parameters are automatically bound to the two first variable placeholders. - Bind the third variable placeholder to a 64-bit integer, that will receive the server generated primary key, using an
Int64Bind object. - Call the
ExecuteNonQuery() member function of the OCI::Statement object to execute the DML statement on the database server.
The two first placeholders :1 and :2 are created for the Name and Description column, respectively; while the third placeholder is for the value of the Id column that will be generated by the call to SimpleTest1Seq.NextVal inside the DML as specified by the trailing ‘RETURNING Id INTO :3’. The OptimisticLock column gets assigned 0 marking this as the initial version of the row:
std::unique_ptr<SimpleTestData> Insert( const std::wstring& name,
const std::wstring& description = std::wstring( ) ) const
{
auto& serviceContext = ServiceContext( );
std::optional<std::wstring> descr;
if ( description.size( ) )
{
descr = description;
}
constexpr wchar_t sql[] =
L"INSERT INTO SimpleTest1(Id, OptimisticLock, Name, Description ) "
L"VALUES(SimpleTest1Seq.NextVal,0,:1,:2) RETURNING Id INTO :3";
auto statement = serviceContext.CreateStatement( sql, name, descr );
auto* idBind = statement.Bind<Int64>( 3 );
auto transaction = serviceContext.BeginTransaction( );
statement.ExecuteNonQuery( );
transaction.Commit( );
auto id = idBind->AsInt64( );
return std::make_unique<SimpleTestData>( id, 0, name, description );
}
Retrieve
The steps for preparing an OCI::Statement object for retrieving the data for a particular row are nearly identical to those used to insert a new record, except that this time, we must
- pass the structured query language (SQL) statement with a single variable placeholder as the first parameter to the
CreateStatement(…) function, and the value to assign to this placeholder as the second argument. - call ExecuteReader on the
OCI::Statement object to execute the query on the database server. ExecuteReader returns an OCI::DataReader of the specified type that provides access to the query results.
Since we already know the value of the Id column, we only ask for the OptimisticLock, Name and Description columns. The value of the Id column is guaranteed to uniquely identify a single row in the SimpleTest1 table, so we only execute reader->Read() once, and if it returns true, we know that the query was able to locate the requested row. The OptimisticLock and Name columns cannot be NULL, while the Description column can – which we check by calling IsDBNull. Each column for the current row is identified by its 0 based offset into the select-list:
std::unique_ptr<SimpleTestData> Select( Int64 id ) const
{
auto& serviceContext = ServiceContext( );
constexpr wchar_t sql[] =
L"SELECT OptimisticLock, Name, Description FROM SimpleTest1 "
L"WHERE Id = :1";
auto statement = serviceContext.CreateStatement( sql, id );
auto reader = statement.ExecuteReader<OCI::DataReader>( );
if ( reader->Read( ) )
{
auto optimisticLock = reader->GetInt64( 0 );
auto name = reader->GetString( 1 );
std::wstring description;
if ( reader->IsDBNull( 2 ) == false )
{
description = reader->GetString( 2 );
}
return std::make_unique<SimpleTestData>( id, optimisticLock,
name, description );
}
else
{
return nullptr;
}
}
Update
Again, we use an OCI::Statement object, passing an UPDATE DML statement as the first parameter to the CreateStatement(…) function. This time, the variable placeholders are only for input variables and the variables holding the values are passed as the additional arguments.
The row is not updated unless the Id column matches the value bound to the third variable placeholder and the OptimisticLock column matches the value bound to the fourth variable placeholder. This will prevent the DML from updating the row if it has been updated by another user or process; and as a side effect, we also know that the next value for the OptimisticLock column, after a successful update, will be the previous value incremented by 1.
The DML statement can at most update a single row in the SimpleTest1 table and since ExecuteNonQuery() returns the number of rows that was altered by the DML statement, we can safely assume that a return value greater than 0 means that the update succeeded, while 0 means that either the row is deleted or the value for the OptimisticLock column has been changed by another update:
bool Update( SimpleTestData& data )
{
auto id = data.Id();
auto optimisticLock = data.OptimisticLock();
auto& name = data.Name();
auto& description = data.Description();
auto& serviceContext = ServiceContext( );
std::optional<std::wstring> descr;
if ( description.size( ) )
{
descr = description;
}
constexpr wchar_t sql[] = L"UPDATE SimpleTest1 "
L"SET OptimisticLock=OptimisticLock+1, Name=:1, Description=:2 "
L"WHERE Id=:3 AND OptimisticLock=:4";
auto statement = serviceContext.CreateStatement( sql, name, descr,
id, optimisticLock );
if ( statement.ExecuteNonQuery( ) > 0 )
{
data.SetOptimisticLock( optimisticLock + 1 );
return true;
}
else
{
return false;
}
}
Delete
The logic behind the DELETE DML statement is nearly identical to the logic for updating a row:
bool Delete( const SimpleTestData& data )
{
auto id = data.Id( );
auto optimisticLock = data.OptimisticLock( );
auto& serviceContext = ServiceContext( );
constexpr wchar_t sql[] = L"DELETE FROM SimpleTest1 "
L"WHERE Id=:1 AND OptimisticLock=:2";
auto statement = serviceContext.CreateStatement( sql, id, optimisticLock );
if ( statement.ExecuteNonQuery( ) > 0 )
{
return true;
}
else
{
return false;
}
}
OCI Program Initialization
Just about every operation that can be done using OCI is performed through handles to OCI resources. Each application that uses OCI must create a handle to an OCI environment, defining a context for executing OCI functions. The environment handle establishes a memory cache for fast memory access, and all memory used by the environment comes from this cache.
Environment
The Environment class provides access to the functionality of the OCI environment handle.
OCI applications use an error handle as a conduit for error information between the client application and the API, and the ErrorHandle class provides access to the functionality for this handle type.
Creating an Environment is the first step performed when creating and application using the Harlinn.OCI library:
EnvironmentOptions options;
Environment environment( options );
The Environment constructor calls CreateEnvironment( ) which creates the handle for the object.
void* Environment::CreateEnvironment( )
{
void* handle = nullptr;
auto rc = OCIEnvCreate( (OCIEnv**)&handle,
(UInt32)DefaultEnvironmentMode( ),
nullptr, nullptr, nullptr, nullptr, (size_t)0, (dvoid**)0 );
if ( rc < OCI::Result::Success )
{
ThrowOracleExceptionOnError( handle, rc );
}
return handle;
}
ErrorHandle
Once the Environment object has a valid handle, it creates an ErrorHandle object that is used for all error handling, except for calls to OCIHandleAlloc, related to this Environment object.
