If you have some big arrays to compute but not enough RAM and a very slow HDD, then you can use your graphics cards as storage with this.
Introduction
All popular modern OSes have some paging technique that allows us to use more data than our RAM can hold. This is crucial to be able to continue testing/learning algorithms for larger scale data without buying extra RAM and just have thousands of apps running on the same machine without an overflow.
But, they don't (yet) have an option to use spare-VRAM in system that is connected with high-enough throughput pcie bridges. This header-only C++ tool (VirtualMultiArray) supports basic array-like usage pattern and is backed by a paging system that uses multiple-graphics card through OpenCL.
Github page: https://github.com/tugrul512bit/VirtualMultiArray/wiki/How-it-is-used
Background
The basic idea about this tool is to waste less CPU cycles in swap-death which occurs with over-allocation over-usage of big buffers. Wasting some VRAM is sometimes better than wasting all CPU-cycles in next 10 minutes trying to Ctrl-C the app (and save HDD from permanent damage in stormy weather, SSD from weariness, etc.).
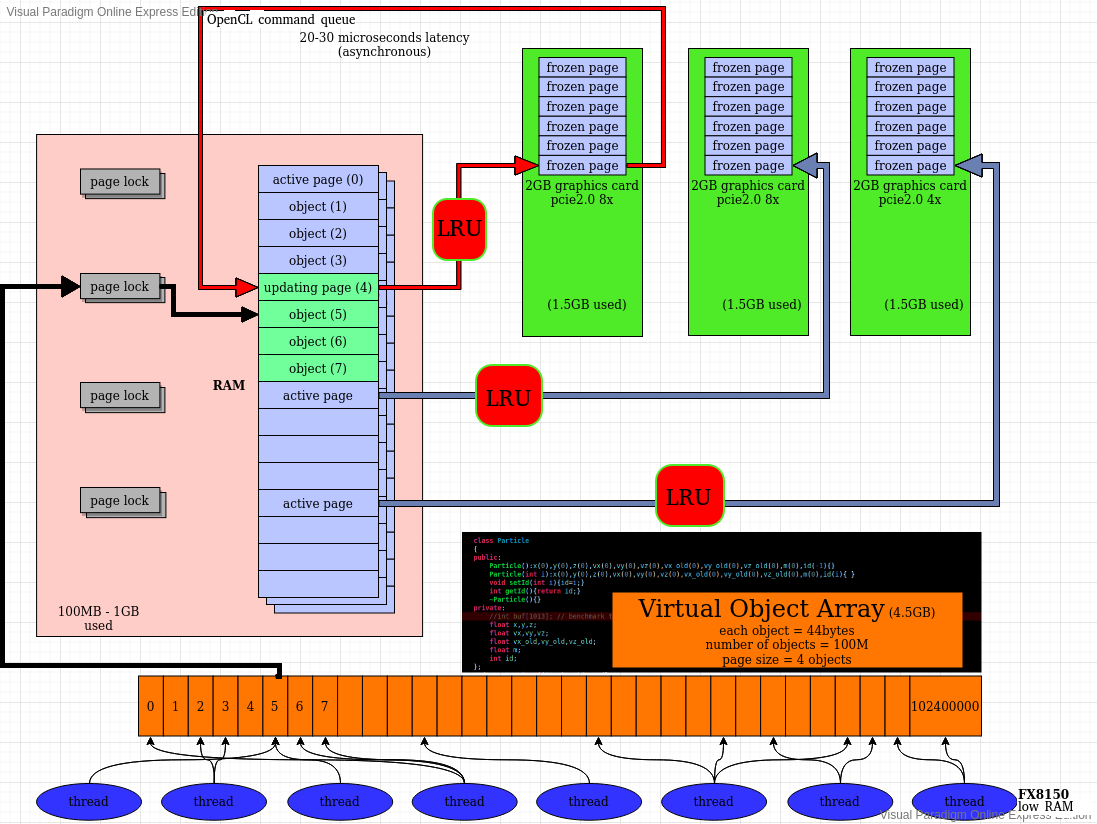
With this simple array tool, access to all indices of array are seamless while paging is handled only on demand by only those threads accessing the array. It is thread-safe, even on same elements.
Performance depends on access pattern, but for simple sequential multi-threaded access on a low-memory cheap system, it turns this:

into this:
Even after system is saved from near swap death, it takes several minutes to rollback those pages from HDD. So real time loss is much more than 10m33s but when an unused vram is given some work, it's both quick and fully responsive.
Using the Code
Some environment preparations:
- Since it uses OpenCL and written under Ubuntu 18.04 with Nvidia graphics card, its OpenCL library is "
lib64". This can be different for other OSes and graphics card vendors (like Amd/Intel). - For multi-threaded testing only, there is some OpenMP usage (one can use any other parallel task library).
- Tested with g++-7 (c++1y dialect) and g++-10
- For a short main.cpp source, compiling and linking looks like this:
g++ -std=c++1y -O3 -g3 -Wall -c -fmessage-length=0 -march=native -mavx -fopenmp -pthread
-fPIC -MMD -MP -MF"src/foo.d" -MT"src/foo.d" -o "src/foo.o" "../src/foo.cpp"
g++ -L/usr/local/cuda/lib64 -o "your_app_name" ./src/foo.o -lOpenCL -lpthread -lgomp
Usage is simple:
GraphicsCardSupplyDepot depot;
const size_t n = 1000000000ull; const size_t pageSize=1000; const int activePagesPerVirtualGpu = 5;
VirtualMultiArray<Bar> data(n,depot.requestGpus(),pageSize, activePagesPerVirtualGpu);
data.set(100,Bar()); Bar value = data.get(100);
- Create a
GraphicsCardSupplyDepot. - Request
gpus from it. - Give them to
VirtualArray<T> templated virtual array along with array size, page size and active pages per gpu. - Use
get/set methods (or the operator [] overload with proxy class, T var=data[i]; data[j]=x;). - Array size needs to be integer multiple of page size.
- Don't use too many active pages, they consume RAM.
