Caching algorithm that has 1-2 nanosecond average latency to each cache-hit and not-too-slow cache-miss functions to the middle layer LRU. CLOCK-second-chance algorithm is used in this middle layer cache implementation and it is fast because of not-allocating any new node during cache eviction. For multithreading & read-only access, a third synchronized LRU is used.
Cache
Everyone in hardware design and software development, is directly or indirectly using a cache. Caches are the helpful structures that combine cost-efficiency of dense memory with low-latency of fast memory.
Since there is no free lunch in information technologies, a cache has to trade off some performance and some capacity to be actually useful. That's why there is no 8GB L1 cache in desktop processors. The bigger the cache, the higher the latency. Similarly, the smaller the cache, the less cache-hit ratio which means possibly lower performance. There has to be a middle point for maximum performance & minimum cost.
Like hardware, software-side caches have their own tradeoffs. For example, to make a perfect LRU which evicts only the least recently used cache item, a developer has to use at least an std::map or std::unordered_map. This has a not-so-small amortized O(1) time complexity and eviction must be done on a linked-list (sometimes doubly-linked-list) which requires frequent allocations or several pointer assignments. These solutions add extra latency to every cache-hit and every cache-miss.
LRU Approximation
An LRU approximation algorithm is a tradeoff between cache hit rate and access latency. Generally, slightly lower hit rate is tolerable when access-latency based performance gain is much bigger than the loss. In this article, CLOCK Second-Chance version of LRU approximation is implemented and benchmarked then further optimized by adding a direct mapped cache in front of it to have single-cycle eviction item search for smaller datasets.
CLOCK Second Chance Algorithm
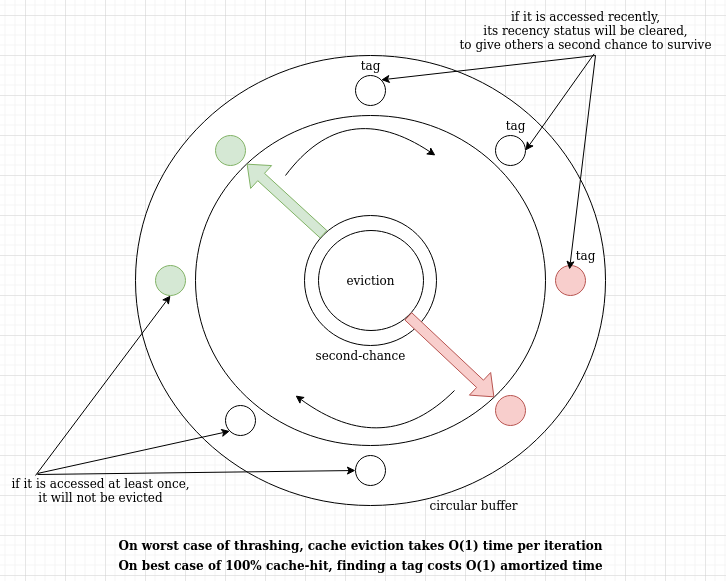
CLOCK-second-chance algorithm optimizes the node allocations (of linked-list) out by using a fixed sized buffer (circular buffer). Without allocations on each get/set call, both cache-hit and cache-miss timings are minimized but still there is a requirement of mapping which incurs some hashing computations and comparisons before reaching the data inside & outside.
There are two hands of CLOCK, one for eviction of a victim and one for giving a second-chance to another possible victim. One hand leads the other hand by 50% phase difference and both are implementable by only two integer counters (size_t type counters if number of cache-elements is more than 4 billion).
Whenever cache get set methods are called, the first thing to do is find requested key in cache. This is a single call to map's find method and comparison to its end() method. If it is found, then key/value pair is in RAM. If not found, then CLOCK algorithm's item searching procedure starts iterating on the circular buffer and checks for available items. One hand of clock simply checks any non-accessed-yet items and uses it as a victim item to evict. The other hand follows with 50% phase difference on the same buffer and gives other "unlucky" items a second chance to prove themselves to be "not least recent". This is an approximation and it does not work the same way as a complete LRU even at just 2-sized cache cases.
