Here we implement the final version of our application to indicate people violating social distancing rules, given an image from a camera or a video file.
We already know how to detect people in images from a webcam or video file and calculate the distances between them. However, we found that the underlying AI model (MobileNet) does not always perform well. Namely, it cannot detect all people in the image.
We'll improve this by employing the state-of-the-art YOLO (You Only Look Once) object detector. There are many tutorials and descriptions of YOLO on the web, so, I won't discuss it here in detail. I will focus on adapting our application to use YOLO instead of MobileNet. In the end, we will achieve the results shown in the image below. You can find the companion code with all the necessary model and video files here.
Loading YOLO Object Detection
To use YOLO for object detection, follow the same path as for MobileNet.
Specifically, first load and configure the model. Then, preprocess the input image such that it is compatible with the YOLO input. Next, run inference and parse results at the output of the YOLO neural network.
I implemented all of the above operations within the YoloInference class (see yolo_inference.py in the Part_08 folder). I started by loading the YOLO model. A pre-trained model consists of three files:
- config – Contains parameters for the YOLO neural network.
- weights – Stores weights for the neural network.
- labels – A text file with labels for detected objects.
In MobileNet, the config and weights were in a single *.tflite file. Here, the two are split.
To load the YOLO network, I use OpenCV's readNetFromDarknet method from the DNN (Deep Learning Network) module. It returns an object that represents the network (it is like Interpreter in TensorFlow). Given that interpreter I can get the information about the network output (refer to the YoloInference class):
def load_model_and_configure(self, config_file_path, weights_file_path):
self.interpreter = opencv.dnn.readNetFromDarknet(config_file_path, weights_file_path)
layer_names = self.interpreter.getLayerNames()
self.output_layers =
[layer_names[i[0] - 1] for i in self.interpreter.getUnconnectedOutLayers()]
self.input_image_size = (608, 608)
self.scaling_factor = 1 / 255.0
Note that the above method also sets two members of the YoloInference class:
input_image_size – Stores the size of the image passed to the YOLO network. I obtained those values from the config file.scaling_factor – A number that is used to multiply each image pixel before inference. With this scaling, the image pixels will be converted from integers (with values of 0 to 255) to floats (with values of 0 to 1).
Then, I invoke the load_model_and_configure function within the YoloInference class constructor. Additionally, I also load labels (using the same method as for MobileNet):
def __init__(self, config_file_path, weights_file_path, labels_file_path):
self.load_model_and_configure(config_file_path, weights_file_path)
self.load_labels_from_file(labels_file_path)
Running Inference
After loading the model, we can prepare the input image and then run inference. To preprocess the image, I use the following method:
def prepare_image(self, image):
blob = opencv.dnn.blobFromImage(image, self.scaling_factor,
self.input_image_size, swapRB=True, crop=False)
return blob
The method invokes blobFromImage from OpenCV's DNN module. The method accepts the pixel scaling factor and image size. There are two additional parameters: swapRB and crop. The first one will swap the red and blue channels. This is required as OpenCV's image has a BGR color channel ordering. After the swap, the color channels will be in RGB order. The second parameter indicates whether the image should be cropped to the expected input size.
Then, I run the inference (see the detect_people function in YoloInference):
image = self.prepare_image(image)
self.interpreter.setInput(image)
output_layers = self.interpreter.forward(self.output_layers)
The information about detected objects is encoded in the output_layers variable. That is the list of network outputs. We then need to parse those outputs to get detection results.
Interpreting the Results
To process the output layers, I use two for loops. The first one goes over layers. The second one analyzes the detection results for each layer:
detected_people = []
for output_layer in output_layers:
for detection_result in output_layer:
object_info = self.parse_detection_result(input_image_size,
detection_result, threshold)
if(object_info is not None):
detected_people.append(object_info)
In the above code, I use the helper method parse_detection_result. It accepts three parameters:
input_image_size – The size of the original input image.detection_result – An object from the output layer.threshold – A score threshold. Detections whose scores are below this value will be rejected.