#include "GraphicsCardSupplyDepot.h"
#include "VirtualMultiArray.h"
#include <iostream>
#include <numeric>
#include <random>
template<typename T>
class ArrayData
{
public:
ArrayData(){
std::random_device rd;
std::mt19937 rng(rd());
std::uniform_real_distribution<float> rnd(-1,1000);
for(int i=0;i<1000;i++)
{
data[i]=rnd(rng);
}
}
T calc(){ return std::accumulate(data,data+1000,0); }
private:
T data[1000];
};
int main(int argC, char ** argV)
{
GraphicsCardSupplyDepot depot;
const size_t n = 800000;
const size_t pageSize=10;
const int maxActivePagesPerGpu = 5;
VirtualMultiArray<ArrayData<int>> data(n,depot.requestGpus(),pageSize,
maxActivePagesPerGpu,{2,4,4});
#pragma omp parallel for
for(size_t i=0;i<n;i++)
{
data.set(i,ArrayData<int>());
}
#pragma omp parallel for
for(size_t i=0;i<n;i++)
{
if(data.get(i).calc()<0){ std::cout<<"error: doctor"<<std::endl;};
}
return 0;
}
Run it on a system with this idle-stats:
(10 minutes with vector vs 11 seconds with virtual array)
The {2,4,4} parameter is used for choosing ratio of vram usage (both amount and max cpu threads) per card. Test system has 3 cards, first one has less free memory, hence the 2 value. Other cards fully dedicated to program, so they are given 4. This value is also the number of virtual graphics cards per physical graphics card. 2 means there are 2 channels working on 2 virtual gpus, available for 2-cpu-threads to access array elements, concurrently. 4 means 4 threads in-flight for accessing elements, just by that card. {2,4,4,} lets 10 CPU threads access the array concurrently. If a card needs to be removed from this, simply zero is given: {0,4,4} disables first card. If second card has 24GB memory and others only 4GB, then {4,24,4} should work. Not tested with high-end system. If parameter is not given, its default value gives all cards 4 virtual cards which is equivalent to {4,4,....,4} and may need a lot of cpu cores to be fully used.
{2,4,4} also means, there are "maxActivePagesPerGpu=5" amount of actively computed/kept-on-RAM pages on each channel. First card has 2 clones, so it has 10 pages. Other cards have 20 each. Total 50 pages. Each page is given 10 elements in same sample code. This means a total of 500 elements in RAM, for 10-way threading. Since each element costs 4000 bytes, RAM holds only 2MB data. Much bigger pages give better sequential access performance, up to 3.3GB/s on test machine below:
On a PC with parts of FX8150(2.1GHz), GT1030(2GB, pcie v2.0 4-lanes), 2xK420(2GB, pcie v2.0 4 lanes, 8 lanes) and 4GB single-channel 1333MHz ddr RAM, performance is measured as this:
// cpu active
// testing method object size throughput page size threads n objects pages/gpu
// random 44 bytes 3.1 MB/s 128 objects 8 100k 4
// random 4kB 238.3 MB/s 1 object 8 100k 4
// serial per thread 4kB 496.4 MB/s 1 object 8 100k 4
// serial per thread 4kB 2467.0MB/s 32 objects 8 100k 4
// serial per thread 44 bytes 142.9 MB/s 32 objects 8 100k 4
// serial per thread 44 bytes 162.3 MB/s 32 objects 8 1M 4
// serial per thread 44 bytes 287.0 MB/s 1k objects 8 1M 4
// serial per thread 44 bytes 140.8 MB/s 10k objects 8 10M 4
// serial per thread 44 bytes 427.1 MB/s 10k objects 8 10M 100
// serial per thread 44 bytes 299.9 MB/s 10k objects 8 100M 100
// serial per thread 44 bytes 280.5 MB/s 10k objects 8 100M 50
// serial per thread 44 bytes 249.1 MB/s 10k objects 8 100M 25
// serial per thread 44 bytes 70.8 MB/s 100kobjects 8 100M 8
// serial per thread 44 bytes 251.1 MB/s 1k objects 8 100M 1000
// interleaved thread44 bytes 236.1 MB/s 1k objects 8 100M 1000
// interleaved thread44 bytes 139.5 MB/s 32 objects 8 100M 1000
// interleaved thread44 bytes 153.6 MB/s 32 objects 8 100M 100
// interleaved thread4kB 2474.0MB/s 32 objects 8 1M 5
It handles 4.5GB data with consuming only 100MB-1GB RAM (depends on total active pages).
Another example that actually does something (Mandelbrot set generation code from here):
#include "GraphicsCardSupplyDepot.h"
#include "VirtualMultiArray.h"
#include <iostream>
#include <fstream>
#include <complex>
class Color
{
public:
Color(){}
Color(int v){val=v;}
int val;
};
const int width = 1024;
const int height = 1024;
int value ( int x, int y) {std::complex<float> point((float)x/width-1.5,
(float)y/height-0.5);std::complex<float> z(0, 0);
unsigned int nb_iter = 0;
while (abs (z) < 2 && nb_iter <= 34) {
z = z * z + point;
nb_iter++;
}
if (nb_iter < 34) return (255*nb_iter)/33;
else return 0;
}
int main(int argC, char ** argV)
{
GraphicsCardSupplyDepot depot;
const size_t n = width*height;
const size_t pageSize=width;
const int maxActivePagesPerGpu = 10;
VirtualMultiArray<Color> img(n,depot.requestGpus(),pageSize,maxActivePagesPerGpu);
std::cout<<"Starting cpu-compute on gpu-array"<<std::endl;
#pragma omp parallel for
for (int i = 0; i < width; i++) {
for (int j = 0; j < height; j++) {
img.set(j+i*width,Color(value(i, j)));
}
}
std::cout<<"mandelbrot compute finished"<<std::endl;
std::ofstream my_Image ("mandelbrot.ppm");
if (my_Image.is_open ()) {
my_Image << "P3\n" << width << " " << height << " 255\n";
for (int i = 0; i < width; i++) {
for (int j = 0; j < height; j++) {
int val = img.get(j+i*width).val;
my_Image << val<< ' ' << 0 << ' ' << 0 << "\n";
}
}
my_Image.close();
}
else std::cout << "Could not open the file";
std::cout<<"File saved"<<std::endl;
return 0;
}
Verification:
Produced in an openmp-parallelized for-loop in setter method, read serially single threaded from get method.
