The preceding article presented the basics of ANTLR parser generation and explained how to access the generated code in C++. This article goes further and shows how to use ANTLR to code an advanced Python parser in C++.
1 Introduction
The preceding article explained how ANTLR-generated code can be accessed in a C++ application. The grammar was trivially simple, so the generated code wasn't suitable for demonstrating ANTLR's advanced capabilities. This article generates parsing code from a Python grammar and presents an application that uses the code to analyze a Python script.
This article presents a number of advanced features related to ANTLR grammars. Then it explains how to analyze parse trees using listeners and visitors.
2 Parsing Python
You can find several grammar files on ANTLR's Github page. In the Python folder, you'll find different grammars related to the Python programming language. This article is concerned with the grammar file in the python/python3-cpp folder, Python3.g4. This is provided in this article's Python3_grammar.zip file, and you can generate code from it by entering the following command:
java -jar antlr-4.9.2-complete.jar -Dlanguage=Cpp -visitor Python3.g4
The -visitor flag is new, and it tells ANTLR to generate code for visitor classes. I'll explain what visitor classes are later in this article.
Right now, I'd like to present an overview of Python's grammar. Then I'll explain how to build this article's example application, which analyzes the parse tree of a short program using a listener and a visitor.
2.1 Fundamental Parsing Rules
Python has become immensely popular and a large part of the reason is simplicity. Python is easy to read, easy to code, and easy to debug. It's also easy to parse, which makes it ideal for advanced ANTLR development. This discussion focuses on parsing the code in the test.py file, which is presented in Listing 1.
Listing 1: test.py
letters = ["a", "b", "c"]
for letter in letters:
print(letter)
print("Done")
As the parser analyzes this text, it forms a parse tree whose nodes represent grammar rules. Figure 1 shows what the upper part of the parse tree looks like.
Figure 1: Example Python Parse Tree (Abridged)
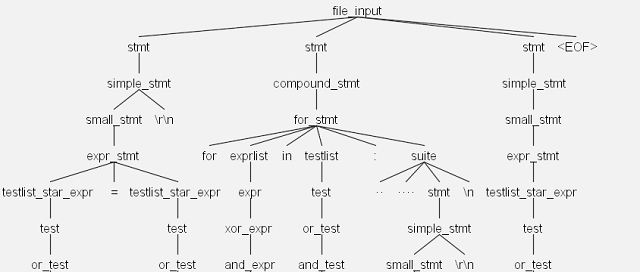
To understand the nodes of this tree, you need to be familiar with the rules of the Python grammar. An input file consists of statements and newline characters. Statements can be simple or compound, and a simple statement consists of one or more small statements followed by newline characters. Python3.g4 expresses these relationships in the following way:
file_input: (NEWLINE | stmt)* EOF;
stmt: simple_stmt | compound_stmt;
simple_stmt: small_stmt (';' small_stmt)* (';')? NEWLINE;
small_stmt: (expr_stmt | del_stmt | pass_stmt | flow_stmt |
import_stmt | global_stmt | nonlocal_stmt | assert_stmt);
The test.py code has three statements: two simple statements and one compound statement. The following discussion presents the rules for simple statements and then introduces the rules for compound statements.
