This article continues the discussion of Threaded Binary Trees, and will implement Double Threaded Binary Search Tree, which combines the left and right single-threaded binary trees and has both advantages, but it also increases the complexity.
Project Setup
Follow the same style and assumption as other articles in the Build the Binary Search Tree, the implementation assumes Python 3.9 or newer. This article adds two modules to our project: double_threaded_binary_trees.py for the double-threaded binary search tree implementation and test_double_threaded_binary_tree.py for its unit tests. After adding these two files, our project layout becomes the following:
forest-python
├── forest
│ ├── __init__.py
│ ├── binary_trees
│ │ ├── __init__.py
│ │ ├── binary_search_tree.py
│ │ ├── double_threaded_binary_tree.py
│ │ ├── single_threaded_binary_trees.py
│ │ └── traversal.py
│ └── tree_exceptions.py
└── tests
├── __init__.py
├── conftest.py
├── test_binary_search_tree.py
├── test_double_threaded_binary_tree.py
├── test_single_threaded_binary_trees.py
└── test_traversal.py
(The complete code is available at forest-python.)
What is Double Threaded Binary Tree?
As we talked about in the What is Threaded Binary Trees section, the double-threaded binary tree has both single-threaded binary trees' characters: for any empty left or right attribute, the empty attributes are threaded towards either the in-order predecessor or successor: If the left attribute is empty, the left attribute points to the node's predecessor; if the right attribute is empty, the right attribute points to the node's successor.
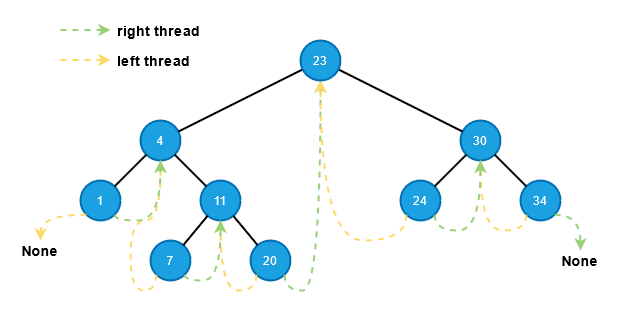
Although adding right and left threads increases complexity, the double-threaded tree has the advantages of both single-threaded trees.
- Fast successor and predecessor access
- No auxiliary stack or recursion approach for in-order, pre-order, and reverse in-order traversals
- Since no auxiliary stack or recursion is required, memory consumption is reduced.
- Utilize wasted space. Since the empty left and right attribute of a node does not store anything, we can use the empty left and right attributes as threads.
Build Double Threaded Binary Search Tree
As we did in the Build Single-Threaded Binary Search Trees section, this section will walk through the implementation and discuss some thoughts behind the implementation choices.
Node
Since a node could have a left thread, a right thread, or both, the node has two more fields – left_thread and right_thread – than the binary search tree node.

Both the left_thread and the right_thread attributes are boolean variables: True if the attribute is a thread; False otherwise.
@dataclass
class Node:
key: Any
data: Any
left: Optional["Node"] = None
right: Optional["Node"] = None
parent: Optional["Node"] = None
left_thread: bool = False
right_thread: bool = False
As the binary search tree node, we define the node class for threaded binary trees as a dataclass.
The double-threaded binary tree has core functions (insert, delete and search) to build and modify and other auxiliary functions that do not tie to a specific tree, such as getting the leftmost node and get the height of the tree. The same __repr__() function we implemented in the binary search tree can also be used for debugging purposes.
Since the double-threaded binary tree has both left and right threads, we can implement in-order, pre-order, and reversed in-order traversals that do not use a stack or use a recursive approach. The following is the class overview of the double-threaded binary tree.
class DoubleThreadedBinaryTree:
def __init__(self) -> None:
self.root: Optional[Node] = None
def __repr__(self) -> str
if self.root:
return (
f"{type(self)}, root={self.root}, "
f"tree_height={str(self.get_height(self.root))}"
)
return "empty tree"
def search(self, key: Any) -> Optional[Node]:
…
def insert(self, key: Any, data: Any) -> None:
…
def delete(self, key: Any) -> None:
…
@staticmethod
def get_leftmost(node: Node) -> Node:
…
@staticmethod
def get_rightmost(node: Node) -> Node:
…
@staticmethod
def get_successor(node: Node) -> Optional[Node]:
…
@staticmethod
def get_predecessor(node: Node) -> Optional[Node]:
…
@staticmethod
def get_height(node: Optional[Node]) -> int:
…
def preorder_traverse(self) -> traversal.Pairs:
…
def inorder_traverse(self) -> traversal.Pairs:
…
def reverse_inorder_traverse(self) -> traversal.Pairs:
…
Insert
The insert operation is similar to the single-threaded binary trees, but the double-threaded tree needs to consider both left and right threads update.
