In this post, you will see a common and perfectly acceptable solution is to add a timer to debounce the input. Then you will see the logic and code for an easier debounce followed by a comparison of the two solutions.
Autocomplete (also known as “type ahead”) is a pattern used to make it easier for users to select items from a long dropdown list. As the user types, suggestions are provided. These are usually the result of filtering on the input text, but some services like search engines may also serve popular results or results based on your history. If you’re a web developer, you’ve probably implemented some form of autocompletion.
By the way, the code for this post is available in the following repository:
One issue with autocomplete is the overhead of network traffic when fetching results. In order to provide immediate feedback, you must respond to input as the user is typing. Due to network latency and query overhead, the results often arrive after the user has already modified the filter because they are typing faster than the results can be returned. Consider this input field:
Enter search text:
<input @bind-value="Text"
@bind-value:event="oninput" />
A naive or “classic” implementation of the fetch looks like this:
public string Text
{
get => text;
set
{
if (value != text)
{
text = value;
InvokeAsync(async () => await SearchAsync(text));
}
}
}
private async Task SearchAsync(string text)
{
if (!string.IsNullOrWhiteSpace(text))
{
foodItems = await Http.GetFromJsonAsync<FoodItem[]>(
$"/api/foods?text={text}");
calls++;
totalItems += foodItems.Length;
await InvokeAsync(StateHasChanged);
}
}
Chew on this Example
In this example, as the user types, the input is fetched and updated. So, what’s the concern? To test this, I created a server that does an in-memory search but introduces an artificial one-second delay before providing results. The data is from the USDA Foods Database and contains a lot of simple descriptions. Much of the text is duplicated, but that’s fine for our purposes. I just hold the identifier and description text in memory.
Here’s the controller:
[HttpGet]
public IEnumerable<FoodItem> Get([FromQuery] string text)
{
IEnumerable<FoodItem> result = Enumerable.Empty<FoodItem>();
if (text != null)
{
var safeText = text.Trim().ToLowerInvariant();
if (!string.IsNullOrWhiteSpace(safeText))
{
result = FoodItems.Where(fi => fi.Description
.Trim().ToLowerInvariant().Contains(safeText));
}
}
Thread.Sleep(1000);
return result;
}
🛑 Just so we’re on the same page: I would never, ever (ever) put a Thread.Sleep in my production server code. This is just for the demo app!
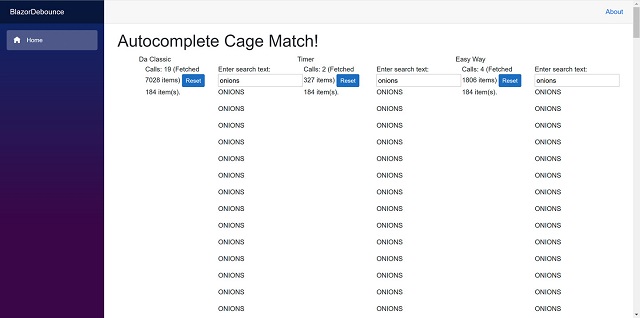
Running the program seems to work fine, but my test case produces some interesting results. If I type “oatmeal” as fast as I can, then backspace and type “onions,” the result is 19 calls and nearly 7000 database items returned. To put it in perspective, there are only 143 items matching “oatmeal” and 184 items matching “onions.” Clearly, we are over-fetching. Imagine this is happening with thousands of concurrent users! 😱
This approach can also have side effects. If you open the networking tab in your browser, you will see multiple requests running at the same time. If, for some reason, a certain request takes longer then the others, it may return out of order. Imagine how confusing it would be to type “oatmeal” then “onions” and receive the results for oatmeal!
The Perfect Time
One common and perfectly acceptable solution is to add a timer to debounce the input. The logic looks like this:
1) key press detected
2) timer running? shut it down
3) set a timer for 300 milliseconds
4) key press in under 300ms? Go back to (1)
5) timer fires and processes fetch
This is implemented in code like this:
private string Text
{
get => text;
set
{
if (value != text)
{
text = value;
DisposeTimer();
timer = new Timer(<span style="color:#40a070">300);
timer.Elapsed += TimerElapsed_TickAsync;
timer.Enabled = true;
timer.Start();
}
}
}
private async void TimerElapsed_TickAsync(
object sender,
EventArgs e)
{
DisposeTimer();
await SearchAsync(text);
}
It works quick well. You can type quickly, and only when you pause or stop will it fetch results. Using the same scenario as before, typing “oatmeal” then correcting to “onions” makes only 2 calls and fetches a total of 327 items. This is exactly the two sets of results we were looking for.
If you like the timer approach, we’re done. No need to keep reading. However, it occurred to me that there is a simpler pattern that trades off a few more calls and fetches for code that doesn’t have to keep track of, and dispose of, a timer.
An Easier Debounce
Let’s start with the logic:
1) key press detected
2) already loading a result?
3) yes - set the queued flag
4) no - reset the queued flag
5) fetch the items
6) if the queued flag is set, reset it and go to (5)
7) done
Basically, what is happening is we’re fetching as fast as the server allows. Unlike the classic example, there are no simultaneous fetches. It always fetches in order and always returns the most relevant result.
Here’s the code:
private string Text
{
get => text;
set
{
if (value != text)
{
text = value;
InvokeAsync(async () => await SearchAsync(text));
}
}
}
private async Task SearchAsync(string text)
{
if (!string.IsNullOrWhiteSpace(text))
{
if (loading)
{
queued = true;
return;
}
do
{
loading = true;
queued = false;
foodItems = await Http.GetFromJsonAsync<FoodItem[]>(
$"/api/foods?text={text}");
calls++;
totalItems += foodItems.Length;
loading = false;
}
while (queued);
await InvokeAsync(StateHasChanged);
}
}
To understand how this works, imagine me typing “oatmeal” and the following happening:
1) key press detected "o"
2) nothing queued, set start to load "o" items
3) key press detected "a"
4) items still not back, so set queued flag
5) key press detected "t"
6) items still not back, so set queued flag
7) items return, queued flag is checked so another fetch is issued
8) the fetch returns with items matching "oat"
The confusing part is seeing queued set to false then repeating based on queued being true. Remember, this is asynchronous code. While the code is waiting for a fetch, the same code might be executed for the next key press and that code sets queued back to true.
This compromise results in 4 calls that return 1806 items. We are still over-fetching, but it’s far less.
Here’s a comparison of approaches:

To make it easier for you to see for yourself, I created a little app.
The Autocomplete Cage Match
The code is at this repo:
It implements the three different autocomplete approaches. Here is the result of my test run:
You can see the code for yourself and test it out. I welcome your thoughts and feedback!

