Here we train a no-code predictive machine learning model using AutoML. We also use these techniques to analyze home sales data.
So far in this three-part series, we discussed how Azure Synapse Analytics and Azure Machine Learning (ML) combine to help data scientists and others explore their data without previous machine learning and coding experience. First, we set up an Azure Synapse Analytics workspace, Azure Machine Learning workspace, and Azure Machine Learning linked service, then imported our house sales data into a Spark table to prepare for machine learning.
This article will pick up from where we left off and focus on Azure Machine Learning. We’ll explore how to enrich our data using a pre-trained model and trigger an Auto ML experiment from a Spark table. These actions will help us analyze our house sales data for King County, USA, for better insight into home prices in the Seattle area.
Let’s dive right in.
Training a No-Code Auto ML Model
Azure Machine Learning’s integration with Azure Synapse Analytics helps us seamlessly train a model from within Synapse Studio directly using data from a Spark table. We can use the entire chunk of data or pre-process the data before training the model. Since we had loaded a massive dataset in the previous article, we’ll reduce its dimensions before feeding it to our ML model to save time and resources.
Say we’re only interested in a few columns of data, for example, bedrooms, bathrooms, floors, waterfront, view, condition, and year built (yr_built) to predict the price of the house. We use the code below to select only these columns and change their data types from string to appropriate types.
from pyspark.sql.functions import *
df_reduced=df.select(col("price").cast("double"),col("bedrooms").cast("int"),col("bathrooms").cast("int"),col("floors").cast("int"), col("waterfront").cast("int"), col("view").cast("int"), col("condition").cast("int"))
Again, we can use the display function to view the data going into our model.
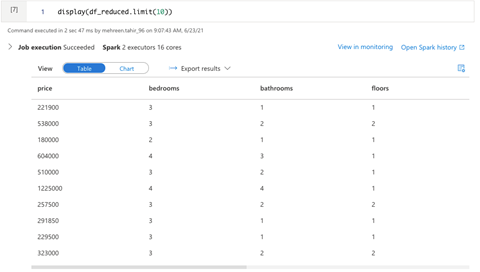
Let’s check the schema to confirm our dataset is now in the correct shape:
df_reduced.printSchema()

Last, but not least, we save the above reduced dataset into a Spark table:
df_reduced.write.mode("overwrite").saveAsTable("default.kchousereduce")
Training the AutoML Model Using Data from a Spark Table
To trigger the AutoML model training, we first select the Spark table and click … to activate the menu.
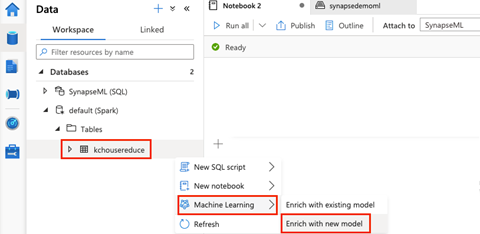
We next navigate to Machine Learning and choose Enrich with new model.
Enrich with new model enables us to configure our Azure Machine Learning experiment. We’ll find almost all the fields already populated. We leave them unchanged and work with the default settings. However, we do need to specify the Target column. We select the feature we’re trying to predict, for example, price.
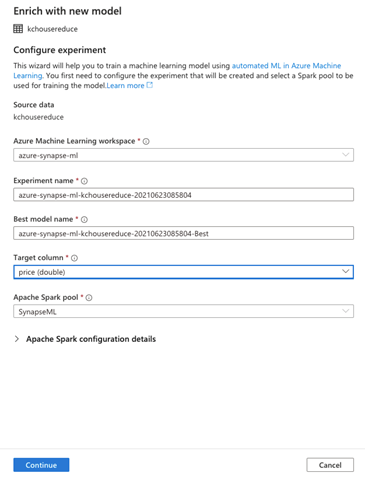
We can also configure Apache Spark’s details. We expand Apache Spark configuration details and choose the Executors (2) and Executor size (Small).
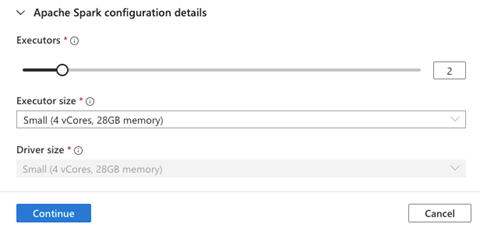
After we set those details, we click Continue.
Next, we need to Choose a model type. Since we’re trying to predict a continuous numerical value, we’ll choose Regression and then click Continue.