- Find the proper location (i.e., the new node's parent) to insert the new node by walking through the tree from the root and comparing the new node's key with each node's key along the way. When walking to the right subtree, check the
right_thread variable as well. If the variable is True, we reach the leaf node, and that's the parent node. Similarly, when walking to the left subtree, we check the left_thread. If it is true, we reach the leaf node and find the node's parent node to be inserted. - Update the new node's parent attribute to point to the parent node.
- If the new node is the parent's left child, copy the parent's left attribute to the new node's left attribute (the parent's left attribute must be the thread before the insertion), and set the
left_thread variable to True. Update the parent's left attribute to point to the new node and set the parent's left_thread to False. - If the new node is the right child of its parent, copy the parent's right attribute to the new node's right attribute (the parent's right attribute must be the thread before the insertion), and set the
right_thread variable to True. Update the parent node's right attribute to point to the new node and set the parent's right_thread to False.
The picture below demonstrates the steps of node insertion.
The implementation has to check and update both left and right threads.
def insert(self, key: Any, data: Any) -> None:
node = Node(key=key, data=data)
if self.root is None:
self.root = node
else:
temp = self.root
while temp:
if node.key < temp.key:
if temp.left_thread is False and temp.left:
temp = temp.left
continue
else:
node.left = temp.left
temp.left = node
node.right = temp
node.right_thread = True
node.parent = temp
temp.left_thread = False
if node.left:
node.left_thread = True
break
elif node.key > temp.key:
if temp.right_thread is False and temp.right:
temp = temp.right
continue
else:
node.right = temp.right
temp.right = node
node.left = temp
node.left_thread = True
temp.right_thread = False
node.parent = temp
if node.right:
node.right_thread = True
break
else:
raise tree_exceptions.DuplicateKeyError(key=key)
Search
The search operation is similar to the single-threaded trees, but we check both the left_thread and the right_thread variables to determine if we reach the leaf.
- Walkthrough the tree from the root and compare the key with each node's key along the tree walk
- If a key matches, we found the node.
- If no key matches when either
left_thread or right_thread is True, the node does not exist in the tree.
The implement is similar to the search of the single-threaded binary trees with a simple modification – check both left_thread and right_thread.
def search(self, key: Any) -> Optional[Node]:
current = self.root
while current:
if key == current.key:
return current
elif key < current.key:
if current.left_thread is False:
current = current.left
else:
break
else:
if current.right_thread is False:
current = current.right
else:
break
return None
Delete
Like the deletion in any other binary tree, the double-threaded binary tree's delete can be broken down into three subcases: the node to be deleted has no child, only one child, or two children. We also use the transplant technique that we did in the Binary Search Tree: Delete to replace a subtree with the node to be deleted. Although the basic idea is the same, both the transplant function and the delete function need to take right and left threads into a count. The most important thing we need to keep in mind is that when we delete a node, if there are other nodes' right or left attributes that point to the node to be deleted, we need to update those nodes' threads (i.e., right or left attributes).
Case 1: No Child
If the node to be deleted has no child, both left and right attributes are empty, and both left_thread and right_thread are True. Regarding the threads, there are two cases we need to consider. See the picture below.
Case 2: Only One Child
If the node to be deleted has only one child, whether it's a left or right child, we always need to update its thread: if the deleting node is the left child, update the right thread that the deleting node interacts with. If the deleting node is the right child, update the left thread that points to it. The situations that we need to update the threads are like the picture below.
Case 3: Two Children
Similar to the binary search tree delete, the case of the node to be deleted has two children can be broken down into two subcases:
3.a. The right child of the deleting node is also the leftmost node in the right subtree. In this case, the right child must have only one right child. Therefore, we can replace the deleting node with its right child, as shown in the picture below.
3.b. The right child of the deleting node also has two children.
In this case, we find the leftmost node from the right subtree to replace the node to be deleted. Note that when we take out the leftmost node from the right subtree, it also falls into the deletion cases: case 1: no child or case 2: only one right child. Otherwise, it cannot be the leftmost node.
Therefore, we use the transplant function twice: one to take out the leftmost node and the other one to replace the deleting node with the original leftmost node. The picture below demonstrates the thread consideration when we perform deleting.
