We discuss the various intermediate steps involved in this entire workflow along with the tools used for training and labelling.
Introduction
In a previous article, we saw how one can utilize a prebuilt model to read data from a sales receipt. In this article, we will learn to create our own ML model, train it, and then extract information from a sales receipt. Here, custom model means a model which is completely tailored to meet a specific need or a use case.
Steps Involved
To perform this end-to-end workflow, there are 4 major steps.
Step 1 - Create Training Dataset
For training a model, we need at least 5 documents of the same type, which means if we are planning to analyze receipts, then we need at least 5 samples of the sales receipts. If we are planning to extract data from a business card, then we need to have at least 5 samples of a business card, and so on and these documents can be either text or handwritten.
Step 2 - Upload Training Dataset
Once the training documents are collected, we need to upload that to Azure Storage. To perform this step, one should have Storage Account created on the Azure portal and one can upload images in the container using the below steps:
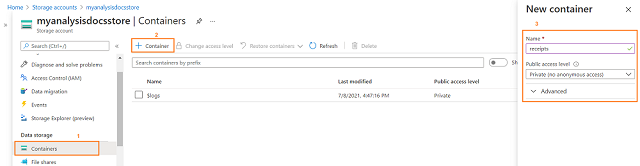
The above screenshot will guide you on how to create a container named receipts. Once the container is created successfully, documents can be uploaded to the newly created container by clicking on the Upload button as shown below:

The below screenshot depicts the five images uploaded to the container.
Once we collected the training data, we need to make a decision on whether we are going with supervised learning or unsupervised learning. In the case of supervised learning, we have to label our training data, which means along with sample training data, we should have additional files to hold information about OCR and Labels.
Step 3 - Running the OCR and Labelling the Training Dataset
For data labeling and training, I’m using Form Recognizer Sample Labeling Tool, which is available online on FOTT website.
Once the web page is opened, one needs to click on the New Project shown in the center of the screen and it will open up a new page as shown below:
Adding a New Connection
Clicking on the button Add Connection will open up a new page, wherein we need to provide SAS URI. To obtain SAS URI, we need to open the same Azure Storage resource and get the SAS generated as shown below:
Getting Form Recognizer Service URI and Key
To get the URI and Key, we need to open up the Azure Form Recognizer resource and copy the required fields as shown below:
Once the project is saved successfully, you will notice that all the blob objects are loaded on the left-hand side as shown below:
Running the OCR
Next, we need to run the OCR for all 5 documents. Doing this will mark the identified text areas in a yellow rectangle and the respective coordinates will be saved in a new file having a name ending with .ocr.JSON. These marks can be changed and rectified if required. Once this process is completed, you will notice that container is updated with new files as shown below:
Constructing the Tag List
After running the OCR, next, we need to construct the tag list and this can be done by clicking the button on the right as shown below:
This will allow us to add all the required tags as shown below:
Labeling the Dataset
When it comes to labeling, we have to perform this for all the training documents. For this, select the text on receipt and then click on the corresponding tag on the right side. On doing so, values got added to the respective tag. On completion, it would look something like this:
Before moving ahead, we need to verify whether labeling is done for all the documents and this can be done by looking at our container. If everything went well, then you will notice that new files ending with labels.json got added as shown below:
Step 4 - Training the Model
To train the model, we need to click on the Train button shown on the left side as:
On completion of the training process, the complete summary will be shown as below:
On the bottom right, you can see Average accuracy, which tells how our model behaved with the given training set. If this figure is not satisfactory, then we can add more documents to the training dataset and re-visit the labeling step.
Step 5 - Testing the Model
This is the very important step wherein we need to test our model and see how it is performing on test data. In this step, we need to write few lines of Python code, which will use our training dataset and model id to perform this testing. Here is the Python code:
import json
import time
from requests import get, post
endpoint = "FORMRECOGNIZER_ENDPOINT"
key = "FORMRECOGNIZER_KEY"
model_id = "MODEL_ID"
post_at = endpoint + "/formrecognizer/v2.0/custom/models/%s/analyze" % model_id
input_image = "IMAGE_TO_TEST"
headers = {
'Content-Type': 'image/jpeg',
'Ocp-Apim-Subscription-Key': key,
}
f = open(input_image, "rb")
try:
response = post(url = post_at, data = f.read(), headers = headers)
if response.status_code == 202:
print("POST operation successful")
else:
print("POST operation failed:\n%s" % json.dumps(response.json()))
quit()
get_url = response.headers["operation-location"]
except Exception as ex:
print("Exception details:%s" % str(ex))
quit()
response = get(url = get_url, headers = {"Ocp-Apim-Subscription-Key": key})
json_response = response.json()
if response.status_code != 200:
print("GET operation failed:\n%s" % json.dumps(json_response))
quit()
status = json_response["status"]
if status == "succeeded":
print("Operation successful: %s" % json.dumps(json_response))
quit()
if status == "failed":
print("Analysis failed:\n%s" % json.dumps(json_response))
On execution of the above code, you will see JSON output with a confidence score.
Summary
In this article, we have seen how to analyze a sales receipt with a customized ML model. To view the complete demo of htis article, you can refer my video here.
History
- 14th July, 2021: Initial version