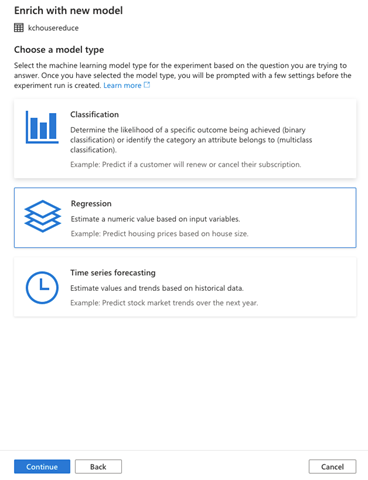
The Configure regression model page enables us to provide and configure the model parameters that best suit our use case. Here, we choose our Primary metric to be Spearman correlation, Normalized root mean squared error, R2 score, or Normalized mean absolute error. Here, we select Spearman correlation.
We can also specify the Maximum training job time, Max concurrent iterations, and ONNX model compatibility. For the sake of this demo, we’ll reduce the Maximum training job time to 0.5 hours and also enable ONNX model compatibility since Synapse Studio currently only supports ONNX models.
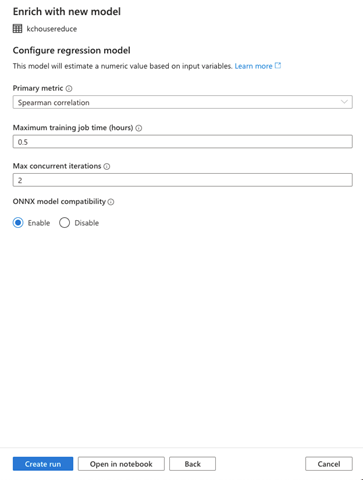
Before we start the training, note that Synapse Studio also lets you open the Auto ML integrated experiment in your notebook. So, for example, if you click Open in notebook as visible in the above image, Synapse Studio opens the experiment, with the details we specified, in the notebook.
For reference, here’s how our experiment will look in the notebook:
automl_config = AutoMLConfig(spark_context = sc,
task = "regression",
training_data = dataset,
label_column_name = "price",
primary_metric = "spearman_correlation",
experiment_timeout_hours = 0.5,
max_concurrent_iterations = 2,
enable_onnx_compatible_models = True)
We can either run the notebook or just go ahead and click Create run. Azure Synapse Studio now submits the AutoML run.
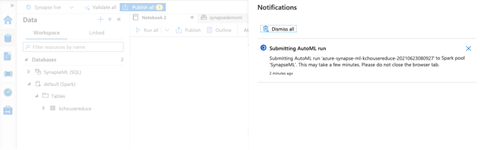
Synapse Studio alerts you when the run successfully submits. You can also view it in the Azure Machine Learning portal.
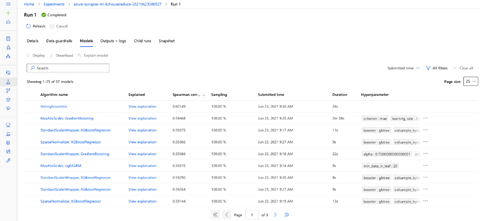
Since we’re running the AutoML experiment inside Azure Synapse Analytics, we’ll see Compute target to be local when we view it in the Azure Machine Learning portal. We can also see the details of the individual run. We go to the Models tab to view the current list of models that AutoML built during the run. The model list is in descending order, with the best listed first.
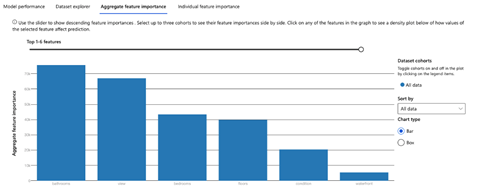
You can select any of the models and click View Explanations to open a tab containing your model’s explanation. You can also choose Aggregate feature importance to see the most influential feature from the dataset.
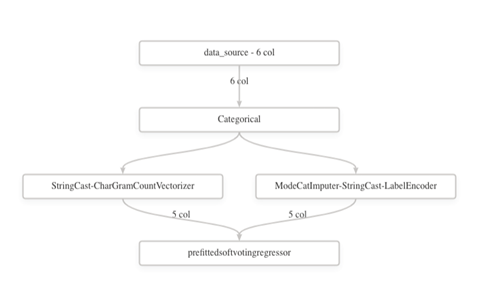
Moreover, you can view the data transformation that AutoML applied. We go to Data transformation (preview) to view the image.