The replacing node has no child:
The replacing node has only one right child:
Based on the pictures above, we can implement the delete and transplant functions as the following:
def delete(self, key: Any) -> None:
if self.root and (deleting_node := self.search(key=key)):
if (deleting_node.left_thread or deleting_node.left is None) and (
deleting_node.right_thread or deleting_node.right is None
):
self._transplant(deleting_node=deleting_node, replacing_node=None)
elif (
deleting_node.left_thread or deleting_node.left is None
) and deleting_node.right_thread is False:
successor = self.get_successor(node=deleting_node)
if successor:
successor.left = deleting_node.left
self._transplant(
deleting_node=deleting_node, replacing_node=deleting_node.right
)
elif (
deleting_node.right_thread or deleting_node.right is None
) and deleting_node.left_thread is False:
predecessor = self.get_predecessor(node=deleting_node)
if predecessor:
predecessor.right = deleting_node.right
self._transplant(
deleting_node=deleting_node, replacing_node=deleting_node.left
)
elif deleting_node.left and deleting_node.right:
predecessor = self.get_predecessor(node=deleting_node)
replacing_node: Node = self.get_leftmost(node=deleting_node.right)
successor = self.get_successor(node=replacing_node)
if replacing_node.parent != deleting_node:
if replacing_node.right_thread:
self._transplant(
deleting_node=replacing_node, replacing_node=None
)
else:
self._transplant(
deleting_node=replacing_node,
replacing_node=replacing_node.right,
)
replacing_node.right = deleting_node.right
replacing_node.right.parent = replacing_node
replacing_node.right_thread = False
self._transplant(
deleting_node=deleting_node, replacing_node=replacing_node
)
replacing_node.left = deleting_node.left
replacing_node.left.parent = replacing_node
replacing_node.left_thread = False
if predecessor and predecessor.right_thread:
predecessor.right = replacing_node
if successor and successor.left_thread:
successor.left = replacing_node
else:
raise RuntimeError("Invalid case. Should never happened")
def _transplant(self, deleting_node: Node, replacing_node: Optional[Node]) -> None:
if deleting_node.parent is None:
self.root = replacing_node
if self.root:
self.root.left_thread = False
self.root.right_thread = False
elif deleting_node == deleting_node.parent.left:
deleting_node.parent.left = replacing_node
if replacing_node:
if deleting_node.left_thread:
if replacing_node.left_thread:
replacing_node.left = deleting_node.left
if deleting_node.right_thread:
if replacing_node.right_thread:
replacing_node.right = replacing_node.right
else:
deleting_node.parent.left = deleting_node.left
deleting_node.parent.left_thread = True
else:
deleting_node.parent.right = replacing_node
if replacing_node:
if deleting_node.left_thread:
if replacing_node.left_thread:
replacing_node.left = deleting_node.left
if deleting_node.right_thread:
if replacing_node.right_thread:
replacing_node.right = replacing_node.right
else:
deleting_node.parent.right = deleting_node.right
deleting_node.parent.right_thread = True
if replacing_node:
replacing_node.parent = deleting_node.parent
Get the Height
To calculate the tree height of a double-threaded binary tree, we can recursively increment the height by one for each child's height as we did in the binary search tree. If a node has two children, we use the max function to get the bigger height from the children and increase the highest by one. The main difference is that we use left_thread and right_thread to check if a node has a child or not.
@staticmethod
def get_height(node: Optional[Node]) -> int:
if node:
if node.left_thread is False and node.right_thread is False:
return (
max(
DoubleThreadedBinaryTree.get_height(node.left),
DoubleThreadedBinaryTree.get_height(node.right),
)
+ 1
)
if node.left_thread and node.right_thread is False:
return DoubleThreadedBinaryTree.get_height(node.right) + 1
if node.right_thread and node.left_thread is False:
return DoubleThreadedBinaryTree.get_height(node.left) + 1
return 0
Get the Leftmost and Rightmost Nodes
Since double-threaded tree nodes may have left thread, right thread, or both, to get the rightmost node and the leftmost node, we need to check if right_thread and left_thread are True. The implementation of get_leftmost is the following:
@staticmethod
def get_leftmost(node: Node) -> Node:
current_node = node
while current_node.left and current_node.left_thread is False:
current_node = current_node.left
return current_node
The get_rightmost implementation is symmetric to get_leftmost.
@staticmethod
def get_rightmost(node: Node) -> Node:
current_node = node
if current_node:
while current_node.right and current_node.right_thread is False:
current_node = current_node.right
return current_node
Predecessor and Successor
The double threaded tree has both left and right threads, so it has fast in-order successor and predecessor access.
@staticmethod
def get_predecessor(node: Node) -> Optional[Node]:
if node.left_thread:
return node.left
else:
if node.left:
return DoubleThreadedBinaryTree.get_rightmost(node=node.left)
return None
The get_successor is symmetric to get_predecessor.
