In this post, you will see a basic workflow and learn how to attack any problem for an insight using Machine learning.
Let’s have a quick look into basic workflow when we apply Machine Learning to a problem.

A short brief about Machine Learning, its association with AI or Data Science world is here.
How Does Machine Learning Help?
Machine Learning is about having a training algorithm that helps predict an output based on the past data. This input data can keep on changing and accordingly, the algorithm can fine tune to provide better output.
It has vast applications across. For example, Google is using it to predict natural disasters like floods. A very common use we hear these days in news are usage in Politics and how to attack the demography of voters.
How Does Machine Learning Work?
Data is the key here. More the data is, better the algorithm can learn and fine tune. For any problem output, there would be multiple factors at play. Some of them would have more affect then others. Analyzing and applying all such findings are part of a machine learning problem. Mathematically, ML converts a problem output as a function of multiple input factors.
Quote:
Y = f(x)
Y = predicted output
x = multiple factors as an input
How Does a Typical ML Workflow Look?
There is a structured way to apply ML on a problem. I tried to put the workflow in a pictorial view to easily visualize and understand it:
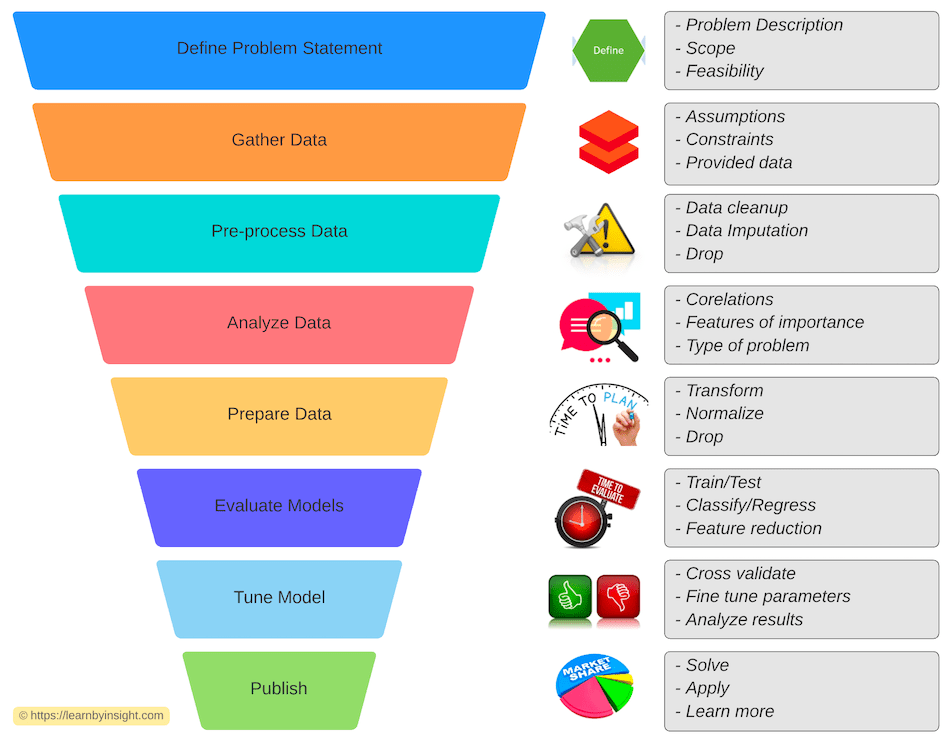
It’s goes in a cycle and once we have some insights from the published model, it goes back into the funnel as learning to make output better.