Enriching Data Using a Pretrained Model
Once we have our AutoML model ready, we can use it to perform predictions, such as house prices. Let’s start by importing our test data to an SQL Pool.
Importing the Data to a Dedicated SQL Pool
We need to upload another dataset to Azure Data Lake Storage the same way we uploaded our dataset before. You can use any dataset you like, but we recommend you use this test data set we’ve created for this tutorial.
Let’s go to the Data hub in Synapse Studio and choose the Linked tab. There, we select the primary storage account and click Upload to upload the dataset.

We choose the dataset and finish the upload.
Our next step is to copy this data to our dedicated SQL pool. First, let’s create a corresponding table in our SQL pool where we can load our data.
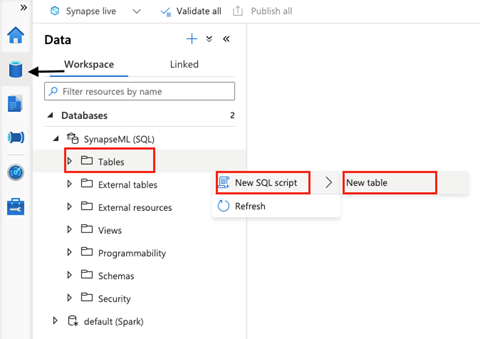
From Synapse Studio, we navigate to the Data hub and, in Databases, expand SynapseML (SQL). To create a new table, we choose New SQL script from the Tables action menu (…) and click New table.
Synapse Studio now launches a new script file. We replace the contents of the file with the following code:
CREATE TABLE [dbo].[PricePrediction]
(
[bedrooms] [int] ,
[bathrooms] [int] ,
[floors] [int] ,
[waterfront] [int] ,
[view] [int] ,
[condition] [int] ,
[price] [bigint]
)
When the query is successful, we’ll move on to copying the data from Azure Data Lake to the SQL table. To do this, we navigate to the Integrate hub, click +, then click Copy Data tool to launch the copying pipeline wizard.
Next, we follow the user interface (UI) guidelines and provide configurations for copying the pipeline.
We select the underlying storage as the source Connection and choose the test_pricing file that we uploaded earlier.
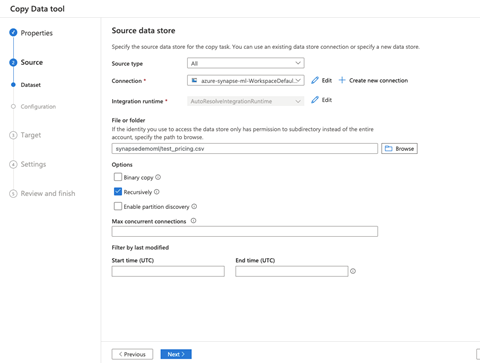
We now review the configurations for our source dataset. You can also click Preview data to verify you have the correct data.
Next, we choose Target. We’ll copy data to our previously-created SQL table.
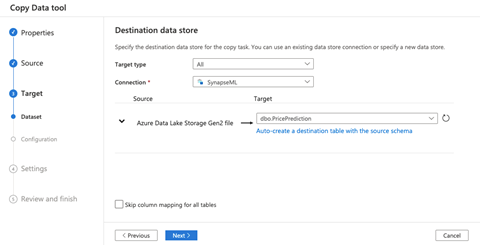
We carefully review the column mapping since this is a crucial step. If our column does not map correctly, our copy data pipeline will fail. Once we verified everything looks fine, we click Next.
On the Settings page, we just need to provide a name for our task. For example, "CopyDataToSQLTable."
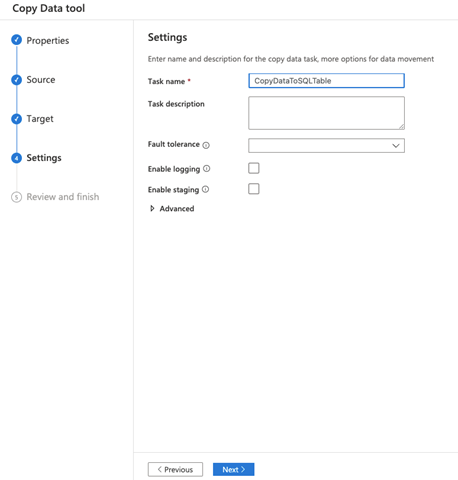
Finally, we review and finish configuring the copy data pipeline.