Implementation of CLOCK-second-chance (LruClockCache.h):
#ifndef LRUCLOCKCACHE_H_
#define LRUCLOCKCACHE_H_
#include<vector>
#include<algorithm>
#include<unordered_map>
#include<functional>
#include<mutex>
#include<unordered_map>
template< typename LruKey, typename LruValue,typename ClockHandInteger=size_t>
class LruClockCache
{
public:
LruClockCache(ClockHandInteger numElements,
const std::function<LruValue(LruKey)> & readMiss,
const std::function<void(LruKey,LruValue)> &
writeMiss):size(numElements),loadData(readMiss),saveData(writeMiss)
{
ctr = 0;
ctrEvict = numElements/2;
for(ClockHandInteger i=0;i<numElements;i++)
{
valueBuffer.push_back(LruValue());
chanceToSurviveBuffer.push_back(0);
isEditedBuffer.push_back(0);
keyBuffer.push_back(LruKey());
}
mapping.reserve(numElements);
}
inline
const LruValue get(const LruKey & key) noexcept
{
return accessClock2Hand(key,nullptr);
}
inline
const std::vector<LruValue> getMultiple(const std::vector<LruKey> & key) noexcept
{
const int n = key.size();
std::vector<LruValue> result(n);
for(int i=0;i<n;i++)
{
result[i]=accessClock2Hand(key[i],nullptr);
}
return result;
}
inline
const LruValue getThreadSafe(const LruKey & key) noexcept
{
std::lock_guard<std::mutex> lg(mut);
return accessClock2Hand(key,nullptr);
}
inline
void set(const LruKey & key, const LruValue & val) noexcept
{
accessClock2Hand(key,&val,1);
}
inline
void setThreadSafe(const LruKey & key, const LruValue & val) noexcept
{
std::lock_guard<std::mutex> lg(mut);
accessClock2Hand(key,&val,1);
}
void flush()
{
for (auto mp = mapping.cbegin();
mp != mapping.cend() ; )
{
if (isEditedBuffer[mp->second] == 1)
{
isEditedBuffer[mp->second]=0;
auto oldKey = keyBuffer[mp->second];
auto oldValue = valueBuffer[mp->second];
saveData(oldKey,oldValue);
mapping.erase(mp++); }
else
{
++mp;
}
}
}
LruValue const accessClock2Hand(const LruKey & key,const LruValue * value,
const bool opType = 0)
{
typename std::unordered_map<LruKey,ClockHandInteger>::iterator it = mapping.find(key);
if(it!=mapping.end())
{
chanceToSurviveBuffer[it->second]=1;
if(opType == 1)
{
isEditedBuffer[it->second]=1;
valueBuffer[it->second]=*value;
}
return valueBuffer[it->second];
}
else {
long long ctrFound = -1;
LruValue oldValue;
LruKey oldKey;
while(ctrFound==-1)
{
if(chanceToSurviveBuffer[ctr]>0)
{
chanceToSurviveBuffer[ctr]=0;
}
ctr++;
if(ctr>=size)
{
ctr=0;
}
if(chanceToSurviveBuffer[ctrEvict]==0)
{
ctrFound=ctrEvict;
oldValue = valueBuffer[ctrFound];
oldKey = keyBuffer[ctrFound];
}
ctrEvict++;
if(ctrEvict>=size)
{
ctrEvict=0;
}
}
if(isEditedBuffer[ctrFound] == 1)
{
if(opType==0)
{
isEditedBuffer[ctrFound]=0;
}
saveData(oldKey,oldValue);
if(opType==0)
{
const LruValue && loadedData = loadData(key);
mapping.erase(keyBuffer[ctrFound]);
valueBuffer[ctrFound]=loadedData;
chanceToSurviveBuffer[ctrFound]=0;
mapping.emplace(key,ctrFound);
keyBuffer[ctrFound]=key;
return loadedData;
}
else
{
mapping.erase(keyBuffer[ctrFound]);
valueBuffer[ctrFound]=*value;
chanceToSurviveBuffer[ctrFound]=0;
mapping.emplace(key,ctrFound);
keyBuffer[ctrFound]=key;
return *value;
}
}
else {
if(opType == 1)
{
isEditedBuffer[ctrFound]=1;
}
if(opType == 0)
{
const LruValue && loadedData = loadData(key);
mapping.erase(keyBuffer[ctrFound]);
valueBuffer[ctrFound]=loadedData;
chanceToSurviveBuffer[ctrFound]=0;
mapping.emplace(key,ctrFound);
keyBuffer[ctrFound]=key;
return loadedData;
}
else {
mapping.erase(keyBuffer[ctrFound]);
valueBuffer[ctrFound]=*value;
chanceToSurviveBuffer[ctrFound]=0;
