The article and code illustrate usage of GraphQL under NestJS framework. GraphQL data access is optimized with data caching while preserving benefits of NestJS. Several libraries were developed to support JWT authentication, TLS, logging, configuration, custom guards and interceptors and other useful features.
Table of Contents
Introduction
NestJS is a framework for building efficient, scalable Node.js server-side applications. It uses progressive JavaScript, is built with and fully supports TypeScript (yet still enables developers to code in pure JavaScript) and combines elements of OOP (Object Oriented Programming), FP (Functional Programming), and FRP (Functional Reactive Programming). NestJS documentation may be found here.
GraphQL is an open-source data query and manipulation language for APIs, and a runtime for fulfilling queries with existing data. GraphQL was developed internally by Facebook in 2012 and was publicly released in 2015. Currently, the GraphQL project is running by GraphQL Foundation. It provides an approach to developing web APIs and has been compared and contrasted with REST and other web service architectures. It allows clients to define the structure of the data required, and the same structure of the data is returned from the server, therefore preventing excessively large amounts of data from being returned.
NestJS framework and GraphQL technology have become increasingly popular among Node.js developers. The former offers convenient support with minimum code to many useful features such as logging, OpenAPI (Swagger), TLS, login, to list just the few. The latter provides handy and flexible technique for data receiving in hierarhical format according to predefined schema with minimum network load. NestJS documentation has lengthy description of its support for GraphQL. The purpose of this work is submit a workable sample of a GraphQL component working in the NestJS based service.
Although the focal point of this work is implementation of GraphQL under NestJS, we will also address such important for modern service features as logging, secure communication, authentication and OpenAPI support. While the overall layout of the NestJS service with its modular structure is preserved, the bulk of functionality is placed into reusable libraries described below.
Let's outline the main requirements to the service.
- Optimization of fetching data from database
The purpose of our service is to accept client request for data, fetch required data from database and respond to the client with these data. Usage of GraphQL allows service to respond with only data requested by client and avoid sending extra data over network. But to achieve good performance, we need to optimize access to database. This can be achieved by minimizing number of queries to database and by fetching only data required by a client. Both these topics will be addressed below.
- Upload of GraphQL schema and resolvers on the start of a service
This feature allows service to work with any GraphQL schema (within given set of database entity types) without redeployment. The upload may be carried out either from disk (allowing easy debugging during development) or from Web for production environment.
- REST and OpenAPI support
The service should provide RESTful API for purposes like runtime tuning, configuration, health check, etc. OpenAPI support is useful for check, analysis and documentation of RESTful API.
- Authentication and authorization
These features allows service to identify client and its permission for actions required.
- Transport layer security (TLS)
This feature protects message from being read while travelling across the network. Usage of TLS has become virtually compulsory for modern services.
Overall structure of the sample software is depicted in Figure 1.
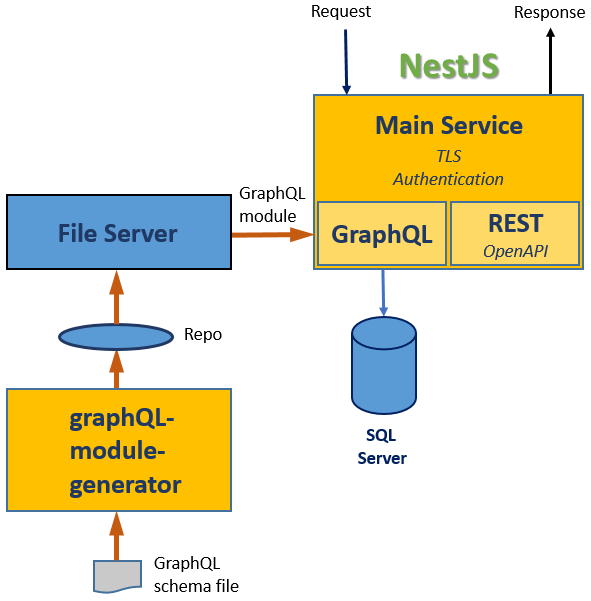
Figure 1. Sample structure.
