When we use a data structure to manage data, one important use case is to go over all the data we manage. In this article, we will implement the functions to traverse binary trees.
The article is the second one of the Build the Forest in Python Series. In this article, we are not going to build a tree. Instead, we will implement the functions to traverse binary trees. When we use a data structure to manage data, one important use case is to go over all the data we manage. That's why tree traversal is essential.
Introduction
Traversal is a method of examining the nodes of a tree systematically to visit each node exactly once. There are many ways to traverse a binary tree: in-order, pre-order, post-order, and level-order. The names come from the relative position of the root to its subtrees. Tree traversal is also a form of graph traversal. In-order, pre-order, and post-order traversals are types of depth-first traversal, whereas Level-order traversal is a type of breadth-first traversal. This article will go through these traversal functions' implementation in both recursive and iterative ways.
Project Setup
The same as Build the Binary Search Tree, the implementation assumes Python 3.9 or newer. In addition, we add two modules to our project: traversal.py for traversal functions and test_traversal.py for its unit tests. After adding these two files, our project layout becomes the following:
Forest-python
├── forest
│ ├── __init__.py
│ ├── binary_trees
│ │ ├── __init__.py
│ │ ├── binary_search_tree.py
│ │ └── traversal.py
│ └── tree_exceptions.py
└── tests
├── __init__.py
├── conftest.py
├── test_binary_search_tree.py
└── test_traversal.py
(The complete code is available at forest-python.)
Function Interface
The traversal methods we implement here try to be as generic as possible. In theory, we can apply the traversal methods to any binary trees as long as their nodes have left and right fields, and this is true. However, for different types of binary trees, their nodes may have additional information. For instance, a threaded binary tree node has information that tells us if the node is a leaf or a thread. In this case, when we traverse a threaded binary tree, we need to check the extra information to determine if we reach the leaf or not. In other words, we cannot just check if the node's left or right fields are empty.
Instead of adding logic for each tree type's different conditions, we define the supported tree type, so the client (i.e., a human or a linter) would know if a tree type is supported or not. Our supported type definition looks like below:
from typing import Union
from forest.binary_trees import binary_search_tree
SupportedNode = Union[None, binary_search_tree.Node]
SupportedTree = Union[binary_search_tree.BinarySearchTree]
Currently, we support types None and Node for nodes, and we only support type BinarySearchTree for trees; we will add more when we implement other types of binary trees.
With the type definitions, we can utilize the type annotation to define our traversal functions (use in-order traversal as an example).
from typing import Any, Iterator, Optional
Pairs = Iterator[tuple[Any, Any]]
"""Iterator of Key-Value pairs, yield by traversal functions. For type checking"""
def inorder_traverse(tree: SupportedTree, recursive: bool = True) -> Pairs:
…
Note that we also define a custom type Pairs for the return. Although we need to write more code in the way, as The Zen of Python suggests, "Explicit is better than implicit." This way, the client can clearly see the correct parameter type to input and the type the functions will return, and a type-checking tool (like mypy) can prevent type mismatch issues. Besides, we will implement them in both recursive and non-recursive ways for depth-first traversals, and that's why we have the second parameter, recursive.
Why not @overload?
Python is a dynamically typed language, and function overloading does not make too much sense in Python. But we can utilize the type annotation to prevent type mismatch issues.
Since Python 3.5, PEP-484 introduced @overload decorator. According to the official document, "The @overload decorator allows describing functions and methods that support multiple different combinations of argument types." It sounds great. However, it is for the benefit of type checkers only. At runtime, a client code can still pass any parameters to the function. The document also says, "An example of overload that gives a more precise type than can be expressed using a union or a type variable." Therefore, we define the SupportedTree type using the Union. Using SupportedTree is also less code than defining several @overload-decorated definitions.
Why the return type Pairs is an iterator?
