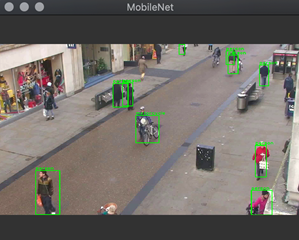
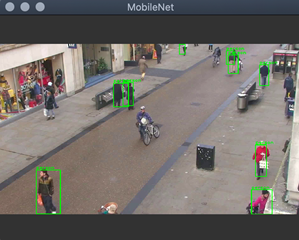
Here we will employ the MobileNet object detector to find people in a video sequence. After running the code, we note that the detections are not perfect.
Object detectors are usually applied to video streams from various cameras. Sometimes you perform object detection in post-processing, where you are given the complete video file and must look for specific objects. In this article, we will start by doing just that. Then, we will see how to filter out the detection results to show only people. We will achieve the results shown in the figures below (note the figure on the right does not detect a bicycle).
For object detection, we use TensorFlow and MobileNet models. The video sequence comes from this link. All the companion code is here.
Reading a Video File
To read the video file, I created a VideoReader class (see video_reader.py in the Part_05 folder). Internally, this class employs OpenCV's VideoCapture. My use of VideoCapture is quite similar to the previous case, back when we were reading frames from the camera. The major difference is that I need to pass the file path to the VideoCapture initializer:
def __init__(self, file_path):
try:
self.video_capture = opencv.VideoCapture(file_path)
except expression as identifier:
print(identifier)
Then, I read the consecutive frames from the file by invoking the read method of the VideoCapture class instance:
def read_next_frame(self):
(capture_status, frame) = self.video_capture.read()
if(capture_status):
return frame
else:
return None
To use the VideoReader class, first invoke the initializer to provide the input video file, then invoke the read_next_frame method as many times as needed to read the frames. When the method reaches the end of the file, it will return None.
People Detection
To detect people, I started with the modules I created previously, including the Inference and ImageHelper classes. We will reference them in main.py. The source code of those modules is included in the Part_03 folder and explained in a previous article.
To reference the modules, I supplemented the main.py file with the following statements, assuming that the main script is executed from the Part_05 folder:
import sys
sys.path.insert(1, '../Part_03/')
from inference import Inference as model
from image_helper import ImageHelper as imgHelper
Consequently, we can easily access the object detection on the frames of the video file:
model_file_path = '../Models/01_model.tflite'
labels_file_path = '../Models/02_labels.txt'
ai_model = model(model_file_path, labels_file_path)
video_file_path = '../Videos/01.mp4'
video_reader = videoReader(video_file_path)
frame = video_reader.read_next_frame()
score_threshold = 0.5
results = ai_model.detect_objects(frame, score_threshold)
However, the problem is that we detect all the objects that the model was trained for. To detect only people, we need to filter the results returned by the detect_objects method. For filtering purposes, we use the label of the detected object. The filtering method can be implemented as follows:
def detect_people(self, image, threshold):
all_objects = self.detect_objects(image, threshold)
people = filter(lambda r: r['label'] == 'person', all_objects)
return list(people)
I added the above method, detect_people, to the Inference class (see inference.py in the Part_03 folder). A detect_people function internally invokes detect_objects and then filters the results using filter, a built-in Python function. The first parameter is the filtering method. Here, I use an anonymous lambda function that returns a boolean value. It is True when the label of the current detection result is "person", and False otherwise.
Displaying Detection Results
To display the detected people, I use the static display_image_with_detected_objects method from the image_helper module. However, the display_image_with_detected_objects method was intended to display the image until the user presses a key. If I use it for a video sequence, the user would need to press the key for each frame. To adapt it for videos, I modified the method by adding another parameter: delay. I pass the value of this parameter to OpenCV's waitKey method to impose the waiting timeout:
@staticmethod
def display_image_with_detected_objects(image, inference_results, delay = 0):
opencv.namedWindow(common.WINDOW_NAME, opencv.WINDOW_GUI_NORMAL)
for i in range(len(inference_results)):
current_result = inference_results[i]
ImageHelper.draw_rectangle_and_label(image,
current_result['rectangle'], current_result['label'])
opencv.imshow(common.WINDOW_NAME, image)
opencv.waitKey(delay)
By default, the delay is 0, so the method will still work with calls to it that expect it to wait for a keypress.
Putting Things Together
With all the components ready, we can put them together:
import sys
sys.path.insert(1, '../Part_03/')
from inference import Inference as model
from image_helper import ImageHelper as imgHelper
from video_reader import VideoReader as videoReader
if __name__ == "__main__":
model_file_path = '../Models/01_model.tflite'
labels_file_path = '../Models/02_labels.txt'
ai_model = model(model_file_path, labels_file_path)
video_file_path = '../Videos/01.mp4'
video_reader = videoReader(video_file_path)
score_threshold = 0.4
detect_only_people = False
delay_between_frames = 5
while(True):
frame = video_reader.read_next_frame()
if(frame is None):
break
if(detect_only_people):
results = ai_model.detect_people(frame, score_threshold)
else:
results = ai_model.detect_objects(frame, score_threshold)
imgHelper.display_image_with_detected_objects(frame, results, delay_between_frames)
There are two switches here to control the script execution. First, there's the detect_only_people variable, which controls whether the script detects all objects (False) or only people (True). Second, there's the delay_between_frames variable, which controls the delay between frames and therefore the speed of a result's preview. By default, I set it to 5 ms.
Wrapping Up
In this article, we employed the MobileNet object detector to find people in a video sequence. After running the code, we note that the detections are not perfect. Some people are not recognized. This is not improved even if the detection score is reduced. We will deal with this problem later by using a more robust object detection. But first, we will learn how to calculate the distance between people in images to check if they are too close.