2.1.1 Simple Statements
The first line of test.py is a simple statement. To be specific, it's an expression represented by the expr_stmt rule:
expr_stmt: testlist_star_expr (annassign | augassign (yield_expr|testlist) |
('=' (yield_expr|testlist_star_expr))*);
In the first line of test.py, the letters variable name and the assigned array are both identified by the testlist_star_expr rule:
testlist_star_expr: (test|star_expr) (',' (test|star_expr))* (',')?;
The test rule recognizes any general expression and is defined in the following way:
test: or_test ('if' or_test 'else' test)? | lambdef;
test_nocond: or_test | lambdef_nocond;
or_test: and_test ('or' and_test)*;
and_test: not_test ('and' not_test)*;
not_test: 'not' not_test | comparison;
comparison: expr (comp_op expr)*;
If the test node doesn't contain if, and, or, or not, it boils down to an expr. The expr rules are given as follows:
expr: xor_expr ('|' xor_expr)*;
xor_expr: and_expr ('^' and_expr)*;
and_expr: shift_expr ('&' shift_expr)*;
shift_expr: arith_expr (('<<'|'>>') arith_expr)*;
arith_expr: term (('+'|'-') term)*;
term: factor (('*'|'@'|'/'|'%'|'//') factor)*;
factor: ('+'|'-'|'~') factor | power;
power: atom_expr ('**' factor)?;
atom_expr: (AWAIT)? atom trailer*;
If the expr doesn't contain logical or mathematical operators, it boils down to an atom, which is defined with the following rule:
atom: ('(' (yield_expr|testlist_comp)? ')' |
'[' (testlist_comp)? ']' |
'{' (dictorsetmaker)? '}' |
NAME | NUMBER | STRING+ | '...' | 'None' | 'True' | 'False');
At this point, we can see how the parser will analyze the first line of test.py. The letters variable is represented by the NAME token.
NAME: ID_START ID_CONTINUE*;
In this lexer rule, ID_START is a fragment that identifies all the characters that a Python variable name can use. ID_CONTINUE identifies all the characters that can make up the rest of the name.
On the right side of the assignment, the list of three items is represented by a testlist_comp.
testlist_comp: (test|star_expr) ( comp_for | (',' (test|star_expr))* (',')? );
This indicates that a testlist_comp is essentially a comma-separated set of test nodes. We looked at the test rules earlier.
2.1.2 Compound Statements
In the test.py script, the second line of code contains a compound statement. According to the Python grammar, a compound statement can have one of nine forms:
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef |
classdef | decorated | async_stmt;
The for_stmt rule represents for loops. It's defined in the following way:
for_stmt: 'for' exprlist 'in' testlist ':' suite ('else' ':' suite)?;
The exprlist and testlist rules are both straightforward.
exprlist: (expr|star_expr) (',' (expr|star_expr))* (',')?;
testlist: test (',' test)* (',')?;
After the first line of the for loop, the following lines are represented by the suite rule:
suite: simple_stmt | NEWLINE INDENT stmt+ DEDENT;
This indicates that the for loop must be followed by a simple statement or by one or more indented/dedented statements. The INDENT and DEDENT tokens are particularly interesting, and I'll discuss them shortly.
You can look through the other compound statements in a similar way. You don't need to be an expert on Python or its grammar to follow this article, but the better you understand its grammar, the better you'll understand its parse trees.
2.2 Building the Example Project
To demonstrate Python parsing in C++, this article provides two zip files containing project code. The first zip file, Python3_vs.zip, contains project code for Visual Studio. The second, Python3_gnu.zip, contains code for GNU-based build systems.
Like the project from the preceding article, these projects access ANTLR-generated code through the main.cpp source file. Listing 2 presents its code.
Listing 2: main.cpp
int main(int argc, const char* argv[]) {
std::ifstream infile("test.py");
antlr4::ANTLRInputStream input(infile);
Python3Lexer lexer(&input);
antlr4::CommonTokenStream tokens(&lexer);
Python3Parser parser(&tokens);
Python3BaseVisitor visitor;
std::string str = visitor.visitSuite(parser.suite()).as<std::string>();
std::cout << "Visitor output: " << str << std::endl;
std::cout << "Listener output" << std::endl;
antlr4::tree::ParseTreeWalker walker;
antlr4::ParserRuleContext* fileInput = parser.file_input();
Python3BaseListener* listener = new Python3BaseListener();
walker.walk(listener, fileInput);
return 0;
}
As in the preceding article, the main function creates an ANTLRInputStream containing the input text. Then it creates a lexer (Python3Lexer) and a parser (Python3Parser). After creating the parser, the function analyzes the parse tree with a visitor (Python3BaseVisitor) and a listener (Python3BaseListener).
This article explains listeners and visitors later on. First, it's important to understand some of the advanced capabilties used in the Python3.g4 grammar file.