The main service is a NestJS based service consisting of GraphQL and RESTful components. It uses a set of libraries placed in .\libs directory. The libraries implement common features used across the service and will be discussed below. Code for GraphQL support is mostly placed into gql-module-lib library with main functionality in its class Gql comprising of static methods. Application graphQL-module-generator generates GraphQL module file with a service class (please do not confuse NestJS service class with service application) and resolvers classes based on GraphQL schema. Simple 3rd party file server provides Web access to GraphQL schema and module for main service.
GraphQL implies usage of resolvers. NestJS documentation describes creation of the resolver types according to GraphQL schema and their integration with NestJS modules structure. This ensures calls of appropriate resolve functions by the framework during formation of a Web response hierarchical structure. The way how the resolve functions fetch actual data from database and/or other services is up to developer. If every resolve function issues a SELECT query, then overall number of those queries equals to a sum of return rows on each level of the hierarchy. For example, with this approach in our sample AllPersons query in the upmost level all n persons are fetched. Then on the second level SELECT query is executed n times to fetch affiliations and relations for each person. Similar picture is observed on each following level. Obviously, substantial amount of return rows causes large number of queries to database causing serious performance penalty. Number of queries to database in this case is
database_queries = Σ entries(level - 1)
levels
This problem is commonly referred to as N+1 problem. It is depicted in Figure 2.

Figure 2. Non-Optimized GraphQL.
In addition to performance problem, the above approach makes implementation of database transactions more difficult and inefficient. Clearly, data access has to be optimized.
Let's consider the following example. We have type Person which has several properties of scalar type, like name, surname, address, phone, etc. and two properties of complex types, such as affiliations, that is array of a complex Affiliation type, and relations, an array of a complex Relation type (appropriate GraphQL schema may be seen in file .\nestjs-graphql-service\gql\schema.gql). Complex types Affiliation and Relation in their turn are comprised of properties of scalar and complex types. As an example of query, we take query PersonBySurname that returns all persons (array of type Person) with given surname.
NestJS documentation recommends the way for creation of resolver classes with resolve methods below referred to as resolvers. During GraphQL query execution, the resolvers built according to these recommendations, are automatically called by the framework.
A way for an optimization is as follows: knowing return type of a GraphQL query, in the query resolver to fetch data for this type and subsequently for all its complex property types. Let's discuss GraphQL query PersonBySurname as an example. The query should return array of objects of type Person. So our first database query will be:
SELECT ... FROM persons WHERE surname = '...'
This query brings scalar properties of Person type for all persons with given surname. But type Person contains also properties of complex types, like affiliations and relations. To get them, we need to query appropriate database tables. In general, a query looks like this:
SELECT ... FROM ... WHERE id IN ( entries(level - 1) )
Similar procedure is performed for all internal properties of complex types.
The following set of SELECT database queries is produced by AllPerson GraphQL query from our code sample:
SELECT _id, id, givenName, surname, address FROM persons
SELECT _id, id, organization_id, role_id, person_id FROM affiliations _
WHERE person_id IN (6,7,8,9,10,11,12)
SELECT _id, id, name, address, parent_id FROM organizations WHERE _id IN (8,6,9,10,7)
SELECT _id, id, name, parent_id FROM organizations WHERE _id IN (6,7)
SELECT _id, id, name, description FROM roles WHERE _id IN (4,5,6)
SELECT _id, id, kind, p1_id, p2_id FROM relations WHERE p1_id IN (6,7,8,9,10,11,12)
SELECT _id, id, givenName FROM persons WHERE _id IN (10,7,8,9,6)
As you can see, number of database calls (SELECT-s) corresponds to number of inner levels of the GraphQL query and independent on number of fetched records on each level.