Benefits of Overlapping I/O
CPU caches have only several cycles of overhead which makes only nanoseconds. RAM has tens of nanoseconds latency. Pcie latency is anywhere between 1 microsecond and 20 microseconds even if its just 1 byte data requested from graphics card. So, without doing anything while waiting for the data is a heavy loss of CPU cycles. This is against the benefit of using this tool (not losing cycles waiting on HDD swap death). Luckily, a CPU can run more threads than its number of logical cores. For this, some of threads are required to yield() their current work whenever they are in an unknown-duration waiting state, such as waiting for pcie data arrival for microseconds (a microsecond is eternity for a CPU).
Default OpenCL way to wait (without any idle/bust wait policy defined):
clFinish(commandQueue);
This is so simple but can also be so much CPU unfriendly, especially when the vendor of GPU had chosen the busy-wait policy as default for OpenCL implementation. At this point, CPU thread can not go on anywhere else and has to wait for clFinish() to return. A lot of CPU cycles wasted without using any floating-point pipeline nor integer-pipeline nor L1 cache.
A solution to make it scalable up to 64 threads on a 8-core/8-thread CPU (for simplicity, any error-handling was removed):
cl_event evt;
clEnqueueReadBuffer(q->getQueue(),...,.., &evt);
clFlush(q->getQueue());
const cl_event_info evtInf = CL_EVENT_COMMAND_EXECUTION_STATUS;
cl_int evtStatus0 = 0;
clGetEventInfo(evt, evtInf,sizeof(cl_int), &evtStatus0, nullptr);
while (evtStatus0 != CL_COMPLETE)
{
clGetEventInfo(evt, evtInf,sizeof(cl_int), &evtStatus0, nullptr);
std::this_thread::yield();
}
The clFlush() part is just an opening signal to OpenCL driver to let it start issuing commands in command queue, asynchronously. So this command immediately returns and the driver begins sending commands to graphics card.
Event object data is populated by the clEnqueueReadBuffer() (it reads data from VRAM into RAM) last parameter and the event tracking starts.
clGetEventInfo() is the query command to know if event has reached a desired state. When event status becomes CL_COMPLETE, the command is complete and data is ready on the target buffer.
Until the event becomes CL_COMPLETE, the while loop continues yielding its work to some other thread for some useful work. It could be an nbody algorithm's compute loop or some data copying inside L1 cache of CPU which is independent of DMA work being done outside of CPU or even another I/O thread that starts another DMA operation in parallel or hiding latency of LRU cache of another array access (LRU implementation info below).
Here is a 64-thread random-access benchmark of data sets ranging from 120kB to 4.6GB, on FX8150(8 thread/8 core):
[click here for a full-sized image]
When randomly-accessed data set size is larger than LRU capacity, the I/O is overlapped with other I/O (both between multiple graphics cards and within same card).
When random-access is done inside an L3-sized data set, any I/O is overlapped with L1 data transmissions during object copying from get() method to an Object variable. The test CPU has 8 MB L3 capacity so the performance increase is fast around 8MB data set size on the graph. The probability of I/O is very very low when data set is smaller than LRU and LRU has cached nearly all of content. But until its full, it continues fetching data from VRAM of graphics cards. Thanks to the overlapped I/O, it's faster than 8 thread version and a lot faster than single threaded one.
One issue about this graph is that performance drops again on left side. This is caused by page-lock contention because the less objects exist in array, the more threads race for the same lock. Each object in that benchmark is 60kB long so whole array of 4.6GB data is made of only about 75000 objects.
Least Recently Used (LRU) Cache Implementation
Depending on number of cache lines required by user, one of three different data paths are followed:
1 cache line (numActivePage = 1) per virtual gpu: direct eviction on demand. Whenever required virtual index is not cached in active page (cache line), it is fetched from VRAM (before old one is sent back if it had edited data).
fImplementation=[&](const size_t & ind)
{
if(directCache->getTargetGpuPage()!=ind) {
updatePage(directCache, ind); directCache->reset(); }
return directCache;
};
Then simply the get/set method uses the returned page pointer to do any read/write operation on it (and sets edited status if edits).
2-12 cache lines (numActivePage = 2..12) per virtual gpu: this is a direct&fast mapping of "priority queue" to the codes with a cache-friendly way of moving data.
Page<T> * const accessFast(const size_t & index)
{
Page<T> * result=nullptr;
auto it = std::find_if(usage.begin(),usage.end(),
[index](const CacheNode<T>& n){ return n.index == index; });
if(it == usage.end())
{
if(usage[0].page->getTargetGpuPage()!=index)
{
updatePage(usage[0].page, index);
usage[0].page->reset();
}
usage[0].index=index;
usage[0].used=ctr++;
result = usage[0].page;
}
else
{
it->used=ctr++;
result = it->page;
}
insertionSort(usage.data(),usage.size());
return result;
}
First, it checks if the required element(virtual index) is in std::vector. If not found, simply replaces first element with the required virtual index so that it will be cached for future accesses. Here, a counter is used to give it highest usage frequency directly, before evicting the page contents. This part can be tuned for other types of eviction policies. (For example, if LFU(least frequently used) eviction is required, then the counter can be removed and just usage[0].index = usage.[usage.size()/2].index + 1; can be used to send it to middle of vector. When it goes to middle of vector, left side elements continue for survival to not become victim next time and right side becomes privileged and easier to stay in cache. More like a "segmented" version of LFU. )
If it's already found in cache, then its counter value is updated to highest value in vector.
Finally, the insertion sort does the necessary ordering (shifting of right-hand-side elements in this version).
13 or more cache lines (numActivePage = 13+) per virtual gpu: this version uses std::unordered_map and std::list to have the necessary scaling up many more cache lines (like 500) without slowing down.
