The goal of forque data structure is to allow items to be scheduled for processing based on hierarchical tags attached to them. Forque ensures that at most one item is processed at a given time for all tags related to the item’s own tag, while respecting relative order among related items in which they have been reserved in the queue.
Introduction
The purpose of the forque structure is to schedule processing in such way that items processed concurrently do not affect each other. For instance, when we receive stream of updates for a specific data set, where entities in that data set have parent-child relationship, it is possible that we do not want to process more than one update for the same item, or to have updates done on parent and one or more of its children simultaneously.
To achieve this, user augments each enqueued item with a tag which defines three-like hierarchy. Based on these tags, forque ensures that only one item at a time can be processed for the specific sub-tree in the hierarchy.
For example, tags 1/2 and 1/2/3 have parent-child relationship, while tags 1/2/1 and 1/2/3 are not related.
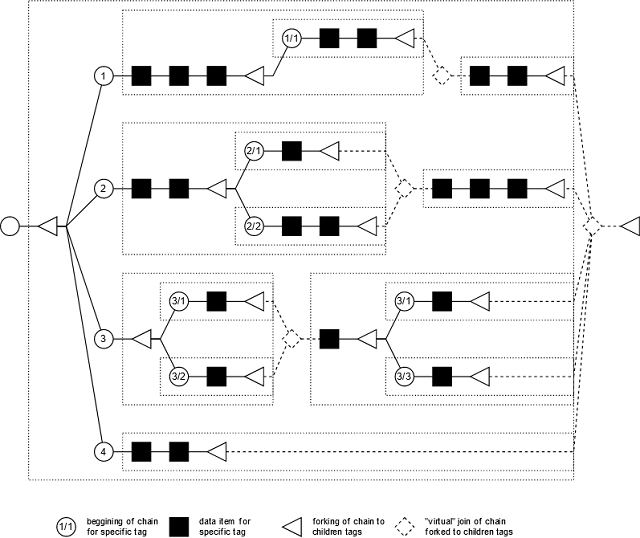
Structure of tag can be dynamic or static. Static tags have depth and types of each level defined at compile-time. For dynamic tags, depth is not defined while types can change during run-time and they can be of different type event for sibling tags.
| Level: | 0 | 1 | 2 |
| Type: | int | string | float |
| Static Tag #1 | 77 | "x" | 12.3 |
| Static Tag #2 | 8 | "y" | |
| Static Tag #3 | 10 | | |
| Level: | 0 | 1 | 2 |
| Dynamic Tag #1 | 8 | "x" | 12.3 |
| Dynamic Tag #2 | 8 | 7.9 | |
| Dynamic Tag #3 | "y" | 8 | |
Production of an item is done in two phases:
- Reserving place in the queue
- Populating item with actual payload
Reserving place ensures that relative order of related items will be respected, so that time needed to populate item with actual value does not cause unwanted reorderings.
Only populated items will be served to the consumers. All related items ordered after the item will wait for it to be populated, served and consumed before they are offered to the consumer, even if they are populated.
These two phases can be merged and item can be populated at reservation time, but the order will still be respected and the new item will not be offered unless there are no other related items that have to be consumed before it.
Like production, consumption is also done in two phases:
- Obtaining populated item
- Releasing item from the queue
The two phase process ensures that consumers will not be served with related items concurrently. In the first phase, consumer asks for an available time. After the item is processed, consumer has to notify queue that processing is done, so the next available item with related tag, if any, can be offered.
While the order of related items is respected, no such guarantee exists for unrelated items, which is the whole point of the exercise. :) There is still some control over the order in which available, but unrelated items, are served the consumers:
- FIFO - the first item made available gets served first
- LIFO - the last item made available gets served first
- Priority - available item with highest user-defined priority gets served first
Requirements
Forque library requires support for C++20 from the compiler. Specifically, support for coroutines and concepts. Currently, it is only working with Microsoft Visual C++ 14 compiler.