The idea is to implement the traversal functions as generators. One main benefit to do so is that when a generator iterator returns, it picks up where it left off. This method could save a lot of memory when a tree is huge. The client code of the traversal functions can process one item at one time. Besides, the client code will be simpler and easier to read.
In-Order Traversal
In-order traversal visits a binary tree by the following method, and each node can represent as a root of the subtree.
- Traverse to the left subtree
- Visit the root
- Traverse to the right subtree
The picture below demonstrates the idea of in-order traversal. The yellow part is the left subtree of the root 23, and the green part is root 23's right subtree. And the small numbers (i.e., 1, 2, 3) next to the nodes indicate the traversal order.
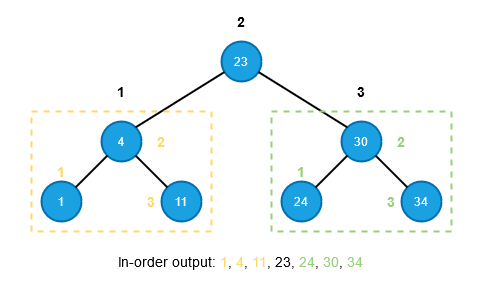
If the binary tree is also a binary search tree, the binary-search-tree-property allows us to produce sorted order key values by in-order traversal, as shown in the picture above.
Binary tree traversal can be done by using either recursion or an auxiliary stack. As mentioned in the previous section, we implement them in both recursive and non-recursive ways.
def inorder_traverse(tree: SupportedTree, recursive: bool = True) -> Pairs:
if recursive:
return _inorder_traverse(node=tree.root)
return _inorder_traverse_non_recursive(root=tree.root)
Because we want to hide the implementation detail, we name the actual implementation function (_inorder_traverse and _inorder_traverse_non_recursive) with a leading underscore, which means they are internal functions.
Recursive Implementation
Traversal recursively is the most natural way to traverse a tree because of the in-order traversal definition and can be implemented as the following:
def _inorder_traverse(node: SupportedNode) -> Pairs:
if node:
yield from _inorder_traverse(node.left)
yield (node.key, node.data)
yield from _inorder_traverse(node.right)
Note that we use yield from to call _inorder_traverse recursively. That's because _inorder_traverse is a generator; to allow a generator to delegate part of its operations to another generator, we need to use yield from.
Non-Recursive Implementation
We visit the left subtree first, then the root, and the right subtree regarding the in-order traversal. So, we push the right subtree first and then the root before we visit the left subtree. The push order is because a stack is a first-in-last-out data structure. After we visit the left subtree, we pop the stack to visit the root, and then pop again to visit the right subtree. Repeat the steps until the stack is empty.

To implement an in-order traversal function, we need a stack to keep the roots of subtrees that we will visit later. When doing non-recursive traversal, the keys are: 1. when do we push a node to the stack and pull a node from the stack, and 2. when do we produce (i.e., visit) the node while we are traversing.
- When a node we are visiting has a right child, we push its right child to the stack and then push the node to the stack.
- When a node is popped from the stack, we produce the node if the node has no right child or its right child is the same as the top node.
We use Python's built-in list as a stack to implement the non-recursive in-order traversal because the built-in list has the first-in-last-out ability: list.append(x) adds an item to the end of the list and list.pop() removes and returns the last item from the list.
def _inorder_traverse_non_recursive(root: SupportedNode) -> Pairs:
if root is None:
raise StopIteration
stack = []
if root.right:
stack.append(root.right)
stack.append(root)
current = root.left
while True:
if current:
if current.right:
stack.append(current.right)
stack.append(current)
current = current.left
continue
stack.append(current)
current = current.left
else:
if len(stack) > 0:
current = stack.pop()
if current.right is None:
yield (current.key, current.data)
current = None
continue
else:
if len(stack) > 0:
if current.right == stack[-1]:
yield (current.key, current.data)
current = stack.pop() if len(stack) > 0 else None
continue
else:
continue
else:
break
Reverse In-Order Traversal
In-order traversal produces sorted output in ascending order when traversing a type of binary search tree. If the binary tree is traversed in reversed in-order traversal, the sorted result becomes descending. To traverse in reversed in-order order, we visit the right subtree first and the left subtree last.