Interesting that the above set of SELECT-s contains some duplications. This happens due to entities relationship in the GraphQL schema. So strictly speaking, it is possible to achieve further database access reduction by checking cache before execution of SELECT. But this would lead to increase in code complexity and therefore was not implemented in this sample. These queries bring us all data required to fulfill GraphQL query.
Now, possessing all data required, we have to present them in structured order according to GraphQL query. But this problem has been already solved with the resolvers we already have. Return values of resolve methods will be automatically inserted into response object for GraphQL query. So we only need to provide those return values based on data we have already fetched from database in the GraphQL query resolver. The simplest way to achieve this is to place the fetched data into a cache object in memory and attach it to a context object available across all resolvers. The cache is organized as a dictionary with keys according to resolvers. Each resolver returns a piece of data extracted from the cache with appropriate key. Number of queries to database in this case is:
database_queries = levels
This procedure is depicted in Figure 3.
Figure 3. Optimized GraphQL.
These return values form response object to be sent back to client on fulfillment of GraphQL query. Since cache object is a property of a context object, it will be destroyed along with the context on the end of GraphQL query processing. So cache object is created for each client request and its lifetime corresponds to processing of this request.
Data acquisition optimization based on memory cache boosts performance. Its limitation is however in size of available operative memory (RAM). If cache object is too big to accommodate it in the single process memory, then distributed cache solutions such as Redis, Memcached or similar may be used. In this article, for simplicity, we assume simple in-process in-memory cache. Similar memory cache based solution is offered by Facebook with its dataloader package. But it should be adjusted to be used with NestJS.
We saw that resolver classes and their methods were constructed according to GraphQL schema as per rules explained in NestJS documentation. This structure being included in appropriate module, ensures the resolvers' calls by the framework in a proper order. Now we can go a step further and automatically generate resolvers based on GraphQL schema providing developer with resolver classes and methods, even partly implemented. This can be done with a separate gql-resolver-generator application. This application takes GraphQL schema as its input and generates a complete GraphQL module including resolvers and services classes with optimized access to database and memory cache usage. Resolver generator parses GraphQL schema and creates resolver classes and methods for GraphQL queries, fields and mutations. It also creates a service class for database access. Resolvers and service method names are defined based on certain naming convention.
In this work, semi-automatic GraphQL module generation is adopted. It means that methods signature and partly implementation are generated automatically whereas part of their implementation (particularly queries to database) has to be completed manually. Please note that for a given database structure, GraphQL module generation may be completely automated without any manually added code. But in the article, we decided to confine ourselves with semi-automatic approach for the sake of generality. So, our GraphQL module generation takes a GraphQL schema as its input and produces a GraphQL module file containing resolvers and appropriate service class. After manual adjustment of the module, it is ready to use.
In our code sample, gql-resolver-generator tool generates files .\generated-gql.module.ts and .\schema.ts . File .\generated-gql.module.ts after manual adjustment will be transformed to file .\nestjs-graphql-service\src\modules\gql.module.ts . File .\schema.ts contains types corresponding to TypeORM entity types and may serve as boilerplates for them. Actually, gql-resolver-generator may be designed to automatically generate the entity types.
Classic NestJS implementation of GraphQL implies loading GraphQL schema and module from disk. But this is not always convenient. When we have a set of various GraphQL schemas and their resolvers, it would be nice to be able to load them from the Web with some file server on the start of our NestJS service. This gives us flexibility to use the same service instance for different GraphQL schemas. On the other hand, ability to load GraphQL schema and module from disk should be also supported, for example, for easy debugging. In this case, we may use the same service structure for various GraphQL schemas. In our sample, the 3rd party .\file-server application provides Web access to GraphQL schema and module. Library .\libs\gql-module-lib loads GraphQL schema, whereas library module-loader-lib loads GraphQL module file gql.module.ts.
The main idea behind GraphQL is to deliver to client only those data that were actually requested. But we would also like to select from database tables only requested data. This is achieved in class Gql of .\libs\gql-module-lib library by comparing requested fields with database tables columns names and a certain naming convention.