@staticmethod
def get_successor(node: Node) -> Optional[Node]:
if node.right_thread:
return node.right
else:
if node.right:
return DoubleThreadedBinaryTree.get_leftmost(node=node.right)
return None
In-Order, Pre-Order, and Reversed In-Order Traversals
The double-threaded tree has the advantage of both left and right threaded trees, so it can perform in-order, pre-order, and reverse in-order traversals without using a stack or recursive approach.
In-Order Traversal
The red arrows from the picture below demonstrate the in-order traversal in the threaded tree.
- Start from the leftmost node of the entire tree.
- If the right attribute is a thread, follow the right attribute; if the right attribute is not a thread, go to the subtree's leftmost node.
- Repeat step 2 until the right attribute is
None.
And implement the function without using auxiliary stack or recursive.
def inorder_traverse(self) -> traversal.Pairs:
if self.root:
current: Optional[Node] = self.get_leftmost(node=self.root)
while current:
yield (current.key, current.data)
if current.right_thread:
current = current.right
else:
if current.right is None:
break
current = self.get_leftmost(current.right)
Pre-Order Traversal
The following red arrows in the picture below show the threaded way pre-order traversal.
- Start from the root.
- If the left attribute is not empty, go to the left child.
- If the left attribute is empty or a thread, follow the right thread to the right.
- Repeat steps 2 and 3 until the right attribute is empty.
The pre-order traversal can be implemented as the following:
def preorder_traverse(self) -> traversal.Pairs:
current = self.root
while current:
yield (current.key, current.data)
if current.right_thread:
current = current.right.right
elif current.left_thread is False:
current = current.left
else:
break
Reverse In-Order Traversal
The red arrows from the picture below demonstrate the threaded way of reversed in-order traversal.
- Start from the rightmost node of the entire tree.
- If the left attribute is a thread, follow the thread; if the left attribute is not a thread, go to the subtree's rightmost node.
- Repeat step 2 until the left attribute is
None.
The following is the implementation:
def reverse_inorder_traverse(self) -> traversal.Pairs:
if self.root:
current: Optional[Node] = self.get_rightmost(node=self.root)
while current:
yield (current.key, current.data)
if current.left_thread:
current = current.left
else:
if current.left is None:
break
current = self.get_rightmost(current.left)
Test
As always, we should have unit tests for our code as much as possible. Here, we use the basic_tree function in conftest.py that we created in Build the Binary Search Tree to test our double-threaded binary tree. Check test_double_threaded_binary_tree.py for the complete unit test.
Analysis
Since the double-threaded tree is the combination of single-threaded binary trees, the run-time of its operations is the same as the single-threaded binary trees as well as the normal binary search tree.
And it has constant space complexity on in-order, pre-order, and reverse in-order traversals.
Example
Although the double-threaded binary tree is more complicated than the single-threaded binary trees, it could be a solution when traversals are critical, but space consumption is concerned and could be simpler for users who need access node's predecessor and successor fast. Therefore, the example we discussed in the single-threaded binary trees could be simplified as the following:
from typing import Any
from forest.binary_trees import double_threaded_binary_tree
from forest.binary_trees import traversal
class MyDatabase
def __init__(self) -> None:
self._double_bst = double_threaded_binary_tree.DoubleThreadedBinaryTree()
def _persist(self, payload: Any) -> str
return f"path_to_{payload}"
def insert_data(self, key: Any, payload: Any) -> None
path = self._persist(payload=payload)
self._double_bst.insert(key=key, data=path)
def dump(self, ascending: bool = True) -> traversal.Pairs
if ascending:
return self._double_bst.inorder_traverse()
else:
return self._double_bst.reverse_inorder_traverse()
if __name__ == "__main__":
my_database = MyDatabase()
my_database.insert_data("Adam", "adam_data")
my_database.insert_data("Bob", "bob_data")
my_database.insert_data("Peter", "peter_data")
my_database.insert_data("David", "david_data")
print("Ascending...")
for contact in my_database.dump():
print(contact)
print("\nDescending...")
for contact in my_database.dump(ascending=False):
print(contact)
(The complete example is available at double_tbst_database.py.)
The output will look like the below:
Ascending...
('Adam', 'path_to_adam_data')
('Bob', 'path_to_bob_data')
('David', 'path_to_david_data')
('Peter', 'path_to_peter_data')
Descending...
('Peter', 'path_to_peter_data')
('David', 'path_to_david_data')
('Bob', 'path_to_bob_data')
('Adam', 'path_to_adam_data')
Summary
The double-threaded tree does offer both single-threaded binary trees' benefits, but its implementation is even more complicated than single-threaded binary trees. Besides, the run-time performance does not improve significantly. However, in some cases, such as the space complexity is concerned, and the specific traversals (e.g., in-order traversal) are critical, the double-threaded binary tree could be an option.
History
- 9th April, 2021: Initial version

