Here we briefly explain CI/CD in the context of Machine Learning (ML).
In this series of articles, we’ll walk you through the process of applying CI/CD to AI tasks. You’ll end up with a functional pipeline that meets the requirements of level 2 in the Google MLOps Maturity Model. We’ll try to keep things simple so as not to distract you from the main goal with complex terms and steps.
We’re assuming that you have some familiarity with Python, Deep Learning, Docker, DevOps, and Flask. We’ll use Google Cloud Platform and Google Kubernetes Engine for pipeline deployment. However, you can use any other cloud provider in the same way.
The dataset we’ll use in this project is COVID-19 radiography recopilation, which is very popular at Kaggle. We won’t talk too much about the dataset or the model we’ll use because neither is especially important in the context of this article series. For more info, see this notebook, which covers the entire model creation process.
CI/CD Applied to Machine Learning
Everybody is talking about CI/CD nowadays - what is it? Continuous Integration / Continuous Delivery, a.k.a. CI/CD, is a way of introducing automation into the stages of software development. Continuous Integration makes all developers upload and merge their code changes to a central repository. Continuous Delivery means that the app release is automated. Frequently, CD absorbs another step which is Continuous Deployment and is widely used in the automation of the software development cycle.
How do all these concepts apply to Artificial Intelligence, specifically to Machine Learning (ML), its most popular subset? Well, the real challenge nowadays is not building an ML model that achieves good performance but building and operating a system that uses this model to provide predictions in production. The ML code is only the tip of the iceberg – see the picture below.
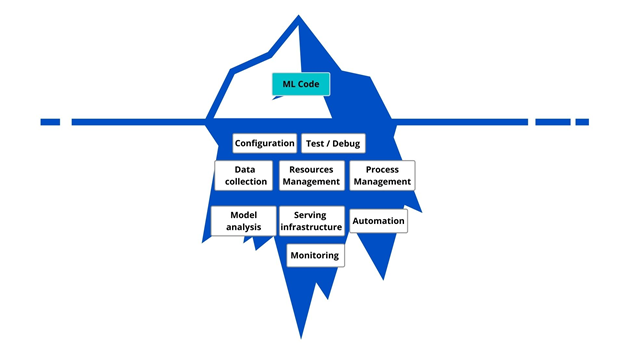
In real life, there are even more procedures involved in the process than the picture shows.
Developing and operating ML-based software is far from easy tasks, that’s why it is worth applying DevOps principles to AI systems. Compared to any other software, ML systems require an extra service from Continuous Integration: to retrain the model and incorporate it into the pipeline.
Project Schema
Here is the schema of the CI/CD pipeline we’ll work on in this project:

As you may notice, it’s composed by 3 major pipelines orchestrated by Jenkins (the default and most popular tool for CI/CD pipelines management), 6 automated tasks and the model registry (a directory for testing and another one for production):
- If Jenkins detects a push in the CodeCommit repository (which would mean that a developer modified something in the model code), it will initiate a training from scratch using the code allocated in it (Continuous Integration) and the dataset available in the Dataset repository. The training would be performed on a Docker container and at the end, if the model reaches a predefined accuracy, would be saved in the model testing registry (Continuous Delivery). This unit will be tested in a clone of the production environment using the code allocated in the UnitTesting and if all stages are passed, the success will be notified to the product owner via email which will need to execute the Semi-automated production deployment (Continuous Deployment), which is a script that copies the model from the testing directory to the production one and initiates the prediction service (Model API).
- If Jenkins detects a push in the Dataset repository (meaning that more data has been gathered), the pipeline would check if a model exists already in the production registry. If it does, Jenkins would initiate the retraining of this model (Continuous Training) and would save it in the model testing directory (Continuous Delivery). If no model is detected in the production directory then the one available in the testing directory would be retrained. To do this, Jenkins would take the retraining code allocated at the DataCommit repository and the dataset at the Dataset one. Next, the unit testing would be performed (with the code available in the UnitTesting repository) and if everything goes well, the results would be notified to the product owner via email, which will need to execute the Semi-automated production deployment workflow (Continuous Deployment).
- Finally, if any change is made in the UnitTesting repository (meaning that more tests have been added to the unit testing step), the model from the registry will be loaded and tested. If everything goes well, it will be saved again in the registry.
Next Steps
In the next article, we’ll set up the CI/CD base – GitHub, Docker, and Google Cloud Platform. Stay tuned!