Sometimes, we would like to make the last changes in response object - either in data or in error message - before the response will finally go to client. For that matter, we added a small code fragment to a file requestPipeline.js of apollo-server-core and copy its updated version to .\libs\gql-module-lib\node_modules\apollo-server-express\node_modules\apollo-server-core\dist\requestPipeline.js.
Library common-utils-lib contains collection of commonly used classes and functions, including e.g., a simple dictionary.
Library config-lib is responsible for configuration. It provides means to read data from .env file.
Logging is implemented in logger-lib library. It is based on winston framework. Its the only code file index.ts provides configuration of nest-winston package to output appropriate logs to files (separately for info and errors) and console. Logger configuration is read from .env file.
Reference: config-lib.
Library module-loader-lib is responsible for a dynamic module upload (in our case of GraphQL module).
References: common-utils-lib, config-lib, logger-lib.
Library gql-module-lib provides solution for the following problems:
- data fetching optimization,
- dynamic loading GraphQL schema, and
- fetching only required data from database.
References: common-utils-lib, logger-lib.
Library sql-base-lib provides software for basic SQL Server support. It includes building connection to SQL Server and a simple transaction mechanism.
Reference: config-lib.
Library interceptors-lib contains main custom interceptors and guards used in the sample services.
References: config-lib, logger-lib.
TlsGuard from library interceptors-lib provides support for TLS. Additional related code is placed in function bootstrap() (file main.ts). It creates a service with httpOptions containing appropriate key and certificate.
Library auth-lib provides authentication for GraphQL resolvers and REST controllers based on JSON Web Token (JWT) approach. Database table users provides data for authentication and authorization. To illustrate authorization, its column permission contains string of two positions filled with either 0 (access denied) or 1 (access permitted) each. The first position stands for query execution permission while the second one controls access to execution of mutations.
References: config-lib, sql-base-lib.
Library login-lib offers means for user login when authentication is used. Class LoginController provides method login() taking user credentials that handles POST /auth/login request, and "guarded" method getProfile() handling GET /profile request which returns profile of current user.
References: config-lib, interceptors-lib, auth-lib.
NestJS provides excellent support for OpenAPI required just few lines of code. This code is placed in function bootstrap() of file main.ts with appropriate comments.
Node.js and SQL Server should be installed on your machine. In order to test authentication and TLS Postman and perhaps curl should be installed. Although formally the sample can be run without any IDE it will be much more convenient to play with it using some development studio, such as WebStorm or Visual Studio Code.
When you run the sample for the first time, please follow the steps below:
- Start SQL Server Management Studio (or other IDE managing SQL Server) and execute .\script_PersonDb.sql to create
PersonDB database. - Open directory .\libs and run command file _BUILD_LIBS.cmd to build all libraries.
- Open directory .\init-db and run command files _NPM_INSTALL.cmd, _BUILD.cmd and _RUN.cmd . This builds and runs application that fills
PersonDB database with some initial data. Before build entities files were copied from directory .\typeorm-entities to directory .\init-db\src\sql\entities. - Open directory .\nestjs-graphql-service and run command files _NPM_INSTALL.cmd and _BUILD.cmd to build main service. Before build entities files were copied from directory .\typeorm-entities to directory .\nestjs-graphql-service\src\sql\entities. After build files .\nestjs-graphql-service\gql\schema.gql and .\nestjs-graphql-service\dist\modules\gql.module.js were copied to directory .\file-server\gql .
