This project tries to provide a different perspective to learn software development and tree data structures by building a few tree data structures (the forest) in Python way with object-oriented programming.
Introduction
Building software projects is hard, and it also requires broad knowledge such as writing code, understanding algorithms, set up environments, testing, and deployment. Besides, each language has its ways of implementing things, even if all the languages were object-oriented programming languages. Getting into the habit of thinking about software development from various angles takes time. This project, Build the Forest Series, tries to provide a different perspective to learn software development and tree data structures by building a few tree data structures (the forest) in Python way with object-oriented programming.
Why Trees?
Trees are essential data structures that solve many problems in software everywhere. Also, tree-related questions are asked in almost all software engineer position interviews. Although we may not need to implement a tree data structure from scratch for our daily jobs, having a solid understanding of tree data structures helps us solve many problems.
Assumption
The project assumes Python 3.9 or newer, and the readers have a basic understanding of Python programming and data structures. Besides, for the sake of simplicity, the implementation does not take multi-threading into account, i.e., not thread-safe.
Project Setup
The project has the following basic layout:
forest-python
├── forest
│ ├── __init__.py
│ ├── binary_trees
│ │ ├── __init__.py
│ │ └── binary_search_tree.py
│ └── tree_exceptions.py
└── tests
├── __init__.py
├── conftest.py
└── test_binary_search_tree.py
(The project is available at forest-python.)
Unlike compiled languages (e.g., C++ and Java), Python does not have a compiler to check errors for us, so we need to use additional tools. In this project, we use the following tools to ensure our code's quality.
- Flake8 is a tool for finding bugs and style problems in Python source code.
- It is a static type checker for Python programs. Although Python is a dynamic language, type checking helps prevent potential bugs and issues.
- Pydocstyle for document style checking
- Black for coding style checking
- pytest for unit testing
Besides, the code also follows My Python Coding Style and Principles.
What is the Binary Search Tree?
The Binary Search Tree is a binary tree whose keys always satisfy the binary-search-tree-property:
- Let x be a node in a binary search tree.
- If y is a node in the left subtree of x, then
y.key < x.key. - If y is a node in the right subtree of x, then
y.key > x.key.
Note that y.key = x.key is a special case if the binary search tree allows duplicate keys. For simplicity, this project does not allow duplicate keys, i.e., all keys must be unique.
The binary search tree data structure supports many dynamic operations. The most basic functions are search, insert and delete. Other auxiliary operations can be supported, including getting the minimum key, the maximum key, a node's predecessor, and successor.
Build the Binary Search Tree
This section will walk through the implementation and some thoughts behind the implementation choices.
Node
The binary search tree node is the building block of the binary search tree.
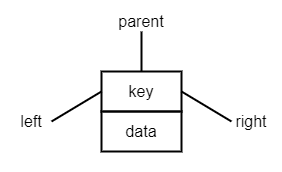
The tree node can be present in the above picture and has the following attributes:
- The key is the essential field of building the binary search tree, and it must satisfy the binary-search-tree-property, and its value must be comparable.
- The left attribute points to the left node.
- The right attribute points to the right node.
- The parent attribute points to the parent node, and
- the data field is for containing whatever data.
The purpose of a data structure is to manage data. Although many textbooks omit the data field for the sake of simplicity, in the real world, it is not useful if a tree node does not hold any data. That's why our node definition has the data filed.
Why parent? The parent is not essential by the binary search tree definition, but it simplifies the implementation, so we do not need to track the parent node while doing tree operations. If space usage is concerned, the binary search tree can be implemented with tree nodes that don't have the parent field.
With the above ideas in mind, we can define the node class in the following way:
@dataclasses.dataclass
class Node:
key: Any
data: Any
left: Optional["Node"] = None
right: Optional["Node"] = None
parent: Optional["Node"] = None
Why use dataclass?
Python introduced dataclass in the 3.7 release, which mainly for a class that contains data only. When a class is defined as a dataclass, the dataclass decorator provides some basic functionality for us, such as __init__() and __repr__() functions. So a dataclass offers a convenient way to define a class that mainly for data and increases readability. Since our tree node is for data only, it makes sense we define it as a dataclass.