OCI::ErrorHandle Environment::CreateError( ) const
{
void* errorHandle = nullptr;
auto rc = OCIHandleAlloc( (dvoid*)Handle( ),
(dvoid**)&errorHandle,
OCI_HTYPE_ERROR, 0, (dvoid**)0 );
if ( rc < OCI_SUCCESS )
{
ThrowOracleExceptionOnError( Handle( ), rc );
}
return OCI::ErrorHandle( *this, errorHandle, true );
}
ServiceContext, Server and Session
Next, we need to establish a handle to the service context that is required for most operational calls through OCI.
The service context handle contains three handles, representing the server connection, the user session, and the transaction:
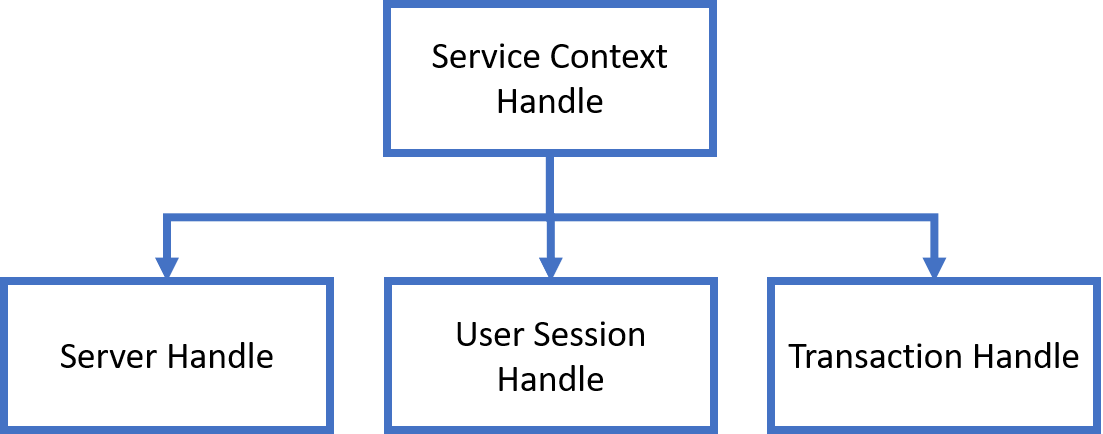
- The server handle represents a physical connection in a connection-oriented transport mechanism between the client and the database server.
- The user session defines the roles and privileges of the user.
- The transaction handle represents the transaction context used to perform operations against the server. This includes user session state information, including fetch state and package instantiation.
To establish a service context handle that can be used to execute SQL statement against an Oracle database, we need to perform a number of steps:
- Allocate a sever handle using
OCIHandleAlloc - Initialize the server handle using
OCIServerAttach - Allocate the service context handle using
OCIHandleAlloc - Assign the server handle to the service context handle using
OCIAttrSet - Allocate the user session handle using
OCIHandleAlloc - Assign the user session handle to the service context using
OCIAttrSet - Assign the user name to the user session using
OCIAttrSet - Assign the password to the user session using
OCIAttrSet - Initialize the service context using
OCISessionBegin
Harlinn.OCI simplifies this to:
auto server = environment.CreateServer( );
auto serviceContext = server.CreateServiceContext( Username, Password, Alias );
serviceContext.SessionBegin( );
But also allows each step to be performed separately:
auto server = environment.CreateServer( );
server.Attach( Alias );
auto serviceContext = environment.CreateServiceContext( );
serviceContext.SetServer( server );
auto session = environment.CreateSession( );
serviceContext.SetSession( std::move( session ) );
session.SetUserName( Username );
session.SetPassword( Password );
serviceContext.SessionBegin( );
This is useful when you need better control of how you want to configure the options for the various handle types provided by OCI.
Executing SQL against the Oracle Database
Now, that we have established a valid service context, we are ready to execute SQL statements against the Oracle database. To execute a SQL statement using OCI, the client application performs the following steps:
- Allocate a statement handle for the SQL statement using
OCIStmtPrepare2(). - For statements with input, or output, variables, each placeholder in the statement must be bound to an address in the client application using
OCIBindByPos2(), OCIBindByName2(), OCIBindObject(), OCIBindDynamic() or OCIBindArrayOfStruct(). - Execute the statement by calling
OCIStmtExecute().
The remaining steps are only required for SQL queries:
- Describe the select-list items using
OCIParamGet() and OCIAttrGet(). This step is not required if the elements of the select list are known at compile-time. - Define output variables using
OCIDefineByPos2() or OCIDefineByPos(), OCIDefineObject(), OCIDefineDynamic(), or OCIDefineArrayOfStruct() for each item in the select list. - Fetch the results of the query using
OCIStmtFetch2().
The code below shows the easiest way to execute an SQL query with bound input variables:
std::wstring sql =
L"SELECT * FROM ALL_USERS WHERE USERNAME<>:1";
std::wstring myName( L"ESPEN" );
auto statement = serviceContext.CreateStatement( sql, myName );
auto reader = statement.ExecuteReader<DataReader>( );
while ( reader->Read( ) )
{
auto userName = reader->As<std::wstring>( 0 );
auto userId = reader->As<Int64>( 1 );
auto created = reader->As<DateTime>( 2 );
}
The CreateStatement(…) function binds all but the first argument automatically, and is able to perform this for the following C++ types:
bool and std::optional<bool>SByte (signed char) and std::optional<SByte>Byte (unsigned char) and std::optional<Byte>Int16 (short) and std::optional<Int16>UInt16 (unsigned short) and std::optional<UInt16>Int32 (int) and std::optional<Int32>UInt32 (unsigned int) and std::optional<UInt32>Int64 (long long) and std::optional<Int64>UInt64 (unsigned long long) and std::optional<UInt64>Single (float) and std::optional<Single>Double (double) and std::optional<Double>DateTime and std::optional<DateTime>Guid and std::optional<Guid>std::wstring and std::optional<std::wstring>
If the argument is passed as one of the supported std::optional<> types, then std::optional<>::has_value() is used to control the NULL indicator for the bind.