Page<T> * const accessScalable(const size_t & index)
{
Page<T> * result=nullptr;
typename std::unordered_map<size_t,
typename std::list<Page<T>*>::iterator>::iterator it =
scalableMapping.find(index);
if(it == scalableMapping.end())
{
Page<T> * old = scalableCounts.back();
size_t oldIndex = old->getTargetGpuPage();
if(old->getTargetGpuPage()!=index)
{
updatePage(old, index);
old->reset();
}
scalableCounts.pop_back();
scalableMapping.erase(oldIndex);
scalableCounts.push_front(old);
typename std::list<Page<T>*>::iterator iter = scalableCounts.begin();
scalableMapping[index]=iter;
result = old;
}
else
{
Page<T> * old = *(it->second);
scalableCounts.erase(it->second);
scalableCounts.push_front(old);
auto iter = scalableCounts.begin();
scalableMapping[index]=iter;
result = old;
}
return result;
}
Basically the same algorithm, just with higher efficiency for higher amount of cache lines. The unordered map holds necessary mapping from virtual index (VRAM buffer) to active page (physical page / RAM buffer) but the buffer pointer is held inside a list instead. Because on a list, it is quick (O(1)) to remove a node from back and add it to front. Unordered map also does the mapping quick (O(1)), thanks to its efficient(hash-table?) implementation. Instead of linearly searching a vector, finding the element directly is better. Once it is not found, eviction of "least recently used" page(cache-line) is done. If already found, then no eviction, just an access to buffer in RAM(or L1/L2/L3).
Taking back-node of list and moving it to head completes the cycle of LRU so that next time someone doesn't find something in cache, next victim is ready at the new back-node and the newest front-node is safe from being evicted for a long time (or a short time if there is cache thrashing happening in user's access pattern).
Once an implementation is chosen and assigned to fImplementation function member, it is called whenever a page is requested:
Page<T> * const access(const size_t & index)
{
return fImplementation(index);
}
after calculation of frozen(VRAM)-page index from VirtualArray.h:
T get(const size_t & index)
{
const size_t selectedPage = index/szp;
Page<T> * sel = pageCache->access(selectedPage);
return sel->get(index - selectedPage * szp);
}
after user calls get() method from VirtualMultiArray.h:
T get(const size_t & index) const{
const size_t selectedPage = index/pageSize;
const size_t numInterleave = selectedPage/numDevice;
const size_t selectedVirtualArray = selectedPage%numDevice;
const size_t selectedElement = numInterleave*pageSize + (index%pageSize);
std::unique_lock<std::mutex> lock(pageLock.get()[selectedVirtualArray].m);
return va.get()[selectedVirtualArray].get(selectedElement);
}
It does interleaved access to LRUs. Every K-th page belongs to another virtual graphics card and every virtual graphics card is cached. So, if one accesses pages 1,5,9,13,17,21, ... it requires same LRU if virtual graphics card setting is like this: std::vector<int> memMult = { 1,1,1,1 } ; The associativity of each LRU creates a strided pattern and multiple LRUs combined into a continuous parallel-caching with increased throughput because of independent page locks. Normally, a single LRU works with only 1 thread at a time and causes too high lock contention. But with N parallel LRUs, N number of threads can run at a time and help overlapping I/O with math operations.
For a simple image processing benchmark (that computes Gaussian Blur on a Mandelbrot image), throughput increased by 300% after addition of LRU (combined with tiled processing). Similarly, overlapped sequential reading/writing benefited from LRU and up to some point, even random-access pattern gained performance.
Features
Bulk Reading and Writing
These methods decrease average number of page locking per element greatly and achieve much higher bandwidth than basic get/set methods (sometimes up to 50x).
Writing to array:
std::vector<Obj> vec;
vec.push_back(Obj(1));
vec.push_back(Obj(1));
vArray.writeOnlySetN(i,vec);
Reading from array:
std::vector<Obj> result = vArray.readOnlyGetN(i,2)
Mapping
This method takes a user function and serves a raw buffer pointer to it as a better alternative for bulk operations involving SIMD/vector instructions, faster data copies, anything that needs an aligned buffer. When pages are big enough, it has slight advantage over bulk read/write methods.
In short, it optionally reads whole region into buffer, runs function, optionally writes data back into virtual array.
arr.mappedReadWriteAccess(303,501,[](int * buf){
for(int i=303;i<303+501;i++)
buf[i]=i;
},pinned=false,read=true,write=true,userPtr=nullptr);
If pinned parameter is true, mlock/munlock commands of Linux are used to stop OS paging the buffer out.
If read parameter is true, buffer is filled with latest data bits from virtual array before running the user function.
If write parameter is true, buffer contents are written back to virtual array after running the user function.
If userPtr parameter is not nullptr, then internal allocation is skipped and userPtr is used for user function+r/w copies instead. The user function takes negatively offset version of userPtr so the algorithm inside the function uses same indexing base as virtual array. If index=100 and range=100, then inside the function, user can access buf as buf[100]...buf[199].
Since the temporary buffer within mapping is aligned better than std::vector and is allocated all at once (unlike bulk-read's K number of allocations where K=number of pages locked), it tends to complete quicker. If user gives a dedicated pointer, then allocation is evaded altogether for a lesser latency before running the user function.
Uncached (streaming) Read/Write Operations
For some algorithms, there is no performance gain from any page size (cache line size) nor any number of active pages (cache lines). Uncached versions of (currently only for scalar versions of) get/set methods lower the latency of access. It is the same as get/set but with an addition of decorating any uncached accessing block with streamStart/Stop commands.
arr.streamStart();
arr.setUncached(..); arr.getUncached(..);
arr.streamStop();
If there will be no cached-access until the end of scope, then these extra start/stop commands are not required. Since cached writes need an eviction and bringing new data back, it costs twice as a cached read operation. But uncached write has only one way data movement so it is twice as fast in terms of latency.