3 Advanced Grammar Features
The Python3.g4 grammar file is much more complex than the Expression.g4 grammar presented in the preceding article. In addition to rules and the grammar identification, it contains three new features:
- A
tokens section that identifies tokens outside of lexer rules - Code blocks following names like
@lexer::header and @lexer::members - Code blocks following rule definitions
This section looks at each of these features and explains how they're used.
3.1 The tokens Section
After the grammar identification, the Python3.g4 grammar has the following line:
tokens { INDENT, DEDENT }
This creates two tokens that don't have associated lexer rules. They don't have rules because they require special processing. This processing is defined using actions, which I'll discuss next.
3.2 Named Actions
In Python, code blocks are indicated by indentation, not punctuation. If consecutive lines have the same indentation, the interpreter assumes that they belong to the same code block. The exact number of spaces in the indentation isn't important, but every line in a block must be indented the same number of spaces.
The tokens section creates the INDENT token to represent moving text right and the DEDENT token to represent moving text left. Because of Python's special requirements, these tokens can't be defined with lexer rules. Instead, the grammar needs to provide special code that creates these tokens. This code is contained in curly braces following @lexer::members.
@lexer::members {
private:
std::vector<std::unique_ptr<antlr4::Token>> m_tokens;
std::stack<int> m_indents;
...
public:
...
}
This code takes care of processing INDENT and DEDENT tokens. It's surrounded by curly braces, so it identifies an action, and will be inserted into the ANTLR-generated code. This action follows @lexer::members, so it will be added to the lexer's properties and functions. Actions can also follow names like @lexer::header, @parser::header, and @parser::members.
If an action follows @header, it will be added to the header region of the generated lexer and parser. If an action follows @members, it will be added to the members of the generated lexer class and the generated parser class.
3.3 Anonymous Actions
Most of the actions in Python3.g4 don't follow names like @parser::header or @lexer::members. Instead, they're located inside or after rules. For example, the NEWLINE rule is given as follows:
NEWLINE: ( {atStartOfInput()}? SPACES | ( '\r'? '\n' | '\r' | '\f' ) SPACES?) { ,,, }
This rule has two actions. The first calls the lexer's atStartOfInput() function during the rule's processing. The second is given by the block of code at the end of the rule. Because the second action is at the end, it will be called after the lexer finds a valid NEWLINE token.
If an action is associated with a lexer rule, its code can access attributes of the rule's token by preceding the token's name with $ and following it with a dot and the attribute. For example, if an action is associated with a rule for the ID token, it can access the token's line with $ID.line and the token's text with $ID.text.
4 Analyzing Parse Trees
Many applications monitor the parser's analysis and perform operations when specific rules are encountered. This is called walking the parse tree. ANTLR provides two mechanisms for walking parse trees: listeners and visitors. Listeners are easier to use but visitors provide more control.
4.1 Listeners
When ANTLR generates code from a grammar, it creates two listener classes: one ending in -Listener and one ending in -BaseListener. Figure 2 illustrates the class hierarchy of the listeners generated from the Python3 grammar.
Figure 2: Listener Class Hierarchy

If you look at the header files for the Python3Listener and Python3BaseListener classes, you'll see that they both have the same set of functions: two functions for each parser rule. For example, the Python3 grammar has a rule called if_stmt, so listener classes have functions called enterIf_stmt and exitIf_stmt. The enter function is called before the rule is processed and the exit function is called after the rule has been processed.
In the Python3Listener class, the enter/exit functions are pure virtual. In the Python3BaseListener class, the functions have empty code blocks. Therefore, if you want to code your own listener class, you should make it a subclass of Python3Listener. If you only want to provide code for a few enter/exit functions, you should modify the Python3BaseListener code.