Using the Forque
Forque is implemented by frq::forque class template which is parameterized by type of the items stored in the queue, type of tags used for scheduling, desired runque type and allocator.
template<typename Ty,
runlike Runque,
taglike Tag,
typename Alloc = std::allocator<Ty>>
class forque;
Runque and Tag template parameters are constrained by runlike and taglike concepts.
frq::forque has a rather simple interface that allows user to do the following:
- Reserve place in queue for already produced item with specific tag:
template<taglike Tag>
task<> reserve(Tag const& tag, value_type const& value);
template<taglike Tag>
task<> reserve(Tag const& tag, value_type&& value);
- Reserve place in queue for an item with specific tag that will be produced later:
template<taglike Tag>
task<reservation_type> reserve(Tag const& tag);
- Get access to next ready item in runqueue:
task<retainment_type> get() noexcept;
- Stop acceptance of new reservations and processing of existing items:
task<> interrupt() noexcept;
Producing Items
If item’s value is already known, it can be marked with desired tag and be placed in forque using reserve overloads (a) or (b). Item will be put in ready queue whenever its dependencies are processed. On the other hand, if item’s value is not yet known, but the place has to be reserved to keep desired order of processing when it comes to item’s dependencies, overload (c) can be used. It returns object of reservation<T> type which represents this reservation. Calling release() on this type will set desired value and it will allow item to be put in ready queue. If release() is not called, all dependent items will be stuck in forque and they will not be scheduled for processing.
Consuming Items
get()will return only when there are available items in runqueue, or if the processing is interrupted by throwing interrupted exception. Item is not considered consumed after calling get(). Instead instance of retainment<T> type is returned. Calling value() will yield item’s value and finalize() will mark item as consumed and forque can proceed with processing dependent items. finalize() will not be called automatically by the destructor of retainment<T>, so it’s user’s responsibility to invoke it even in case of exception. If finalize() is not invoked, all dependent items will be stuck in forque and will never be scheduled for processing.
Stopping the Item Processing
Invoking interrupt() will immediately awake any consumers waiting for items and throw interrupted exception within their context. Any subsequent call to reserve() or get() will also result in interrupted exception.
Tags
Library offers the following choice of tag types:
- Static tags -
frq::stag class template, taking number of elements the tag has, its size, and their types - Dynamic tag -
frq::dtag class template, taking only allocator type
All tag types have to satisfy taglike concept which is defined as:
template<typename Ty>
concept taglike = requires(Ty t) {
typename Ty::size_type;
typename Ty::storage_type;
{std::size_t{typename Ty::size_type{}}};
{ t.values() } noexcept -> std::convertible_to<typename Ty::storage_type>;
{ t.size() } noexcept -> std::same_as<typename Ty::size_type>;
};
where
size_type is type that can store number of values in the tag and it can be converted to std::size_t without narrowing,storage_type is the type can store all values in the tag,size is a member function that returns number of values in the tag, andvalues is a member function returning all the values currently stored in tag.
Static Tags
Static tag has its structure, size and type of values at each level, defined at the compile time. Static tag owns values stored in them which means that copying/destroying tag will also copy/destroy stored values.
frq::stag class template represent static tag.
template<std::uint8_t Size, typename... Tys>
class stag;
Size template parameter specifies how many values from the Tys type list will be populated, so it defines "level" of the tag. List of types have to be the same for all tags used by the same queue, no matter the tag level:
| Level: | 0 | 1 | 2 |
stag<3, int, string, float> | 77 | "x" | 12.3 |
stag<2, int, string, float> | 8 | "y" | |
stag<1, int, string, float> | 10 | | |
frq::stag can be constructed from tuple of fitting size containing defined types, or providing the list of arguments to the constructor which will be used to initialize corresponding values in tag:
template<typename... Txs>
constexpr inline stag(construct_tag_default_t, Txs&&... args);
constexpr inline stag(storage_type const& values);
constexpr inline stag(storage_type&& values);
Size of the tag can be obtained by calling size:size(); tuple containing all values in the tag is returned by values(); and value at the highest available level is returned by key().