This way of binding variables is intended for input variables only. The CreateStatement function is implemented as a variadic template function, which is why it is able to bind the arguments based on their type:
template<typename ...BindableTypes>
inline OCI::Statement ServiceContext::CreateStatement( const std::wstring& sql,
BindableTypes&& ...bindableArgs ) const
{
auto result = CreateStatement( sql );
Internal::BindArgs( result, 1,
std::forward<BindableTypes>( bindableArgs )... );
return result;
}
CreateStatement( sql ) just calls OCIStmtPrepare2 and checks for errors:
OCI::Statement ServiceContext::CreateStatement( const std::wstring& sql ) const
{
auto& environment = Environment( );
if ( environment.IsValid( ) )
{
OCIStmt* ociStatement = nullptr;
auto& error = Error( );
auto errorHandle = (OCIError*)error.Handle( );
auto rc = OCIStmtPrepare2( (OCISvcCtx*)Handle( ), &ociStatement, errorHandle,
(OraText*)sql.c_str( ), static_cast<UInt32>( sql.length( ) * sizeof( wchar_t ) ),
nullptr, 0, OCI_NTV_SYNTAX, OCI_DEFAULT );
error.CheckResult( rc );
return Statement( *this, ociStatement, true );
}
else
{
ThrowInvalidEnvironment( );
}
}
While the internal implementation of BindArgs processes each of the variadic template arguments:
template<typename Arg, typename ...OtherArgsTypes>
void BindArgs( OCI::Statement& statement, UInt32 position,
const Arg& arg, OtherArgsTypes&& ...otherArgsTypes )
{
if constexpr ( IsAnyOf<Arg, std::wstring> )
{
auto newBind = statement.Bind<Arg>( position, arg.length( ) );
newBind->Assign( arg );
}
else if constexpr ( IsSpecializationOf<Arg, std::optional> )
{
using BintT = typename Arg::value_type;
if ( arg.has_value( ) )
{
if constexpr ( IsAnyOf< BintT, std::wstring> )
{
auto newBind = statement.Bind<BintT>( position, arg.value( ).length( ) );
newBind->Assign( arg.value() );
}
else
{
auto newBind = statement.Bind<BintT>( position );
newBind->Assign( arg.value( ) );
}
}
else
{
if constexpr ( IsAnyOf<BintT, std::wstring> )
{
auto newBind = statement.Bind<BintT>( position, static_cast<size_t>(0) );
newBind->SetDBNull( );
}
else
{
auto newBind = statement.Bind<BintT>( position );
newBind->SetDBNull( );
}
}
}
else
{
auto newBind = statement.Bind<Arg>( position );
newBind->Assign( arg );
}
if constexpr ( sizeof...( otherArgsTypes ) > 0 )
{
BindArgs( statement, position + 1, std::forward<OtherArgsTypes>( otherArgsTypes )... );
}
}
This is an example of how C++ can perform complex compile-time logic while ensuring that the code can still be debugged, where ‘if constexpr’ is used to control the code generation. Before C++ 17, debugging code involving compile-time logic could be rather confusing.
The ExecuteReader function is where all the magic happens, and so far OCIStmtPrepare2 is the only OCI function that has been called.
auto reader = statement.ExecuteReader<DataReader>( );
ExecuteReader performs three interesting operations:
- Creates the
DataReader object, or an object of a type derived from DataReader - Calls the
InitializeDefines() function on the newly created object - Executes the SQL statement
template<typename DataReaderType>
requires std::is_base_of_v<OCI::DataReader, DataReaderType>
inline std::unique_ptr<DataReaderType> Statement::ExecuteReader(
StatementExecuteMode executeMode )
{
auto result = std::make_unique<DataReaderType>( *this );
result->InitializeDefines( );
auto rc = Execute( 1, executeMode );
result->Prefetch( rc );
return result;
}
The DataReader provides a default implementation of InitializeDefines() which performs an explicit describe to determine the fields of the select-list and create appropriate defines using OCIDefineByPos2.
Another alternative is to create a class derived from DataReader:
class AllUsersReader : public DataReader
{
public:
using Base = DataReader;
constexpr static UInt32 USERNAME = 0;
constexpr static UInt32 USER_ID = 1;
constexpr static UInt32 CREATED = 2;
constexpr static UInt32 COMMON = 3;
constexpr static UInt32 ORACLE_MAINTAINED = 4;
constexpr static UInt32 INHERITED = 5;
constexpr static UInt32 DEFAULT_COLLATION = 6;
constexpr static UInt32 IMPLICIT = 7;
constexpr static UInt32 ALL_SHARD = 8;
constexpr static wchar_t SQL[] = L"SELECT USERNAME, "
L"USER_ID, CREATED, COMMON, ORACLE_MAINTAINED, "
L"INHERITED, DEFAULT_COLLATION, IMPLICIT, ALL_SHARD "
L"FROM ALL_USERS";
...
};
Each field gets its own id, which is the offset in the select-list. Since we know the types for the defines, we can create member variables for each field:
private:
CStringDefine* userName_ = nullptr;
Int64Define* userId_ = nullptr;
DateDefine* created_ = nullptr;
CStringDefine* common_ = nullptr;
CStringDefine* oracleMaintained_ = nullptr;
CStringDefine* inherited_ = nullptr;
CStringDefine* defaultCollation_ = nullptr;
CStringDefine* implicit_ = nullptr;
CStringDefine* allShard_ = nullptr;
public:
and then override the InitializeDefines( ) function:
virtual void InitializeDefines( ) override
{
userName_ = Define<CStringDefine>( USERNAME + 1, 128 );
userId_ = Define<Int64Define>( USER_ID + 1 );
created_ = Define<DateDefine>( CREATED + 1 );
common_ = Define<CStringDefine>( COMMON + 1, 3 );
oracleMaintained_ = Define<CStringDefine>( ORACLE_MAINTAINED + 1, 1 );
inherited_ = Define<CStringDefine>( INHERITED + 1, 3 );
defaultCollation_ = Define<CStringDefine>( DEFAULT_COLLATION + 1, 100 );
implicit_ = Define<CStringDefine>( IMPLICIT + 1, 3 );
allShard_ = Define<CStringDefine>( ALL_SHARD + 1, 3 );
}
This removes the need to perform any describe on the select-list and provides direct access to the objects that receives the data fetched from the database through OCI. We can easily implement function to access the data:
std::wstring UserName( ) const
{
return userName_->AsString( );
}
Int64 UserId( ) const
{
return userId_->AsInt64( );
}
DateTime Created( ) const
{
return created_->AsDateTime( );
}
And now, we can query the ALL_USERS view like this:
auto statement = serviceContext.CreateStatement( AllUsersReader::SQL );
auto reader = statement.ExecuteReader<AllUsersReader>( );
while ( reader->Read( ) )
{
auto userName = reader->UserName( );
auto userId = reader->UserId( );
auto created = reader->Created( );
}
While quite a bit more work, this executes more efficiently – and perhaps even more importantly: It isolates the internal implementation details of the query from the rest of the code.
There are also many situations where you know that it is more efficient to use a 64-bit integer than an Oracle Number, or that OCI::Date is more appropriate than a Timestamp, or a long var binary (LVB) in place of a BLOB. There are many real-world cases where the ability to control how data is exchanged with Oracle is crucial to the performance of the solution.
Improving Performance
The article started out with a promise of high performance, and performance is a relative thing, so a base case is needed. Here are the tables that will be used for the test cases:
CREATE TABLE TimeseriesValue1
(
Id NUMBER(19) NOT NULL,
Ts TIMESTAMP(9) NOT NULL,
Flags NUMBER(19) NOT NULL,
Val BINARY_DOUBLE NOT NULL,
CONSTRAINT PK_TSV1 PRIMARY KEY(Id,Ts)
) ORGANIZATION INDEX;
CREATE TABLE TimeseriesValue2
(
Id NUMBER(19) NOT NULL,
Ts NUMBER(19) NOT NULL,
Flags NUMBER(19) NOT NULL,
Val BINARY_DOUBLE NOT NULL,
CONSTRAINT PK_TSV2 PRIMARY KEY(Id,Ts)
) ORGANIZATION INDEX;
They are nearly identical, except that the type of the Ts column is a TIMESTAMP(9) for TimeseriesValue1 and a NUMBER(19) for TimeseriesValue2. NUMBER(19) is large enough to hold any value that can be held by a 64-bit integer.
