Here, we cover the basics of creating and using an Apache Spark Pool in the Azure Synapse Analytics environment.
In the first article of this series, we learned how Azure Synapse Analytics helps you analyze, understand, and report your big data to drive business insights. In the second article, we explored how to set up one component, an SQL pool. This third article will explore how to set up the other component, Apache Spark, and use it to analyze New York City safety data.
Apache Spark is a popular open-source system for handling big data. Big data can be large — perhaps petabytes. It can also be complex, combining several schemas and sources. It also might be a high-speed data stream. All these data types benefit from extensive parallel processing of different parts of the data in memory to minimize round trips to permanent storage. Apache Spark facilitates this by automatically scaling processing and memory to analyze large datasets efficiently.
Applications for Apache Spark include batch processing of data filtering, data aggregating, and transforming data into usable datasets. It can also feed machine learning models and analysis to process vast amounts of data to create models, find trends, and predict future scenarios. It is helpful, too, for real-time data processing that quickly ingests and analyzes a stream of data. Apache Spark’s many other uses are limited only by your imagination.
You initialize the Apache Spark system with execution resources. When you submit your program, it divides the work into tasks scheduled on executors and managed by a cluster manager. The cluster manager can spin resources up and down within your set constraints.
Apache Spark supports many languages, including Scala, Python, Java, SQL, R, .NET, C#, and F#. APIs for the various languages support more control over your programs. Apache Spark in Azure continues to mature, making it easy to set up and run a Spark cluster.
Although we give simple examples here, they introduce you to the steps to set up Apache Spark on Azure. Note that if you run a heavy load on Apache Spark, the resources and hence charges may run up quickly.
We use Python notebooks, which make data exploration and experimentation even more interactive. Notebooks are available for a variety of languages and environments.
Register an Azure Account
You need to sign up for an Azure account if you do not already have one. The free Azure account provides access to all free services plus a $200 credit to explore Azure’s other features for 30 days.
Create a Synapse Workspace
To follow this tutorial, you can create a new Synapse workspace or use an existing one, such as the one you created while following the previous tutorial.
To create a Synapse workspace, search for "synapse" on the Azure portal, and select "Azure Synapse Analytics."

On the Azure Synapse Analytics screen, click Create Synapse Workspace or + New. You will now see the first page for creating a Synapse workspace. The Synapse workspace will be the focal point of your data and analysis.
We cover creating an Azure Synapse Analytics workspace in more detail in part two of this series. For this exercise, use all the defaults to create the workspace.
Set Up Apache Spark Pool
Now that your Azure account and Azure Synapse Analytics workspace are available, you can create an Apache Spark pool. The pool preconfigures the resources needed for the Spark cluster. On the "Manage" tab of your Synapse workspace, under "Analytics pools," click Apache Spark pools. To create a new pool, click + New.
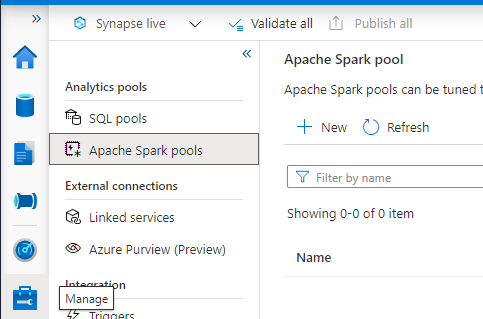
Name the Apache Spark pool. This name must be unique within the Synapse workspace.
For this tutorial, we select the smallest size and configuration cluster possible: node size small. Ensure Autoscale is enabled and use the slider on the number of nodes so minimum and maximum are at 3.
Now is an excellent time to review the pricing above minimum settings. Pricing may vary by hosting type, activity, and other factors.
