Here we'll create a Keras tokenizer that will build an internal vocabulary out of the words found in the parallel corpus, use a Jupyter notebook to train and test our model, and try running our model with self-attention enabled.
Introduction
Google Translate works so well, it often seems like magic. But it’s not magic — it’s deep learning!
In this series of articles, we’ll show you how to use deep learning to create an automatic translation system. This series can be viewed as a step-by-step tutorial that helps you understand and build a neuronal machine translation.
This series assumes that you are familiar with the concepts of machine learning: model training, supervised learning, neural networks, as well as artificial neurons, layers, and backpropagation.
In the previous article, we built a deep learning-based model for automatic translation from English to Russian. In this article, we’ll train and test this model.
Training and Testing Using the LSTM Cells
We’ll start to train and test the core of our model: the LSTM cells without self-attention and word embedding. The standard Keras embedding component will provide the encoding from a set of words to vectors.
Model training includes several specific tasks:
- Tokenizing the input data (preprocessing)
- Deciding the training/self-test data ratio
- Training of the model
We'll start by preparing the input (source) data and output (target) data to have numerical, fixed-size input and output models. Until this is in place, we cannot feed sentences or words to our Keras neural network (NN) model.
We'll start by creating a Keras tokenizer that will build an internal vocabulary out of the words found in the parallel corpus. Let's wrap it in a function:
def tokenization(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
First, we must use the fit_on_texts function.
This function accepts a list of sentences as its argument, and builds a mapping from most commonly encountered words to indices. It doesn’t encode sentences but prepares a tokenizer to do so.
Then, we have to provide a way to encode our input sentences. Let's create another function to do that:
def encode_sequences(tokenizer, length, lines):
seq = tokenizer.texts_to_sequences(lines)
seq = pad_sequences(seq, maxlen=length, padding='post')
return seq
Once we have initialized the tokenizer, we’ll call the texts_to_sequences function for encoding. The following code retrieves a word from a numerical vector:
temp = []
for j in range(len(i)):
t = get_word(i[j], ru_tokenizer)
if j > 0:
if (t == get_word(i[j-1], ru_tokenizer)) or (t == None):
temp.append('')
else:
temp.append(t)
else:
if(t == None):
temp.append('')
else:
temp.append(t)
return ' '.join(temp)
Let’s use a Jupyter notebook to train and test our model. If you're running on a machine that doesn't have a GPU, you may want to run the notebook on Colab as it provides free GPU-enabled notebook instances..
Processing the first entries of our dataset will give us an exact result for the entries that fall in the training data, and an approximated transaction for other data. This lets us check that the translator is working correctly.
The table below shows the input data in English, then the ideal translation to Russian, and finally the model translation:
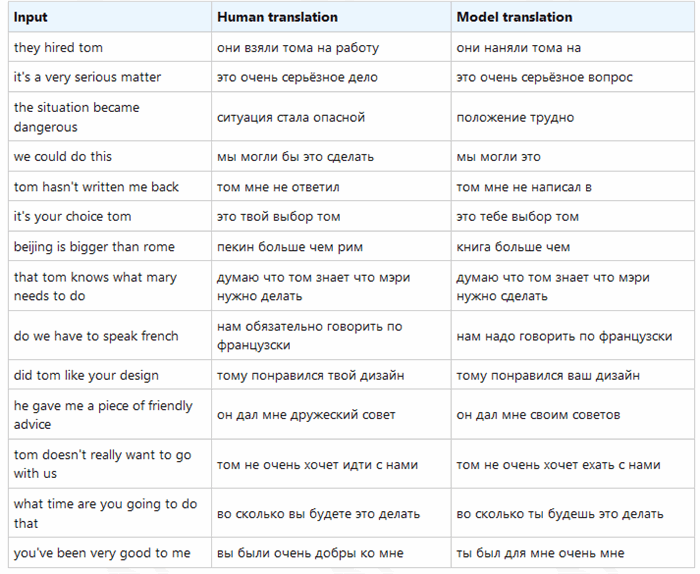
The Russian translator is surprisingly good, probably because we’ve trained the model with more than 400,000 inputs.
Of course, it’s still not as good as professional automatic translation system, which demonstrates how hard the challenge is. Some flaws became immediately apparent. For example, the sentence "you've been very good to me" is translated as, "ты был для мне очень мне" ("you were for me very me").
We can also create a reverse translation (Russian to English) by simply swapping the output and input data. Or, to experiment with other languages, we can load any other training set from the Tatoeba project.
Now With Self-Attention
Next let’s try running our model with self-attention enabled. We see mixed results. In some cases the translation is close to perfect (yellow) but in some other cases, the translation does not improve or is even inferior in quality to the translation without self-attention (grey).
Intuitively, this makes sense. Attention mechanisms can help a model focus on the importance of words within a sentence - and the longer a sentence is, the easier it is to determine which words are and are not important. A translation model that uses self-attention will often provide better results, but it won't always do so, especially on shorter inputs.

Next Steps
In the next article we’ll analyze the results our model produced and discuss the potential of a DL-based approach for universal translators. Stay tuned!