- Traverse to the right subtree
- Visit the root
- Traverse to the left subtree
Reverse in-order traversal can also be implemented by recursive and non-recursive ways. And the implementation is symmetric to in-order traversal.
def reverse_inorder_traverse(tree: SupportedTree, recursive: bool = True) -> Pairs:
if recursive:
return _reverse_inorder_traverse(node=tree.root)
return _reverse_inorder_traverse_non_recursive(root=tree.root)
Recursive Reversed In-Order Traversal
def _reverse_inorder_traverse(node: SupportedNode) -> Pairs:
if node:
yield from _reverse_inorder_traverse(node.right)
yield (node.key, node.data)
yield from _reverse_inorder_traverse(node.left)
Non-Recursive Reversed In-Order Traversal
def _reverse_inorder_traverse_non_recursive(root: SupportedNode) -> Pairs:
if root is None:
raise StopIteration
stack = []
if root.left:
stack.append(root.left)
stack.append(root)
current = root.right
while True:
if current:
if current.left:
stack.append(current.left)
stack.append(current)
current = current.right
continue
stack.append(current)
current = current.right
else:
if len(stack) > 0:
current = stack.pop()
if current.left is None:
yield (current.key, current.data)
current = None
continue
else:
if len(stack) > 0:
if current.left == stack[-1]:
yield (current.key, current.data)
current = stack.pop() if len(stack) > 0 else None
continue
else:
continue
else:
break
Pre-Order Traversal
Pre-order traversal visits a binary tree by the following method:
- Visit the root.
- Traverse to the left subtree.
- Traverse to the right subtree.
The picture below shows the idea of pre-order traversal. The yellow part is the left subtree of the root 23, and the green part is root 23's right subtree. The same as in-order traversal, the small numbers (i.e., 1, 2, 3) next to the nodes indicate the traversal order.
We also implement the pre-order traversal in recursive and non-recursive ways.
def preorder_traverse(tree: SupportedTree, recursive: bool = True) -> Pairs:
if recursive:
return _preorder_traverse(node=tree.root)
return _preorder_traverse_non_recursive(root=tree.root)
Recursive Pre-Order Traversal
Recursive implementation is straightforward, just follow the traversal order.
def _preorder_traverse(node: SupportedNode) -> Pairs:
if node:
yield (node.key, node.data)
yield from _preorder_traverse(node.left)
yield from _preorder_traverse(node.right)
Non-Recursive Pre-Order Traversal
Regarding the non-recursive implementation, the picture below demonstrates non-recursive pre-order traversal.
Non-recursive pre-order traversal is simpler than non-recursive in-order traversal. Since we visit the root first, the process can be seen as the steps:
- When we visit a node, we push its right child to the stack (if it has one) and then push its left child to the stack (if it has one).
- When a node is popped from the stack, we produce the node.
def _preorder_traverse_non_recursive(root: SupportedNode) -> Pairs:
if root is None:
raise StopIteration
stack = [root]
while len(stack) > 0:
temp = stack.pop()
yield (temp.key, temp.data)
if temp.right:
stack.append(temp.right)
if temp.left:
stack.append(temp.left)
Post-Order Traversal
Post-order traversal visits a binary tree by the following method:
- Traverse to the left subtree.
- Traverse to the right subtree.
- Visit the root.
The picture below shows the idea of post-order traversal. Similar to the previous traversals, the small numbers (i.e., 1, 2, 3) next to the nodes indicate the traversal order.