- By default, main service is configured (by its .env file) to take GraphQL schema and module from file-server service and run without TLS and authentication. So, file-server service should be started before the main service. This can be done by running command file _RUN_FILE_SERVER.cmd . You will see it in a separate console window with message: "Server listening on port 9000". If you'd like to run the main service loading GraphQL schema and module from disk, then you need in file .env to comment out paragraph "
# Load from Web" and uncomment paragraph "# Load locally" replacing there value of GQL_URL with your local path. - Run command file _RUN.cmd in directory .\nestjs-graphql-service to start the main service. It will open another console window with several messages reporting the service progress beginning with message "
Main Service started" and ending with messages "http on port 3000" and "http on port 443". And in file-server console window messages "GET /gql/gql.module.js" and "GET /gql/schema.gql" will appear. - Start your favorite browser (I tested it with Google Chrome and Microsoft Edge). First, let's browse for localhost:3000/gql . GraphQL implementation provides Playground Web application to test service. Its Web page appears in your browser. Copy content of file .\nestjs-graphql-service\gql\graphql-queries-mutation.txt (or simply drag-and-frop it) to the left-hand side of the appeared page (to query panel) and execute queries and mutation with the triangle button.
As you can see, by running mutation, we add two new persons to our database. Attempt to execute the same mutation for the second time fails with message that the entries already exist in database. You can play with various queries and mutations that comply with given GraphQL schema. Result of PersonsBySurname GraphQL query is presented in Figure 4 below:
Figure 4. PersonsBySurname GraphQL query.
We can also test the RESTful part of our service. Let's browse http://localhost:3000/numEcho/3 and observe appearance of 3 as a result. We can also use OpenAPI browsing http://localhost:3000/api. Result is depicted in Figure 5 below:
Figure 5. OpenAPI.
Now you may be wanted to test out service with authentication and TLS enabled. For this, we need to stop main service with Ctrl-C, make appropriate changes in its configuration file .env and start the service again. To enable authentication parameter IS_AUTH_ON should be set to true, and to enable TLS parameter IS_TLS_ON should be set to true. Please note that self-signed certificate for TLS is used here for testing purposes. So it is subject to restrictions imposed on self-signed certificates.
After these changes were made, please run command file _RUN.cmd and observe the changes in console log. Now with authentication in place, in order to use our main service we have to login. Let's do it on behalf of a user Rachel with curl as:
curl -d "username=Rachel&password=rrr" -X POST -k https://localhost/auth/login
We can also use Postman for this matter with:
POST https://localhost/auth/login?username=Rachel&password=rrr
As a response, we get an access_token that may be used for further requests to the service.
Now we can execute GraphQL query and mutation using Postman supplying the access token as Token in Authorization page.
RESTful API may be tested with OpenAPI inserting the access token to Authorize -> Value textbox. Now execution of GET /profile results with user Rachel id ("u_1") and her permissions ("11"). And GET /numEcho/{n} will also work only after authorization.
As it was said above, it is possible to generate GraphQL service, resolvers and module based on schema. Appropriate application is located in .\graphql-module-generator directory. Files _NPM_INSTALL.cmd, _BUILD.cmd and _RUN.cmd should be executed in order to generate .\generated-gql.module.ts file. This file contains boilerplate for SqlService, GqlModule and resolver classes. In this sample file, .\generated-gql.module.ts may be transformed to a file .\nestjs-graphql-service\src\modules\gql.module.ts of the main service by adding actual SQL queries to its resolvers. In real world generation of gql.module.ts file may be fully automated based on well-known database structure and appropriate naming convention. graphql-module-generator application also generates file .\schema.ts which content may be useful for writing TypeORM entities classes (actually those classes placed initially in .\typeorm-entities\*.entity.ts files and copied to appropriate project directories as it was mentioned above, also can be automatically generated based on database structure).
As it was said above, sometimes we'd like to make final changes in data or error message that goes to client. Command file .\nestjs-graphql-service\_BUILD.cmd copies updated version of file requestPipeline.js to a proper place. An added code fragment calls a callback transformResponse() function provided by the service in a resolver in file gql.module.ts and attached to request context object.
The article presents sample of Node.js NestJS based service contains GraphQL and REST components. Usage of GraphQL is optimized in several aspects, primarily by reducing number of database queries per client request. The service uses secure communication with TLS and JWT authentication mechanism.
- 16th December, 2020: Initial version