Insert using ODP.Net
The base case uses .NET 5.0 and Oracle ODP.Net Core version 2.19.100, and it inserts 1 000 000 rows in a loop:
public void BasicInsert()
{
int count = 1000000;
var lastTimestamp = new DateTime(2020, 1, 1);
var firstTimestamp = lastTimestamp - TimeSpan.FromSeconds(count);
var oneSecond = TimeSpan.FromSeconds(1);
var stopwatch = new Stopwatch();
stopwatch.Start();
for (int i = 0; i < count; ++i)
{
var transaction = _connection.BeginTransaction();
using (transaction)
{
using (var command = _connection.CreateCommand())
{
command.CommandText = "INSERT INTO TimeseriesValue1(Id,Ts,Flags,Val) " +
"VALUES(:1,:2,:3,:4)";
OracleParameter id = new OracleParameter();
id.OracleDbType = OracleDbType.Int64;
id.Value = i + 1;
OracleParameter timestamp = new OracleParameter();
timestamp.OracleDbType = OracleDbType.TimeStamp;
timestamp.Value = firstTimestamp + (oneSecond * (i + 1));
OracleParameter flag = new OracleParameter();
flag.OracleDbType = OracleDbType.Int64;
flag.Value = i + 1;
OracleParameter value = new OracleParameter();
value.OracleDbType = OracleDbType.BinaryDouble;
value.Value = (double)i + 1.0;
command.Parameters.Add(id);
command.Parameters.Add(timestamp);
command.Parameters.Add(flag);
command.Parameters.Add(value);
command.ExecuteNonQuery();
}
transaction.Commit();
}
}
stopwatch.Stop();
var duration = stopwatch.Elapsed.TotalSeconds;
var rowsPerSecond = count / duration;
System.Console.Out.WriteLine("Inserted {0} rows in {1} seconds - rows per second: {2} ",
count, duration, rowsPerSecond);
}
Output:
Inserted 1000000 rows in 285.0611257 seconds - rows per second: 3508.019543332632
Performing the same operation on the TimeseriesValue2 table improves the performance by about 20%:
Inserted 1000000 rows in 237.306739 seconds - rows per second: 4213.955339886071
Inserting rows one by one is how most client applications insert data into a database.
ODP.Net has a nice feature that enables us to pass all the data using a single call to ExecuteNonQuery():
public void Insert()
{
int count = 1000000;
long[] ids = new long[count];
DateTime[] timestamps = new DateTime[count];
long[] flags = new long[count];
double[] values = new double[count];
var lastTimestamp = new DateTime(2020, 1, 1);
var firstTimestamp = lastTimestamp - TimeSpan.FromSeconds(count);
var oneSecond = TimeSpan.FromSeconds(1);
for (int i = 0; i < count; ++i)
{
ids[i] = i + 1;
timestamps[i] = firstTimestamp + (oneSecond * (i + 1));
flags[i] = i + 1;
values[i] = i + 1;
}
using (var command = _connection.CreateCommand())
{
command.CommandText = "INSERT INTO TimeseriesValue1(Id,Ts,Flags,Val) "
+"VALUES(:1,:2,:3,:4)";
OracleParameter id = new OracleParameter();
id.OracleDbType = OracleDbType.Int64;
id.Value = ids;
OracleParameter timestamp = new OracleParameter();
timestamp.OracleDbType = OracleDbType.TimeStamp;
timestamp.Value = timestamps;
OracleParameter flag = new OracleParameter();
flag.OracleDbType = OracleDbType.Int64;
flag.Value = flags;
OracleParameter value = new OracleParameter();
value.OracleDbType = OracleDbType.BinaryDouble;
value.Value = values;
command.ArrayBindCount = ids.Length;
command.Parameters.Add(id);
command.Parameters.Add(timestamp);
command.Parameters.Add(flag);
command.Parameters.Add(value);
var stopwatch = new Stopwatch();
stopwatch.Start();
var transaction = _connection.BeginTransaction();
using (transaction)
{
command.ExecuteNonQuery();
transaction.Commit();
}
stopwatch.Stop();
var duration = stopwatch.Elapsed.TotalSeconds;
var rowsPerSecond = count / duration;
System.Console.Out.WriteLine("Inserted {0} rows in {1} seconds - rows per second: {2} ",
count, duration, rowsPerSecond);
}
}
Output:
Inserted 1000000 rows in 5.1137679 seconds - rows per second: 195550.5254745723
Performing the same operation on the TimeseriesValue2 table improves the performance by about 9%:
Inserted 1000000 rows in 4.6812986 seconds - rows per second: 213615.9398163578
This code binds the input variables to four arrays, each holding 1 000 000 values, and inserts 1 000 000 rows in 4.68 seconds. The program inserted more than 195 000 rows per second, improving the performance by a factor of more than 55.
Note: With ODP.Net, I am able to insert 1 000 000 rows using a single call, but attempting to insert 1 050 000 causes ExecuteNonQuery() to throw an exception.
Changing the type for the Ts column to NUMBER(19) also improves the performance, and most modern programming environments use a 64-bit integer representation for time – so this is certainly something to consider when performance is a priority.
Insert using Harlinn.OCI
Let us do the same thing using Harlinn.OCI:
std::wstring sql2( L"INSERT INTO TimeseriesValue1(Id,Ts,Flags,Val) "
L"VALUES( :1, :2, :3, :4)" );
DateTime lastTimestamp( 2020, 1, 1 );
auto firstTimestamp = lastTimestamp - TimeSpan::FromSeconds( count );
auto oneSecond = TimeSpan::FromSeconds( 1 );
Stopwatch stopwatch;
stopwatch.Start( );
for ( size_t i = 0; i < count; ++i )
{
auto id = i + 1;
auto timestamp = firstTimestamp + ( oneSecond * ( i + 1 ) );
auto flags = i + 1;
auto value = static_cast<double>( i + 1 );
auto insertStatement =
serviceContext.CreateStatement( sql2, id, timestamp, flags, value );
insertStatement.Execute( );
}
serviceContext.TransactionCommit( );
stopwatch.Stop( );
auto duration = stopwatch.TotalSeconds( );
auto rowsPerSecond = count / duration;
printf( "Inserted %zu rows in %f seconds - %f rows per seconds\n",
count, duration, rowsPerSecond );
Output:
Inserted 1000000 rows in 113.662342 seconds - 8797.988711 rows per seconds
The code performs pretty much the same job as the ODP.Net base case above, inserting rows one-by-one in a loop, allocating an OCI::Statement and binding the input variables for each iteration. It outperforms the ODP.Net version by a factor of more than 2.5.