mapping.emplace(key,ctrFound);
keyBuffer[ctrFound]=key;
return *value;
}
}
}
}
private:
ClockHandInteger size;
std::mutex mut;
std::unordered_map<LruKey,ClockHandInteger> mapping;
std::vector<LruValue> valueBuffer;
std::vector<unsigned char> chanceToSurviveBuffer;
std::vector<unsigned char> isEditedBuffer;
std::vector<LruKey> keyBuffer;
const std::function<LruValue(LruKey)> loadData;
const std::function<void(LruKey,LruValue)> saveData;
ClockHandInteger ctr;
ClockHandInteger ctrEvict;
};
#endif /* LRUCLOCKCACHE_H_ */
The core of algorithm, the eviction part, consists of a while-loop followed by a conditional eviction data-flow. The while loop only checks for eligible items for eviction and eligible items for a second chance. Since it is a circular iteration, it most probably finds an item to evict within only few iterations, same as the second chance part. Having a bigger cache even reduces the probability of number of extra iterations to evict an item.
After finding an item to evict, it checks if item was edited before. Edited status means "changed by set() method before" or in caching terms the "dirty bit". Just a single byte per item is enough to hold the necessary information. If the isEdited status is set, then it updates the backing-store or whatever the source the cache is client of. It could be writing to a database or a heavy-computation or another cache that works slower.
After conditionally updating the backing-store, it branches into get/set paths. If it is a set method call, then it updates item key+value with new one and updates mapping objects to point new key to the victim item. If it is a get method, then it does one extra operation of reading new value from backing-store. Then the new value is returned from get method.
The implementation of cache requires the user to give cache-miss functions for read-cache-miss and write-cache-miss operations, as constructor parameters. Read-miss function can be given as a lambda function and its parameter is the same type of first parameter of template and returns value in type of second parameter of template.
LruClockCache<Key,Value> cache(numberOfCacheItems,[&](Key key){
return receiveDataFromVoyager1(key);
},[&](Key key,Value value){
transmitDataToVoyager1(key,value);
});
Of course, this project is not to be used for mission-critical systems running in space. In such systems, one should opt for highest cache-hit ratio instead of access latency, preferably a dynamically evolving eviction algorithm (adaptive). This project aims to be useful in cases where both cache-misses and cache-hits are to be called millions of times per second or up to billions of times per second, like loading/storing world-chunks in a Minecraft clone.
After construction is done, it directly affects backing-store whenever it is needed, automatically like this:
WorldChunk chunk = cache.get("terrain data at 1500 35 2000");
chunk.type = WorkdChunk::Lava();
cache.set("terrain data at 1500 35 2000",chunk);
cache.flush();
Since the set call does not immediately write to backing-store, the flush() method has to be called before closing the application, if user needs latest bits of data from current session in the next game session is loaded.
cache.flush();
Apart from normal get/set methods, there are getThreadSafe and setThreadSafe methods to be used as a last-level-cache (LLC). These methods have simple lock-guards to make data transmissions synchronized between multiple threads.