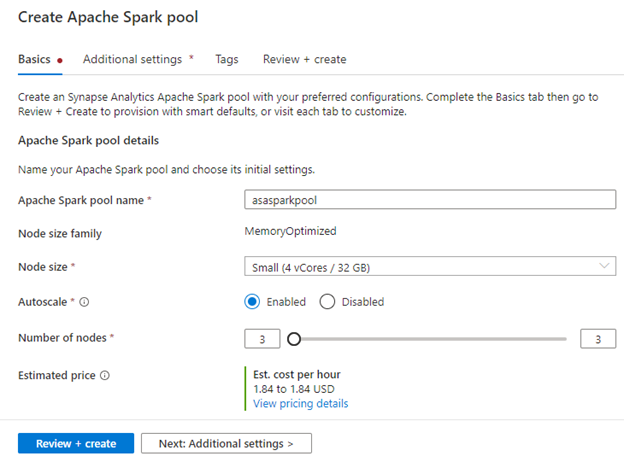
Click Next: Additional Settings to continue.
Although we use the default values on the Additional settings page, we'll point out a few settings.
Automatic pausing is set to 15 minutes by default. This pauses the cluster while specific resources are released and minimizes the Spark cluster’s cost.
You may be able to select your Spark pool’s version. The default is 2.4, but you can use version 3.0. This is in preview. You can also review the various language package versions.
Also, you can upload a configuration file to specify additional settings for your Spark jobs.
Finally, you can pre-load pool or session-level packages. For example, Python comes with many built-in libraries, but you may want custom or third-party packages available for your jobs.
Although the default setting is disabled, you can enable this if you need this feature for a particular session. You can also use a requirements document to pre-load other packages and make them available to the entire pool.
Click Next: Tags to continue.
Tags are available on most Azure resources and enable searches for related resources in different resource groups. You do not need to pick any settings here. Click Next: Review + create to continue.
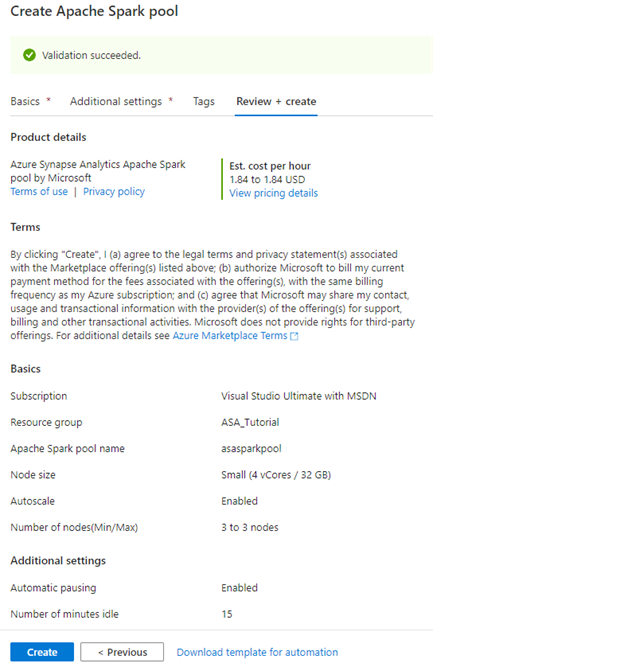
Review the basic settings and click Create to continue. It takes a few minutes to provision your pool. Next, you will start using it.
Apache Spark has built-in SQL support, but we will use a Python notebook for this example. Data scientists and others commonly use notebooks to explore and experiment with data. They provide an easy-to-use interactive interface to create and run code.
We use a Notebook with the Python language enabled.
In the Synapse workspace Develop tab, click + and select Notebook.
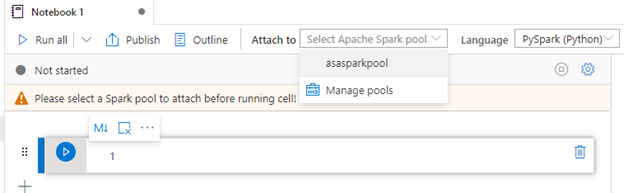
Select your Spark pool and preferred language. We use Python in this example, but you can also choose Scala, C#, and Spark SQL.
Notebooks consist of cells such as markdown (for comments and documentation), raw, and header. We use code cells. In most cases, you can execute one cell. The results (variables, sessions, and more) are then available in subsequent cells.
For this tutorial, select your Apache Spark pool (asasparkpool) and the Python language.