The improvement achieved by switching to TimeseriesValue2 is so marginal that it is hard to argue that it proves anything one way or the other:
Inserted 1000000 rows in 110.978168 seconds - 9010.781308 rows per seconds
Using ODP.Net demonstrated that we can significantly improve the performance by binding to arrays and perform all the inserts through a single call to ExecuteNonQuery(), so it is certainly interesting to see how much this technique will improve the OCI based solution:
constexpr size_t count = 1'000'000;
std::wstring sql2( L"INSERT INTO TimeseriesValue1(Id,Ts,Flags,Val) "
L"VALUES( :1, :2, :3, :4)" );
auto insertStatement = serviceContext.CreateStatement( sql2 );
auto id = insertStatement.Bind<UInt64ArrayBind>( 1 );
auto timestamp = insertStatement.Bind<TimestampArrayBind>( 2 );
auto flag = insertStatement.Bind<UInt64ArrayBind>( 3 );
auto value = insertStatement.Bind<DoubleArrayBind>( 4 );
DateTime lastTimestamp( 2020, 1, 1 );
auto firstTimestamp = lastTimestamp - TimeSpan::FromSeconds( count );
auto oneSecond = TimeSpan::FromSeconds( 1 );
std::vector<UInt64> ids( count );
std::vector<DateTime> timestamps( count );
std::vector<UInt64> flags( count );
std::vector<double> values( count );
for ( size_t i = 0; i < count; ++i )
{
ids[i] = i + 1;
timestamps[i] = firstTimestamp + ( oneSecond * ( i + 1 ) );
flags[i] = i + 1;
values[i] = static_cast<double>( i + 1 );
}
id->Assign( std::move( ids ) );
timestamp->Assign( timestamps );
flag->Assign( std::move( flags ) );
value->Assign( std::move( values ) );
Stopwatch stopwatch;
stopwatch.Start( );
insertStatement.Execute( count );
serviceContext.TransactionCommit( );
stopwatch.Stop( );
auto duration = stopwatch.TotalSeconds( );
auto rowsPerSecond = count / duration;
printf( "Inserted %zu rows in %f seconds - %f rows per seconds\n",
count, duration, rowsPerSecond );
Output:
Inserted 1000000 rows in 0.814117 seconds - 1228324.072179 rows per seconds
This version further improved the performance by a factor of 5.75 compared to the fastest .NET version – demonstrating that the Oracle Call Interface can be much more efficient than ODP.Net. Compared to the basic ODP.Net version, we have improved the performance by a factor of 350, so this is certainly worth the extra effort; which, to be honest, isn’t that big.
Switching to TimeseriesValue2, the code now performs slightly worse than for TimeseriesValue1, but again the difference is so marginal that it cannot be argued that it proves anything.
Inserted 1000000 rows in 0.818555 seconds - 1221665.604225 rows per seconds
The capacity for handling large volumes of data is also much greater for OCI, and this version can easily insert 100 000 000 rows using a single call, but with reduced performance:
Inserted 100000000 rows in 106.102264 seconds - 942486.955012 rows per seconds
Select using ODP.Net
Again .NET 5.0 and ODP.Net is used to establish a base case:
public void Select()
{
using (var command = _connection.CreateCommand())
{
int count = 0;
var stopwatch = new Stopwatch();
command.CommandText = "SELECT Id,Ts,Flags,Val FROM TimeseriesValue2 ORDER BY Id,Ts";
stopwatch.Start();
var reader = command.ExecuteReader();
while (reader.Read())
{
var id = reader.GetInt64(0);
var ts = reader.GetInt64(1);
var flags = reader.GetInt64(2);
var value = reader.GetDouble(3);
count++;
}
stopwatch.Stop();
var duration = stopwatch.Elapsed.TotalSeconds;
var rowsPerSecond = count / duration;
System.Console.Out.WriteLine("Retrieved {0} rows in {1} seconds - "+
"rows per second: {2} ",
count, duration, rowsPerSecond);
}
}
Output:
Retrieved 1000000 rows in 0.5656143 seconds - rows per second: 1767989.2463822078
This is surprisingly good. :-)
Select using Harlinn.OCI
The initial C++ implementation performs only marginally better:
auto statement = serviceContext.CreateStatement( L"SELECT Id,Ts,Flags,Val "
L"FROM TimeseriesValue2" );
statement.SetPrefetchRows( 30'000 );
Stopwatch stopwatch;
stopwatch.Start( );
auto reader = statement.ExecuteReader<ArrayDataReader>( 120'000 );
size_t count = 0;
while ( reader->Read( ) )
{
auto id = reader->GetUInt64( 0 );
auto ts = reader->GetUInt64( 1 );
auto flags = reader->GetUInt64( 2 );
auto value = reader->GetDouble( 3 );
count++;
}
stopwatch.Stop( );
auto duration = stopwatch.TotalSeconds( );
auto rowsPerSecond = count / duration;
printf( "Retrieved %zu rows in %f seconds - %f rows per seconds\n",
count, duration, rowsPerSecond );
Output:
Retrieved 1000000 rows in 0.413025 seconds - 2421160.946674 rows per seconds
Here, we got about 36% better throughput using C++ and OCI, but we should be able to do better than that. It is time for a custom data reader:
class TimeseriesValues2Reader : public ArrayDataReader
{
public:
using Base = ArrayDataReader;
constexpr static UInt32 ID_ID = 0;
constexpr static UInt32 TS_ID = 1;
constexpr static UInt32 FLAGS_ID = 2;
constexpr static UInt32 VAL_ID = 3;
constexpr static wchar_t SQL[] = L"SELECT Id,Ts,Flags,Val FROM TimeseriesValue2";
public:
TimeseriesValues2Reader( const OCI::Statement& statement, size_t size )
: Base( statement, size )
{
}
virtual void InitializeDefines( ) override
{
Define<UInt64>( ID_ID + 1 );
Define<UInt64>( TS_ID + 1 );
Define<UInt64>( FLAGS_ID + 1 );
Define<Double>( VAL_ID + 1 );
}
UInt64 Id( ) const { return GetUInt64( ID_ID ); }
UInt64 Timestamp( ) const { return GetUInt64( TS_ID ); }
UInt64 Flag( ) const { return GetUInt64( FLAGS_ID ); }
Double Value( ) const { return GetDouble( VAL_ID ); }
};
The implementation of InitializeDefines( ) allows us to take control over the native data format for each of the elements in the select-list. This makes a huge difference:
constexpr UInt32 PrefetchRows = 32'000;
auto statement = serviceContext.CreateStatement( TimeseriesValues2Reader::SQL );
statement.SetPrefetchRows( PrefetchRows );
Stopwatch stopwatch;
stopwatch.Start( );
auto reader = statement.ExecuteReader<TimeseriesValues2Reader>( PrefetchRows*5 );
size_t count = 0;
while ( reader->Read( ) )
{
auto id = reader->Id( );
auto ts = reader->Timestamp( );
auto flags = reader->Flag( );
auto value = reader->Value( );
count++;
}
stopwatch.Stop( );
auto duration = stopwatch.TotalSeconds( );
auto rowsPerSecond = count / duration;
printf( "Retrieved %zu rows in %f seconds - %f rows per seconds\n",
count, duration, rowsPerSecond );
Output:
Retrieved 1000000 rows in 0.294642 seconds - 3393944.659696 rows per seconds
The C++ implementation is 91% faster than ODP.Net and .Net 5.0, and this includes the time that was spent on parsing, executing, and fetching the data from the cursor on the server – in this case about 100 ms according to the ELAPSED_TIME column of the V$SQLAREA view; and the time spent passing the data through the TCP/IP stack.