Given these inputs, the parse_detection_result method decodes the object label and its score and then looks for objects with the label 'person'. Finally, the method decodes the object's bounding box and converts it to a rectangle. This conversion is needed to make the code compatible with other parts of the application (for a conversion method, see yolo_inference.py of the companion code). Finally, the method wraps the rectangle, label, and score into a Python dictionary. There is one more object here: a box. I will use it later to improve object locations detection.
def parse_detection_result(self, input_image_size, detection_result, threshold):
label, score = self.get_object_label_and_detection_score(detection_result)
if(score > threshold and label == 'person'):
box = detection_result[0:4]
return {
'rectangle': self.convert_bounding_box_to_rectangle_points(
box, input_image_size),
'label': label,
'score': float(score),
'box' : self.adjust_bounding_box_to_image(box, input_image_size)
}
else:
return None
To decode the label and the score, I use another helper:
def get_object_label_and_detection_score(self, detection_result):
scores = detection_result[5:]
class_id = np.argmax(scores)
return self.labels[class_id], scores[class_id]
It takes the raw scores from the detection result, calculates the position of the maximum score and uses that to find the corresponding label.
Previewing Detected People
We can now test the YOLO detector using our video file. To do so, I use most of the components developed earlier, including a video reader, image helper, and distance analyzer. Additionally, I import the YoloInference class. Here is the complete script:
import sys
sys.path.insert(1, '../Part_03/')
sys.path.insert(1, '../Part_05/')
sys.path.insert(1, '../Part_06/')
from yolo_inference import YoloInference as model
from image_helper import ImageHelper as imgHelper
from video_reader import VideoReader as videoReader
from distance_analyzer import DistanceAnalyzer as analyzer
if __name__ == "__main__":
config_file_path = '../Models/03_yolo.cfg'
weights_file_path = '../Models/04_yolo.weights'
labels_file_path = '../Models/05_yolo-labels.txt'
ai_model = model(config_file_path, weights_file_path, labels_file_path)
video_file_path = '../Videos/01.mp4'
video_reader = videoReader(video_file_path)
score_threshold = 0.5
delay_between_frames = 5
while(True):
frame = video_reader.read_next_frame()
if(frame is None):
break
results = ai_model.detect_people(frame, score_threshold)
imgHelper.display_image_with_detected_objects(frame,
results, delay_between_frames)
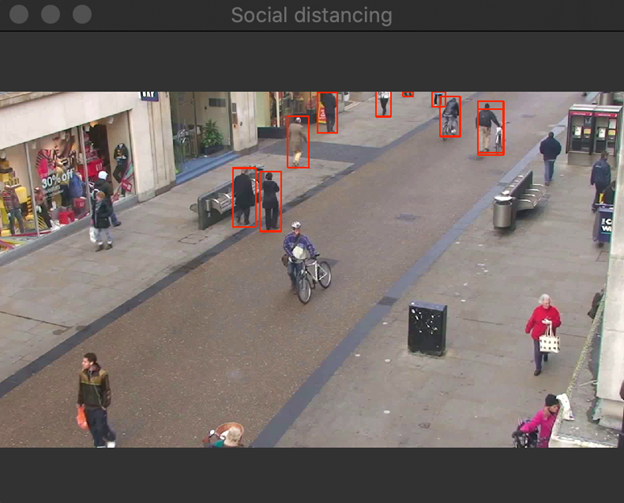
The script looks pretty much the same as the one we developed for MobileNet. The only difference is that we use YoloInference instead of Inference. After running the above code, you should get results shown in the image below. What is immediately apparent here is that YOLO detected every person in the image, but we have plenty of overlapping bounding boxes. Let's see how to remove them.
