Here we discuss dedicated SQL pools and learn how to create one using Azure Synapse Studio. We also create an empty pool that we still need to populate with data.
In the first article of this series, we developed a basic understanding of Azure Synapse Analytics and took the first step toward using the service by creating a workspace. We also discussed a few top features and analytics engines that help us ingest, transform, model, and analyze our data. One of these engines, SQL pool, provides us with traditional data warehouse capabilities.
There are two types of SQL pools: dedicated and serverless. We will explore dedicated SQL pools in this article, including creating one in Azure Synapse Analytics.
To follow this tutorial, you need an active Azure subscription. If you don’t have one, you can sign up to get $200 in credits to explore all of Azure’s features for 30 days. You should also have created an Azure Synapse Analytics workspace, which you can do by following the previous tutorial.
What is a Dedicated SQL Pool?
SQL pool is a traditional data warehousing solution that stores data in a relational table format. It was previously known as Azure SQL Data Warehouse (SQL DB) and can store data at a massive scale.
Since SQL pool stores the data in columnar format, we can leverage clustered columnstore indexing for fast retrieval. Moreover, we can leverage massively parallel processing (MPP) architecture (a distributed query engine) and efficiently run queries.
Once we have our data in the dedicated SQL pool, we can use it for analysis, creating engaging dashboards, machine learning (ML), or any other data goals.
Let’s create a dedicated SQL pool.
Creating Dedicated SQL Pools
When creating dedicated SQL pools, we have two options: create them from Azure Synapse Studio or create them from the Azure portal.
The processes are simple and almost the same. However, since we will be mainly working in Synapse Studio throughout this article series, let’s jump into Synapse Studio to create our dedicated SQL pool.
Creating a Dedicated SQL Pool in Azure Synapse Studio
To start creating our dedicated SQL pool, we go to our Azure Synapse workspace and click Open Synapse Studio.
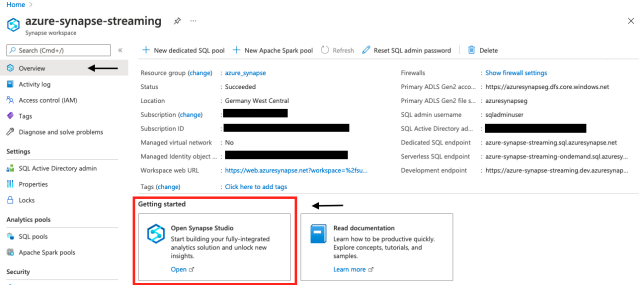
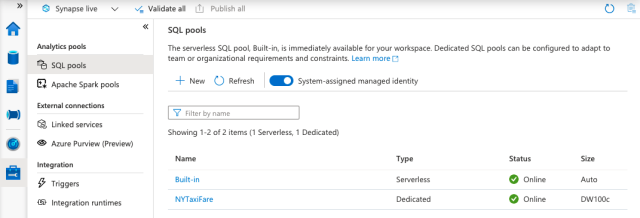
Once we are in the studio, we click Manage and select SQL Pools. Here, we will see a serverless SQL Pool already exists. We are interested in a dedicated SQL pool, though, so we can go ahead and click New.
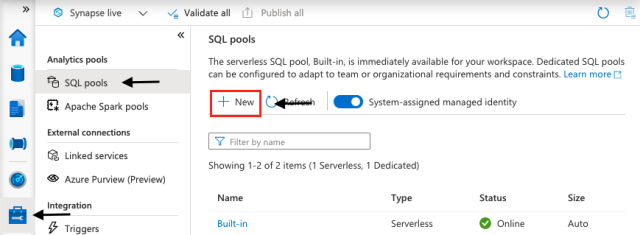
Next, we name our dedicated SQL pool (NYTaxiFare) and choose its initial settings. By default, the performance level is DW1000c. This means 1,000 data warehouse compute units, which cost us around $15.10 per hour. Here, we must make a tradeoff between the capacity based on cost budget versus performance requirements. For the sake of this article, let’s select DW100c.