Can we do better than this? Harlinn.OCI does not yet support binding to structures, but this is an option that needs to be explored.
First, we need a structure that matches the select-list for the data:
struct TimeseriesValue
{
Int64 Id;
Int64 Timestamp;
Int64 Flags;
Double Value;
};
We still use Harlinn.OCI to create the statement, and configure the prefetch rows:
constexpr UInt32 PrefetchRows = 32'000;
auto statement = serviceContext.CreateStatement( L"SELECT Id,Ts,Flags,Val "
L"FROM TimeseriesValue2" );
statement.SetPrefetchRows( PrefetchRows );
With that out of the way, we need to allocate the memory that will receive the data from OCI:
std::vector<TimeseriesValue> values( PrefetchRows*4 );
TimeseriesValue* data = values.data( );
OCIStmt* statementHandle = (OCIStmt*)statement.Handle();
auto& error = statement.Error( );
OCIError* errorHandle = (OCIError*)error.Handle( );
When we want OCI to place data directly into a structure, we call OCIDefineByPos2 as usual, passing the address, size and type of the variable for the first element of the vector:
OCIDefine* idDefineHandle = nullptr;
auto rc = OCIDefineByPos2( statementHandle, &idDefineHandle, errorHandle, 1,
&data->Id, sizeof( data->Id ), SQLT_INT,
nullptr, nullptr, nullptr, OCI_DEFAULT );
if ( rc < OCI_SUCCESS )
{
error.CheckResult( rc );
}
Then we need to let OCI know about the distance to the same variable for the next element of the vector:
rc = OCIDefineArrayOfStruct( idDefineHandle, errorHandle,
sizeof( TimeseriesValue ), 0, 0, 0 );
if ( rc < OCI_SUCCESS )
{
error.CheckResult( rc );
}
This is then repeated for the remaining members of the structure:
OCIDefine* timestampDefineHandle = nullptr;
rc = OCIDefineByPos2( statementHandle, ×tampDefineHandle, errorHandle, 2,
&data->Timestamp, sizeof( data->Timestamp ), SQLT_INT,
nullptr, nullptr, nullptr, OCI_DEFAULT );
if ( rc < OCI_SUCCESS )
{
error.CheckResult( rc );
}
rc = OCIDefineArrayOfStruct( timestampDefineHandle, errorHandle,
sizeof( TimeseriesValue ), 0, 0, 0 );
if ( rc < OCI_SUCCESS )
{
error.CheckResult( rc );
}
OCIDefine* flagsDefineHandle = nullptr;
rc = OCIDefineByPos2( statementHandle, &flagsDefineHandle, errorHandle, 3,
&data->Flags, sizeof( data->Timestamp ), SQLT_INT,
nullptr, nullptr, nullptr, OCI_DEFAULT );
if ( rc < OCI_SUCCESS )
{
error.CheckResult( rc );
}
rc = OCIDefineArrayOfStruct( flagsDefineHandle, errorHandle,
sizeof( TimeseriesValue ), 0, 0, 0 );
if ( rc < OCI_SUCCESS )
{
error.CheckResult( rc );
}
OCIDefine* valueDefineHandle = nullptr;
rc = OCIDefineByPos2( statementHandle, &valueDefineHandle, errorHandle, 4,
&data->Value, sizeof( data->Value ), SQLT_BDOUBLE,
nullptr, nullptr, nullptr, OCI_DEFAULT );
if ( rc < OCI_SUCCESS )
{
error.CheckResult( rc );
}
rc = OCIDefineArrayOfStruct( valueDefineHandle, errorHandle,
sizeof( TimeseriesValue ), 0, 0, 0 );
if ( rc < OCI_SUCCESS )
{
error.CheckResult( rc );
}
Now that we have created defines for each column of the query, it is time to execute the query on the Oracle database:
OCISvcCtx* serviceContextHandle = (OCISvcCtx*)serviceContext.Handle( );
Stopwatch stopwatch;
stopwatch.Start( );
size_t count = 0;
rc = OCIStmtExecute( serviceContextHandle, statementHandle, errorHandle,
0, 0, NULL, NULL, OCI_DEFAULT );
if ( rc < OCI_SUCCESS )
{
error.CheckResult( rc );
}
It is only when we receive the data from OCI that we need to specify the size of the vector:
rc = OCIStmtFetch2( statementHandle, errorHandle,
static_cast<UInt32>( values.size( ) ),
OCI_FETCH_NEXT, 0, OCI_DEFAULT );
At this point, the data has been placed into the vector, and information about exactly how many rows that was retrieved by the fetch can be determined by calling RowsFetched( ):
if ( rc >= OCI_SUCCESS )
{
UInt32 rowsFetched = statement.RowsFetched( );
while ( rowsFetched && rc >= OCI_SUCCESS )
{
for ( UInt32 i = 0; i < rowsFetched; ++i )
{
auto id = data[i].Id;
auto ts = data[i].Timestamp;
auto flags = data[i].Flags;
auto value = data[i].Value;
count++;
}
if ( rc != OCI_NO_DATA )
{
rc = OCIStmtFetch2( statementHandle, errorHandle,
static_cast<UInt32>( values.size( ) ),
OCI_FETCH_NEXT, 0, OCI_DEFAULT );
rowsFetched = statement.RowsFetched( );
}
else
{
rowsFetched = 0;
}
}
}
if ( rc < OCI_SUCCESS )
{
error.CheckResult( rc );
}
stopwatch.Stop( );
auto duration = stopwatch.TotalSeconds( );
auto rowsPerSecond = count / duration;
printf( "Retrieved %zu rows in %f seconds - %f rows per seconds\n",
count, duration, rowsPerSecond );
Output:
Retrieved 1000000 rows in 0.276765 seconds - 3613176.242065 rows per seconds
This improved the performance by about 6% compared to the custom data reader.