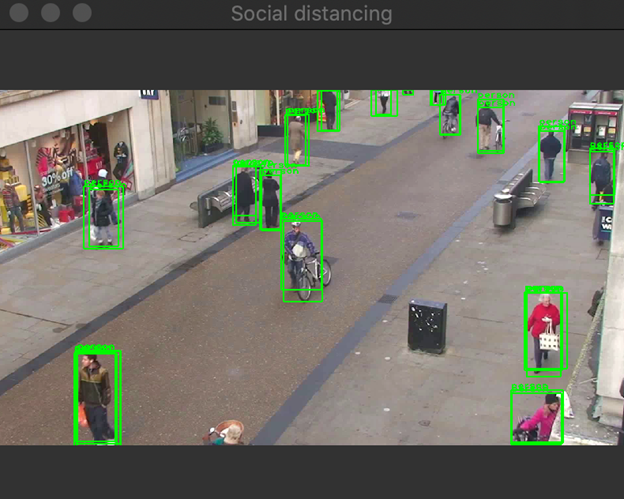
Filtering Out Overlapping Bounding Boxes
Out of each overlapping bounding box, we need to choose the best one (the one with the highest score). Thankfully, we do not need to implement everything from scratch. There is a dedicated function for that in OpenCV – NMSBoxes from DNN. It uses the non-maximum suppression (NMS) algorithm to filter out useless boxes.
NMSBoxes takes four input parameters:
boxes – The list of bounding boxes.scores – The list of detection scores.threshold – A threshold for the score.nms_threshold – A threshold used for NMS algorithm.
With the following code, I get the boxes and scores from the results returned by detect_people such that I only get the values from the corresponding field in the dictionary:
def get_values_from_detection_results_by_key(self, detection_results, dict_key):
return [detection_results[i][dict_key] for i in range(0, len(detection_results))]
Subsequently, to incorporate NMSBoxes, I supplemented the YoloInference class with another helper:
def filter_detections(self, detected_people, threshold, nms_threshold):
scores = self.get_values_from_detection_results_by_key(detected_people, 'score')
boxes = self.get_values_from_detection_results_by_key(detected_people, 'box')
best_detections_indices = opencv.dnn.NMSBoxes(boxes,
scores, threshold, nms_threshold)
return [detected_people[i] for i in best_detections_indices.flatten()]
Finally, I invoke filter_detections in detect_people as follows:
def detect_people(self, image, threshold):
input_image_size = image.shape[-2::-1]
image = self.prepare_image(image)
self.interpreter.setInput(image)
output_layers = self.interpreter.forward(self.output_layers)
detected_people = []
for output_layer in output_layers:
for detection_result in output_layer:
object_info = self.parse_detection_result(input_image_size,
detection_result, threshold)
if(object_info is not None):
detected_people.append(object_info)
nms_threshold = 0.75
detected_people = self.filter_detections(detected_people, threshold, nms_threshold)
return detected_people
Putting Things Together
With all of the above pieces, we can now modify the main script as follows (for the full code, see main.py in the Part_08 folder):
frame = video_reader.read_next_frame()
if(frame is None):
break
results = ai_model.detect_people(frame, score_threshold)
proximity_distance_threshold = 150
people_that_are_too_close = analyzer.find_people_that_are_too_close(
results, proximity_distance_threshold)
imgHelper.indicate_people_that_are_too_close(
frame, people_that_are_too_close, delay_between_frames)
The script sets up the AI model, opens the sample video file, and finds people who are too close. Here, I set the distance threshold to 150 pixels. After running main.py, you will get the results shown in the introduction, achieving our goal of an AI-powered social distancing detector.
Wrapping Up
In this article, we implemented the final version of our application to indicate people violating social distancing rules, given an image from a camera or a video file.
We started this exciting journey by learning about computer vision tasks (image acquisition and display) with OpenCV. Then, we learned about image annotations, object detection with TensorFlow Lite, and how to calculate distances between detected objects. Finally, we incorporated the state-of-the-art YOLO object detector to make our app more robust.
With that, our journey comes to an end. I hope you enjoyed this article series! I encourage you to expand on what we've done and perhaps even find another application for it.