Exception
In our binary search tree, there is one case we would like to raise an exception, which happens when we try to insert a node whose key already exists in the tree. Python provides several built-in exceptions. However, none of them address the case of duplicated keys. Therefore, we define our exception for this purpose. In the tree_exceptions.py, we add the exception.
class DuplicateKeyError(Exception):
def __init__(self, key: str) -> None:
Exception.__init__(self, f"{key} already exists.")
This object clearly says the reason for the exception and tells us which key is duplicate.
Core Functions
Like a real tree with roots, branches, and leaves, we treat the tree as an object. Therefore, we define our binary search tree as a class and use it to declare binary search tree objects. The BinarySearchTree class should have the minimum functionalities – insert, delete and search, so we can grow, trim, and lookup the tree.
class BinarySearchTree:
def __init__(self) -> None:
self.root: Optional[Node] = None
def search(self, key: Any) -> Optional[Node]:
…
def insert(self, key: Any, data: Any) -> None:
…
def delete(self, key: Any) -> None:
…
Insert
To build the BinarySearchTree, we first need to insert a tree node into the tree, and the new node is always added at the leaf level. The following steps summarize the insertion algorithm.
- Find the proper location (i.e., the new node's parent) to insert the new node by walking through the tree from the root and comparing the new node's key with each node's key along the way.
- After finding the parent node, update the parent's left (or right depends on the location) to point to the new node.
- Update the new node's parent attribute to point to the parent node.
The picture below visualizes each step of the insert algorithm.

The interface takes key and data as parameters and uses them to construct a new tree node. Then, find the proper location based on the binary-search-tree-property to insert the node. So, we implement the insert function in the following way:
def insert(self, key: Any, data: Any) -> None:
new_node = Node(key=key, data=data)
parent: Optional[Node] = None
current: Optional[Node] = self.root
while current:
parent = current
if new_node.key < current.key:
current = current.left
elif new_node.key > current.key:
current = current.right
else:
raise
tree_exceptions.DuplicateKeyError(key=new_node.key)
new_node.parent = parent
if parent is None:
self.root = new_node
elif new_node.key < parent.key:
parent.left = new_node
else:
parent.right = new_node
Search
The search algorithm is similar to the insertion. We look for the node by a given key.
- Walkthrough the tree from the root and compare the key with each node's key along the tree walk.
- If a key matches, we found the node.
- If no key matches after we reach the leaf level, the node does not exist in the tree.
We can visualize the search steps through the following picture:
And implement the search method as the following:
def search(self, key: Any) -> Optional[Node]:
current = self.root
while current:
if key < current.key:
current = current.left
elif key > current.key:
current = current.right
else:
return current
return None
One thing to note is that if the node does not exist, we return None. It is the client's responsibility to check if the search function returns None, and a given key that does not live in a tree is normal.
Delete
The binary search tree's deletion has three cases – the node to be deleted has no child, one child, or two children.
The idea to delete a node is to replace a subtree with the node to be deleted. The technique comes from Introduction to Algorithms. In this book, the author defines a transplant method to move subtrees around within the binary search tree. With the transplant method, we can utilize the method to implement the three deletion cases. Therefore, this section starts from the transplant function and then the three delete cases.
Transplant
The transplant method replaces the subtree rooted at node deleting_node with the subtree rooted at node replacing_node. After the replacing_node replaces the deleting_node, the parent of the deleting_node becomes the replacing_node's parent, and the deleting_node's parent ends up having the replacing_node as its child. Since the function is internal, we define the function with a leading underscore, i.e., _transplant.
def _transplant(self, deleting_node: Node, replacing_node: Optional[Node]) -> None:
if deleting_node.parent is None:
self.root = replacing_node
elif deleting_node == deleting_node.parent.left:
deleting_node.parent.left = replacing_node
else:
deleting_node.parent.right = replacing_node
if replacing_node:
replacing_node.parent = deleting_node.parent
Case 1: No Child
If the node to be deleted has no child, use the transplant function to replace the node with None.
Case 2: Only One Child
If the node to be deleted has only one child, whether the child is left or right, use the transplant function to replace the child's node.
One Left Child
One Right Child
Case 3: Two Children
The case of the node to be deleted has two children can be broken down into two subcases:
3.a The right child of the deleting node is also the leftmost node in the right subtree.