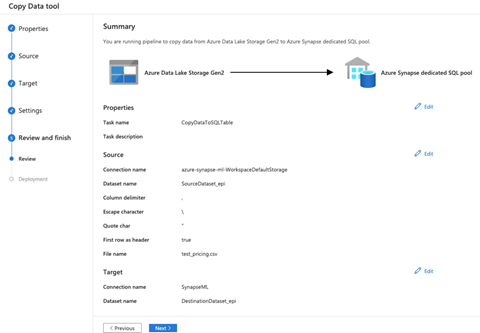
We now deploy the pipeline. When the deployment is successful, we are ready to finish up and run the pipeline. To do this, we click Finish.
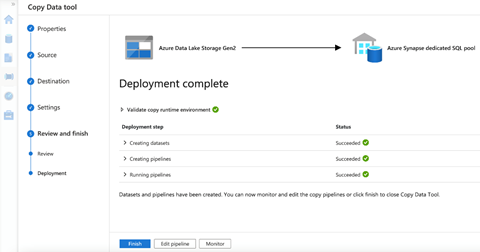
When the pipeline runs successfully, the data loads into the respective table.
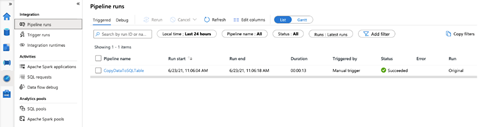
We can verify that our data is successfully copied by querying the table as follows:
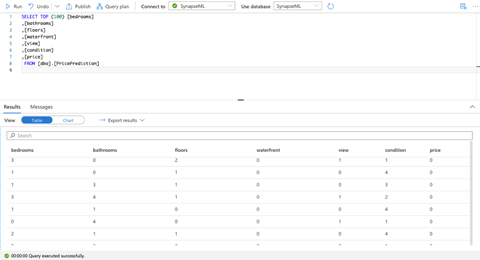
Enrich Data from an SQL Pool Using a Pre-trained Model
Next, we’ll use the prediction model that we trained to enrich the data from the SQL table we just created.
First, we move to the Data hub and expand the SQL pool table’s action menu (…).
We choose Machine Learning from the menu, then Enrich with existing model.
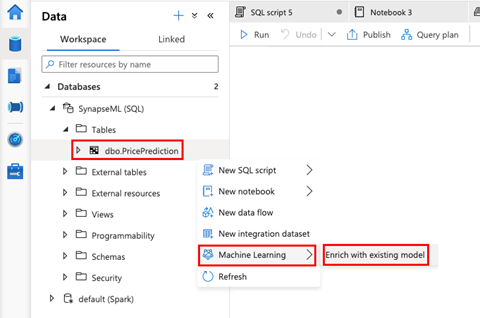
The Enrich with existing model dialogue shows you the models we trained in Azure Machine Learning. However, it only lists the models that are ONNX compatible.
We choose the desired model from the list and click Continue.
We’ll see column mappings on the next page. The columns are already mapped, so we verify and click Continue.
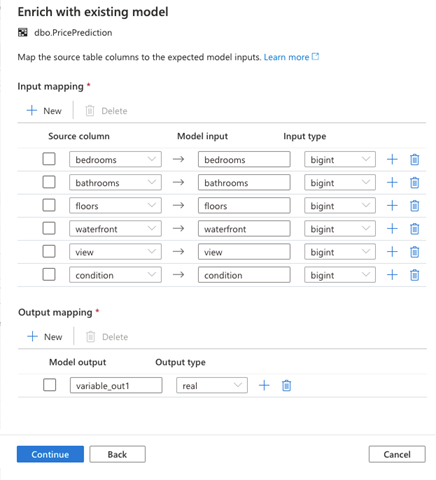
On the next page, we need to name the procedure. Synapse Studio creates the procedure when we run the script.
We also need to choose the Target table for our enriched data. We can either choose an existing table or Create new. Here, we select a new table, so we specify the table’s name as well.
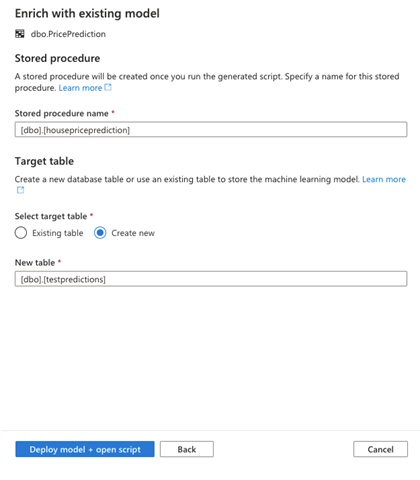
The last step of the procedure is to click Deploy model + open script. Azure Synapse Analytics sends us updates on the progress when we click the button, such as "Your model is being uploaded."