Update using ODP.Net
The most common way to update tables in a database is to execute an update statement for each row, like this:
public void BasicUpdate()
{
var rows = GetAll();
var stopwatch = new Stopwatch();
stopwatch.Start();
foreach (var row in rows)
{
using (var command = _connection.CreateCommand())
{
command.CommandText = "UPDATE TimeseriesValue1 SET Flags=:1, Val=:2 "
+ "WHERE Id=:3 AND Ts=:4";
OracleParameter flag = new OracleParameter();
flag.OracleDbType = OracleDbType.Int64;
flag.Value = row.Flags * 2;
OracleParameter value = new OracleParameter();
value.OracleDbType = OracleDbType.BinaryDouble;
value.Value = row.Value * 2;
OracleParameter id = new OracleParameter();
id.OracleDbType = OracleDbType.Int64;
id.Value = row.Id;
OracleParameter timestamp = new OracleParameter();
timestamp.OracleDbType = OracleDbType.TimeStamp;
timestamp.Value = row.Timestamp;
command.Parameters.Add(flag);
command.Parameters.Add(value);
command.Parameters.Add(id);
command.Parameters.Add(timestamp);
command.ExecuteNonQuery();
}
}
stopwatch.Stop();
var duration = stopwatch.Elapsed.TotalSeconds;
var rowsPerSecond = rows.Count / duration;
System.Console.Out.WriteLine("Updated {0} rows in {1} seconds - rows per second: {2} ",
rows.Count, duration, rowsPerSecond);
}
Output:
Updated 1000000 rows in 199.6225356 seconds - rows per second: 5009.454453598274
And as we saw for the inserts, this can be drastically improved by binding to arrays and executing all the updates through a single call to ExecuteNonQuery():
public void Update()
{
var rows = GetAll();
long[] ids = new long[rows.Count];
DateTime[] timestamps = new DateTime[rows.Count];
long[] flags = new long[rows.Count];
double[] values = new double[rows.Count];
for (int i = 0; i < rows.Count; ++i)
{
var row = rows[i];
ids[i] = row.Id;
timestamps[i] = row.Timestamp;
flags[i] = row.Flags * 2;
values[i] = row.Value* 2;
}
using (var command = _connection.CreateCommand())
{
command.CommandText = "UPDATE TimeseriesValue1 SET Flags=:1, Val=:2 "
+ "WHERE Id=:3 AND Ts=:4";
OracleParameter flag = new OracleParameter();
flag.OracleDbType = OracleDbType.Int64;
flag.Value = flags;
OracleParameter value = new OracleParameter();
value.OracleDbType = OracleDbType.BinaryDouble;
value.Value = values;
OracleParameter id = new OracleParameter();
id.OracleDbType = OracleDbType.Int64;
id.Value = ids;
OracleParameter timestamp = new OracleParameter();
timestamp.OracleDbType = OracleDbType.TimeStamp;
timestamp.Value = timestamps;
command.ArrayBindCount = rows.Count;
command.Parameters.Add(flag);
command.Parameters.Add(value);
command.Parameters.Add(id);
command.Parameters.Add(timestamp);
int count = 0;
var stopwatch = new Stopwatch();
stopwatch.Start();
var transaction = _connection.BeginTransaction();
using (transaction)
{
count = command.ExecuteNonQuery();
transaction.Commit();
}
stopwatch.Stop();
var duration = stopwatch.Elapsed.TotalSeconds;
var rowsPerSecond = count / duration;
System.Console.Out.WriteLine("Updated {0} rows in {1} seconds - rows per second: {2} ",
count, duration, rowsPerSecond);
}
}
Output:
Updated 1000000 rows in 11,9057144 seconds - rows per second: 83993,279731286
This improved the performance by a factor of 16 – which is certainly a worthwhile improvement.
Update using Harlinn.OCI
Using OCI to implement the basic update loop:
Stopwatch stopwatch;
stopwatch.Start( );
constexpr wchar_t sql[] =
L"UPDATE TimeseriesValue1 SET Flags=:1, Val=:2 WHERE Id=:3 AND Ts=:4";
for ( auto& row : rows )
{
auto updateStatement = serviceContext.CreateStatement( sql,
row.Flags*2, row.Value*2, row.Id, row.Timestamp );
updateStatement.ExecuteNonQuery( );
}
stopwatch.Stop( );
auto duration = stopwatch.TotalSeconds( );
auto rowsPerSecond = count / duration;
printf( "Updated %zu rows in %f seconds - %f rows per seconds\n",
count, duration, rowsPerSecond );
Output:
Updated 1000000 rows in 123.436877 seconds - 8101.306717 rows per seconds
Improves the performance by 61% over the basic update loop implemented using ODP.Net, and when we perform array binding using OCI:
constexpr wchar_t sql[] =
L"UPDATE TimeseriesValue1 SET Flags=:1, Val=:2 WHERE Id=:3 AND Ts=:4";
auto updateStatement = serviceContext.CreateStatement( sql );
auto flag = updateStatement.Bind<UInt64ArrayBind>( 1 );
auto value = updateStatement.Bind<DoubleArrayBind>( 2 );
auto id = updateStatement.Bind<UInt64ArrayBind>( 3 );
auto timestamp = updateStatement.Bind<TimestampArrayBind>( 4 );
std::vector<UInt64> ids( count );
std::vector<DateTime> timestamps( count );
std::vector<UInt64> flags( count );
std::vector<double> values( count );
for ( size_t i = 0; i < count; ++i )
{
auto& row = rows[i];
ids[i] = row.Id;
timestamps[i] = row.Timestamp;
flags[i] = row.Flags*2;
values[i] = row.Value*2;
}
id->Assign( std::move( ids ) );
timestamp->Assign( timestamps );
flag->Assign( std::move( flags ) );
value->Assign( std::move( values ) );
Stopwatch stopwatch;
stopwatch.Start( );
updateStatement.ExecuteNonQuery( static_cast<UInt32>( count ) );
serviceContext.TransactionCommit( );
stopwatch.Stop( );
auto duration = stopwatch.TotalSeconds( );
auto rowsPerSecond = count / duration;
printf( "Updated %zu rows in %f seconds - %f rows per seconds\n",
count, duration, rowsPerSecond );
Output:
Updated 1000000 rows in 6.182285 seconds - 161752.501656 rows per seconds
Improves the performance by a factor of 32 over the basic ODP.Net update loop, and it’s twice as fast as the array binding for ODP.Net.
Updating 100 000 000 rows using a single call to ExecuteNonQuery is possible, but again this hurts performance significantly:
Updated 100000000 rows in 1131.646176 seconds - 88366.842991 rows per seconds
The End (for now …)
It is interesting to note how fast Oracle can insert data compared to updating the rows.
Most transactional database management systems leverage a technique called multi-version concurrency control. As a result, updates never update the existing record, but create a copy that will only be visible to other sessions after the update is committed to the database. Some systems offer multiple transaction isolation levels, sometimes allowing parallel sessions to read data that has not yet been committed by the session performing the update or insert. These systems will still make a copy of the updated row, otherwise they would be unable to perform a rollback of the current transaction. Managing multiple versions of data in a consistent manner is complicated, so it should not be surprising that this has a significant impact on the overall performance of the server.