In this case, the right child must have only one right child. Otherwise, it cannot be the leftmost node. Therefore, we can replace the deleting node with its right child, as shown in the picture below:
3.b. The right child of the deleting node also has two children.
In this case, we find the leftmost node from the right subtree to replace the node to be deleted. Note that when we take out the leftmost node from the right subtree, it also falls into the deletion cases: case 1: no child or case 2: only one right child. Otherwise, it cannot be the leftmost node.
Therefore, we use the transplant function twice: one to take out the leftmost node and the other one to replace the deleting node with the original leftmost node. The picture below demonstrates the steps of this case.
The following steps are the procedure of the deletion:
- Find the node to be deleted.
- If the deleting node has no child, replace the node with
None. - If the deleting node has only one child, replace the node with its child.
- If the deleting node has two children:
- Find the leftmost node from the right subtree
- If the leftmost node is also the direct child of the deleting node, replace the deleting node with the child
- If the right child also has two children,
- take out the leftmost node by doing the same thing as cases: no child or only one right child
- take the leftmost node as the new root of the right subtree
- replace the deleting node with the new root of the right subtree
With the algorithm, we can implement the delete method as the following:
def delete(self, key: Any) -> None:
if self.root and (deleting_node := self.search(key=key)):
if deleting_node.left is None:
self._transplant(
deleting_node=deleting_node, replacing_node=deleting_node.right
)
elif deleting_node.right is None:
self._transplant(
deleting_node=deleting_node, replacing_node=deleting_node.left
)
else:
replacing_node = BinarySearchTree.get_leftmost(node=deleting_node.right)
if replacing_node.parent != deleting_node:
self._transplant(
deleting_node=replacing_node,
replacing_node=replacing_node.right,
)
replacing_node.right = deleting_node.right
replacing_node.right.parent = replacing_node
self._transplant(
deleting_node=deleting_node, replacing_node=replacing_node
)
replacing_node.left = deleting_node.left
replacing_node.left.parent = replacing_node
Auxiliary Functions
In addition to the core functions, the binary search tree may have other useful functions, such as get the leftmost node, get the successor of a node, and get the height of a tree. These functions do not tie to a specific tree object. Instead, they can apply to any tree and any given subtree. Therefore, we define these functions as independent functions instead of methods of the BinarySearchTree class.
In this project, we implement the auxiliary functions as static methods of the BinarySearchTree class.
Why @staticmethod?
When a method is defined as a static method, it means this method performs some functionality related to the class but does not require any class instance to do the work. The static method definition perfectly matches the case of the auxiliary functions that perform operations bound to the BinarySearchTree class, not a BinarySearchTree object.
Why not just define a regular function?
Using the static method not only logically makes sense but also improves the readability. When a client (i.e., a human) reads the code, the function definition tells the client that this function is bound to any object whose types are BinarySearchTree.
The following section focuses on these auxiliary functions.
Get the Height
The height of a tree (subtree) is the longest length down to a leaf from the root. Also, a tree only has one node, its height is zero. For example, the picture below shows the tree's height is 4, the subtrees with roots 11 and 30 have heights 2 and 1, respectively.
The tree height is the key factor determining binary search tree operation performance (See Analysis section for more detail).
To calculate the tree height, we can recursively increment the height by one for each child's height. If a node has two children, we use the max function to get the bigger height from the children and increase the highest by one.
@staticmethod
def get_height(node: Node) -> int:
if node.left and node.right:
return max(
BinarySearchTree.get_height(node=node.left),
BinarySearchTree.get_height(node=node.right),
) + 1
if node.left:
return BinarySearchTree.get_height(node=node.left) + 1
if node.right:
return BinarySearchTree.get_height(node=node.right) + 1
return 0
Get the Leftmost and Rightmost Nodes
The leftmost node contains the minimum key in a given (sub)tree because of the binary-search-tree-property. Similarly, the rightmost node's key is the maximum in a given (sub). To find the leftmost and the rightmost is simple – follow the path.
Since we can retrieve the leftmost or rightmost node from any given subtree (if not the entire tree), the parameter is the root of the given (sub)tree.