Once again, we build the post-order traversal in recursive and non-recursive approaches.
def postorder_traverse(tree: SupportedTree, recursive: bool = True) -> Pairs:
if recursive:
return _postorder_traverse(node=tree.root)
return _postorder_traverse_non_recursive(root=tree.root)
Recursive Post-Order Traversal
Similar to the in-order and the pre-order traversals, recursive implementation is simple.
def _postorder_traverse(node: SupportedNode) -> Pairs:
if node:
yield from _postorder_traverse(node.left)
yield from _postorder_traverse(node.right)
yield (node.key, node.data)
Non-Recursive Post-Order Traversal
However, the non-recursive implementation for post-order traversal is a bit complicated. The picture below demonstrates the post-order traversal in a non-recursive way.
- Like non-recursive in-order traversal, when we perform non-recursive post-order traversal, if a node we visit has a right child, we push its right child to the stack and then push the node to the stack as well.
- We produce the node when the node is popped from the stack, and it has no right child, or the stack becomes empty. Besides, if the node popped from the stack has a right child and the child is different from the top node in the stack, it means that we already visited the right subtree. In this case, we can produce the node. Otherwise, we swap the top node in the stack with the current node and traverse to the right subtree.
def _postorder_traverse_non_recursive(root: SupportedNode) -> Pairs:
if root is None:
raise StopIteration
stack = []
if root.right:
stack.append(root.right)
stack.append(root)
current = root.left
while True:
if current:
if current.right:
stack.append(current.right)
stack.append(current)
current = current.left
continue
else:
if current.left:
stack.append(current)
else:
yield (current.key, current.data)
current = current.left
else:
if len(stack) > 0:
current = stack.pop()
if current.right is None:
yield (current.key, current.data)
current = None
else:
if len(stack) > 0:
if current.right != stack[-1]:
yield (current.key, current.data)
current = None
else:
temp = stack.pop()
stack.append(current)
current = temp
else:
yield (current.key, current.data)
break
else:
break
Level-Order Traversal
Unlike the previous depth-first traversal, level-order traversal is breadth-first. In this case, we visit every node on a level before going to a lower level. The idea is shown in the picture below:
Instead of using a stack, we use a queue to implement the level-order traversal function. A queue is a first-in-first-out data structure. For each node, the node is visited first and then put its children in the queue. Dequeue a node from the queue, visit the node first, and then enqueue the node's children. Repeat until the queue is empty.
We also use Python's built-in list as a queue to implement the level-order function because the built-in list has the first-in-first-out ability as well: list.append(x) adds an item at the end of the list and list.pop(0) removes and returns the first item from the list.
def levelorder_traverse(tree: SupportedTree) -> Pairs:
queue = [tree.root]
while len(queue) > 0:
temp = queue.pop(0)
if temp:
yield (temp.key, temp.data)
if temp.left:
queue.append(temp.left)
if temp.right:
queue.append(temp.right)
Test
As always, we should have unit tests for our code as much as possible. Here, we use the basic_tree function in conftest.py that we created in Build the Binary Search Tree to test our traversal functions. In test_traversal.py, we can do the unit test like below: We check if the traversal output is the same as expected (test postorder_traverse as an example).
def test_binary_search_tree_traversal(basic_tree)
tree = binary_search_tree.BinarySearchTree()
for key, data in basic_tree:
tree.insert(key=key, data=data)
assert [item for item in traversal.postorder_traverse(tree)] == [
(1, "1"), (7, "7"), (15, "15"), (22, "22"), (20, "20"), (11, "11"),
(4, "4"), (24, "24"), (34, "34"), (30, "30"), (23, "23")
]
(Check test_traversal.py for the complete unit test.)
Analysis
Depth-First Traversal: In-Order, Reverse In-Order, Pre-Order, and Post-Order
Run-time in In-Order, Reserve In-Order, Pre-Order, and Post-Order Traversals
In graph algorithms, the running time of depth-first search is O(V+E), where V is the number of vertex and E is the number of edges. (The reason why the run time is O(V+E), please refer to Introduction to Algorithms chapter 22.3). Since in-order, reverse in-order, pre-order, and post-order traversals are types of depth-first traversals, we can map these traversals to the depth-first search. Therefore, we have run time O(V+E) for these traversals. A vertex in a binary tree is a node. Besides, for a binary tree, if the tree has n nodes, it must have n-1 edges. Therefore, we can rewrite the run time to O(n+(n-1))=O(2n-1)=O(n), where n is the number of nodes. Therefore, their run-time becomes O(n).