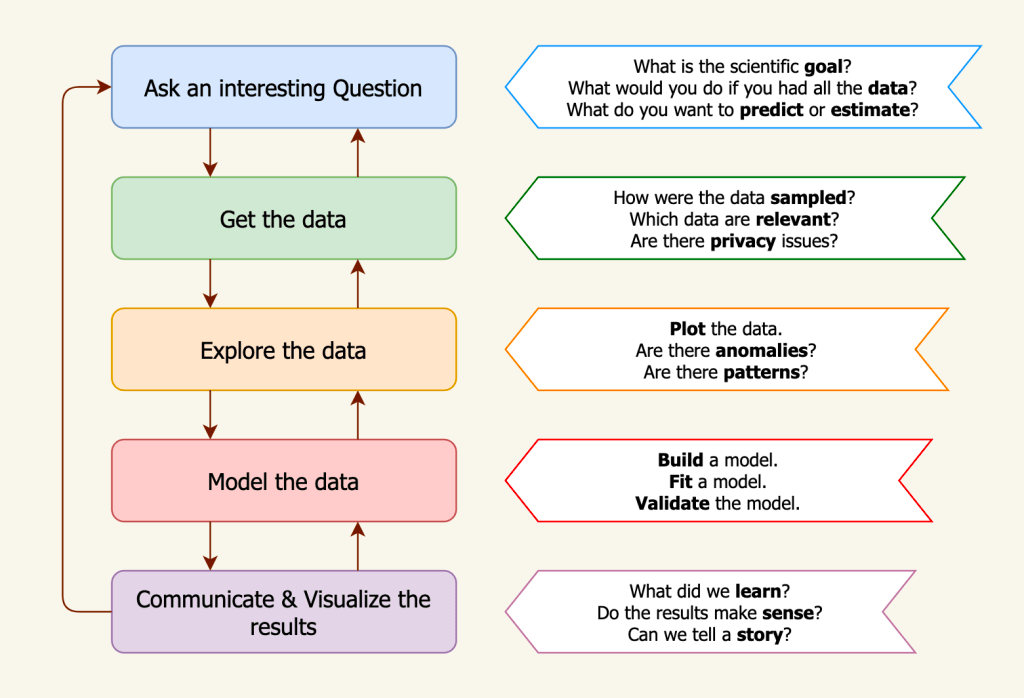
Quote:
Roughly, Data scientists spend 60% of their time on cleaning and organizing data
Walk Through an Example?
Let’s use dataset of Titanic survivors found here and run through basic workflow to see how certain features like traveling class, sex, age and fare are helping us assess survival probability.
Load Data From File
Data could be in various formats. Easiest is to have it in a csv and then load it using pandas. More details around how to play with data is discussed here.
titanicdf = pd.read_csv("data-files/titanic.csv")
print(titanicdf.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 pclass 1309 non-null int64
1 survived 1309 non-null int64
2 name 1309 non-null object
3 sex 1309 non-null object
4 age 1046 non-null float64
5 sibsp 1309 non-null int64
6 parch 1309 non-null int64
7 ticket 1309 non-null object
8 fare 1308 non-null float64
9 cabin 295 non-null object
10 embarked 1307 non-null object
11 boat 486 non-null object
12 body 121 non-null float64
13 home.dest 745 non-null object
dtypes: float64(3), int64(4), object(7)
memory usage: 143.3+ KB
None
titanicdf.head(3)
| | pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest |
| 0 | 1 | 1 | Allen, Miss. Elisabeth Walton | female | 29 | 0 | 0 | 24160 | 211.3375 | B5 | S | 2 | NaN | St Louis, MO |
| 1 | 1 | 1 | Allison, Master. Hudson Trevor | male | 0.9167 | 1 | 2 | 113781 | 151.55 | C22 C26 | S | 11 | NaN | Montreal, PQ / Chesterville, ON |
| 2 | 1 | 0 | Allison, Miss. Helen Loraine | female | 2 | 1 | 2 | 113781 | 151.55 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON |
Data Cleanup – Drop the Irrelevant Columns
It’s not always that the data captured is the only data you need. You will have a superset of data that has additional information which are not relevant for your problem statement. This data will work as a noise and thus it’s better to clean the dataset before starting to work on them for any ML algorithm.
titanicdf.drop(['embarked','body','boat','name',
'cabin','home.dest','ticket', 'sibsp', 'parch'],
axis='columns', inplace=True)
titanicdf.head(2)
| | pclass | survived | sex | age | fare |
| 0 | 1 | 1 | female | 29 | 211.3375 |
| 1 | 1 | 1 | male | 0.9167 | 151.55 |
Data Analysis
There could be various ways to analyze data. Based on the problem statement, we would need to know the general trend of the data in discussion. Statistics Probability Distribution knowledge help here. For gaining insights to understand more around correlations and patterns, data visualization based insights help.
import seaborn as sns
sns.pairplot(titanicdf)

Data Transform – Ordinal/Nominal/Datatype, etc.