Thread Safety Of Bulk R/W and Mapping
Both bulk and map operations are thread-safe within each page (pages are always thread-safe) but when their regions span multiple pages, then user is needed to make data consistency through explicit synchronizations. Multiple pages are not locked at the same time. Only 1 page is locked & processed at a time. Due to this, user needs to stop any concurrent accesses that overlap/touch same region. A single big bulk/map operation can have multiple read/write accesses which may conflict with other threads read/write until completed.
It is safe to use read-only versions (of map / bulk read / get) concurrently even in overlapped regions. Data is always preserved intact unless a writing method is used in same region. This may or may not invalidate data to be uploaded to graphics cards before reading it from another thread.
It is safe to do concurrent bulk write / write / map write on non-overlapped regions.
It is safe to do concurrent any (bulk or not )write / any (bulk or not)read operation on non-overlapped regions.
Why Bulk Read/Write?
Some algorithms are optimized for speed by loading more of data at once (such as "tiling") or just explicit caching of a region. Then the data is computed more efficiently on faster memory. For example, in an nbody algorithm, the data in RAM can be tiled as smaller "cache"-sized chunks to complete groups of force calculations quicker than just streaming data from RAM always. Sometimes chunks are as small as several CPU registers (register-tiling). Same rule applies to virtual memory too. "Paging" of this virtual array is just an implicit caching. Then user can further improve it by using a custom sized "tile" and load from "pages" into "tiles" that have both proper alignment for SIMD/vectorization of C++ compiler and the lower latency of "locking only once per page instead of once per element".
Why Map?
Mapping offers a raw pointer that does not have the awful side-effects of SetterGetter proxy class that works for the array subscription operator [] overloading.
The raw pointer given by mapping is also aligned at 4096 which helps improve data copying performance between devices (such as graphics cards) and RAM and running aligned-versions of SIMD instructions.
To further optimize, optionally allows pinning of buffer and user-defined pointer to stop allocating on each mapping.
GPU-accelerated find()
To find one or more elements inside the virtual array at a constant time,
template<typename S>
std::vector<size_t> find(T & obj, S & member, const int indexListMaxSize=1);
is used. First parameter is an object instance that contains a search-value as a member. Second parameter is the member to search for. This member needs to be direct member of "obj" object. This way, this method can compute its byte offset in the object and use it in all GPUs' "find" kernels to search member value in all objects. Last parameter is maximum number of indices returned from each OpenCL data channel. If 1000 is given, and if there are 10 total channels, then a total of 10000 indices may be returned from this method. All elements at those indices have the same member value. Usage is simple:
Plain Data
char searchObj = 'X';
std::vector<size_t> found = charArray.find(searchObj,searchObj);
This searches for at most 1 element per OpenCL channel that contains 'X' value.
Object
MyObject obj;
obj.id=450;
std::vector<size_t> found = charArray.find(obj,obj.id,100);
This searches for all objects that contains id=450 and maximum 100 results per OpenCL channel are returned.
The order of results (indices) in the vector are not guaranteed to be same between multiple calls to find().
Since it uses GPUs, the search performance relies on VRAM+GPU. For a system with a single GTX 1070, searching 1GB data for ~200 elements takes at most 45 milliseconds while a GT1030 + 2x K420 system takes 250 milliseconds to find the same elements that contain the required member value.
If element member value to find is at end of array, then this completes much quicker than std::find. If element member is found at the beginning of array, then std::find is faster. But, during the searches, RAM bandwidth is not used, only VRAM bandwidth is required. Only the result index array is copied from VRAM to RAM and is negligible when compared to std::find's bandwidth requirement. If its a small array that can fit into L1, then there is no use for a virtual array anyway. This virtual array is for big data that does not fit inside RAM.
Since the search time is ~constant and it returns an array of indices for elements, it is something like using a std::map with an augmentation of one-to-many relation for read-only access.
Currently, this is the only GPU-accelerated method. Maybe in future, a std::transform-like method can be added. But may not be needed at all, if user's project has an OpenCL/CUDA accelerated compute library already.
During the method call before running "find" kernel, all active pages on RAM are flushed to VRAMs of graphics cards so that the find() actually returns updated results. It is not advised to do concurrent write operations on virtual array during find() call. Reading concurrently is ok.
A Vectorized & Tiled N-body Compute Benchmark Using Virtual Array
Nbody algorithm is used for computing movements of masses under a gravitational field that is produced by masses. This example focuses on its most bottlenecking part, the force calculation, of N number of masses.
Since CPUs have more than one floating-point pipeline per core, namely SIMD, it would be a waste to not use all of them in a math-heavy algorithm, like the Nbody algorithm. To do this the easy way, mipp library is used (it is a header-only library and can use SSE/AVX/AVX512). All a developer needs to do is to use vector classes of it to do the computations in bigger chunks like 4 at a time, 8 at a time, 16, ...
Vectorization is just one part of optimization. Other part is tiling. Tiling makes use of repeated access to a smaller region of memory to use caching better.
- L1 cache tiling (assuming just 4000 x,y,z coordinates can fit inside L1 of CPU)
- RAM tiling (getting big chunks of virtual array data to RAM at once, working on them efficiently)
Cache tiling is simple. Just making use of small set of variables (coordinates of some particles) again and again is enough to use cache and many CPUs have at least tens of kB of L1 cache which is enough to hold thousands of mass coordinate data (x=4 byte, y=4 byte, z=4 byte: 12 bytes per particle). To do this, a tile of particles is prepared and is re-scanned for every particle in particle array. Actually there is no particle here, just arrays. X array, Y array, Z array for 3D position data and VX array, VY array, VZ array for 3D velocity data.
RAM tiling is just for optimizing virtual array's x,y,z reading efficiency. Reading 4000 particles at once means page-lock overhead & pcie latency is divided by 4000 on average per particle. Mapped access to virtual array does this and serves a raw pointer to work on data. Since mapped access also aligns the temporary buffer to 4096, any aligned-version of AVX/SSE instructions can be used on it. Aligned SSE/AVX data loading is generally faster than unaligned data loading.
