In the first article of this series, we learned our fictional CEO wants to improve efficiency by knowing when and where the next taxi pickup will take place — and its destination. We then discussed how to tackle this challenge.
Here, we’ll build a machine learning model in Azure Synapse Analytics to answer these questions. Based on that information, we’ll create a deployment schedule so the company deploys vehicles ahead of time to where the need will be most significant.
Getting Our Data into Azure
To follow along with this tutorial, you’ll need a Microsoft Azure account. You can use your $200 in free credits to explore the services we use in this article series.
To start, we need to migrate our SQL schema from a local SQL Server to an Azure SQL instance in our serverless pool. For this, we use Azure Synapse Pathway (in preview at the time of writing) to convert our data warehouse schema and data to an Azure-optimized format offline.
We export our schema scripts using SQL Server Management Studio (SSMS). When we fire up Azure Synapse Pathway, we locate the files and select an output directory. We can convert from Netezza and Snowflake, too.
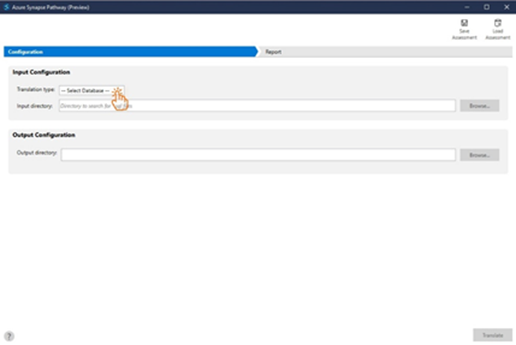
One benefit of Azure Synapse Pathway is the report output that displays problems it encounters in the translation process. It also shows approximately how many work hours we save by using the application.
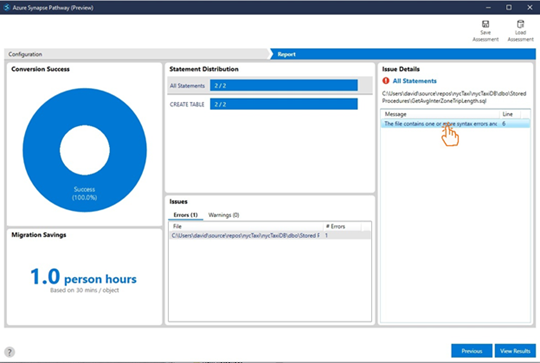
When we click on the error message, it gives a better explanation:
Once we correct the errors, we can execute these scripts on the Azure SQL serverless database.
For this tutorial, we convert the SQL data to Parquet format using a notebook. The example inverts and uploads the trip data. We can also import Azure open datasets, such as New York Yellow Cab trips, in this script.
First, we open Azure Data Studio and connect to our SQL Server. Open the notebook from the link above and select the Python 3 kernel. Azure Data Studio may install Python if necessary.
We need to import the PyArrow package to use the Apache Arrow and Parquet libraries.
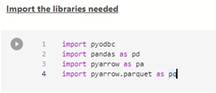
To import the PyArrow package, on the upper right-hand side, click the package manager.
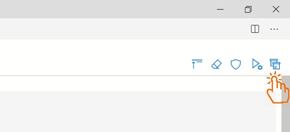
In the Add new tab, Search for "pyarrow" and click Install.
Once Azure Data Studio installs PyArrow, we make the necessary changes to our notebook. We point to our correct tables and execute the notebook to export our data in Parquet format.
Next, we log into Azure and click on Containers in our storage account. In our container, we create a new directory to house our Parquet files. We make a user folder for this.
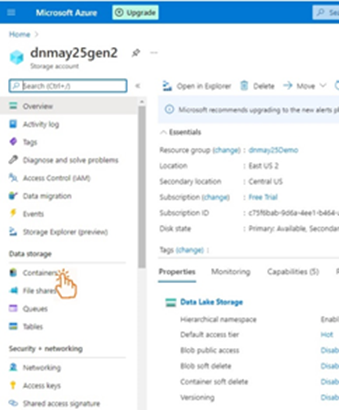
We can now upload our files from within the selected directory in Azure.
The following dialog opens for us to select our local file:
When we select a file, click Upload, and the process completes, our Parquet file is available in the directory.
We can access the data via SQL by creating an external table pointing to the Parquet data. Then, we can import the uploaded data using a script.
Creating the Demand Data
This script pulls data from a source table into the form we want in a view. This step is a little redundant, but we include it here for clarity. The next script demonstrates how to copy this data into an external table using CREATE EXTERNAL TABLE AS SELECT (CETAS). Don't underestimate CETAS’ usefulness. We can import data while formatting, aggregating, filtering, and manipulating, all in a single step.
Creating the Machine Learning Model
We are creating a quick solution for a problem requiring an answer in a hurry. We decided to use an automatic machine learning solution in Azure requiring no coding at all.
We’ll format the demand data in the form we proposed, then use an Auto ML regression model. Our first model predicts what trips customers take, and our second model determines how many of each trip will occur.
To allow for these two models, we've created two tables comprising the same trip data. The hourly route demand table lists the occurrences of trip indexes, a unique reference to a trip’s start and end zones. The hourly zone demand table allocates the number of trips from a zone into an hourly bucket.
In the first table, we target the routes column, concatenating all the trips in the relevant forecast zone and bucket. For this, we use a categorization model. The concatenated trip indexes form a category, and the rest of the columns form the input data.