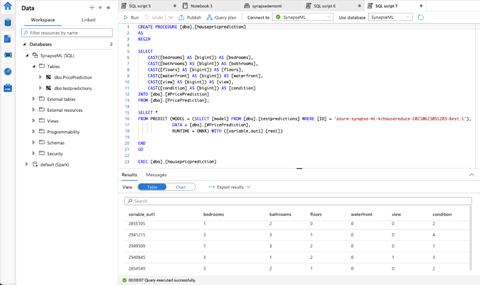
When the deployment is complete, Synapse Studio opens the script for us to review and run. We replace the contents of the script as follows:
CREATE PROCEDURE [dbo].[housepricprediction]
AS
BEGIN
SELECT
CAST([bedrooms] AS [bigint]) AS [bedrooms],
CAST([bathrooms] AS [bigint]) AS [bathrooms],
CAST([floors] AS [bigint]) AS [floors],
CAST([waterfront] AS [bigint]) AS [waterfront],
CAST([view] AS [bigint]) AS [view],
CAST([condition] AS [bigint]) AS [condition]
INTO [dbo].[#PricePrediction]
FROM [dbo].[PricePrediction];
SELECT *
FROM PREDICT (MODEL = (SELECT [model] FROM [dbo].[testpredictions] WHERE [ID] = 'azure-synapse-ml-kchousereduce-20210623051203-Best:1'),
DATA = [dbo].[#PricePrediction],
RUNTIME = ONNX) WITH ([variable_out1] [real])
END
GO
EXEC [dbo].[housepricprediction]
We now run the script to get the predicted values on the test data.
Enriching Data Using Azure Cognitive Services
Azure Synapse Analytics also integrates with other Azure and third-party services, including Azure Cognitive Services. At the moment, we can opt for sentiment analysis or anomaly detection from within Synapse Studio. Before we start, we first need to configure Azure Cognitive Services to work with Azure Synapse Analytics.
Creating a Cognitive Service Resource
Azure Cognitive Services offers many types of machine learning solutions. Here, we’ll work with anomaly detection.
First, we go to the Azure portal and search for the Anomaly Detector resource in the Marketplace. Then, we click Create to start creating an Anomaly Detector service.
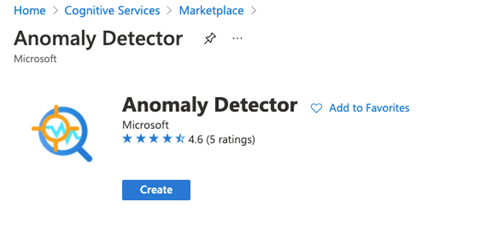
In the Create Anomaly Detector dialogue, we choose Subscription, Resource group, Pricing tier, and Name. Then, we click Next: Virtual Network.
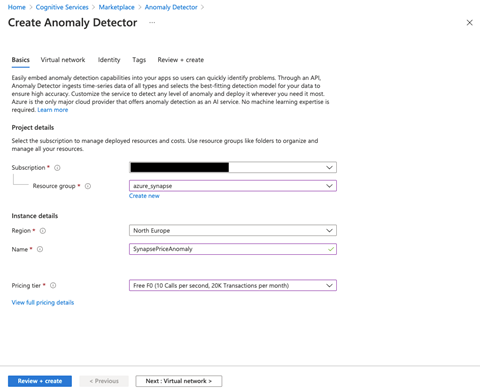
To keep it simple, we’ll allow all networks to access this resource.
We’ll keep the default settings for the rest of the tabs and move on to Review + create to deploy the resource.

Our next step is to configure the access and secrets. We click Go to resource and navigate to Keys and Endpoint. This tab contains the keys that we will use to access the Cognitive Service API. The best practice is to store them in Azure Key Vault for security.
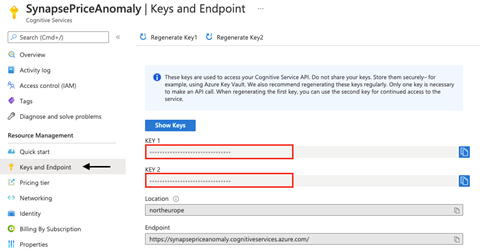
We’ll next create a Key Vault in Azure to store the access key.
Creating a Key Vault to Configure Secrets and Access
Since we don’t have Azure Key Vault Service provisioned at the moment, we’ll simply create a key vault in the Azure portal.