Single-level cache with data coherence for multiple threads
cache.setThreadSafe("terrain data at 1500 35 2000",lava);
...
WorldChunk chunk = cache.getThreadSafe("terrain data at 1500 35 2000");
Synchronization takes a heavy toll on latency when there are many threads contending for the same resource. Best case scenario is when there is no contender on a resource. Then it gets much faster but this requires caching of the resource (here, the resource is cache already so a thread should have its own private cache too, to be less dependent on the shared cache (last-level cache), more on that later).
To test performance of the cache in a simple, readable RAII way, there is another header file (source code):
#ifndef CPUBENCHMARKER_H_
#define CPUBENCHMARKER_H_
#include <chrono>
#include <string>
#include <iostream>
#include <iomanip>
class CpuBenchmarker
{
public:
CpuBenchmarker():CpuBenchmarker(0,"",0)
{
measurementTarget=nullptr;
}
CpuBenchmarker(size_t bytesToBench):CpuBenchmarker(bytesToBench,"",0)
{
measurementTarget=nullptr;
}
CpuBenchmarker(size_t bytesToBench, std::string infoExtra):CpuBenchmarker
(bytesToBench,infoExtra,0)
{
measurementTarget=nullptr;
}
CpuBenchmarker(size_t bytesToBench, std::string infoExtra,
size_t countForThroughput):t1(std::chrono::duration_cast<
std::chrono::nanoseconds >
(std::chrono::high_resolution_clock::now().time_since_epoch()))
{
bytes=bytesToBench;
info=infoExtra;
count = countForThroughput;
measurementTarget=nullptr;
}
void addTimeWriteTarget(double * measurement)
{
measurementTarget=measurement;
}
~CpuBenchmarker()
{
std::chrono::nanoseconds t2 = std::chrono::duration_cast<
std::chrono::nanoseconds >
(std::chrono::high_resolution_clock::now().time_since_epoch());
size_t t = t2.count() - t1.count();
if(measurementTarget!=nullptr)
{
*measurementTarget=t/1000000000.0; }
if(info!=std::string(""))
std::cout<<info<<": ";
std::cout<<t<<" nanoseconds ";
if(bytes>0)
{
std::cout <<" (bandwidth = ";
std::cout << std::fixed;
std::cout << std::setprecision(2);
std::cout << (bytes/(((double)t)/1000000000.0))/1000000.0 <<" MB/s) ";
}
if(count>0)
{
std::cout<<" (throughput = ";
std::cout << std::fixed;
std::cout << std::setprecision(2);
std::cout << (((double)t)/count) <<" nanoseconds per iteration) ";
}
std::cout<<std::endl;
}
private:
std::chrono::nanoseconds t1;
size_t bytes;
size_t count;
std::string info;
double * measurementTarget;
};
#endif /* CPUBENCHMARKER_H_ */
Instance of this class simply initializes time measurement on its constructor and finalizes the measurement on the destructor. Usage is scope-based. It measures time span between its construction + destruction:
for(int i=0;i<10;i++)
{
CpuBenchmarker bench;
for(int j=0;j<100000;j++)
summation += cache.get(j);
}
then outputs the result on cout:
14292519 nanoseconds
1613470 nanoseconds
1484368 nanoseconds
1475362 nanoseconds
1476067 nanoseconds
1445494 nanoseconds
1476075 nanoseconds
1443211 nanoseconds
1444241 nanoseconds
1542156 nanoseconds
By checking the usage of benchmarker class and the performance of LRU approximation at the same time, there is ~15 nanoseconds average latency per cache.get(key) call. This is in tune with test system's processor's L2 cache latency. FX8150 at 2GHz with L2 cache of 21 clock cycles = 10.5 nanoseconds. Extra latency comes from eviction logic. Dataset was only 100000 elements (of int type) which makes 400kB data that doesn't fit L1 cache but certainly benefits from L2 which has 2MB capacity.