Regarding the space complexity, we need to analyze it based on our approach: recursive or non-recursive.
Space Complexity in Recursive Approach
The space usage is the call stack when we make the recursive approach, i.e., how deep the function calls itself. We traverse a binary tree from the root to the leaf level, so the tree height determines how deep the function calls itself. Therefore, if a binary tree has n node, we know the average case is O(lg n) when the tree is randomly built; the worst case is O(n) when the tree is linear chained.
Space Complexity in Non-Recursive Approach
The space usage is the size of the stack if we use the non-recursive approach. The same as the recursive approach, the stack size is decided by the height of a tree. Therefore, for a binary tree that has n node, we know the average case is O(lg n) when the tree is randomly built; the worst case is O(n) when the tree is linear chained.
Breadth-First Traversal: Level-Order
A breadth-first search algorithm has time complexity O(V+E), where V is the number of vertex and E is the number of edges (please refer Introduction to Algorithms chapter 22.2 for the detail). Therefore, the running time of level-order traversal is also O(n), where n is the number of nodes. The reason is the same as in-order and the rest depth-first type traversals discussed above.
Since we use a queue to implement level-order traversal, the space cost is the queue’s size. The reason we use a queue in level-order traversal is to track the nodes at the same level. The maximum number of nodes that could be in the queue is the leaf level, which is 2^h where h is the tree height (this can be easily proved by math induction), and the worst case of the queue’s size happens when the tree is balanced, i.e., the maximum number of the leaf nodes. We also know a balanced tree is also the best case of a tree height, which is (lg n) where n is the number of nodes. Therefore, the worst case of the queue size becomes O(2^h)=O(2^(lg n))=O(n), where n is the number of nodes.
However, the queue size’s best case happens when each level has only one node, i.e., the tree is linear chained. In this case, the space complexity becomes constant, i.e., O(1).
The table below summarizes the complexity of each traversal implementation.
Examples
Since we have implemented the traversal routines, we can use these traversal functions to implement the __iter__ method of the Map class from the Binary Search Tree example and iterate the data of a map object.
from typing import Any, Optional
from forest.binary_trees import binary_search_tree
from forest.binary_trees import traversal
class Map
def __init__(self) -> None:
self._bst = binary_search_tree.BinarySearchTree()
def __setitem__(self, key: Any, value: Any) -> None
self._bst.insert(key=key, data=value)
def __getitem__(self, key: Any) -> Optional[Any]
node = self._bst.search(key=key)
if node:
return node.data
return None
def __delitem__(self, key: Any) -> None
self._bst.delete(key=key)
def __iter__(self) -> traversal.Pairs
return traversal.inorder_traverse(tree=self._bst)
@property
def empty(self) -> bool
return self._bst.empty
if __name__ == "__main__":
contacts = Map()
contacts["Mark"] = "mark@email.com"
contacts["John"] = "john@email.com"
contacts["Luke"] = "luke@email.com"
print(contacts["Mark"])
del contacts["John"]
print(contacts["John"])
for contact in contacts:
print(contact)
(The complete example is available at bst_map.py.)
Summary
Binary tree traversals are the methods to visit each node of a binary tree systematically, and each node is visited only once. They are special cases of graph search algorithms, e.g., depth-first search and breadth-first search, and can be implemented by different approaches, and each approach has its pros and cons. The following articles will introduce modified binary search trees, threaded binary search trees, which allow us to traverse the trees without using a stack or recursive approach, i.e., the space complexity for traversals is always constant.
(Originally published at Shun's Vineyard on March 17, 2021.)