An example will clarify how this works. In this article's example code, the Python3BaseListener contains a function that's called whenever the parser enters the for_stmt rule:
void Python3BaseListener::enterFor_stmt(Python3Parser::For_stmtContext* forCtx) {
std::cout << "For statement text: " << forCtx->getText() << std::endl;
Python3Parser::ExprContext* exprCtx = forCtx->testlist()->test()[0]->or_test()[0]->
and_test()[0]->not_test()[0]->comparison()->expr()[0];
std::cout << "Expr text: " << exprCtx->getText() << std::endl;
Python3Parser::AtomContext* atomCtx = exprCtx->xor_expr()[0]->and_expr()[0]->
shift_expr()[0]->arith_expr()[0]->term()[0]->factor()[0]->power()->atom_expr()->atom();
std::cout << "Atom text: " << atomCtx->getText() << std::endl;
}
This function accesses different rule contexts associated with the for_stmt. Then it calls getText() to print the string associated with three of the rule contexts.
Once you've written your listener functions, you need to associate the listener with the parser. Creating this association requires four steps:
- Create an instance of the
antl4::tree::ParseTreeWalker class. - Obtain a pointer to the parser rule context that you want the listener to process.
- Create an instance of your listener.
- Call the
ParseTreeWalker's walk function with the listener and the parser rule context.
The following code, taken from main.cpp, shows how these four operations can be performed.
antlr4::tree::ParseTreeWalker walker;
antlr4::ParserRuleContext* fileInput = parser.file_input();
Python3BaseListener* listener = new Python3BaseListener();
walker.walk(listener, fileInput);
Listeners are easy to use and understand, but they have two limitations. First, applications can't control which nodes are processed. For example, the preceding listener code runs for every for_stmt rule, and the application can't change this. Also, listener functions always return void, so there's no easy way to transfer information to other classes and functions. To make up for these shortcomings, ANTLR provides visitors.
4.2 Visitors
By default, ANTLR doesn't generate code for visitor classes. But if the -visitor flag is added to the generation command, ANTLR will generate four additional source files. For the Python3.g4 grammar, these files are Python3Visitor.h, Python3Visitor.cpp, Python3BaseVisitor.h, and Python3BaseVisitor.cpp.
The Python3Visitor.h file declares a class called Python3Visitor and a series of pure virtual functions. The Python3BaseVisitor.h file declares a subclass of Python3Visitor called Python3BaseVisitor. This subclass has the same functions as Python3Visitor, but these functions have code. If you want to create a new visitor class, it's a good idea to code a custom subclass of Python3Visitor. If you'd rather write code for individual visitor functions, add the functions to Python3BaseVisitor.cpp.
The names of visitor functions all start with visit and end with the name of a parser rule. Each visitor function provides a pointer to the corresponding rule context. For example, the function visitSuite is called to visit the context corresponding to the grammar's suite rule. It provides a pointer to the SuiteContext for each rule processed. The following code presents the definition of visitSuite in Python3BaseVisitor.h.
virtual antlrcpp::Any visitSuite(Python3Parser::SuiteContext *ctx) override {
return visitChildren(ctx);
}
By default, every visitor function calls visitChildren to access the children of the rule context. Also, every visitor function returns an antlrcpp::Any. The Any struct is based on Boost's Any class, and it can be set equal to any value. To access the value of an Any instance, you need to call its as function with the desired data type. For example, the following code calls visitSuite and accesses its return value as a string.
std::string res = visitSuite(ctx).as<std::string>();
To understand visitor functions, it helps to look at an example. The following function in Python3BaseVisitor.cpp returns the text corresponding to the SuiteContext.
antlrcpp::Any Python3BaseVisitor::visitSuite(Python3Parser::SuiteContext* ctx) {
return ctx->getText();
}
To associate this visitor with the parser, the main function creates an instance of the visitor and calls its visitSuite function with the parser's SuiteContext. Then it casts the result to a string and prints it to standard output.
Python3BaseVisitor visitor;
std::string str = visitor.visitSuite(parser.suite()).as<std::string>();
std::cout << "Visitor output: " << str << std::endl;
This example isn't very interesting, but it demonstrates two important features of visitors. First, the application can control which rules are visited by the visitor. Second, it shows how the return value of a visitor function can be set and accessed.
History
- 1st August, 2021: Article was first submitted

