After learning how to employ TensorFlow and a pre-trained MobileNet model, we move forward to combine our detector with a web camera. By the end of this article, you will know how to run object detection on video sequences, as shown below.
You can find the companion code here.
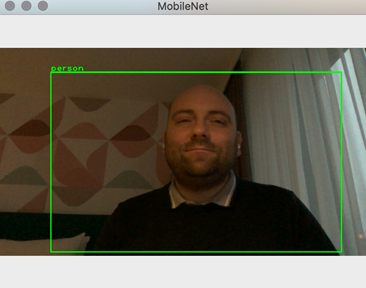
Camera Capture
I started by implementing the Camera class, which helps capture frames from the webcam (see camera.py in Part_04). To do so, I am using OpenCV. In particular, I am using the VideoCapture class. I get the reference to the default webcam and store it in the camera_capture field:
def __init__(self):
try:
self.camera_capture = opencv.VideoCapture(0)
except expression as identifier:
print(identifier)
To capture a frame, use the read method of the VideoCapture class instance. It returns two values:
status – A boolean variable representing the status of the capture.frame – The actual frame acquired with the camera.
It is good practice to check the status before using the frame. Additionally, on some devices, the first frame might appear blank. The capture_frame method from the Camera class compensates by ignoring the first frame, depending on the input parameter:
def capture_frame(self, ignore_first_frame):
if(ignore_first_frame):
self.camera_capture.read()
(capture_status, current_camera_frame) = self.camera_capture.read()
if(capture_status):
return current_camera_frame
else:
print('Capture error')
The general flow of using the Camera class is to call the initializer once and then invoke capture_frame as needed.
Referencing Previously Developed Modules
To proceed further, we will use the previously developed Inference class and ImageHelper. To do so, we will use main.py, in which we reference those modules. The source code of those modules is included in the Part_03 folder and explained in the previous article.
To reference the modules, I supplemented main.py with the following statements (I assume that the main.py file is executed from the Part_04 folder):
import sys
sys.path.insert(1, '../Part_03/')
from inference import Inference as model
from image_helper import ImageHelper as imgHelper
Now, we can easily access the object detector, and perform inference (object detection), even though the source files are in a different folder:
model_file_path = '../Models/01_model.tflite'
labels_file_path = '../Models/02_labels.txt'
ai_model = model(model_file_path, labels_file_path)
score_threshold = 0.5
results = ai_model.detect_objects(camera_frame, score_threshold)
Putting Things Together
We just need to capture the frame from the camera and pass it to the AI module. Here is the complete example (see main.py):
import sys
sys.path.insert(1, '../Part_03/')
from inference import Inference as model
from image_helper import ImageHelper as imgHelper
from camera import Camera as camera
if __name__ == "__main__":
model_file_path = '../Models/01_model.tflite'
labels_file_path = '../Models/02_labels.txt'
ai_model = model(model_file_path, labels_file_path)
camera_capture = camera()
camera_frame = camera_capture.capture_frame(False)
score_threshold = 0.5
results = ai_model.detect_objects(camera_frame, score_threshold)
imgHelper.display_image_with_detected_objects(camera_frame, results)
After running the above code, you will get the result shown in the introduction.
Wrapping Up
We developed a Python console application that performs object detection in a video sequence from a webcam. Although it was a single frame inference, you can extend the sample by capturing and calling the inference in a loop, continuously displaying the video stream, and invoking the inference on demand (by pressing the key on a keyboard, for example). We will perform object detection on the frames from the test data sets including video sequence stored in the video file in the next article.

