Here we will learn how to perform object detection with a pre-trained MobileNet model in Python. We will implement the complete pipeline from loading the model up to interpreting and displaying results.
In this article, we continue learning how to use AI to build a social distancing detector. Specifically, we will learn how to detect objects in images with TensorFlow. Then, we will annotate the detected objects with the methods we previously developed.
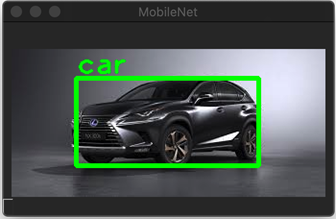
By the end of the article, you will have Python code that generates the results shown below. The companion code is here.

Prerequisites
I started by downloading a pre trained TensorFlow model from here. The package contains two files:
- detect.tflite – The pre-trained model saved in the TensorFlow Lite format. We will use this file to perform object detection.
- labelmap.txt – A text file containing the labels for the detected objects.
The selected model (detect.tflite) returns several pieces of information about detected objects, including:
- Bounding box – The rectangle surrounding the detected object.
- Class ID – An identifier of the class, describing the detected object. Given this ID, you get the object label from the labelmap.txt file.
- Score – The detection confidence, typically expressed as floating-point values between 0 and 1. The larger the value, the higher the confidence.
Getting Started
Given the above, I started by implementing the Inference class (inference.py), where I defined two methods: load_model_and_configure and load_labels_from_file. Both methods are invoked within the initializer of the Inference class. The first method, load_model_and_configure, looks like this:
from tensorflow import lite as tflite
def load_model_and_configure(self, model_path)
self.interpreter = tflite.Interpreter(model_path)
self.interpreter.allocate_tensors()
self.input_details = self.interpreter.get_input_details()
self.output_details = self.interpreter.get_output_details()
self.input_image_height = self.input_details[0]['shape'][1]
self.input_image_width = self.input_details[0]['shape'][2]
The load method accepts one argument, model_path. It points to the location of the *.tflite file. Then, I load this file using the Interpreter class from TensorFlow Lite. I store the resulting object in the interpreter field of the Inference class. Then, I allocate memory (allocate_tensors), keep the input and output of the model. To do so, I use get_input_details and get_output_details from the Interpreter class. Finally, I read the dimensions of the images accepted at the model input using the input details. Models can be pre-trained to get images in the specific format only. Depending on the model, you can change the input sizes using resize_tensor_input of the interpreter class. Here, I am adjusting the input image to the model requirements using the prepare_image method (see below). The method converts the color channels arrangement from BGR (blue-green-red) to RGB, and then resizes the image to the dimension expected by the model. Both steps are performed using OpenCV.
def prepare_image(self, image)
image = opencv.cvtColor(image, opencv.COLOR_BGR2RGB)
new_size = (self.input_image_height, self.input_image_width)
image = opencv.resize(image, new_size, interpolation = opencv.INTER_AREA)
return image
To read object labels from a file I implemented the following method:
def load_labels_from_file(self, file_path):
with open(file_path, 'r') as file:
self.labels = [line.strip() for line in file.readlines()]
I read the contents of the file and store the resulting collection of strings in the labels field of the Inference class.
I use the above method and load_model_and_configure to initialize the Inference class as shown below. This ensures that the model and labels will be ready before performing object detection.
class Inference(object):
def __init__(self, model_file_path, labels_file_path):
self.load_model_and_configure(model_file_path)
self.load_labels_from_file(labels_file_path)
Object Detection
With the model and labels ready to go, we can perform object detection. The general flow here is that you first set the input image or a sequence of images as the input tensor. You do this through the tensor member of the Interpreter class instance. Here is the example from the Inference class:
def set_input_tensor(self, image):
tensor_index = self.input_details[0]['index']
input_tensor = self.interpreter.tensor(tensor_index)()[0]
input_tensor[:,:] = image
This method reads the input tensor index, and then sets the tensor to the image passed as the parameter.