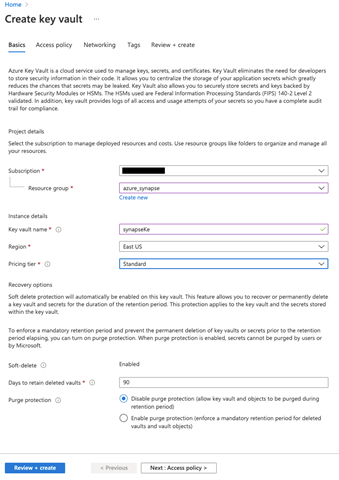
The Create key vault dialogue enables us to configure the project and instance details. Make sure to choose the subscription and resource groups that contain your Cognitive Service.
We enter a name for our key vault and choose the appropriate region and pricing tier. We leave the default settings for the remaining fields and click Next: Access policy.
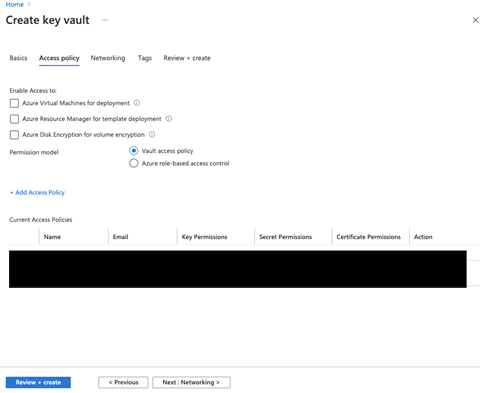
The Access policy tab lets us add and configure all the access policies. Ensure to add an access policy for your Azure Synapse workspace if you don’t have one already, and allow it to read secrets from Azure Key Vault.
Here’s how the Add Access Policy page looks:
When our access policies are in place, we move next to Networking.
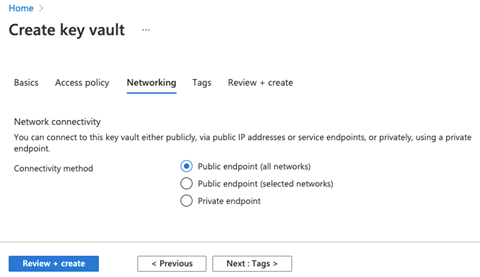
Here, we select the appropriate endpoint settings for our use case. We’ll keep the default settings for the rest of the fields and move on to Review + create.
After creating our key vault, we go to our resource and click Generate/Import under Secrets.
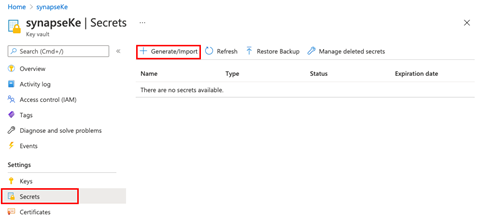
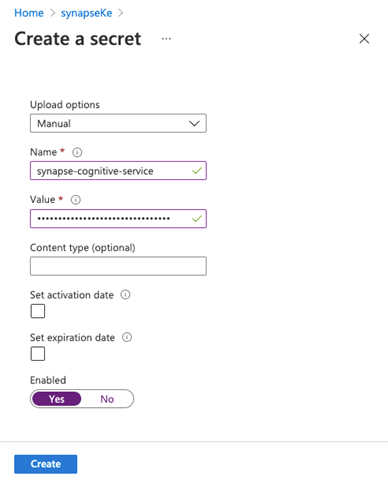
Here, we enter a name for our secret. This name is important since we’ll be using it later to connect to our Azure Synapse workspace.
The Value field contains the secret value that we want to save. First, copy either of the key values from the Anomaly Detector service and paste it in Value. Next, toggle the secret to Enabled and click Create to save the key value in your vault.
Creating an Azure Key Vault Linked Service in Azure Synapse Analytics
Our last step is to create an Azure Key Vault linked service in Azure Synapse Studio. To do this, we open our workspace in Synapse Studio, go to the Manage tab, and select Linked services. We then click New to start creating our new linked service.
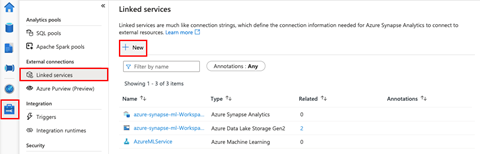
On the next page, we search for "Azure Key Vault."