When the dataset is increased to get out of L3 cache:
for(int i=0;i<10;i++)
{
CpuBenchmarker bench;
for(int j=0;j<10000000;j++) summation += cache.get(j); }
the output is:
2429736836 nanoseconds
184091798 nanoseconds
183418885 nanoseconds
182178757 nanoseconds
182320176 nanoseconds
180748781 nanoseconds
181500728 nanoseconds
182763052 nanoseconds
184306739 nanoseconds
182924882 nanoseconds
which is equivalent of 18 nanoseconds average per cache.get(). This is not the actual latency but inverse-throughput of it. A modern CPU does superscalar, pipelined and out-of-order operations which hides a good portion of real latency of a code block. To have some idea about what real latency could be, the number of iterations could be decreased to just a few:
for(int i=0;i<10;i++) {
CpuBenchmarker bench;
summation += cache.get(5);
}
The result is as follows:
3700 nanoseconds
208 nanoseconds
165 nanoseconds
167 nanoseconds
167 nanoseconds
174 nanoseconds
167 nanoseconds
167 nanoseconds
166 nanoseconds
166 nanoseconds
What first one did:
- try finding key in
unordered_map and fail - try finding a victim item in cache to be evicted
- call cache-miss function given by user and do eviction
- get necessary data into
L3/L2/L1 caches of CPU from RAM (std::vector was used in tests as backing-store) - service the data from cache
- 3700 nanoseconds
What second one did:
- try finding key in
unordered_map and not fail - return data from cache item directly
- CPU branch prediction did not work good enough yet
- 208 nanoseconds
Rest of the iterations:
- try finding key in
unordered_map and not fail - return data from cache item directly
- CPU branch prediction predicted that it was another call to same item
- 165 nanoseconds
All tests above were made with big enough cache to have 100% cache-hits. To test cache-miss performance of the API, the dataset should be bigger than the cache and its access pattern should be a weak-spot of the algorithm. LRU approximation has weak spot of sequential access to big dataset:
std::vector<int> test(1000000);
for(int i=0;i<1000000;i++)
test[i]=sin(i*3.14f);
LruClockCache<int,int> cache(100,[&](int key){
return test[key];
},[&](int key, int value){
test[key]=value;
});
size_t s1=0;
for(int i=0;i<10;i++)
{
CpuBenchmarker bench;
for(int j=0;j<1000000;j++)
s1+=cache.get(j);
}
std::cout<<"======"<<s1<<std::endl;
The output is as follows:
118993415 nanoseconds
120295111 nanoseconds
120736697 nanoseconds
119908045 nanoseconds
118299823 nanoseconds
118886337 nanoseconds
119130691 nanoseconds
118587024 nanoseconds
119342589 nanoseconds
119526892 nanoseconds
======120
With cache size of 100 elements and dataset of 1M elements, hit-ratio is 0.0001%. ~119 milliseconds for 1M cache.get() calls is equivalent to 119 nanoseconds per call. This is mostly bottlenecked by RAM latency, calling lambda functions, failing the map.find() call and accessing std::vector as a second indirection. 1M elements use only 4MB while L3 cache of processor is 8MB so RAM latency is only observed with bigger datasets. When dataset size is increased by 10 times, the average latency increases from 119 nanoseconds to 120 nanoseconds and this small increase is possibly caused by failing map.find() time-complexity of O(logN). Another 10x size increase on dataset causes 125 nanoseconds latency per call instead of 119 nanoseconds on the 1/100 sized cache.