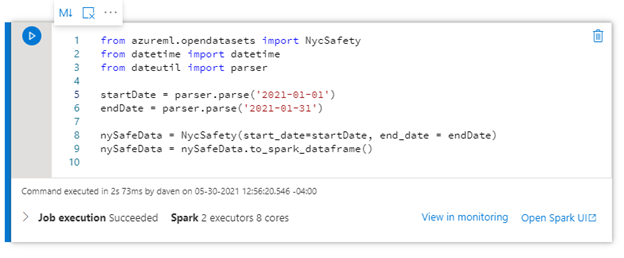
For this example, we use the New York City Safety data from Azure Open Datasets. A preview of Azure open datasets enables us to reference the New York City Safety data directly. Use this script to establish a connection.
from azureml.opendatasets import NycSafety

Execute the cell. It should run without error. Now we have a handle for the New York City Safety data.
Next, we want to look at a date range of data. We will need a couple of Python packages to set a date range for our query. This sets us up for further queries in the notebook.
The following Python code will accomplish this:
from azureml.opendatasets import NycSafety
from datetime import datetime
from dateutil import parser
startDate = parser.parse('2021-01-01')
endDate = parser.parse('2021-01-31')
nySafeData = NycSafety(start_date=startDate, end_date = endDate)
nySafeData = nySafeData.to_spark_dataframe()
We can create another cell in the notebook to display 100 rows of data in the specified date range.
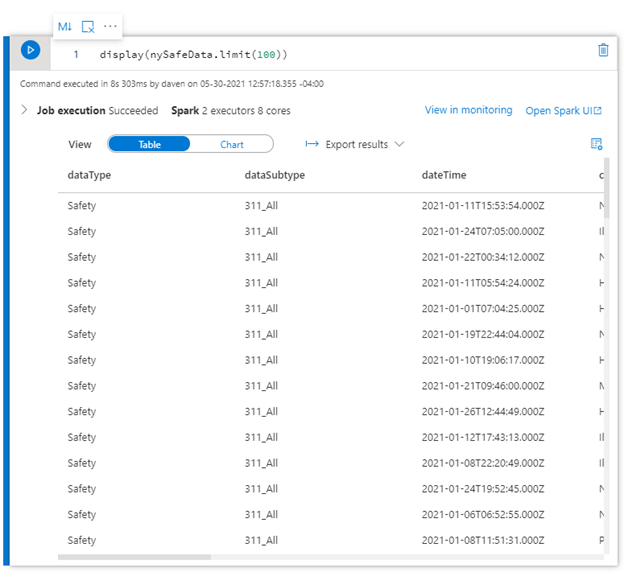
Another simple query counts the records. We do not need the display as there is no table data.
Many Spark data frame commands and extensive libraries for statistics, machine learning, and visualization provide unlimited opportunities to explore data and extract business analytics.
Here is another command to count the data rows:
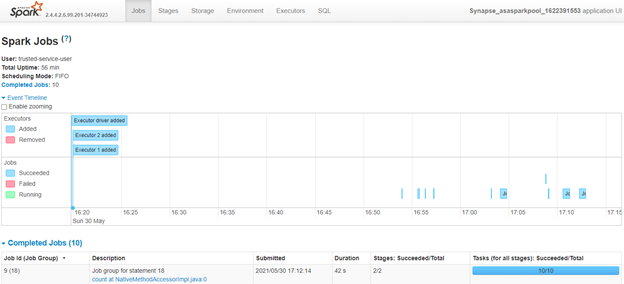
You can also bring up the Apache Spark user interface (UI) to view how Spark schedules and executes the executions.
Summary
Here, we covered the basics of creating and using an Apache Spark Pool in the Azure Synapse Analytics environment. In previous articles, we explored how to create an SQL pool after examining the benefits of using Azure Synapse to analyze, understand, and report your data. We looked at the New York City Safety dataset as an example.
Now that you have experienced the power of these tools to handle large data sets, complex structures, and high-speed streams, you can use these techniques to analyze other Microsoft sample datasets, public datasets, or your data.
For example, you can analyze your data pool to gain business insights, such as items customers usually purchase together, to help drive sales.
For more information about how to use these integrated data tools to drive business intelligence and machine learning, check out the Hands-on Training Series for Azure Synapse Analytics. You can start your first Synapse workspace, build code-free ETL pipelines, natively connect to Power BI, connect and process streaming data, and use serverless and dedicated query options.