Benchmark codes:
#include "GraphicsCardSupplyDepot.h"
#include "VirtualMultiArray.h"
#include "PcieBandwidthBenchmarker.h"
#include "CpuBenchmarker.h"
#include <iostream>
#include "omp.h"
#define MIPP_ALIGNED_LOADS
#include "mipp/mipp.h"
int main()
{
const int simd = mipp::N<float>();
std::cout<<"simd width: "<<simd<<std::endl;
const int n = simd * 40000;
std::cout<<"particles: "<< n <<std::endl;
GraphicsCardSupplyDepot depot;
VirtualMultiArray<float> xVir(n, depot.requestGpus(), 4000, 1,{5,15,10});
VirtualMultiArray<float> yVir(n, depot.requestGpus(), 4000, 1,{5,15,10});
VirtualMultiArray<float> zVir(n, depot.requestGpus(), 4000, 1,{5,15,10});
VirtualMultiArray<float> vxVir(n, depot.requestGpus(), 4000, 1,{5,15,10});
VirtualMultiArray<float> vyVir(n, depot.requestGpus(), 4000, 1,{5,15,10});
VirtualMultiArray<float> vzVir(n, depot.requestGpus(), 4000, 1,{5,15,10});
{
CpuBenchmarker init(0,"init");
#pragma omp parallel for
for(int i=0;i<n;i+=1000)
{
xVir.mappedReadWriteAccess(i,1000,[i](float * ptr)
{ for(int j=i;j<i+1000;j++) ptr[j]=j; },false,false,true);
yVir.mappedReadWriteAccess(i,1000,[i](float * ptr)
{ for(int j=i;j<i+1000;j++) ptr[j]=j; },false,false,true);
zVir.mappedReadWriteAccess(i,1000,[i](float * ptr)
{ for(int j=i;j<i+1000;j++) ptr[j]=j; },false,false,true);
vxVir.mappedReadWriteAccess(i,1000,[i](float * ptr)
{ for(int j=i;j<i+1000;j++) ptr[j]=j; },false,false,true);
vyVir.mappedReadWriteAccess(i,1000,[i](float * ptr)
{ for(int j=i;j<i+1000;j++) ptr[j]=j; },false,false,true);
vzVir.mappedReadWriteAccess(i,1000,[i](float * ptr)
{ for(int j=i;j<i+1000;j++) ptr[j]=j; },false,false,true);
}
}
mipp::Reg<float> smoothing = 0.0001f;
{
CpuBenchmarker bench(((size_t)n) * n * sizeof(float) * 3,
"mapped access for force-calc",((size_t)n)*n);
const int tileSize = 4000;
const int regTile = 500;
#pragma omp parallel for num_threads(32) schedule(dynamic)
for (int i = 0; i < n; i += regTile)
{
std::vector<float> x0 = xVir.readOnlyGetN(i,regTile);
std::vector<float> y0 = yVir.readOnlyGetN(i,regTile);
std::vector<float> z0 = zVir.readOnlyGetN(i,regTile);
mipp::Reg<float> fma1[regTile];
mipp::Reg<float> fma2[regTile];
mipp::Reg<float> fma3[regTile];
for(int j=0;j<regTile;j++)
{
fma1[j]=0.0f;
fma2[j]=0.0f;
fma3[j]=0.0f;
}
for (int ii = 0; ii < n; ii += tileSize)
{
xVir.mappedReadWriteAccess(ii, tileSize, [&,ii](float* ptrX1) {
const float* __restrict__ const ptrX = ptrX1 + ii;
yVir.mappedReadWriteAccess(ii, tileSize, [&,ii](float* ptrY1) {
const float* __restrict__ const ptrY = ptrY1 + ii;
zVir.mappedReadWriteAccess(ii, tileSize, [&, ii](float* ptrZ1) {
const float* __restrict__ const ptrZ = ptrZ1 + ii;
for (int ld = 0; ld < tileSize; ld += simd)
{
mipp::Reg<float> x = mipp::load(ptrX + ld);
mipp::Reg<float> y = mipp::load(ptrY + ld);
mipp::Reg<float> z = mipp::load(ptrZ + ld);
for(int reg0 = 0; reg0 < regTile; reg0++)
{
const int reg = reg0 ;
const mipp::Reg<float> x0r = x0[reg];
const mipp::Reg<float> y0r = y0[reg];
const mipp::Reg<float> z0r = z0[reg];
const mipp::Reg<float> dx = mipp::sub(x,x0r);
const mipp::Reg<float> dy = mipp::sub(y,y0r);
const mipp::Reg<float> dz = mipp::sub(z,z0r);
const mipp::Reg<float> dx2 = mipp::mul(dx,dx);
const mipp::Reg<float> dy2 = mipp::mul(dy,dy);
const mipp::Reg<float> dz2 = mipp::mul(dz,dz);
const mipp::Reg<float> dxy2 = mipp::add(dx2,dy2);
const mipp::Reg<float> dz2s =
mipp::add(dz2,smoothing);
const mipp::Reg<float> smoothed =
mipp::add(dxy2,dz2s);
const mipp::Reg<float> r = mipp::rsqrt(smoothed);
const mipp::Reg<float> r3 =
mipp::mul(mipp::mul(r, r), r);
fma1[reg] = mipp::fmadd(dx, r3, fma1[reg]);
fma2[reg] = mipp::fmadd(dy, r3, fma2[reg]);
fma3[reg] = mipp::fmadd(dz, r3, fma3[reg]);
}
}
}, false, true, false);
}, false, true, false);
}, false, true, false);
}
for(int j=0;j<regTile;j++)
{
vxVir.set(i+j, vxVir.get(i+j) + mipp::hadd(fma1[j]));
vyVir.set(i+j, vyVir.get(i+j) + mipp::hadd(fma2[j]));
vzVir.set(i+j, vzVir.get(i+j) + mipp::hadd(fma3[j]));
}
}
}
return 0;
}
First, virtual arrays are allocated (which may take several seconds for slow computers).