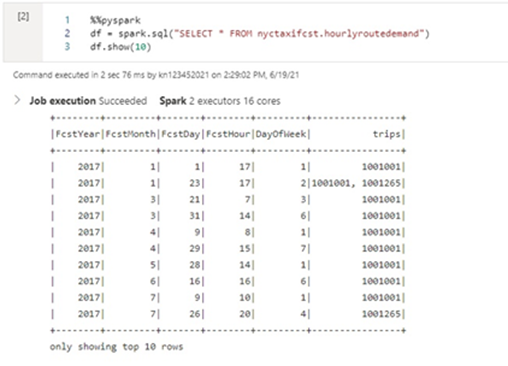
We use a regression model for the second table. We’ll forecast the number of trips that make up the demand for a forecast bucket and trip index. We remove columns that add nothing to the information in our categorization columns.
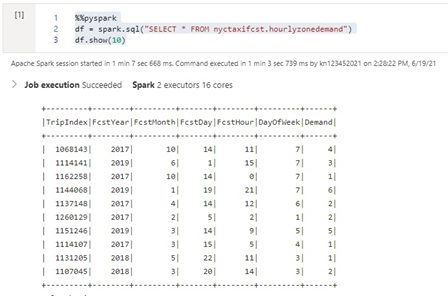
First, we need to make the demand tables available in Spark, which is simple when we enable interactive authoring in our Azure Synapse workspace integration runtime. To do this, we open a new notebook attached to our Spark pool and execute the following commands:
%%pyspark
spark.sql("CREATE TABLE IF NOT EXISTS nyctaxifcst.hourlyzonedemand USING Parquet LOCATION '/user/zonedemand'")
spark.sql("CREATE TABLE IF NOT EXISTS nyctaxifcst.hourlyroutdemand USING Parquet LOCATION '/user/routedemand'")
These commands create a table in our Spark database pointing to the same data in our SQL database.
If you’re new to Azure notebooks, you may not know about magics. When we create a notebook, we can decide which kernel to use: Python, Scala, Spark, or C#. We type our magic into the first line of our cell, in this case, %%pyspark. No matter our default kernel, our cell will use the language of the kernel the magic highlights.
We now have everything we need to submit the automatic machine learning task to Apache Spark. In the Azure Synapse Analytics Data Hub, we open up our Spark database tables and right-click on one of the demand tables. From the menu, we select Machine Learning and Enrich with new model.
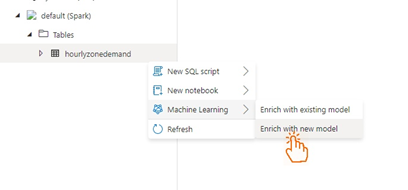
The configuration dialog opens. We only need to configure which column we are forecasting. In our case, we want to predict the demand in one of our models, and our trip index count in the other.
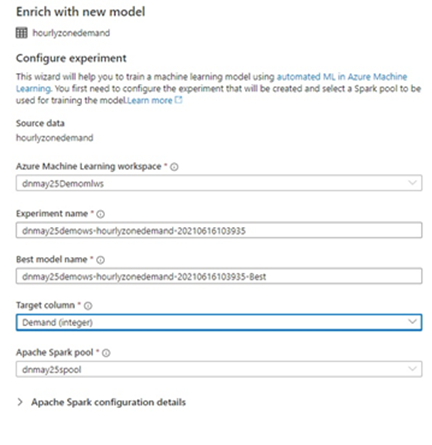
Now, we choose a model.
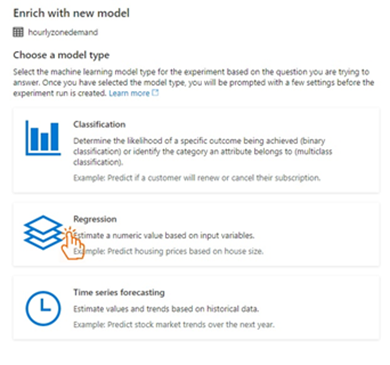
Despite this data being a time series, we choose the regression model. We don’t know precisely what the automatic ML model does. We know that our data has monthly, quarterly, and annual seasonal patterns, and we don't want our model to ignore patterns like the day of the week and hours of the day. So, we choose a regression model. A time series model might do as well or even better, but we don't have the luxury of time to experiment for our CEO’s urgent project.
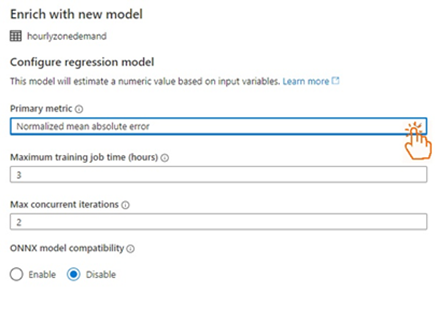
After choosing the Regression model, we set the Primary metric to Normalized mean absolute error because we found it less prone to errors. The model will run for three hours, and we don’t have time to restart with a next-day deadline.
At this point, we can submit the model or open a notebook for extra configuration (or for interest's sake). We'll submit the job and pick it up again after three hours.
Next Steps
We have rudimentarily cleaned our data using the SQL skills we have always had. We then grouped the data and presented it to the ML model, a simple process so far.
Azure Synapse Analytics has an extensive set of tools and may seem a little daunting to new users. We haven’t even touched on pipelines and data transformations. Azure Synapse Analytics pulls together many of the vast resources available in Azure in a way that makes sense to a large cross-section of the IT department.
All that remains in this project is to use our forecast and make the deployment schedule available to the CEO. Continue to the third and final article of this series to explore how to view and access model data.
To learn how Azure Synapse Analytics can help your organization make the most of your data, you can also register for Microsoft’s Hands-on Training Series for Azure Synapse Analytics.