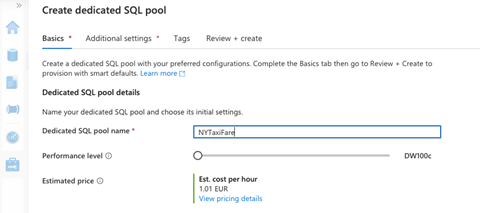
In the next step, Additional settings, we can use existing data or create an empty pool. If you have some backup data, you can use that.
We will populate our dedicated SQL pool with the streaming data later, so we’ll just create an empty pool at the moment. To do this, we choose None as the data source, then move on to Review + create to make the pool.
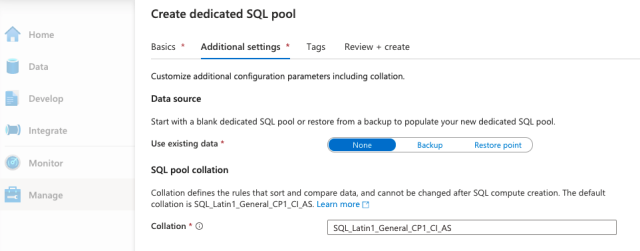
We can now play with our dedicated SQL pool.
Creating a Table
Once we have created the pool, we can use it from different tools, integrated development environments (IDEs), and applications. We can also create tables, populate data, and play with the visuals in Azure Synapse Analytics. Let’s create a table.
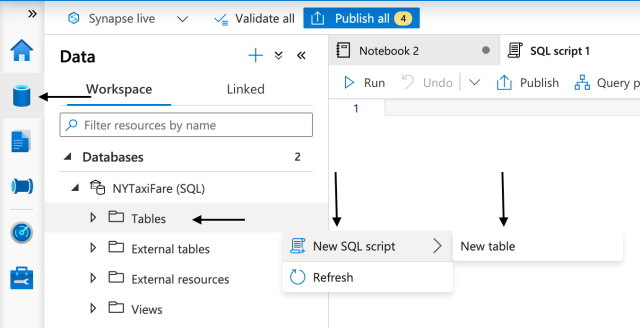
From Synapse Studio, we go to the Data tab. There, we will find our SQL pool under our workspace. We expand the pool, select New SQL script, and click New table.
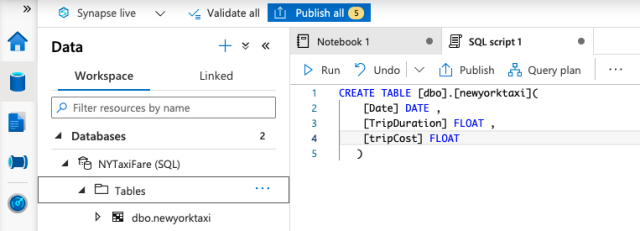
We need to edit the SQL script file as follows to create the table:
CREATE TABLE [dbo].[newyorktaxi]
(
[Date] DATE ,
[TripDuration] FLOAT ,
[tripCost] FLOAT
)
After the query executes successfully, we will see the newyorktaxi table under the Tables tab of the SQL database.
After successfully creating the table, Azure Synapse Analytics lets us insert values into the database table and test it right here by executing the simple SQL commands. However, instead, we want to set up a streaming data pipeline to populate data into the table. To achieve this goal, we will first have to set up a streaming data source, which we will learn in the following article in this series.
Next Steps
In this article, we discussed dedicated SQL pools and learned how to create one using Azure Synapse Studio. You can also make one from the Azure portal following the same procedure.
Here, we created an empty pool that we still need to populate with data. In the next article of this series, we will learn how to set up a streaming data source to populate a dedicated SQL pool. We will use it to explore New York taxi data.
Continue to the final article in this series or register to view the Hands-on Training Series for Azure Synapse Analytics.

