One of the things I observe about front-end development is the propensity for spaghetti code: deeply nested function calls, complex conditional logic, and complex / embedded handling of UI events, AJAX events, and observables via Proxy nowadays. Yes, these can all be corrected with better implementation discipline, but one thing remains that has always frustrated me about front-end development is that it is process-oriented, not data type oriented. On the back end, I solved this years ago with architectures like HOPE and a Semantic Publisher/Subscriber architecture, but front-end development does not have the Type reflection features of C#.
Contents
One of the things I observe about front-end development is the propensity for spaghetti code: deeply nested function calls, complex conditional logic, and complex / embedded handling of UI events, AJAX events, and observables via Proxy nowadays. Yes, these can all be corrected with better implementation discipline, but one thing remains that has always frustrated me about front-end development is that it is process-oriented, not "data type" oriented. On the back end, I solved this years ago with architectures like HOPE and a Semantic Publisher/Subscriber architecture, but front-end development does not have the Type reflection features of C#. This means that the implementation has to either be done with metadata (using proposed decorators in TypeScript) or with interfaces, both of which are a bit hacky but can get the job done.
From my perspective, the advantage of a type-based workflow pattern (as opposed to more-or-less linear processing) are the following, all of which are really the same as the advantages of a publisher/subscriber pattern:
- Small functions that do one thing and one thing only - they are triggered when data is published, they do some work, and they publish the results of that work.
- As publishing is done through a router, logging of the chain of work is straight forward.
- It becomes very simple to write unit tests - set up the data, publish it, verify that the expected results are published.
- The subscriber can determine that the work it does can be performed (using
postMessage) or asynchronously (using Worker.) - Or the caller can determine (or override) whether the work should be performed synchronously or asynchronously.
- Improves re-use and scalability.
- Consistent logging and exception handling which can themselves be implemented as subscribers.
The salient difference between a typical publisher/subscriber pattern and what I'm demonstrating here is this: a typical pub/sub is based on an event name or "topic", whereas what I'm demonstrating is that the event name is the data type itself. This small difference is important in keeping the publication process coupled to the data type. A picture might help:

Here, different subscribers, based on the topic "A" or "B", handle the publication of MyData.
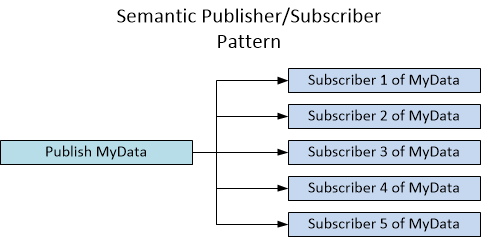
Here, the data type becomes the "topic."
And yes, the standard pub/sub pattern can be used for type-based pub/sub simply by hard-coding the type as the topic, but I want something more dynamic and extensible, such as a hierarchy of type.
Incidentally, the wiki page on the publisher/subscriber pattern says this:
There are two common forms of filtering: topic-based and content-based.
In a topic-based system, messages are published to "topics" or named logical channels. Subscribers in a topic-based system will receive all messages publised to the topics to which they subscribe. The publisher is responsible for defining the topics to which subscribers can subscribe.
In a content-based system, messages are only delivered to a subscriber if the attributes or content of those messages matches constraints defined by the subscriber. The subscriber is responsible for classifying the messages.
Some systems support a hybrid of the two; publishers post messages to a topic while subscribers register content-based subscriptions to one or more topics.
What I'm writing about here is a third form - type-based. However I have found some use for a type-content-based subscriber, but I believe I will leave that out of this article.
Let me be clear that the advantage of having a topic is that you can route the message to specific subscribers based on the topic. Therefore any pub/sub implementation is an implicit coupling of topic-data with the subscriber. In a semantic (as in, type-based approach), it may require that the developer creates specific types that ensure routing to the desired handlers. While I could argue that there is architectural advantage to a tightly coupled explicit type-subscriber implementation, in my experience, it can also lead to creating an overabundance of types simply to ensure routing to the desired subscribers. So keep this in mind if you consider this kind of architecture.
An advantage of a type-less programming language is you can simply pass around objects, like {FirstName: "Marc", LastName: "Clifton"}. The drawback of the concept I present here is (as is similar with C#'s anonymous types), there is no type and hence objects constructed in this manner are not suitable for a type-based pub/sub. There, of course, is a kludgy workaround.
There are other drawbacks as well that I have encountered with developers (forgive the sort of ranty statements here, but I'm just being honest):
- Coders (and I suppose people generally) tend to think linearly so the idea of a "publish and forget" coding style is not necessarily easy to wrap one's head around. I think this is actually why I've never seen a front-end project that uses a pub/sub pattern, not to mention
Worker classes. - Coders do not think in terms of a data-driven architecture. They think in terms of UI events or back-end process calls, all of which simply reinforce linear thinking and linear coding.
- Coders go for the quick implementation, and it is rare to have a group of people agree on a high-level architecture and even rarer to consistently adhere to it and even rarer to be happy with an "implementation enforcer". And coders don't like architectures foisted upon them unless it is falls into the "I need to learn this for job security because it is the current craze", and certainly not by people like me that are so outside of the mainstream React, Vue, Angular, craze-of-the-year, frameworks.
- Asynchronous programming is also something I keep seeing people struggle with, not just because it isn't linear, but simply because there is a general discomfort with the whole concept. Yes, part of that is because one has to potentially manage data locks, downstream "re-sync", death by locks, and so forth, none of which is usually an issue with JavaScript, even with Worker threads, because the data they work on is "copied" into each Worker's separate data area.
- It's easier to simply write the code linearly. If the code is an event handler (from a UI event or an AJAX event, I constantly see function or fat arrow "here's the implementation right here" with no consideration of "is there some re-use in this code." Personally, I cringe when I see event handlers (or any kind of declarative "coding") in the HTML itself!
- Debugging a pub/sub is, let's be honest here, harder than debugging linear or "the handler is right here in the wire-up" code.
- Debugging asynchronous code is even harder. Or so people claim, as I don't find debugging asynchronous code that hard, nor debugging code implemented in a synchronous pub/sub implementation. But that's me.
I had intended the code presented here to use TypeScript version 4 specifically so I can take advantage of labeled tuples:
Unfortunately, it appears the Visual Studio editor support for labeled tuples is still not complete:

That's really annoying. So while at some point I refactored the tuples to have labels, you'll still see [0] and [1] to reference the tuple elements because I can't use their names!
The first order of business is to consider whether the subscriber is long running or requires DOM manipulation (in my opinion, the latter is usually not a good architectural practice anyways.) Behind the scenes in a JavaScript application is the event loop which processes queued messages synchronously on the main thread. In order not to create an unresponsive user interface, the event handlers should be as quick as possible. For long running work, there is the Worker class. The disadvantage of the Worker object is that it cannot manipulate the DOM, so any DOM changes have to be posted back onto the main window thread. Also refer to Functions and classes available to Web Workers. Conversely, queued work in a Worker pool can be removed, whereas messages posted to the event queue cannot. So there are a variety of usage considerations to contemplate in addition to the drawbacks described above.
Another diagram:

This should be straight forward - an object that implements ITyped is published and subscribers are invoked synchronously or asynchronously, which can themselves publish additional data. The pub/sub performs logging and exception handling, which can themselves be implemented as subscribers.
This is "roll as I go" code, so expect to see changes as the article progresses. I find this more fun, and readers seem to like it as well. That said, I already foresee some challenges with the Worker asynchronous processing, but we'll cross that bridge when we get to the chasm.
A very simple interface to enforce the implementation of the data type as a string:
interface ITyped {
__name: string;
}
And since I very much do not like hard-coded strings, for the initial test:
export class DataTypeDictionary {
public static MyData: string = "MyData";
}
import { DataTypeDictionary } from "./DataTypeDictionary"
export class MyData implements ITyped {
__name = DataTypeDictionary.MyData;
public someString: string;
constructor(someString: string) {
this.someString = someString;
}
}
import { Guid } from "./Guid";
type Subscriber = (data: ITyped, pubSub: PubSub, token?: Guid) => void;
type DataType = string;
interface ITypeTokenMap {
[key: string]: Guid[];
}
interface ITypeSubscriberMap {
[key: string]: Subscriber;
}
Subscriber is like a C# Action<T>(T data, PubSub pubSub, Guid token = null) where T : ITyped shorthand that improves code readability, and the interfaces are just key-value dictionaries. The not-so-obvious thing here is that each subscriber gets a unique token (I'm not showing the Guid class (I probably found that on StackOverflow), so behind the scenes, a subscriber gets a token and that token is added to the value array where the data type is the key (1 to many). The actual subscriber is managed in a 1:1 dictionary.
export class PubSub {
private window: any;
private subscriberTokens: ITypeTokenMap;
private subscribers: ITypeSubscriberMap;
constructor(window: any) {
this.window = window;
this.subscriberTokens = {};
this.subscribers = {};
}
Here I'm pre-guessing myself by passing in the "window" object because at some point shortly, I'm going to modify the code to use the window.postMessage function so that publishing queues the invocation of the subscribers rather than processing them immediately. In theory, this will allow the UI to maintain responsiveness, but I have no idea how it'll behave in practice!
public Subscribe(type: DataType, subscriber: Subscriber): Guid {
let guid = Guid.NewGuid();
let strGuid = guid.ToString();
if (!(type in this.subscriberTokens)) {
this.subscriberTokens[type] = [];
}
this.subscriberTokens[type].push(guid);
this.subscribers[strGuid] = subscriber;
return guid;
}
Pretty straight forward. If the data type, as the key, is new, create an empty array of subscriber tokens for it. The add the token and map the token to the subscriber.
public Unsubscribe(subscriberToken: Guid): void {
let strGuid = subscriberToken.ToString();
delete this.subscribers[strGuid];
let subscriberTokenIdx = Object.entries(this.subscriberTokens)
.filter(([k, v]) => this.IndexOf(v, subscriberToken) !== undefined)
.map(([k, v]) => ({ k: k, idx: this.IndexOf(v, subscriberToken) }));
if (subscriberTokenIdx.length == 1) {
let sti = subscriberTokenIdx[0];
this.subscriberTokens[sti.k].splice(sti.idx, 1);
}
}
private IndexOf(guids: Guid[], searchFor: Guid): number {
let strGuid = searchFor.ToString();
let idx = guids.map(g => g.ToString()).indexOf(strGuid);
return idx;
}
A bit more gnarly. Removing the key-value pair of token-subscriber function from the dictionary is easy. Removing the specific item in the data type - token array is obviously more complicated. What we're doing here is filtering the dictionary by finding the token in the value array of the key-value pair, then mapping the filtered result to key-value pairs of data type and index in the array of tokens for that data type. As the code comments point out, we should either find one and only one token somewhere in the dictionary of data type token arrays, or not at all. If we do find one, we remove it from the array.
This is a lot simpler:
public Publish(data: ITyped): void {
let subscriberTokens = this.subscriberTokens[data.__name];
if (subscriberTokens) {
let subscriptions = subscriberTokens.map
(token => ({ subscriber: this.subscribers[token.ToString()], token: token }));
subscriptions.forEach
(subscription => subscription.subscriber(data, this, subscription.token));
}
}
import { PubSub } from "./SemanticPubSub/PubSub";
import { MyData } from "./MyData";
import { DataTypeDictionary } from "./DataTypeDictionary";
import { Guid } from "./SemanticPubSub/Guid";
export class AppMain {
public run() {
let d = new MyData("Foobar");
let pubSub = new PubSub(window);
pubSub.Subscribe(DataTypeDictionary.MyData, this.Subscriber1);
let token2 = pubSub.Subscribe(DataTypeDictionary.MyData, this.Subscriber2);
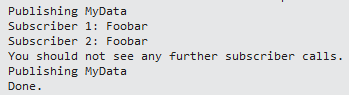
pubSub.Publish(d);
pubSub.Unsubscribe(token2);
console.log("You should not see any further subscriber calls.")
pubSub.Publish(d);
console.log("Done.");
}
public Subscriber1(data: MyData, pubSub: PubSub, token: Guid): void {
console.log(`Subscriber 1: ${data.someString}`);
pubSub.Unsubscribe(token);
}
public Subscriber2(data: MyData): void {
console.log(`Subscriber 2: ${data.someString}`);
}
}
We see:

Snazzy.
Let's add these pieces. First, the data type classes to support this.
import { PubSubDataTypeDictionary } from "../PubSub"
export class Log implements ITyped {
__name: string = PubSubDataTypeDictionary.Logger;
public message: string;
constructor(message: string) {
this.message = message;
}
}
import { PubSubDataTypeDictionary } from "../PubSub"
export class Exception implements ITyped {
__name: string = PubSubDataTypeDictionary.Exception;
public message: string;
constructor(message: string) {
this.message = message;
}
}
Gee, it looks the same except for the type name!
export class PubSubDataTypeDictionary {
public static Logger: string = "Logger";
public static Exception: string = "Exception";
}
export class PubSubOptions {
public hasDefaultLogger: boolean;
public hasDefaultExceptionHandler: boolean;
}
export class PubSub {
private window: any;
private subscriberTokens: ITypeTokenMap;
private subscribers: ITypeSubscriberMap;
constructor(window: any, options?: PubSubOptions) {
this.window = window;
this.subscriberTokens = {};
this.subscribers = {};
this.ProcessOptions(options);
}
and:
private ProcessOptions(options: PubSubOptions): void {
if (options) {
if (options.hasDefaultLogger) {
this.Subscribe(PubSubDataTypeDictionary.Logger, this.DefaultLogger);
}
if (options.hasDefaultExceptionHandler) {
this.Subscribe(PubSubDataTypeDictionary.Exception, this.DefaultExceptionHandler);
}
}
}
private DefaultLogger(data: Log): void {
console.log(data.message);
}
private DefaultExceptionHandler(data: Exception): void {
console.log(`You broke it! ${data.message}`);
}
public Publish(data: ITyped, internal?: boolean): void {
if (!internal) {
this.Publish(new Log(`Publishing ${data.__name}`), true);
}
let subscriberTokens = this.subscriberTokens[data.__name];
if (subscriberTokens) {
let subscriptions = subscriberTokens.map
(token => ({ subscriber: this.subscribers[token.ToString()], token: token }));
subscriptions.forEach(subscription => {
try {
subscription.subscriber(data, this, subscription.token);
} catch (err) {
this.Publish(new Exception(err));
}
});
}
}
Note that we need to stop recursion by adding and internal flag. Notice that the internal flag is only used for logging. We assume that the exception handler will not itself throw an exception.
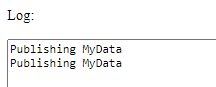
We now instantiate the PubSub with:
let pubSub = new PubSub(window, { hasDefaultLogger: true, hasDefaultExceptionHandler: true });
and running the test app, we see:

Oh wow - our own code has an exception that went undetected! Let's fix that. Debugging, we see on this line:
let subscriptions = subscriberTokens.map
(token => ({ subscriber: this.subscribers[token.ToString()], token: token }));

So clearly, the unsubscribe method did not properly clean up the dictionary of subscription tokens.
The issue here is that we are not filtering the map for tokens that no longer exist in the token-subscriber dictionary. As we see:

The subscribers dictionary only has our Log and Exception data type subscribers. This is a simple fix:
let subscriptions = subscriberTokens
.map(token => ({ subscriber: this.subscribers[token.ToString()], token: token }))
.filter(s => s.subscriber);
and now the run looks clean:
So that was quite interesting! By adding an exception handler subscriber and wrapping each subscriber call in a try-catch block, we found an exception in our own code.
It is hopefully obvious that you can add your own loggers as well. With:
<body>
<p>Log:</p>
<div>
<textarea id="log" rows=10 cols=100></textarea>
</div>
<p>Exceptions:</p>
<div>
<textarea id="exceptions" rows=10 cols=100></textarea>
</div>
</body>
and:
pubSub.Subscribe(PubSubDataTypeDictionary.Log, this.LogViewer);
pubSub.Subscribe(PubSubDataTypeDictionary.Exception, this.ExceptionViewer);
and:
public LogViewer(log: Log): void {
this.AppendText("log", `${log.message}\r\n`);
}
public ExceptionViewer(exception: Exception): void {
this.AppendText("exceptions", `${exception.message}\r\n`);
}
private AppendText(id: string, msg: string) {
let el = document.getElementById(id) as HTMLTextAreaElement;
el.value += msg;
}
We discover this does not work:


in the line err => this.Publish(new Exception(err)))
Argh! I keep forgetting that JavaScript does not maintain the object instance of the "this" when making function calls. For all, the argument as to whether JavaScript is object oriented or not, this is my definitive reason for why it is not!
None-the-less, we need to preserve the calling context. Sadly, this requires passing in the "this" as the context (or in JavaScript parlance, the "scope"), and this requires some minor of refactoring, leveraging TypeScript's concept of a tuple, which is really just an syntactical array hack as the tuple elements cannot be named ("TypeScript tuples are like arrays with a fixed number of elements" - link). So we refactor with:
type Scope = any;
interface ITypeSubscriberMap {
[key: string]: [Subscriber, Scope];
}
and:
public Subscribe(type: DataType, subscriber: Subscriber, scope?: any): Guid {
let guid = Guid.NewGuid();
let strGuid = guid.ToString();
scope == scope ?? this;
if (!(type in this.subscriberTokens)) {
this.subscriberTokens[type] = [];
}
this.subscriberTokens[type].push(guid);
this.subscribers[strGuid] = [subscriber, scope];
return guid;
}
Note that if the scope is not provided, we assume the PubSub scope "this" - not all subscribers require a scope.
And finally, when calling the subscriber, we "apply" the scope:
subscriptions.forEach(subscription =>
Assertion.Try(
() => subscription.subscriber[0].apply
(subscription.subscriber[1], [data, this, subscription.token]),
err => this.Publish(new Exception(err))));
And now we see on the page:
We might as well refactor the console.logs to use our logger subscriber as well:
...
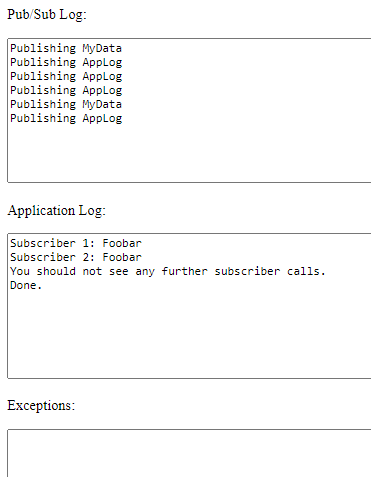
pubSub.Publish(new Log("You should not see any further subscriber calls."));
pubSub.Publish(d);
pubSub.Publish(new Log("Done."));
}
public Subscriber1(data: MyData, pubSub: PubSub, token: Guid): void {
pubSub.Publish(new Log(`Subscriber 1: ${data.someString}`));
pubSub.Unsubscribe(token);
}
public Subscriber2(data: MyData, pubSub: PubSub): void {
pubSub.Publish(new Log(`Subscriber 2: ${data.someString}`));
}
And we see:

Or if you prefer to split the PubSub logging from the application logging:
<body>
<p>Pub/Sub Log:</p>
<div>
<textarea id="pubsublog" rows=10 cols=100></textarea>
</div>
<p>Application Log:</p>
<div>
<textarea id="applog" rows=10 cols=100></textarea>
</div>
<p>Exceptions:</p>
<div>
<textarea id="exceptions" rows=10 cols=100></textarea>
</div>
</body>
with:
export class DataTypeDictionary {
...
public static AppLog: string = "AppLog";
}
import { DataTypeDictionary } from "./DataTypeDictionary"
export class Log implements ITyped {
__name: string = DataTypeDictionary.AppLog
public message: string;
constructor(message: string) {
this.message = message;
}
}
and:
pubSub.Subscribe(DataTypeDictionary.AppLog, this.AppLogViewer, this);
pubSub.Subscribe(PubSubDataTypeDictionary.Log, this.PubSubLogViewer, this);
pubSub.Subscribe(PubSubDataTypeDictionary.Exception, this.ExceptionViewer, this);
and the implementation:
public PubSubLogViewer(log: Log): void {
this.AppendText("pubsublog", `${log.message}\r\n`);
}
public AppLogViewer(log: AppLog): void {
this.AppendText("applog", `${log.message}\r\n`);
}
public ExceptionViewer(exception: Exception): void {
this.AppendText("exceptions", `${exception.message}\r\n`);
}
Given the usage like this as an example:
pubSub.Publish(new AppLog("Done."));
we now see:
But enough of this distraction.
I don't like "if" statements and this code...
if (!internal) {
this.Publish(new Log(`Publishing ${data.__name}`), true);
}
...smells. We can clean it up like this:
public Publish(data: ITyped): void {
this.InternalPublish(new Log(`Publishing ${data.__name}`));
this.InternalPublish(data);
}
private InternalPublish(data: ITyped): void {
...
This has the benefit of also eliminating the optional parameter.
I also don't like how try-catch blocks add visual clutter to the code:
try {
subscription.subscriber(data, this, subscription.token);
} catch (err) {
this.Publish(new Exception(err));
}
Preferring something that wraps any try-catch block:
subscriptions.forEach(subscription =>
Assertion.Try(
() => subscription.subscriber[0].apply
(subscription.subscriber[1], [data, this, subscription.token]),
err => this.Publish(new Exception(err))));
Given:
type Lambda = () => void;
type ErrorHandler = (err: string) => void;
export class Assertion {
public static Try(fnc: Lambda, errorHandler: ErrorHandler) {
try {
fnc();
} catch (err) {
errorHandler(err);
}
}
}
But that's me.
Given this: "The window.postMessage() method safely enables cross-origin communication between Window objects", we can however use postMessage to post messages onto our own window. Doing so in a pub/sub is potentially an over-design: when data is published, do we want the subscribers to run immediately, blocking the execution of the current application code until the subscribers have run, or do we want to queue the "publish" as a message event? Personally, I like the idea that publishing data should not block the publisher so it can continue to do other things. But that leads to another question - should each subscriber be queued as a message event as well? To this question, I think not. I highly doubt that a UI event can sneak in to the queue as the messages on the queue are being processed.
Here's a simple example of self-posting from the Chrome console:
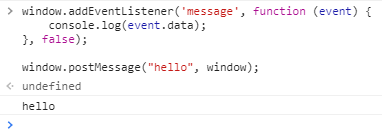
Sort of bare-bones, as we'll need to filter out message that are meant for the pubsub.
However, we have a bigger problem - postMessage again loses scope. So this (literally and as a pun) won't work:
window.addEventListener('message', this.OnWindowMessage);
...
public Publish(data: ITyped): void {
this.window.postMessage(["pubsub", data], this.window);
}
private OnWindowMessage(event): void {
let data = event.data;
if (Array.isArray(data) && data[0] == "pubsub") {
data = data[1] as ITyped;
this.InternalPublish(new Log(`Publishing ${data.__name}`));
this.InternalPublish(data);
}
}
Nor does this work:
this.window.postMessage(["pubsub", data, this], this.window);

Neither do I want to pass in the PubSub instance as this would end up cloning all the data in the PubSub, which would have some undesirable side effects like the subscriber not being able to unsubscribe itself.
This gives me pause in that now we have obviously two issues:
- a performance hit because the data is cloned
- a constraint that the data is cloneable
On the other hand, because the data is cloned, it can be considered immutable except within the scope of the subscriber. There are advantages to that!
Given the two issues described above, the programmer should have the choice, rather than the pub/sub foist an implementation decision upon them. That said, let us proceed.
Given that the user should not be constrained to work with single PubSub instance (thus we could have a static member of PubSub), we have an ugly solution - add to the window object a dictionary whose key-value is the pub/sub name and its instance. Fortunately, the programmer doesn't need to concern themselves with this implementation detail. Given:
interface IPubSubMap {
[key: string]: PubSub;
}
and:
private Register(): void {
this.id = Guid.NewGuid();
let w = window as any;
w._pubsubs = w._pubsubs || {};
let dict = w._pubsubs as IPubSubMap;
dict[this.id.ToString()] = this;
window.addEventListener('message', this.OnWindowMessage);
}
we can now do this:
public QueuedPublish(data: ITyped): void {
this.window.postMessage(["pubsub", data, this.id.ToString()], this.window);
}
and the handler is implemented as:
private OnWindowMessage(event): void {
let eventData = event.data;
if (Array.isArray(eventData) && eventData[0] == "pubsub") {
let data = eventData[1] as ITyped;
let w = window as any;
let dict = w._pubsubs as IPubSubMap;
let me = dict[eventData[2].ToString()] as PubSub;
me.InternalPublish(new Log(`Publishing ${data.__name}`));
me.InternalPublish(data);
}
}
and changing the test to use, for example:
pubSub.QueuedPublish(new AppLog("You should not see any further subscriber calls."));
pubSub.QueuedPublish(d);
pubSub.QueuedPublish(new AppLog("Done."));
We now see:

Well, there you go - in the code:
pubSub.QueuedPublish(d);
pubSub.Unsubscribe(token2);
Subscriber 2 is unsubscribed by the application thread. When the application function finishes, the JavaScript message event queue is processed, so by the time the event queue is processed, the subscriber no longer exists! To fix this (more over-design), the PubSub can maintain its own queue and implement a Flush method, but first some refactoring:
export class PubSub {
...
private queue: ITyped[] = [];
and we no longer need to pass in the data as part of the message, which has the effects:
- The data is no longer cloned - a performance improvement
- The data is no longer cloned - so it is mutable!
public QueuedPublish(data: ITyped): void {
this.queue.push(data);
this.window.postMessage(["pubsub", this.id.ToString()], this.window);
}
and:
private OnWindowMessage(event): void {
let eventData = event.data;
if (Array.isArray(eventData) && eventData[0] == "pubsub") {
let w = window as any;
let dict = w._pubsubs as IPubSubMap;
let me = dict[eventData[1]] as PubSub;
me.Flush();
}
}
And now the Flush method:
public Flush(all: boolean = false): void {
let n = this.queue.length;
while (n > 0 || all)
{
let data = this.queue.shift();
if (data) {
--n;
this.InternalPublish(new Log(`Publishing ${data.__name}`));
this.InternalPublish(data);
}
}
}
The optional parameter all allows the caller to specify that all queued message, including those published by subscribers, should be processed immediately until there is no further data in the queue.
In the test app:
pubSub.QueuedPublish(d);
pubSub.Flush();
We now see:

It turns out that we really don't need the window instance. Therefore:
export class PubSub {
...
constructor(options?: PubSubOptions) {
...
Any calls to the PubSub will, by its very nature, have to happen on the main application thread which already has a window object.
This also requires a minor change:
public QueuedPublish(data: ITyped): void {
this.queue.push(data);
window.postMessage(["pubsub", this.id.ToString()], window as any);
}
Now let's say I have some work that can be done completely asynchronously.
While we ultimately want a worker pool, let's just get the basics done here first. The source of information for this initial pass is from the MDN Web Docs on Using Web Workers.
Problems:
- The first problem is this statement: All you need to do is call the Worker() constructor, specifying the URI of a script to execute in the worker thread. Seriously? I need to create separate files for the subscribers?
- The second problem is the whole issue of scoping again: Workers are considered to have their own execution context, distinct from the document that created them. (link)
Given that, we have some ugly choices to make.
- Do we implement the workers in separate .js files?
- Or do we use the evil
eval function to pass in, as a string, the subscriber?
Since I simply cannot condone the idea of creating separate .js files, and I'm reluctant to bite from the eval apple, we will instead use Function. Note what the docs say:
Calling the constructor directly can create functions dynamically but suffers from security and similar (but far less significant) performance issues to eval. However, unlike eval, the Function constructor creates functions that execute in the global scope only. Functions created with the Function constructor do not create closures to their creation contexts; they always are created in the global scope. When running them, they will only be able to access their own local variables and global ones, not the ones from the scope in which the Function constructor was created. This is different from using eval with code for a function expression.
So that's an improvement.
The idea is this - the Worker gets the data packet and a string representing the function to execute, and it returns an array of ITyped data that is "marshaled" back onto the main thread and published.
The first problem I encountered is that, since I'm using "require.js", the resulting TypeScript code looks like this:
define(["require", "exports", "../../FNumber"], function (require, exports, FNumber_1) {
"use strict";
Object.defineProperty(exports, "__esModule", { value: true });
onmessage = msg => {
console.log(msg);
let calc = -1;
postMessage(new FNumber_1.FNumberResponse(calc));
};
});
Resulting in the runtime error ReferenceError: define is not defined. So forget TypeScript, I'll just code the file in pure JavaScript:
The next gnarly bit of code is calling Function with named parameters and returning the result. The following four examples are all equivalent:
new Function("{return function(a, b) { return a+b; } }").call(null).call(null, 1, 2);
new Function("{return function(a, b) { return a+b; } }").call()(1, 2);
new Function("{return (a,b) => { return a+b; } }").call()(1, 2);
new Function("{return (a,b) => a+b }").call()(1, 2);
and return "3". The concept in each of them is that the dynamic function, as a string, when called, returns an anonymous function (the first two) or a lambda expression (the last two.) When that "function/lambda expression" is called, it performs the processing and it returns the result. The "null" in the first two examples is required as the "this" argument, and since there's no context (scope), it is null. The second two examples, because they are lambda expressions (rather than anonymous functions) do not require a "this" because lambda expressions do not have a scope. It takes a while to wrap one's head around this, and I'm not sure I have, actually. I found this SO post to be very helpful.
Let's look at this code in the file "worker.js":
onmessage = msg => {
let data = msg.data[0];
let fncRaw = msg.data[1];
debugger;
}
Given:
private Fibonacci(data: FNumber): any {
const fibonacci = n => (n < 2) ? n : fibonacci(n - 2) + fibonacci(n - 1);
let calc = fibonacci(data.n);
return { n: calc, __name: "FibonacciResponse" };
}
private FibonacciResponse(fnr: FNumberResponse, pubSub: PubSub): void {
pubSub.Publish(new AppLog(`F = ${fnr.n}`));
}
and:
pubSub.Subscribe(DataTypeDictionary.Fibonacci, this.Fibonacci);
pubSub.Subscribe(DataTypeDictionary.FibonacciResponse, this.FibonacciResponse, this);
pubSub.AsyncPublish(new FNumber(10));
and:
public AsyncPublish(data: ITyped): void {
this.InternalPublish(new Log(`Publishing ${data.__name} (async)`));
this.CreateTask(data);
}
and:
private CreateTask(data: ITyped): void {
let subscriberTokens = this.subscriberTokens[data.__name];
if (subscriberTokens) {
let subscriptions = subscriberTokens
.map(token => ({ subscriber: this.subscribers[token.ToString()], token: token }))
.filter(s => s.subscriber);
subscriptions.forEach(subscription => {
let worker = new Worker("./SemanticPubSub/Worker/worker.js");
worker.onmessage = response => {
this.InternalPublish(response.data);
};
worker.postMessage([data, subscription.subscriber[0].toString()]);
});
}
}
we see, when the debugger is tripped:

So now we know what the function looks like (by the way, the Fibonacci code was borrowed from here.)
So the idea is to wrap the this in a lambda expression so it can be executed by Function inside the Worker like this:
onmessage = msg => {
let data = msg.data[0];
let fncRaw = msg.data[1];
let fnc = fncRaw.substr(fncRaw.indexOf("{"));
fnc = `{return data => ${fnc}}`;
let result = new Function(fnc).call()(data);
postMessage(result);
}
The leading Fibonacci(data) function name is stripped off and the lambda fat arrow expression is tacked on, including the closing brace. Going back to the CreateTask function in the PubSub, the salient piece of code is this:
subscriptions.forEach(subscription => {
let worker = new Worker("./SemanticPubSub/Worker/worker.js");
worker.onmessage = response => {
this.InternalPublish(response.data);
};
worker.postMessage([data, subscription.subscriber[0].toString()]);
});
- The
Worker is instantiated. - The
onMessage event is wired up so that we can process the response. - The worker is invoked with a call to its
postMessage, passing in the data packet and the subscriber code as a string. - The response is published as an
ITyped data packet that will be processed by any subscribers.
And, for completeness, we also have these classes:
import { DataTypeDictionary } from "./DataTypeDictionary"
export class FNumber implements ITyped {
__name = DataTypeDictionary.Fibonacci;
public n: number;
constructor(n: number) {
this.n = n;
}
}
export class FNumberResponse implements ITyped {
__name = DataTypeDictionary.FibonacciResponse;
public n: number;
constructor(n: number) {
this.n = n;
}
}
and these data dictionary type names:
public static Fibonacci: string = "Fibonacci";
public static FibonacciResponse: string = "FibonacciResponse";
When we run the main code (repeated here again):
pubSub.Subscribe(DataTypeDictionary.Fibonacci, this.Fibonacci);
pubSub.Subscribe(DataTypeDictionary.FibonacciResponse, this.FibonacciResponse, this);
pubSub.AsyncPublish(new FNumber(10));
we see this (hurrah!):
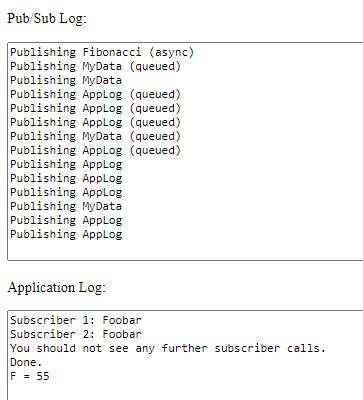
Pretty snazzy, if I may say so myself.
First, because the function that returns the named parameter lambda expression looks like this:
fnc = `{return data => ${fnc}}`;
The subscriber must have the parameter name data as well:
private Fibonacci(data: FNumber) {
I know of no way around this.
Second, the return cannot be:
return new FNumberResponse(calc);
If we do this, we get:

because we're mixing TypeScript (with require.js) and JavaScript. Again, I don't know a way around this. So instead, the return must be an anonymous object that includes the type name:
return { n: calc, __name: "FibonacciResponse" };
Even more annoyingly, for the same reason, we cannot do this:
return { n: calc, DataTypeDictionary.FibonacciResponse };
This is somewhat annoying!
What I also find annoying is that the subscriber type is defined as not having a return:
type Subscriber = (data: ITyped, pubSub: PubSub, token?: Guid) => void;
but TypeScript is quite happy to let me subscribe to a function that returns any:
pubSub.Subscribe(DataTypeDictionary.Fibonacci, this.Fibonacci);
...
private Fibonacci(data: FNumber): any {
I suppose this is because JavaScript doesn't have a concept of a return type, so TypeScript doesn't enforce return types either. Still, I would have expected a syntax error, and I've refactored the type to this:
type Subscriber = (data: ITyped, pubSub: PubSub, token?: Guid) => any;
It's also annoying that I can't use the subscriber in a non-async manner:
pubSub.Publish(new FNumber(10));
because the PubSub doesn't expect any return value. We can fix that with:
subscriptions.forEach(subscription =>
Assertion.Try(
() => {
let ret = subscription.subscriber[0].apply(subscription.subscriber[1],
[data, this, subscription.token]);
if (ret) {
this.InternalPublish(ret);
}
},
err => this.Publish(new Exception(err))));
Also, it's annoying that there is some response expected from the worker thread. What if the worker thread doesn't actually need to return any data? For example:
private Fibonacci(data: FNumber): any {
const fibonacci = n => (n < 2) ? n : fibonacci(n - 2) + fibonacci(n - 1);
let calc = fibonacci(data.n);
console.log(calc);
}
At the moment, this happens:

But again, there's a fix for that:
worker.onmessage = response => {
if (response.data) {
this.InternalPublish(response.data);
}
};
What does the stringified function look like if it's code as an anonymous function like this:
pubSub.Subscribe(DataTypeDictionary.Fibonacci, (data: FNumber) => {
const fibonacci = n => (n < 2) ? n : fibonacci(n - 2) + fibonacci(n - 1);
let calc = fibonacci(data.n);
return { n: calc, __name: "FibonacciResponse" };
});
we see the string:
"(data) => { const fibonacci = n => (n < 2) ? n : fibonacci(n - 2) +
fibonacci(n - 1); let calc = fibonacci(data.n);
return { n: calc, __name: "FibonacciResponse" }; }"
Given that the worker.js strips off everything to the left of the { and then replaces it with data =>
let fnc = fncRaw.substr(fncRaw.indexOf("{"));
fnc = `{return data => ${fnc}}`;
the code handles both subscribers implemented as functions and as anonymous functions. That actually surprised me.
I said that the subscriber could return a collection of ITyped data which would be marshaled and published back on the application thread. Frankly, I cannot come up with a good use case for that so I'm ditching that idea as over-design.
If we test exception handling given:
private ExceptionTest(): void {
throw "I broke it!";
}
and:
pubSub.Subscribe(DataTypeDictionary.ExceptionTest, this.ExceptionTest, this);
pubSub.AsyncPublish(new ExceptionTest());
we see:

So the worker.js code gets refactored, leveraging to point that this code is invoked by the PubSub and the return is handled by the PubSub:
onmessage = msg => {
let data = msg.data[0];
let fncRaw = msg.data[1];
let fnc = fncRaw.substr(fncRaw.indexOf("{"));
fnc = `{return data => ${fnc}}`;
try {
let result = new Function(fnc).call()(data);
postMessage(result);
} catch (err) {
postMessage({ message: err, __name: "Exception" });
}
}
and we see:
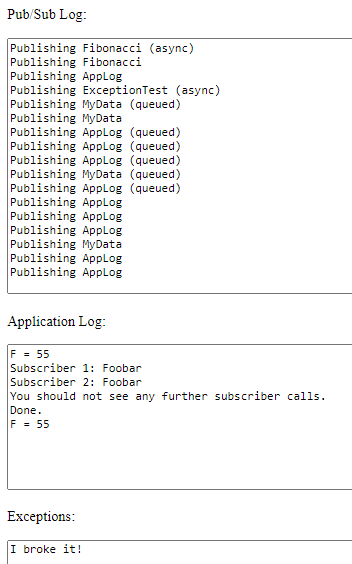
We now have two functions, InternalPublish and CreateTask, which have the same preamble:
let subscriberTokens = this.subscriberTokens[data.__name];
if (subscriberTokens) {
let subscriptions = subscriberTokens
.map(token => ({ subscriber: this.subscribers[token.ToString()], token: token }))
.filter(s => s.subscriber);
Given my distaste for repeating code, these two functions are going to be refactored into a singled function which takes as a parameter the function for processing subscriptions.
For clarity, here is the original code for the two functions we're going to "invert":
private InternalPublish(data: ITyped): void {
let subscriberTokens = this.subscriberTokens[data.__name];
if (subscriberTokens) {
let subscriptions = subscriberTokens
.map(token => ({ subscriber: this.subscribers[token.ToString()], token: token }))
.filter(s => s.subscriber);
subscriptions.forEach(subscription =>
Assertion.Try(
() => {
let ret = subscription.subscriber[0].apply
(subscription.subscriber[1], [data, this, subscription.token]);
if (ret) {
this.InternalPublish(ret);
}
},
err => this.Publish(new Exception(err))));
}
}
private CreateTask(data: ITyped): void {
let subscriberTokens = this.subscriberTokens[data.__name];
if (subscriberTokens) {
let subscriptions = subscriberTokens
.map(token => ({ subscriber: this.subscribers[token.ToString()], token: token }))
.filter(s => s.subscriber);
subscriptions.forEach(subscription => {
let worker = new Worker("./SemanticPubSub/Worker/worker.js");
worker.onmessage = response => {
if (response.data) {
this.InternalPublish(response.data);
}
};
worker.postMessage([data, subscription.subscriber[0].toString()]);
});
}
}
After defining the type for subscription as:
type SubscriberHandler = { subscriber: [Subscriber, any], token: Guid };
The refactored functions are:
private InternalPublish(data: ITyped): void {
let subscriptions = this.GetSubscriptions(data);
subscriptions.forEach(subscription => this.PublishOnUs(data, subscription));
}
private CreateTask(data: ITyped): void {
let subscriptions = this.GetSubscriptions(data);
subscriptions.forEach(subscription => this.PublishOnWorker(data, subscription));
}
private GetSubscriptions(data: ITyped): SubscriberHandler[] {
let subscriberTokens = this.subscriberTokens[data.__name];
let subscriptions: SubscriberHandler[] = [];
if (subscriberTokens) {
subscriptions = subscriberTokens
.map(token => ({ subscriber: this.subscribers[token.ToString()], token: token }))
.filter(s => s.subscriber);
}
return subscriptions;
}
private PublishOnUs(data: ITyped, subscription: SubscriberHandler): void {
Assertion.Try(
() => {
let ret = subscription.subscriber[0].apply
(subscription.subscriber[1], [data, this, subscription.token]);
if (ret) {
this.InternalPublish(ret);
}
},
err => this.Publish(new Exception(err)));
}
private PublishOnWorker(data: ITyped, subscription: SubscriberHandler): void {
let worker = new Worker("./SemanticPubSub/Worker/worker.js");
worker.onmessage = response => {
if (response.data) {
this.InternalPublish(response.data);
}
};
worker.postMessage([data, subscription.subscriber[0].toString()]);
}
It's a bit more code but we've extracted out the common code into the function GetSubscriptions and created separate functions of publishing on the PubSub vs. the Worker. I could been more extreme and used partial functions to remove the forEach in InternalPublish and CreateTask, but that seemed overly complicated and all it does is move the forEach loop into the downstream function.
There's an interesting implementation here but it's actually a thread pool pattern (the author explicitly states this) rather than an actual asynchronous worker pool. This implementation is a true worker pool and is quite excellent (it does use eval though rather than Function). It is a bit of an overkill for my purposes since the worker pool is really just a component of the PubSub rather than a general solution. However, because it's a NodeJs example, the author also doesn't have the problem with the name mangling that require.js appears to create, as well as all the other kruft, or maybe the name mangling is actually the Visual Studio TypeScript compiler, or some other annoying artifact. The point being, the author's worker.js is actually implemented in TypeScript, so it's clearly something about my tools or configuration that is the issue. And I do like the way he works with Promises, so it's definitely worth checking out.
First off, the number of worker threads defaults to 4 unless explicitly set to a different number in the options:
export class PubSubOptions {
public hasDefaultLogger?: boolean;
public hasDefaultExceptionHandler?: boolean;
public numWorkers?: number = 4;
}
The worker pool is simple enough:
import { PubSub } from "../PubSub";
type WorkerInfo = [worker: Worker, inUse: boolean];
type Task = [data: ITyped, code: string];
const Available = false;
const Busy = true;
export class WorkerPool {
private workers: WorkerInfo[] = [];
private queue: Task[] = [];
private pubSub: PubSub;
constructor(numWorkers: number, pubSub: PubSub) {
this.pubSub = pubSub;
this.Initialize(numWorkers);
}
public AddTask(task: Task) {
this.queue.push(task);
this.NextTask();
}
private Initialize(numWorkers: number): void {
for (let n = 0; n < numWorkers; n++) {
let worker = new Worker("./SemanticPubSub/Worker/worker.js");
this.workers.push([worker, false]);
worker.onmessage = response => {
this.workers[n][1] = Available;
this.NextTask();
if (response.data) {
this.pubSub.Publish(response.data);
}
}
}
}
private NextTask(): void {
if (this.queue.length > 0) {
for (let n = 0; n < this.workers.length; n++) {
if (!this.workers[n][1]) {
let task = this.queue.shift();
this.workers[n][1] = Busy;
this.workers[n][0].postMessage(task);
break;
}
}
}
}
}
The idea here is that each worker has a "busy" or "available" state. When the message is posted to the worker, it becomes busy, and is "available" when the response is posted. Adding a task pushes the task onto the queue and the next available worker processes it. If there is no available worker, the task remains on the queue and is processed when a worker completes and becomes free.
Now, PublishOnWorker becomes simply:
private PublishOnWorker(data: ITyped, subscription: SubscriberHandler): void {
this.workerPool.AddTask([data, subscription.subscriber[0].toString()]);
}
And, with the current state of the test application, we see:
<img border="0" height="599" src="5291077/run10.png" width="342" />
You'll note that there's slight difference - we now see the worker response being logged, because earlier I was using InternalPublish and now I'm using Publish.
Also noteworthy, at least to me, is that I now have a mechanism for making semantic server-side calls because the data includes its "type name". Something I've always been frustrated about is that endpoint APIs are "verb" oriented and I want semantic type-oriented endpoints. With the type name, I can now implement similar functionality on the server-side, routing the data based on its __name -- deserializing it directly into the matching class and then using the publisher/subscriber pattern I've already written about to invoke the subscribers. The unification of type-based subscriptions on both front and back end is a powerful solution. It eliminates myriads of endpoints as they are no longer verb driven but type driven. Yes, I could implement subscriber functions on the client-side that basically just post the data to the server, but that would mean a bunch of subscribers that are completely unnecessary if we implement a Post method in the PubSub itself.
This article comes with a small server, the details of which will be ignored except for the route that handles the "types" we publish to the server. Let's pretend we're logging in with a username and password:
import { DataTypeDictionary } from "./DataTypeDictionary"
export class Login implements ITyped {
__name = DataTypeDictionary.Login;
public username: string = "Marc";
public password: string = "Fizbin";
}
And when the user clicks the login button, we "publish" this type to the server's pub/sub:
let url = "http://127.0.0.1/PubSub";
(document.getElementById("btnLogin") as
HTMLButtonElement).onclick = () => pubSub.Post(url, new Login());
Notice I added a Post function:
public Post(url: string, data: ITyped, headers: IHeaderMap = {}): void {
XhrService.Post(url, data, headers)
.then(xhr => {
let obj = JSON.parse(xhr.response) as ITyped;
this.Publish(obj);
})
.catch(err => this.Publish(new Exception(JSON.stringify(err))));
}
and this function expects an ITyped response -- a JSON object that includes __name so that its response can be published to the appropriate type subscribers.
A very simple implementation of a publisher/subscriber pattern on the server-side in C# then routes the instances to the subscribers.
using System;
using System.Collections.Generic;
using System.Linq;
namespace ServerDemo
{
public interface IType { }
public interface ISubscriber
{
Type Type { get; set; }
IType Invoke(IType data);
}
public class Subscriber<T> : ISubscriber where T : IType
{
public Type Type { get; set; }
public Func<T, IType> Handler { get; set; }
public IType Invoke(IType data)
{
return Handler((T)data);
}
}
public class PubSub
{
protected List<ISubscriber> subscribers = new List<ISubscriber>();
public PubSub Subscribe<T>(Func<T, IType> handler) where T : IType
{
var subscriber = new Subscriber<T>()
{
Type = typeof(T),
Handler = handler
};
subscribers.Add(subscriber);
return this;
}
public IType Publish(IType data)
{
Type t = data.GetType();
var subscriptions = subscribers.Where(s => s.Type == t);
var resp = subscriptions.FirstOrDefault()?.Invoke(data);
return resp;
}
}
}
Technically, while only one subscriber should return a response, it's a simple matter to modify the code to return a collection of response types and on the front-end to publish each response type. We then subscribe our actual type handler:
pubSub.Subscribe<Login>(LoginHandler);
And the example handler is:
protected IType LoginHandler(Login login)
{
return new AppLog() { Message = $"Logged in {login.Username}" };
}
The two supporting classes are:
using Newtonsoft.Json;
namespace ServerDemo
{
public class AppLog : IType
{
[JsonProperty("message")]
public string Message { get; set; }
}
}
Notice the JsonProperty attribute so that the property is serialized to match the casing of the JavaScript field public message: string;
and:
namespace ServerDemo
{
public class Login : IType
{
public string Username { get; set; }
public string Password { get; set; }
}
}
Deserializing on the C# side is case insensitve.
We now add this universal route to the router:
router.AddRoute("POST", "/PubSub", PubSub, false);
and a hack of an implementation is:
protected IRouteResponse PubSub(dynamic data)
{
var typeName = data.__name;
var type = Type.GetType($"ServerDemo.{typeName}");
var packet = JsonConvert.DeserializeObject(JsonConvert.SerializeObject(data), type) as IType;
var resp = pubSub.Publish(packet);
dynamic dresp = JsonConvert.DeserializeObject<dynamic>(JsonConvert.SerializeObject(resp));
dresp.__name = resp.GetType().Name;
return RouteResponse.OK(dresp);
}
This is really hacky - I don't want to burden our C# types with the __name property - after all, C# is strongly typed - so instead:
- The type name is extracted from the
dynamic object. - The type is obtained by combining our known namespace.
- The data is then re-serialized and then deserialized into the desired type.
- The subscriber is called.
- The data is again re-serialized and then
deserialized into a dynamic object again. - The
__name property is added and set to the type name of the responding IType instance.
As mentioned above:
(document.getElementById("btnLogin") as
HTMLButtonElement).onclick = () => pubSub.Post(url, new Login());
And given our new button:
When we run the server (as part of the download) and navigate to http://127.0.0.1/index.html, we should see the same thing as when we run the TypeScript project:

But now, when we click on the button, we see this message logged.
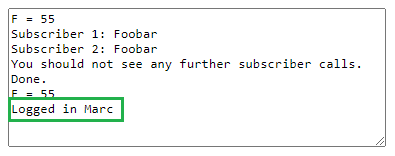
I'm not really bothering to fix the hacks in this example -- the point of it is mainly to demonstrate how the same semantic data on the front-end can achieve, with a semantic publisher/subscriber pattern on the back-end, a consistent use pattern between front and back ends. For me, this is the ultimate goal of using semantic data for both the client and the server.
The concerns are:
- The hacks I pointed out in the code comments.
- The horrid performance of these hacks.
- The case sensitive nature of serializing data back to the client.
- The case sensitive nature of obtaining the type by its class name on the back end.
- The issue of namespaces on the back-end: the front end is oblivious and we can rather easily do better on the back-end.
And of course, the ultimate concern is that nobody programs either the front-end nor the back-end like this. Personally, that doesn't bother me!
The point of this entire exercise was to create a publisher/subscriber that allows for:
- Type-based publication of data to subscribers.
- Publication can occur:
- Immediately (blocking execution of the application thread)
- Queued (the execution of the application thread continues)
- Asynchronous (the subscriber code is executed on a separate thread)
- To the back end!
As I mentioned in the introduction, a publisher/subscriber pattern is a really useful pattern for reducing, if not eliminating, spaghetti code. If the only take-away from this article is that point, then I've succeeded. Whether or not you agree or find use of a type-based publisher/subscriber is besides the point - I highly recommend a publisher/subscriber pattern on the front-end!
- 1st January, 2021: Initial version