Since inserts generally outperform updates; particularly for tables with few, fixed size, columns; this is something that can be taken into consideration when designing the database. In the long run, this will probably make the database more valuable, since it will now be possible to analyze the impact of the changed data, perhaps using machine learning or more traditional statistical methods.
History
- 3rd December, 2020 - Initial post
- 18th December, 2020:
- Bug fixes for IO::FileStream
- Initial http server development support
- Synchronous server: $(SolutionDir)Examples\Core\HTTP\Server\HttpServerEx01
- Asyncronous server: $(SolutionDir)Examples\Core\HTTP\Server\HttpServerEx02
- Simplified asynchronous I/O, Timers, Work and events for Windows waitable kernel objects using Windows thread pool API: $(SolutionDir)Examples\Core\ThreadPools\HExTpEx01
- 11th of February, 2021:
- Bug fixes
- Initial C++ ODBC support
- 25th of February, 2021:
- Updated LMDB
- Updated xxHash
- Added the initial implementation of very fast hash based indexes for large complex keys using LMDB
- Fast asychronous logging - nearly done :-)
- 3rd of March, 2021:
- New authorization related classes
- SecurityId: Wrapper for SID and related operations
- ExplicitAccess: Wrapper for EXCPLICIT_ACCESS
- Trustee: Wrapper for TRUSTEE
- SecurityIdAndDomain: Holds the result from LookupAccountName
- LocalUniqueId: Wrapper for LUID
- AccessMask: Makes it easy to inspect the rights assigned to an ACCESS_MASK
- AccessMaskT<>
- EventWaitHandleAccessMask: Inspect and manipulate the rights of an EventWaitHandle.
- MutexAccessMask: Inspect and manipulate the rights of a Mutex.
- SemaphoreAccessMask: Inspect and manipulate the rights of a Semaphore.
- WaitableTimerAccessMask: Inspect and manipulate the rights of a WaitableTimer.
- FileAccessMask: Inspect and manipulate file related rights.
- DirectoryAccessMask: Inspect and manipulate directory related rights.
- PipeAccessMask: Inspect and manipulate pipe related rights.
- ThreadAccessMask: Inspect and manipulate thread related rights.
- ProcessAccessMask: Inspect and manipulate process related rights.
- GenericMapping: Wrapper for GENERIC_MAPPING
- AccessControlEntry: This is a set of tiny classes that wraps the ACE structures
- AccessControlEntryBase<,>
- AccessAllowedAccessControlEntry
- AccessDeniedAccessControlEntry
- SystemAuditAccessControlEntry
- SystemAlarmAccessControlEntry
- SystemResourceAttributeAccessControlEntry
- SystemScopedPolicyIdAccessControlEntry
- SystemMandatoryLabelAccessControlEntry
- SystemProcessTrustLabelAccessControlEntry
- SystemAccessFilterAccessControlEntry
- AccessDeniedCallbackAccessControlEntry
- SystemAuditCallbackAccessControlEntry
- SystemAlarmCallbackAccessControlEntry
- ObjectAccessControlEntryBase<,>
- AccessAllowedObjectAccessControlEntry
- AccessDeniedObjectAccessControlEntry
- SystemAuditObjectAccessControlEntry
- SystemAlarmObjectAccessControlEntry
- AccessAllowedCallbackObjectAccessControlEntry
- AccessDeniedCallbackObjectAccessControlEntry
- SystemAuditCallbackObjectAccessControlEntry
- SystemAlarmCallbackObjectAccessControlEntry
- AccessControlList: Wrapper for ACL
- PrivilegeSet: Wrapper for PRIVILEGE_SET
- SecurityDescriptor: Early stage implementation of wrapper for SECURITY_DESCRIPTOR
- SecurityAttributes: Very early stage implementation of wrapper for SECURITY_ATTRIBUTES
- Token: Early stage implementation of wrapper for an access token
- DomainObject
- User: Information about a local, workgroup or domain user
- Computer: Information about a local, workgroup or domain computer
- Group: local, workgroup or domain group
- Users: vector of User objects
- Groups: vector of Group objects
- 14th of March, 2021 - more work on security related stuff:
- Token: A wrapper for a Windows access token with a number of supporting classes like:
- TokenAccessMask: An access mask implmentation for the access rights of a Windows access token.
- TokenGroups: A wrapper/binary compatible replacement for the Windows TOKEN_GROUPS type with a C++ container style interface.
- TokenPrivileges: A wrapper/binary compatible replacement for the TOKEN_PRIVILEGES type with a C++ container style interface.
- TokenStatistics: A binary compatible replacement for the Windows TOKEN_STATISTICS type using types implemented by the library such as LocalUniqueId, TokenType and ImpersonationLevel.
- TokenGroupsAndPrivileges: A Wrapper/binary compatible replacement for the Windows TOKEN_GROUPS_AND_PRIVILEGES type.
- TokenAccessInformation: A wrapper/binary compatible replacement for the Windows TOKEN_ACCESS_INFORMATION type.
- TokenMandatoryLabel: A wrapper for the Windows TOKEN_MANDATORY_LABEL type.
- SecurityPackage: Provides access to information about a Windows security package.
- SecurityPackages: An std::unordered_map of information about the security packages installed on the system.
- CredentialsHandle: A wrapper for the Windows CredHandle type.
- SecurityContext: A wrapper for the Windows CtxtHandle type
- Crypto::Blob and Crypto::BlobT: C++ style _CRYPTOAPI_BLOB replacement
- CertificateContext: A wrapper for the Windows PCCERT_CONTEXT type, provides access to a X.509 certificate.
- CertificateChain: A wrapper for the Windows PCCERT_CHAIN_CONTEXT type which contains an array of simple certificate chains and a trust status structure that indicates summary validity data on all of the connected simple chains.
- ServerOcspResponseContext: Contains an encoded OCSP response.
- ServerOcspResponse: Represents a handle to an OCSP response associated with a server certificate chain.
- CertificateChainEngine: Represents a chain engine for an application.
- CertificateTrustList: A wrapper for the Windows PCCTL_CONTEXT type which contains both the encoded and decoded representations of a CTL. It also contains an opened HCRYPTMSG handle to the decoded, cryptographically signed message containing the CTL_INFO as its inner content.
- CertificateRevocationList: Contains both the encoded and decoded representations of a certificate revocation list (CRL)
- CertificateStore: A storage for certificates, certificate revocation lists (CRLs), and certificate trust lists (CTLs).
- 23rd of March, 2021:
- Updated to Visual Studio 16.9.2
- Build fixes
SecurityDescriptor: Implemented serialization for security descriptors, enabling persistence of authorization data.