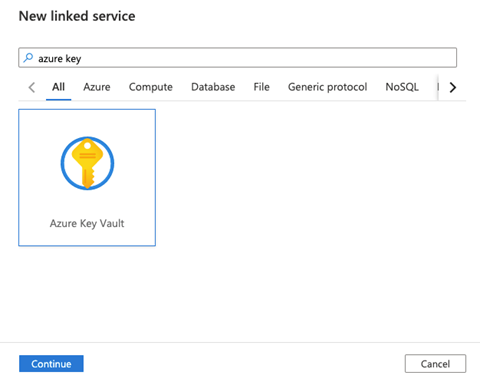
We select Azure Key Vault and click Continue.
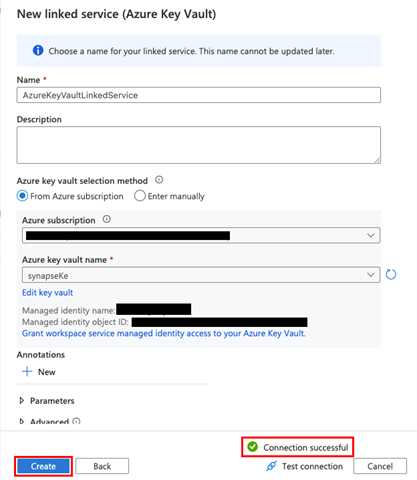
Next, we need to point our new linked service (Azure Key Vault) to the key vault we just created. We name the linked service and select our Azure subscription and Azure key vault name. We then click Test Connection to verify our link is successful. If the connection is successful, we click Create.
Now we’re ready to experiment with Azure Cognitive Services in Synapse Studio.
Setting Up Anomaly Detection with Cognitive Services
For anomaly detection, we’ll first create test data. From Azure Synapse Studio, we navigate to the Develop section, click +, and create a new Notebook.

We next enter the following code into the notebook cell and run it to create test anomaly data. Don’t forget to attach the notebook to the Spark pool.
from pyspark.sql.functions import *
df = spark.createDataFrame([
("2018-01-01T00:00:00Z", 500.0),
("2018-02-01T00:00:00Z", 200.0),
("2018-03-01T00:00:00Z", 800.0),
("2018-04-01T00:00:00Z", 900.0),
("2018-05-01T00:00:00Z", 766.0),
("2018-06-01T00:00:00Z", 805.0),
("2018-07-01T00:00:00Z", 800.0),
("2018-08-01T00:00:00Z", 20000.0),
("2018-09-01T00:00:00Z", 838.0),
("2018-10-01T00:00:00Z", 898.0),
("2018-11-01T00:00:00Z", 957.0),
("2018-12-01T00:00:00Z", 924.0),
("2019-01-01T00:00:00Z", 881.0),
("2019-02-01T00:00:00Z", 837.0),
("2019-03-01T00:00:00Z", 9000.0),
("2019-04-01T00:00:00Z", 850.0),
("2019-05-01T00:00:00Z", 821.0),
("2019-06-01T00:00:00Z", 2050.0),
("2019-07-01T00:00:00Z", 10.0),
("2019-08-01T00:00:00Z", 765.0),
("2019-09-01T00:00:00Z", 1100.0),
("2019-10-01T00:00:00Z", 942.0),
("2019-11-01T00:00:00Z", 789.0),
("2019-12-01T00:00:00Z", 865.0),
("2020-01-01T00:00:00Z", 460.0),
("2020-02-01T00:00:00Z", 780.0),
("2020-03-01T00:00:00Z", 680.0),
("2020-04-01T00:00:00Z", 970.0),
("2020-05-01T00:00:00Z", 726.0),
("2020-06-01T00:00:00Z", 859.0),
("2020-07-01T00:00:00Z", 854.0),
("2020-08-01T00:00:00Z", 6000.0),
("2020-09-01T00:00:00Z", 654.0),
("2020-10-01T00:00:00Z", 435.0),
("2020-11-01T00:00:00Z", 946.0),
("2020-12-01T00:00:00Z", 980.0),
], ["datetime", "value"]).withColumn("group", lit("group1"))
We can print the newly-created data’s schema for verification.
df.printSchema()

Let’s save this data to our Spark table.
df.write.mode("overwrite").saveAsTable("anomaly_detection_data")
After we save our data, we next move to the fun part. We’ll enrich this table using an anomaly detector Cognitive Service.
Enriching the Table
To enrich our table, we navigate to the Synapse Studio Data tab and select the table we just created. Next, we activate the action menu by clicking … and select Machine Learning, then Enrich with existing model from the menu.