VirtualMultiArray<float> xVir(n, depot.requestGpus(), 4000, 1,{5,15,10});
Here, 4000(elements) is page size, 5,15,10 are parallel OpenCL data channels, 1 is page cache per channel. This means there are a total of (5+15+10)*1*4000 = 120000 elements cached inside RAM. This is a bit higher than 1/3 of all particles. So, maximum 1/3 of particles have RAM speed if all of them are concurrently used. For a system with all pcie bridges having same number of pcie channels, {5,5,5} or {10,10,10} or a similar arbitrary multiplier set can be used to maximize pcie usage efficiency. For the development computer, second card has higher pcie bandwidth and first card has some latency issues due to OS functions. To automate finding best bandwidth, PcieBandwidthBenchmarker().bestBandwidth(5 /* or 10 */ ) can be used instead of {...}.
Then arrays are initialized to some arbitrary values to counter any denormalized floating point operation slowdown effects (without initialization, it gets 10x slower on development machine). Lastly, forces are computed in a brute-force way (O(N^2) force calculations). Simd length (on fx8150 & -mavx -march=native g++ compiler options) is 8. This means its using AVX instructions of CPU to compute 8 data at once. With simd length = 8, there are 320000 particles to simulate. On a SSE CPU, it would create 160000 particles instead.
Due to the scalability of I/O operations, 32-threads are used in OpenMP pragma directive. This is for 3 graphics cards on pcie v2.0, a 8 thread cpu and 64bit build. It may have a different performance gain on other systems. But each "mapped access" to virtual array means a VRAM-RAM data movement which takes some time and is asynchronous to CPU thanks to the DMA engines. So, when a thread is blocked at waiting for VRAM data, another thread can context-switch in its place and continue doing other stuff. This way, some(or all?) of I/O latency is hidden behind that new task and overall performance increases. Normally, an NBody algorithm would work just fine with number of threads = 8 on a 8-core CPU, since it is pure math. But virtual array accessing adds I/O.
Same many-threads scalability can happen for any other I/O bottlenecked algorithm, not just N-body. Especially when system has more async graphics card DMA engines than number of CPU cores. For example, some Nvidia Tesla cards have 5 engines per card. So even a dual-core CPU would use 10-20 threads on a dual Tesla system.
The mapping part:
xVir.mappedReadWriteAccess(ii, tileSize, [&,ii](float* ptrX1) {
const float* __restrict__ const ptrX = ptrX1 + ii;
...
},false,true,false);
alone is not enough to extract full performance out of SIMD instructions. Compiler needs to know that pointers are not an alias. This is achieved by adding __restrict__ word for the pointer. Then compiler can do necessary optimizations which can lead to vectorization of math codes.
If this Nbody algorithm was optimized by Barnes-Hut, it could handle millions of particles with ease. If it was Fast-Fourier-Transform approach, it could handle billions of particles. On these bigger-scale simulations, bigger chunks of data would be read from virtual array and this may lead to OS paging some of them in/out during computations. To stop this, the first "false" parameter there could be switched to "true" to stop OS doing that. Since this simple example is a lot less likely to feel OS paging, it is not needed and even can cause performance degradation since pinning an array takes some time too.
Vectorization part is easy, thanks to mipp library, it would also work fine with any other vectorization library:
for (int ld = 0; ld < tileSize; ld += simd)
{
mipp::Reg<float> x = mipp::load(ptrX + ld);
mipp::Reg<float> y = mipp::load(ptrY + ld);
mipp::Reg<float> z = mipp::load(ptrZ + ld);
for(int reg0 = 0; reg0 < regTile; reg0++)
{
const int reg = reg0 ;
const mipp::Reg<float> x0r = x0[reg];
const mipp::Reg<float> y0r = y0[reg];
const mipp::Reg<float> z0r = z0[reg];
const mipp::Reg<float> dx = mipp::sub(x,x0r);
const mipp::Reg<float> dy = mipp::sub(y,y0r);
const mipp::Reg<float> dz = mipp::sub(z,z0r);
const mipp::Reg<float> dx2 = mipp::mul(dx,dx);
const mipp::Reg<float> dy2 = mipp::mul(dy,dy);
const mipp::Reg<float> dz2 = mipp::mul(dz,dz);
const mipp::Reg<float> dxy2 = mipp::add(dx2,dy2);
const mipp::Reg<float> dz2s = mipp::add(dz2,smoothing);
const mipp::Reg<float> smoothed = mipp::add(dxy2,dz2s);
const mipp::Reg<float> r = mipp::rsqrt(smoothed);
const mipp::Reg<float> r3 = mipp::mul(mipp::mul(r, r), r);
fma1[reg] = mipp::fmadd(dx, r3, fma1[reg]);
fma2[reg] = mipp::fmadd(dy, r3, fma2[reg]);
fma3[reg] = mipp::fmadd(dz, r3, fma3[reg]);
}
}
The trick about optimizing force storage (fmadd part) performance is, not using "store" commands. Just using a vector of CPU registers in fmadd (last 3 instructions there) operation. This lets compiler to do load&store where only necessary and use registers directly where it can. Giving compiler some freedom helps in getting some performance. For FX8150 at 3.6GHz(no turbo), this achieves 90GFLOPS compute performance. At 3.6GHz, absolute peak of CPU is 230 GFLOPS but Nbody algorithm does not have equal number of "+" and "*" math operations. Due to this, absolute achievable maximum performance is actually 70% of peak which is 161 GFLOPS. To get 161 GLFLOPS, there has to be a register-tiling scheme that uses registers more often than memory accessing. For simplicity, only cache tiling is used here and still achieves more than 50% achievable peak compute performance. On a Ryzen R9 3950x CPU, it should get close to 1TFLOPS.
After force registers of a particle are accumulated with all force components from other particles, a horizontal-add operation adds 8 elements of them and writes it to velocity (virtual)array as 1 element.
Basic Error Handling
Currently, constructor of VirtualMultiArray checks page size - array length and number of gpus - number of pages based inconsistencies and throws relevant error messages.
try
{
VirtualMultiArray<char> img(n,gpus,pageSize,maxActivePagesPerGpu,{20,20,20});
}
catch(std::exception & e)
{
std::cout<<e.what()<<std::endl;
}
Also data copying between active pages and graphics cards (during get/set/map/read/write operations) have "throw" that tell which part is failing.