storage_type const& values() const noexcept;
size_type size() const noexcept;
auto key() const noexcept;
frq::stag_t type alias provides way to defined stag type at the highest level for specified list of type:
template<typename... Tys>
using stag_t = ;
Dynamic Tags
Dynamic tags have no restriction on size or type of values at each level. Tag size can increase in run-time and types of values can differ for each level and even for the children of the same parent:
| Level: | 0 | 1 | 1 |
| Dynamic Tag #1 | 8 | "x" | 12.3 |
| Dynamic Tag #2 | 8 | 7.9 | |
| Dynamic Tag #3 | "y" | 8 | |
This is achieved through type erasure. Types that are stored in dynamic tag have to support hashing and equality comparison. Values are shared by the dynamic tags, so tags store only references to the values unlike the static tags.
frq::dtag class template is only parameterized by allocator used for type erasure purposes:
template<typename Alloc = std::allocator<dtag_node>>
class dtag;
Values stored in dynamic tags are wrapped by frq::dtag_node abstract type that does type erasure. frq::dtag_node provides interface for hashing, equality comparison and string formatting of stored values.
class dtag_node {
public:
virtual ~dtag_node() {
}
virtual std::size_t hash() const noexcept = 0;
virtual bool equal(dtag_node const& other) const noexcept = 0;
virtual std::string get_string() const = 0;
};
User can interact with values through frq::dtag_value type, which is a regular type providing access to underlying node storing actual value.
class dtag_value {
public:
dtag_node_ptr::element_type const& node() const;
std::size_t hash() const noexcept;
std::string get_string();
bool operator==(dtag_value const& rhs) const noexcept;
bool operator!=(dtag_value const& rhs) const noexcept;
};
frq::dtag can be constructed from sequence of dtag_values or by providing list of arguments to the constructor which will initialize corresponding values in the tag. Hashing operation and equality comparison can be provided which is going to be used by constructed dtag_node.
template<tag_iterator Iter>
dtag(allocator_type const& alloc, Iter first, Iter last);
template<tag_iterator Iter>
dtag(Iter first, Iter last);
template<typename HashCmp, typename... Tys>
dtag(allocator_type const& alloc, HashCmp const& hash_cmp, Tys&&... args);
template<typename... Tys>
dtag(construct_tag_alloc_t, allocator_type const& alloc, Tys&&... args);
template<typename HashCmp, typename... Tys>
dtag(construct_tag_hash_cmp_t, HashCmp const& hash_cmp, Tys&&... args);
template<typename... Tys>
dtag(construct_tag_default_t , Tys&&... args);
Dynamic tags offer the similar interface as static tags. They can provide: size(); vector of tag_values containing references to values in the tag: values(); and tag_value at the highest available level: key(). Additional accessor is provided that allows user to get tuple of values stored in tag: pack(). Number and types of template arguments provided to pack function template must match number and types of values stored in the tag, otherwise behavior is undefined.
storage_type const& values() const noexcept;
size_type size() const noexcept;
template<typename... Tys>
auto pack() const;
auto key() const noexcept;
frq::default_hash_compare type, that is used in case user type is not provided during tag construction, forwards hash computation to std::hash<T> and equality comparison to std::equal_to<T>.
struct default_hash_compare {
template<typename Ty>
std::size_t hash(Ty const& value) const noexcept;
template<typename Ty>
bool equal_to(Ty const& left, Ty const& right) const noexcept;
};
Runques
Runque represents queue of items ready to be served to consumers for processing. Order in which ready items are consumed can be configured by the user. Three options are available:
- FIFO - the first item made available gets served first
- LIFO - the last item made available gets served first
- Priority - available item with highest user-defined priority gets served first
frq::make_runque_t metafunction offers a way to configure desired runque:
template<typename Order,
typename Mtm,
typename Ty,
typename Alloc,
typename... Rest>
using make_runque_t = ;
Order defines in which order ready items are consumed. One of the following options are available:
fifo_orderlifo_orderpriority_order
Mtm defines multithreading model. Only coro_thread_model is implemented.Ty is type of items stored in runque.Alloc is obviously allocator used by queue itself.Rest can be used for passing additional parameters to desired runque type. In case of priority_order, it defines LessThen operation passed to underlying priority queue.