The next step is to perform the inference using the invoke method of the Interpreter class and read the inference results from the output tensor. The number of output details will vary depending on the model. The model I used here returns bounding boxes, class identifiers, and scores. I read them with the get_output_details helper method (it returns a tensor at the given index):
def get_output_tensor(self, index):
tensor = self.interpreter.get_tensor(self.output_details[index]['index'])
return np.squeeze(tensor)
To handle the full workflow for detecting objects, I implemented the following method:
def detect_objects(self, image, threshold)
input_image_size = image.shape[-2::-1]
image = self.prepare_image(image)
self.set_input_tensor(image)
self.interpreter.invoke()
boxes = self.get_output_tensor(0)
classes = self.get_output_tensor(1)
scores = self.get_output_tensor(2)
results = []
for i in range(scores.size):
if scores[i] >= threshold:
result = {
'rectangle': self.convert_bounding_box_to_rectangle_points(
boxes[i], input_image_size),
'label': self.labels[int(classes[i])],
}
results.append(result)
return results
After obtaining the collection of inference results, I filter out the detection results by removing all detections with a score below the threshold. This threshold comes from the last parameter of the detect_objects method. The detect_objects method will thus return a list of objects, each of which has two properties: rectangle and label.
Also note that the bounding box (four-element array) returned by the TensorFlow model is expressed in the normalized units. The coordinates of the top left corner (first two elements of the array) as well as the bottom right corner (third and fourth elements) have fractional values. They were divided by the height and width of the input image (the one passed to the model). So, to recover the location of the bounding box in the input image, we need to multiply the values by width and height of the input image. I do that using the following method:
def convert_bounding_box_to_rectangle_points(self, bounding_box, input_image_size):
width = input_image_size[0]
height = input_image_size[1]
top_left_corner = (int(bounding_box[1] * width), int(bounding_box[0] * height))
bottom_right_corner = (int(bounding_box[3] * width), int(bounding_box[2] * height))
return (top_left_corner, bottom_right_corner)
The method returns two values: top_left_corner, and bottom_right_corner. I then use them to draw the rectangle using OpenCV as explained below.
Displaying Results
After running the inference, I annotate detected objects. To do so, I use OpenCV's rectangle, and putText methods, described in the previous article. The corresponding functionality is implemented within a static method draw_rectangle_and_label in the ImageHelper class (see companion code), which takes the single inference result and draws the rectangle and a label on the image. I invoke this method for each element in the list returned by detect_objects. Finally, as shown below, I display the image using imshow function from OpenCV:
def display_image_with_detected_objects(image, inference_results):
opencv.namedWindow(common.WINDOW_NAME, opencv.WINDOW_GUI_NORMAL)
for i in range(len(inference_results)):
current_result = inference_results[i]
ImageHelper.draw_rectangle_and_label(
image, current_result['rectangle'], current_result['label'])
opencv.imshow(common.WINDOW_NAME, image)
opencv.waitKey(0)
Putting Things Together
We can now put all of the above the pieces together to write the main part of the application (see main.py from the companion code):
import common
from image_helper import ImageHelper as imgHelper
from inference import Inference as model
if __name__ == "__main__":
model_file_path = '../Models/01_model.tflite'
labels_file_path = '../Models/02_labels.txt'
ai_model = model(model_file_path, labels_file_path)
image = imgHelper.load_image('../Images/Lena.png')
score_threshold = 0.5
results = ai_model.detect_objects(image, score_threshold)
imgHelper.display_image_with_detected_objects(image, results)
As shown above, we load the model and labels from the Models subfolder. Then, we configure the model, load the image, and perform inference with a threshold of 0.5. This means that detections below 50% confidence will be rejected. Finally, we display the image with annotated detected objects. After running main.py you will get the results depicted earlier.
Summary
We learned how to perform object detection with a pre-trained MobileNet model in Python. We implemented the complete pipeline from loading the model up to interpreting and displaying results. We are now ready to detect more people in the images and calculate the distance between them. We will cover that in the next article.
Useful Links

