Here we’ll start working on our iOS application. Before we implement object detection in this app, we need to handle video capture.
Introduction
This series assumes that you are familiar with Python, Conda, and ONNX, as well as have some experience with developing iOS applications in Xcode. You are welcome to download the source code for this project. We’ll run the code using macOS 10.15+, Xcode 11.7+, and iOS 13+.
Handling live camera feed in an iOS application may be a little overwhelming. We’ll try to make things as simple as possible, focusing more on code readability than on performance. Also, to reduce the number of scaling options to consider, we’ll use the fixed portrait orientation.
The code for this article was initially inspired by this application.
This demo app was written using Xcode 11.7, and should work reasonably well with any iPhone starting from 7 with iOS 13 or later.
Application Layout
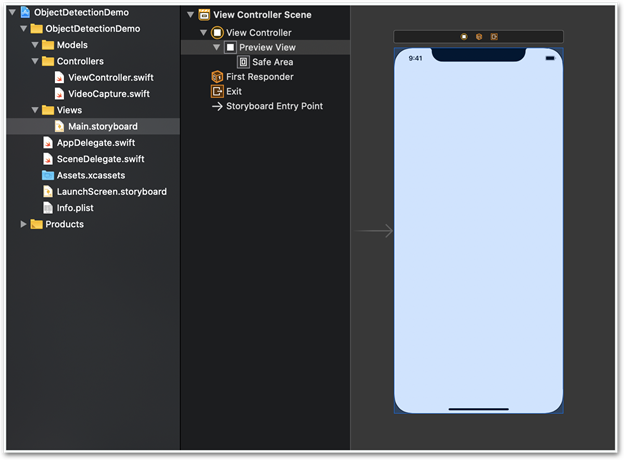
From the storyboard perspective, our application is extremely simple. It contains a single View Controller with a lone Preview View control on it. We’ll use this view for the live camera feed.
Capturing Camera Feed
All the code responsible for handling camera input and video preview are in the Controllers/VideoCapture class, which implements AVCaptureVideoDataOutputSampleBufferDelegate.
The following members store its setup:
private let captureSession = AVCaptureSession()
private var videoPreviewLayer: AVCaptureVideoPreviewLayer! = nil
private let videoDataOutput = AVCaptureVideoDataOutput()
private let videoDataOutputQueue = DispatchQueue(label: "VideoDataOutput", qos: .userInitiated, attributes: [], autoreleaseFrequency: .workItem)
private var videoFrameSize: CGSize = .zero
The setupPreview method, called by the class constructor, binds all the elements together.
First, it obtains the first available back camera as input device:
var deviceInput: AVCaptureDeviceInput!
let videoDevice = AVCaptureDevice.DiscoverySession(deviceTypes: [.builtInWideAngleCamera], mediaType: .video, position: .back).devices.first
do {
Next, it starts the configuration process, forcing 640 x 480 frames from the camera. Such resolution is sufficient for our YOLO v2 model because it uses images scaled to 416 x 416 pixels anyway. Note that, due to the fixed portrait orientation, we store 48 x 640 as input dimensions in the videoFrameSize variable for future use:
captureSession.beginConfiguration()
captureSession.sessionPreset = .vga640x480
self.videoFrameSize = CGSize(width: 480, height: 640)
The configuration continues to establish a single-element queue for frames to process (the alwaysDiscardLateVideoFrames flag). It means that until the processing of the current frame is completed, the subsequent frames will be discarded.
captureSession.addInput(deviceInput)
if captureSession.canAddOutput(videoDataOutput) {
captureSession.addOutput(videoDataOutput)
videoDataOutput.alwaysDiscardsLateVideoFrames = true
videoDataOutput.videoSettings = [kCVPixelBufferPixelFormatTypeKey as String: Int(kCVPixelFormatType_420YpCbCr8BiPlanarFullRange)]
videoDataOutput.setSampleBufferDelegate(self, queue: videoDataOutputQueue)
} else {
print("Could not add video data output to the session")
captureSession.commitConfiguration()
return
}
let captureConnection = videoDataOutput.connection(with: .video)
captureConnection?.isEnabled = true
captureConnection?.videoOrientation = .portrait
captureSession.commitConfiguration()
The fixed portrait orientation will make handling and drawing object detection predictions a little easier.
Camera Feed Preview
In the next steps, the setup method creates a videoPreviewLayer instance and adds it as a sublayer to our application’s view (viewLayer below):
self.videoPreviewLayer = AVCaptureVideoPreviewLayer(session: captureSession)
self.videoPreviewLayer.videoGravity = .resizeAspectFill
videoPreviewLayer.frame = viewLayer.bounds
viewLayer.addSublayer(videoPreviewLayer)
Use of the .resizeAspectFill value for videoGravity ensures that the video fills the entire available screen. Because no iPhone has a screen with proportions equal to 1,33:1 (inferred by the 640 x 480 resolution), each frame will be cropped on both sides in the portrait view. If we used .resizeAspect instead, the whole frame would have been visible, but with empty bars above and below it.
Finalising Camera Preview Configuration
We need three more methods in the VideoCapture class:
public func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
// We will handle frame(s) here
}
public func captureOutput(_ captureOutput: AVCaptureOutput, didDrop didDropSampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
// Dropped frame(s) can be handled here
}
public func startCapture() {
if !captureSession.isRunning {
captureSession.startRunning()
}
}
The first two methods are required because they are defined in AVCaptureVideoDataOutputSampleBufferDelegate, which our VideoCapture class implements. For now, an empty implementation is fine. We need the last method, startCapture, to start processing the video feed.
With the complete VideoCapture implementation linked to cameraView from our Main.storyboard, and with the instance variable to store the created VideoCapture instance, we create a new instance of VideoCapture in the viewDidLoad method of the main ViewController:
self.videoCapture = VideoCapture(self.cameraView.layer)
self.videoCapture.startCapture()
Conclusion
We now have a simple iOS application configured to capture and preview live camera stream. In the next – and last – article in this series, we’ll extend the application to use our YOLO v2 model for object detection.