Ty parameter is not the same as user type on which forque operates. It is a wrapping type that allows consumer to control item’s lifetime. The type also provides a way to notify forque that item has been processed so it can ready next related item, if available.
Type returned by make_runque_t metafunction will satisfy runlike concept which is defined as:
template<typename Ty>
concept runlike = requires(Ty s) {
typename Ty::value_type;
requires runnable<typename Ty::value_type>;
typename Ty::get_type;
{ s.get() } ->std::same_as<typename Ty::get_type>;
{ s.put(std::declval<typename Ty::value_type&&>()) };
};
where
value_type is type of items stored in the queue which needs to satisfy runnable concept,get_type is return type of get() member function that yields next available item,get is a function returning next available item, andput is function adding item to the queue.
runnable concept is rather simple. It only requires non-throwing move constructor:
template<typename Ty>
concept runnable =
std::is_nothrow_move_constructible_v<Ty> && !std::is_reference_v<Ty>;
User’s only responsibility is to configure desired runque type and to provide it to forque. User will not interact with runque directly.
Example
An example of application use of forque can be found in ./src/app/ directory. It is using dynamic tags with several producers and simple consumers that just outputs consumed items to the console.
The example has a rather simple thread pool implementation that provides context for the execution of consumer’s and producer’s coroutines, but it is out of the scope of this article.
The first thing we do is select tag type and configure runque and forque types:
using tag_type = frq::dtag<>;
using reservation_type = frq::reservation<item>;
using retainment_type = frq::retainment<item>;
using runque_type = frq::make_runque_t<frq::fifo_order,
frq::coro_thread_model,
retainment_type,
std::allocator<retainment_type>>;
using queue_type = frq::forque<item, runque_type, tag_type>;
generate_tag function gives an example how to generate dynamic tag of arbitrary size:
auto tag_size = tag_size_dist(rng);
while (tag_size-- > 0) {
auto node = frq::make_dtag_node<int>(std::allocator<frq::dtag_node>{},
frq::default_hash_compare{},
tag_value_dist(rng));
tag_values.push_back(std::move(node));
}
return tag_type{begin(tag_values), end(tag_values)};
produce function is a coroutine that produces items in the two phases:
auto tag = generate_tag(rng);
auto item = co_await queue.reserve(tag);
co_await p.yield();
co_await item.release({tag, value});
In the first phase, we reserve the place for the item in queue. In the second phase, we populate the item with the actual value which will make item available for consumption.
Call to yield actually puts the rest of the coroutine back at the end of the thread pool’s queue. Since production is done in a loop without any waiting, this gives consumers opportunity to start consuming items before we end the loop.
Each producer generates certain number of items and after the last producer has finished the production, it initiates shutdown of the forque:
if (--producers == 0) {
co_await queue.interrupt();
}
consume function is a coroutine that consumes ready items from the forque:
try {
auto item = co_await queue.get();
co_await p.yield();
co_await item.finalize();
}
catch (frq::interrupted&) {
break;
}
As with producer, there are two phases. In the first phase, we wait and obtain item from the queue and in the second phase, after the processing is done, item is released.
yield call in the middle simulates asynchronous processing by putting the rest of the coroutine at the end of thread pool’s queue.
Processing is wrapped in try/catch block so it can abort consumption coroutione after the shutdown of the forque.

