Here we develop a semi-automated deployment to production for our CI/CD MLOps pipeline.
In a previous series of articles, we explained how to code the scripts to be executed in our group of Docker containers as part of a CI/CD MLOps pipeline. In this series, we’ll set up a Google Kubernetes Engine (GKE) cluster to deploy these containers.
This article series assumes that you are familiar with Deep Learning, DevOps, Jenkins and Kubernetes basics.
In the previous article of this series, we built four automated Jenkins workflows. In this article – the last one in the series – we’ll develop a semi-automated deployment to production for our CI/CD MLOps pipeline. It’s semi-automated because typically you as the product owner would want to check the unit test results before deploying to production - to avoid service failures. Deployment to production could be done manually, but automation is required to achieve the Google MLOps Maturity Model goal.
The following diagram shows where we are in our project schema.
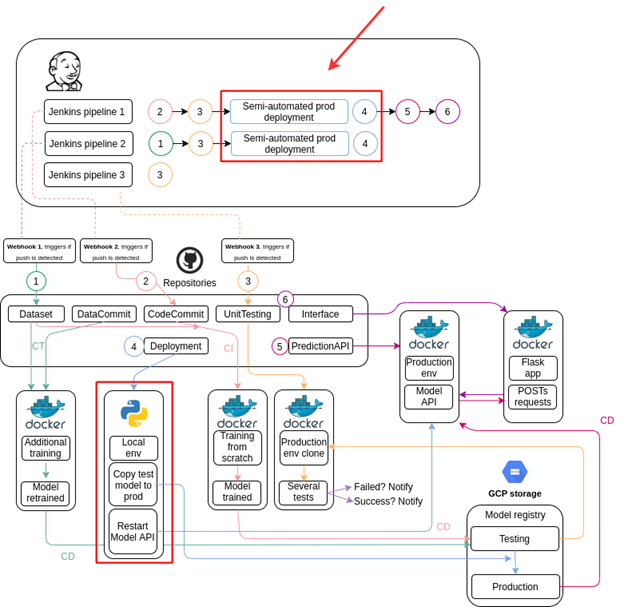
Deployment to production involves:
- Copying the model file from the GCS testing registry to the production one once the unit testing has ended
- Cleaning the completed Kubernetes jobs
- Initiating systematic shutdown of the prediction service pods (if the respective workflow has been executed already), which forces Kubernetes to initiate new ones that will load the new model with zero service downtime
Developing the Python Script
We’ve been working with Jenkins and Kubernetes to build up our CI/CD solution. The next script will show you how to interact with Jenkins and Kubernetes using Python so automate the deployment-to-production tasks. Our Python script will run locally.
Let’s dive into the code. First, we import the required libraries and define the variables:
from kubernetes import client, config
from google.cloud import storage
import jenkins
import time
import os
bucket_name = 'automatictrainingcicd-aiplatform'
model_name = 'best_model.hdf5'
Next, we declare the function that cleans the completed jobs in your cluster:
def clean_jobs():
config.load_kube_config()
api_instance=client.BatchV1Api()
print("Listing jobs:")
api_response = api_instance.list_job_for_all_namespaces()
jobs = []
print('job-name job-namespace active succeeded failed start-time completion-time')
for i in api_response.items:
jobs.append([i.metadata.name,i.metadata.namespace])
print("%s %s %s %s %s %s %s" % (i.metadata.name,i.metadata.namespace,i.status.active,i.status.succeeded,i.status.failed,i.status.start_time,i.status.completion_time))
print('Deleting jobs...')
if len(jobs) > 0:
for i in range(len(jobs)):
api_instance.delete_namespaced_job(jobs[i][0],jobs[i][1])
print("Jobs deleted.")
else:
print("No jobs found.")
return
The function that copies the model from the GCS testing registry to the production one is as follows:
def model_to_production():
storage_client = storage.Client.from_service_account_json('AutomaticTrainingCICD-68f56bfa992e.json')
bucket = storage_client.bucket(bucket_name)
status = storage.Blob(bucket=bucket, name='{}/{}'.format('testing',model_name)).exists(storage_client)
if status == True:
print('Copying model...')
source_blob = bucket.blob('{}/{}'.format('testing',model_name))
destination_blob_name = '{}/{}'.format('production',model_name)
blob_copy = bucket.copy_blob(source_blob, bucket, destination_blob_name)
print('Model from testing registry has been copied to production registry.')
else:
print('No model found at testing registry.')
return
The next function checks if the prediction service is active. If it is, the systematic pod shutdown is initiated; otherwise, the AutomaticTraining-PredictionAPI Jenkins workflow is triggered:
def check_services():
api_instance = client.CoreV1Api()
api_response = api_instance.list_service_for_all_namespaces()
print('Listing services:')
print('service-namespace service-name')
services = []
for i in api_response.items:
print("%s %s" % (i.metadata.namespace, i.metadata.name))
services.append(i.metadata.name)
if True in (t.startswith('gke-api') for t in services):
print('gke-api service is active. Proceeding to systematically shutdown its pods...')
shutdown_pods()
return
else:
jenkins_build()
return
If the prediction service is active, the following function takes charge of pod shutdown:
def shutdown_pods():
config.load_kube_config()
api_instance = client.CoreV1Api()
print("Listing pods:")
api_response = api_instance.list_pod_for_all_namespaces(watch=False)
pods = []
print('pod-ip-address pod-namespace pod-name')
for i in api_response.items:
print("%s %s %s" % (i.status.pod_ip, i.metadata.namespace, i.metadata.name))
pods.append([i.metadata.name, i.metadata.namespace])
print('Shutting down pods...')
print('Deleting only gke-api pods...')
if len(pods) > 0:
for i in range(len(pods)):
if pods[i][0].startswith('gke-api') == True:
api_instance.delete_namespaced_pod(pods[i][0],pods[i][1])
print("Pod '{}' shut down.".format(pods[i][0]))
time.sleep(120)
print("All pods have been shut down.")
else:
print("No pods found.")
return
If the prediction service is not active, the following function is triggered. It deploys the prediction service:
def jenkins_build():
print('gke-api service is not active. Proceeding to build AutomaticTraining-PredictionAPI job at Jenkins.')
server = jenkins.Jenkins('http://localhost:8080', username='your_username', password='your_password')
server.build_job('AutomaticTraining-PredictionAPI')
print('AutomaticTraining-PredictionAPI job has been triggered, check Jenkins logs for more information.')
return
Finally, the main function; it executes the entire script in the required order:
def main():
clean_jobs()
model_to_production()
check_services()
if __name__ == '__main__':
main()
Running the Script
Once you run the Python script we’ve developed file, you should get the following response:

All the old, completed jobs would have been deleted, the model copied to the production registry, and the pods successfully terminated. To double-check that you’d obtained new pods, run kubectl get pods before and after the script execution. You should see the different pod identifiers:
To see what the final product looks like (including the interface "bonus"), check this out. The interface’s public IP address is where we reach our service:
The service interface looks like this:
And finally, here is a prediction shown after you submit an image:
Conclusion
This concludes our series. We hope that you’ve enjoyed the journey, and that you will take advantage of it to gain knowledge when handling the challenging ML tasks!