Get the leftmost
@staticmethod
def get_leftmost(node: Node) -> Node:
current_node = node
while current_node.left:
current_node = current_node.left
return current_node
Get the rightmost
@staticmethod
def get_rightmost(node: Node) -> Node:
current_node = node
while current_node.right:
current_node = current_node.right
return current_node
Predecessor and Successor
When we traverse a binary search tree, the predecessor of a node is the node that lies before the given node, and the successor is the node that lies exactly right after the given node. There are many ways to traverse a binary search tree. In this project, the predecessors and the successors are in in-order traversal order. An in-order traversal traverses a binary search tree in a sorted way. Therefore, the node's predecessor will be the node just right before the given node in the sorted order, and the successor will be the node right after the given node in the sorted order. Since in-order traversal produces sorted order results, using the in-order predecessor and successor of a given node is most useful.
Predecessor
There are two cases of finding the predecessor of a given node:
- If the left child of the given node is not empty, then the rightmost node of the left subtree is the predecessor.
- If the left child of the given node (x) is empty, then we go up from the given node (x) until we encounter a node (y) that is the right child of its parent (z). The parent (z) is the predecessor of the given node (x).
|
The picture below shows the two cases:
Case 1 is straightforward. For case 2, let us take node 24 and node 34 as examples.
In the case of the predecessor of node 24, node 24 is x. Since node 24 (x) does not have a left child, we go up from node 24 (x), and we find the node 30 (y) is the right child of its parent, node 23 (z). The algorithm tells us the node 23 (z) is the predecessor of node 24 (x).
Regarding the case of the predecessor of node 34, node 34 is x. Since node 34 (x) does not have a left child, we go up from node 34 (x), and we find the node 34 (y) is also the right child of its parent, node 30 (z). Therefore, the predecessor of node 34 (x) is node 30 (z). Note that a node can be x and y simultaneously if the node is the right child.
Get the Predecessor
@staticmethod
def get_predecessor(node: Node) -> Optional[Node]:
if node.left:
return BinarySearchTree.get_rightmost(node=node.left)
parent = node.parent
while parent and (node == parent.left):
node = parent
parent = parent.parent
return parent
Successor
The algorithm of getting a successor is symmetric to the algorithm of getting a predecessor, and it also has two cases of finding the successor of a given node:
- If the right child of the given node is not empty, then the leftmost node of the right subtree is the successor.
- If the right child of the given node (x) is empty, then we go up from the node (x) until we encounter a node (y) that is the left child of its parent (z). The parent (z) is the successor of the given node (x).
|
The picture below shows the two cases:
Like the predecessor case, a node can be x and y simultaneously if the node is the left child.
In the case of the successor of node 15, node 15 is x and y, and node 20 is z which is the successor of node 15.
For the successor of node 22, node 22 is x, node 4 is y, and node 23 is z. So node 23 is the successor of node 22 (x).
Get the Successor
@staticmethod
def get_successor(node: Node) -> Optional[Node]:
if node.right:
return BinarySearchTree.get_leftmost(node=node.right)
parent = node.parent
while parent and (node == parent.right):
node = parent
parent = parent.parent
return parent
Special Functions
Per Python document, __repr__() is to compute the official string representation of an object. The document also says, “This is typically used for debugging, …”. Therefore, in our BinarySearchTree class, we utilize this function to provide the tree detail, which will help us to debug issues.
def __repr__(self) -> str:
if self.root:
return (
f"{type(self)}, root={self.root}, "
f"tree_height={str(self.get_height(self.root))}"
)
return "empty tree"
When we print repr() on a BinarySearchTree object, we can view the tree details like below:
<class '__main__.BinarySearchTree'>, root=Node(key=23, data='23',
left=Node(key=4, data='4', left=Node(key=1, data='1', left=None, right=None, parent=...),
right=Node(key=11, data='11', left=Node(key=7, data='7', left=None, right=None, parent=...),
right=Node(key=20, data='20', left=Node(key=15, data='15', left=None, right=None, parent=...),
right=Node(key=22, data='22', left=None, right=None, parent=...), parent=...), parent=...),
parent=...), right=Node(key=30, data='30', left=Node(key=24, data='24', left=None, right=None,
parent=...), right=Node(key=34, data='34', left=None, right=None, parent=...), parent=...),
parent=None), tree_height=4
This information could help us to debug issues.
Test
A unit test is a minimum for a software project to ensure its quality. The pytest framework is a popular test framework for Python programs. In our project, we use it with the following setup:
Check each link for the details.