Points of Interest
Edit: LRU caching overhead was optimized out by making all I/O be waited on idle-loop. Now, a 8 logical core CPU can run 64 threads, 48 of them idle-waiting on I/O while 8 of them doing math.
Feel free to add any ideas like making it an in-memory database, a gpu-accelerated science tool, bug-fixes, etc.
Optimization
Since user can change ratio of memory usage and bandwidth usage per card with "memMult" parameter (vector<int>, {2,2,3,..}), some computers with NVMe drives can offload some of the work from a low-end graphics card or an integrated-gpu (that shares same RAM as its host CPU) to those NVMe if swap file is on that drive. This could enable different load-balancing patterns on element accesses. Currently, the balancing is simply interleaved gpu access from each element. Virtual page 1 access goes to virtual gpu 1, page 2 goes virtual gpu 2, ... possibly a hundred virtual gpus can serve for 100-element-wide threaded page fetching.
If physical cards are not on same type of pcie bridge (1 on 16x slot, 1 on 8x slot, etc..), VirtualMultiArray's "memMult"(std::vector<int>) constructor parameter can be used to put more pressure on the higher bandwidth slot by giving it something like {2,1} or {3,1} or any ratio required. One can even prepare a mini-benchmark to pick best values for the local computer.
Using small objects is not efficient if pages are not given enough objects to make up for the pcie latency. A slow pcie may do only 100k read/write operations per second (or ~10 microseconds latency) so the more bytes on object data, the higher the efficiency. One potential optimization for image processing could be converting pixels into 16x16 tiles (256 pixels, 3 floats each, 3kB data per tile object) to have spatial locality and pcie efficiency.
Currently, all active pages are pinned buffers which are not movable by OS paging system. In future versions, there will be an option to disable this because pinned memory is rather scarce resource that may not work for too big pages. If "error: buffer read" or similar output is observed on std::cout, then probably pageSize is too high or there are too many pages or the object is too big to be pinned by OS/OpenCL (or simply there is not enough memory left).
Edit: some new features
To auto-tune data sharing ratio for maximum bandwidth, there is an optional benchmark class:
#include "PcieBandwidthBenchmarker.h"
PcieBandwidthBenchmarker bench;
std::vector<int> ratios = bench.bestBandwidth(2);
PcieBandwidthBenchmarker bench(250);
std::vector<int> ratios = bench.bestBandwidth(10);
VirtualMultiArray<Obj> data1(..,..,..,..,bench.bestBandwidth(2));
To auto-tune data sharing ratio for maximum size, there is a new parameter (mem) for constructor of VirtualMultiArray:
auto maximizeMem = VirtualMultiArray<Type>::MemMult::UseVramRatios;
auto customMem = VirtualMultiArray<Type>::MemMult::UseDefault;
VirtualMultiArray<Obj> data1(..,..,..,..,bench.bestBandwidth(2),customMem);
VirtualMultiArray<Obj> data1(..,..,..,..,overridenParameter,maximizeMem);
If mem parameter is given "UseVramRatios", then it overrides ratios in memMult parameter except zero valued elements:
auto maximizeMem = VirtualMultiArray<Type>::MemMult::UseVramRatios;
VirtualMultiArray<Obj> data1(..,..,..,..,{0,overridden,overridden},maximizeMem);
VirtualMultiArray<Obj> data2(..,..,..,..,{0,0,overridden}, maximizeMem);
So that combined memory-size is still maximized but only using non-zero ratio cards.
Benchmark method uses both device-to-host and host-to-device copies concurrently to measure combined bandwidth instead of just one-way performance. Maybe later read-optimized or write-optimized benchmark options can be added. For now, benchmark measures read+write performance at once.
Optimizing memMult parameter for maximum size may reduce the combined bandwidth below the equal-data-distribution case (which is the default case when user does not use last two parameters of VirtualMultiArray's constructor). For example, a card with 24GB vram would effectively throttle all other 2GB cards throughput with "MemMult::UseVramRatios".
Benchmarking class also doesn't take "combined size" into consideration and may cause capacity issues if in a very asymmetrical gpu system.
Virtual array=5GB
PCIE lanes bandwidth maximize bandwidth maximize capacity default
Gtx 1080ti: 1x 1GB/s 1GB/s 1GB/s 1.0GB/s
Gtx 1070 : 4x 2GB/s 2GB/s 0.7GB/s 1.0GB/s
Gt1030 : 4x 2GB/s overflow error 0.2GB/s 1.0GB/s
PCIE lanes vram maximize bandwidth maximize capacity default
Gtx 1080ti: 1x 11GB 550MB 2.6GB 1.7GB
Gtx 1070 : 4x 8 GB 2.2GB 1.9GB 1.7GB
Gt1030 : 4x 2 GB overflow error 0.5GB 1.7GB
Currently, algorithm does not take these points into consideration. Users may need to manually change ratios in benchmark results to evade buffer errors. Especially the main card of system (that sends frames to screen) has a constant memory usage by OS which can be as high as 100s of MB. That card's (probably 1st card in ratio array) multiplier can be manually reduced down to {1,3,3} instead of directly using {2,3,3} output of a benchmark.
History
- 5th February, 2021: Currently, this is a very basic version with very little documentation in itself but at least beats a slow HDD in random-access performance by 15x at least and beats an old SSD in sequential read/write. Also when combined with big enough objects, it beats a NVMe.
- 8th February, 2021: Auto-tuning parameter option added to constructor of
VirtualMultiArray class. Adjusts memory consumption on each card to maximize array-size allowed (but doesn't check if other apps use same video card so main card may overflow when approaching to maximum too close). Also added a benchmarking class that fine-tunes data sharing ratios to maximize bandwidth (instead of size). - 13th February, 2021: Added bulk read/write and mapping operations to greatly increase throughput
- 6th March, 2021: Added gpu-accelerated
find() method and an example for nbody algorithm - 15th March, 2021: Added LRU caching, how its overhead was balanced by overlapped I/O and benchmark results