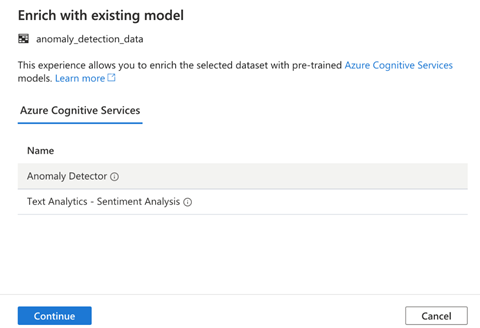
Enrich with existing model enables us to choose between two of the supported Cognitive Services. Here, we select Anomaly Detector and Continue.
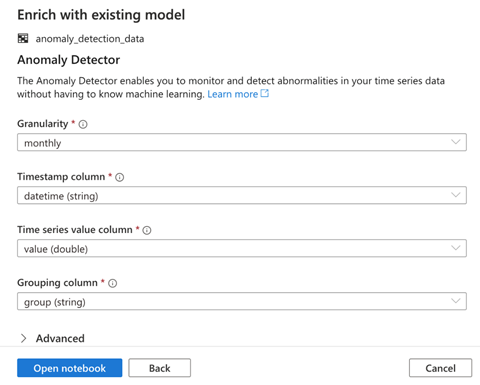
On the next page, we need to specify the model’s configurations. Granularity represents the rate at which our data was sampled. We’ll choose monthly. We then select the Timestamp column, Time series value column, and Grouping column values and click Open notebook.
We now observe the opened notebook. The notebook uses MMLSpark to connect to the Cognitive Services.
import mmlspark
if mmlspark.__spark_package_version__ < "1.0.0-rc3":
raise Exception("This notebook is not compatible with the current version of mmlspark: {}. Please upgrade to 1.0.0-rc3 or higher.".format(
mmlspark.__spark_package_version__))
Also, notice that the Azure Key Vault details we provided earlier will securely access the Cognitive Services resource. This resource will load data from our specified Spark table, run anomaly detection, then display the results.
from mmlspark.cognitive import *
from notebookutils import mssparkutils
# Fetch the subscription key (or a general Cognitive Service key) from Azure Key Vault
service_key = mssparkutils.credentials.getSecret("synapseKe", "synapse-cognitive-service", "AzureKeyVaultLinkedService")
# Load the data into a Spark DataFrame
df = spark.sql("SELECT * FROM default.anomaly_detection_data")
anomalyDetector = (SimpleDetectAnomalies()
.setLocation("northeurope")
.setSubscriptionKey(service_key)
.setOutputCol("output")
.setErrorCol("error")
.setGranularity("monthly")
.setTimestampCol("datetime")
.setValueCol("value")
.setGroupbyCol("group"))
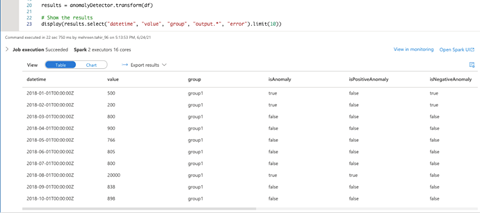
results = anomalyDetector.transform(df)
# Show the results
display(results.select("datetime", "value", "group", "output.*", "error").limit(10))
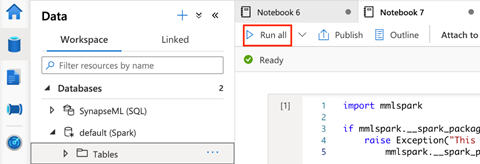
We click Run all to see the results.
Conclusion
This series of articles introduced you to Azure Synapse Analytics’ machine learning capabilities. We learned how to integrate Azure Machine Learning with Azure Synapse Analytics. We also explored enriching our data sets using pre-trained models as well as Azure Cognitive Services. Last but not least, we trained a no-code predictive machine learning model using AutoML. We used these techniques to analyze home sales data.
Azure Synapse Analytics helps data scientists and machine learning engineers to enrich data sets and train machine learning models with minimum code. This integrated service supports users of all expertise levels, enabling them to perform complex data science and machine learning tasks without worrying about the intricate underlying details.
To learn more about Azure Synapse Analytics, register to view the Hands-on Training Series for Azure Synapse Analytics, then apply these machine learning techniques to gain insight from your data. This in-depth webinar series will teach you how to get started with your first Synapse workspace, build code-free ETL pipelines, natively connect to Power BI, connect and process streaming data, use serverless and dedicated query options, and more.