In order to work through data, it’s easy to interpret once they are converted into numbers (from strings) if possible. This helps them input them into various statistics formulas to get more insights. More details on how to apply numerical modifications to data is discussed here.
titanicdf = pd.get_dummies(titanicdf,
columns=['pclass'])
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
titanicdf["sex"] = le.fit_transform(titanicdf.sex)
titanicdf.head(2)
| | survived | sex | age | fare | pclass_1 | pclass_2 | pclass_3 |
| 0 | 1 | 0 | 29 | 211.3375 | 1 | 0 | 0 |
| 1 | 1 | 1 | 0.9167 | 151.55 | 1 | 0 | 0 |
Data Imputation: Fill the Missing Values
There are always some missing data or an outlier. Running algorithms with missing data could lead to inconsistent results or algorithm failure. Based on the context, we can choose to remove them or fill/replace them with an appropriate value.
titanicdf.loc[ titanicdf["age"].isnull(), "age" ] =
titanicdf["age"].mean()
titanicdf.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 7 columns):
--- ------ -------------- -----
0 survived 1309 non-null int64
1 sex 1309 non-null int64
2 age 1309 non-null float64
3 fare 1308 non-null float64
4 pclass_1 1309 non-null uint8
5 pclass_2 1309 non-null uint8
6 pclass_3 1309 non-null uint8
dtypes: float64(2), int64(2), uint8(3)
memory usage: 44.9 KB
titanicdf.dropna(inplace=True)
titanicdf.info()
Normalize Training Data
At times, various data in context are of different scales. In such cases, if the data is not normalized, algorithm can induce bias towards the data that has higher magnitude. E.g., feature A value range is 0-10 and feature B range is 0-10000. In such case, even though a small change in magnitude of A can make a difference but if data is not normalized, feature B will influence results more (which could be not the actual case).
X = titanicdf
y = X['survived']
X = X.drop(['survived'], axis=1)
from sklearn import preprocessing
X_scaled = preprocessing.scale(X)
Split Data – Train/Test Dataset
It’s always best to split the dataset into two unequal parts. Bigger one to train the algorithm and then the smaller one to test the trained algorithm. This way, algorithm is not biased to just the input data and results for test data can provide better picture.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =
train_test_split(X_scaled,y)
X_train.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 981 entries, 545 to 864
Data columns (total 6 columns):
--- ------ -------------- -----
0 sex 981 non-null int64
1 age 981 non-null float64
2 fare 981 non-null float64
3 pclass_1 981 non-null uint8
4 pclass_2 981 non-null uint8
5 pclass_3 981 non-null uint8
dtypes: float64(2), int64(1), uint8(3)
memory usage: 33.5 KB
Run ML Algorithm Data
Once we have our training dataset ready as per our need, we can apply machine learning algorithms and find which model fits in best.
from sklearn.neighbors import KNeighborsClassifier
dtc = KNeighborsClassifier(n_neighbors=5)
dtc.fit(X_train,y_train)
Check the Accuracy of Model
In order to validate the model, we use test dataset where comparing the predicted value by model to actual data helps us know about ML model accuracy.
import sklearn.metrics as met
pred_knc = dtc.predict(X_test)
print( "Nearest neighbors: %.3f"
% (met.accuracy_score(y_test, pred_knc)))
Nearest neighbors: 0.817
Voila! With basic workflow, we have a model that can predict the survivor with more than 80% probability.
Download
Entire Jupyter notebook with more samples can be downloaded or forked from my GitHub to look or play around: https://github.com/sandeep-mewara/machine-learning
Currently, it covers examples on following datasets:
- Titanic Survivors
- Sci-kit Iris
- Sci-kit Digits
- Bread Basket Bakery
Quote:
Over time, I would continue building on the same repository with more samples with different algorithms.
Closure
Believe, now it’s pretty clear on how we can attack any problem for an insight using Machine learning. Try out and see for yourself.
We can apply Machine Learning to multiple problems in multiple fields. I have shared a pictorial view of sectors in the AI section that are already leveraging its benefit.
Keep learning!.