Analysis
A software program able to work, correctness and performance are both necessary. However, I would argue correctness has a higher priority than performance. When we implement a software program, we should always ensure the program works properly and then tune its performance. Without correctness, the program is useless. That is also the reason this article is written in this order: Test section before Analysis section. After the test section (and make sure the BinarySearchTree works), this section focuses on its performance. This section’s analysis applies to the general binary search tree (not just the BinarySearchTree we implement).
The space complexity of the binary search tree is O(n), where n is the total number of the nodes.
The run time of each operation of a binary search tree highly depends on the tree height. If the tree height is h, we can have the run time for each operation as the following:
For the insert operations, we need first to find the location to insert a node from the root to the leaf level, which cost the running time is T(h) on a tree height h. And then update the node attributes, which cost the constant running time. Therefore, the overall running time of the insert operation is T(h) + constant, which is also equivalent to O(h) since the big-O notation is the upper bound of the run time.
Similarly, the search and the delete operations also need to walk the tree from the root until we find the node or the node to be deleted. Therefore, their running time is also O(h) where h is the tree height.
To find the leftmost and the rightmost nodes, we also need to walk the tree from the given node to the leaf level since the leftmost and the rightmost nodes must be in the leaf level. The running time is also O(h) where h is the (sub)tree height.
The predecessor of a given node has two cases: 1. the given node has a left child, and 2. the left child of the given node is empty.
Since the rightmost node of the left subtree is the predecessor if the given node has a left child, the run time of case 1 is equivalent to get the leftmost node, which is O(h) where h is the tree height.
Regarding case 2, we need to find the node which is the parent’s right child. In other words, it could cost O(h) if the predecessor is at the very top level.
Therefore, the run time of the predecessor is the combination of both cases: O(h) + O(h) = 2 * O(h) = O(h).
A successor is symmetric to a predecessor, and it also has run time O(h) where h is the tree height.
Now, we know the run time of each operation is dependent on the tree height. The next thing we want to know is how high a tree could be when the tree has n nodes.
If a tree is complete, its height is O(lg n). However, if a binary tree is linear chained, its height becomes O(n).
Based on the theorem, “The expected height of a randomly build binary search tree on n distinct keys is O(lg n)”, the time complexity of each operation in average cases becomes O(lg n). The detail and proof of this theorem are discussed in Introduction to Algorithms chapter 12.4.
Therefore, we can summary the run time of each operation in the table. n is the number of nodes.
Example
Tree data structures are wildly used in software, including implement other data structures. For example, the operations provided by the BinarySearchTree allow us to use a search tree as a key-value map. This section demonstrates a key-value Map by using the BinarySearchTree we implement in this project.
The key-value Map class supports operations such as inserting a key-value item, getting an item by its key, and deleting an item by its key. To support these operations, we need to implement __setitem__ function for inserting a key-value item, __getitem__ function for retrieving an item by its key, and __delitem__ function for deleting an item by its key. Therefore, we have the implementation like the following:
from typing import Any, Optional
from forest.binary_trees import binary_search_tree
class Map
def __init__(self) -> None:
self._bst = binary_search_tree.BinarySearchTree()
def __setitem__(self, key: Any, value: Any) -> None:
self._bst.insert(key=key, data=value)
def __getitem__(self, key: Any) -> Optional[Any]:
node = self._bst.search(key=key)
if node:
return node.data
return None
def __delitem__(self, key: Any) -> None:
self._bst.delete(key=key)
@property
def empty(self) -> bool
return self._bst.empty
if __name__ == "__main__":
contacts = Map()
contacts["Mark"] = "mark@email.com"
contacts["John"] = "john@email.com"
contacts["Luke"] = "luke@email.com"
print(contacts["Mark"])
del contacts["John"]
print(contacts["John"])
(The complete example is available at bst_map.py.)
Summary
The binary search tree offers good space usage and relatively good performance on operations such as insertion, search, and deletion in average cases. However, we cannot guarantee the tree will be balanced in most cases. Because of that, the binary search tree is not widely used to solve real-world problems. Several variants of the binary search tree are introduced to solve the unbalance problem and improve certain operations' performance, such as Red-Black Tree and AVL tree. Therefore, fully understanding the binary search tree is a solid foundation for advanced tree data structures.
(Originally published at Shun's Vineyard on March 13, 2021)