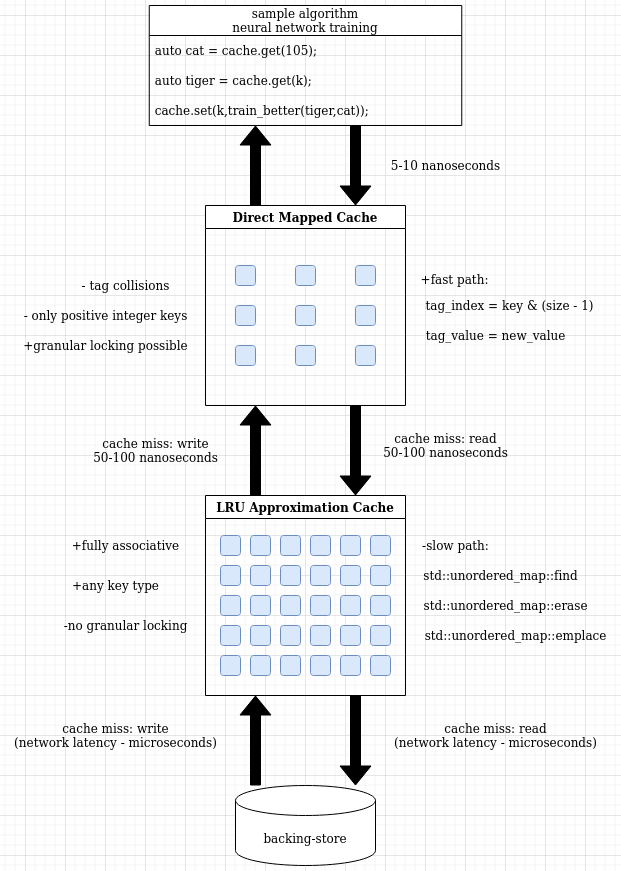
Direct Mapped Cache
To filter the input of LRU approximation cache against some corner-cases and to have an even faster access, a direct mapped cache can be added in front of the LRU approximation cache.

Direct mapped cache is a type of comparisonless cache where actual cache item to evict is derived from a simple operation directly. Easiest is modulo operator. This makes every k-th integer key to be mapped to same cache item and every (k+1)st key to same neighboring cache item and whole cache item array is mapped to whole key space, with just:
int tag = key % size;
calculation. Rest of the algorithm is the same as LRU where eviction is going on but since there is less book-keeping (without any mapping required), it also costs less bytes per cache size. Due to this reason, same sized (number of items) direct mapped cache costs less memory space than same sized (number of items) LRU cache. This further increases the chance of cache itself being contained in L1(or L2) CPU cache. Having a (circular or not) buffer is good for locality of reference and works better with CPU's cache.
There are disadvantages of direct mapped cache. One is the existence of key collisions on same cache items which reduces the cache-hit ratio and another one is being restricted to integer keys only. LRU cache works with any key type from strings to objects to integers.
Implementing a software-side direct mapped cache is straightforward (source code):
#ifndef DIRECTMAPPEDCACHE_H_
#define DIRECTMAPPEDCACHE_H_
#include<vector>
#include<functional>
#include<mutex>
#include<iostream>
template< typename CacheKey, typename CacheValue>
class DirectMappedCache
{
public:
DirectMappedCache(CacheKey numElements,
const std::function<CacheValue(CacheKey)> & readMiss,
const std::function<void(CacheKey,CacheValue)> &
writeMiss):size(numElements),sizeM1(numElements-1),
loadData(readMiss),saveData(writeMiss)
{
for(CacheKey i=0;i<numElements;i++)
{
valueBuffer.push_back(CacheValue());
isEditedBuffer.push_back(0);
keyBuffer.push_back(CacheKey());
}
}
inline
const CacheValue get(const CacheKey & key) noexcept
{
return accessDirect(key,nullptr);
}
inline
const std::vector<CacheValue> getMultiple(const std::vector<CacheKey> & key) noexcept
{
const int n = key.size();
std::vector<CacheValue> result(n);
for(int i=0;i<n;i++)
{
result[i]=accessDirect(key[i],nullptr);
}
return result;
}
inline
const CacheValue getThreadSafe(const CacheKey & key) noexcept
{
std::lock_guard<std::mutex> lg(mut);
return accessDirect(key,nullptr);
}
inline
void set(const CacheKey & key, const CacheValue & val) noexcept
{
accessDirect(key,&val,1);
}
inline
void setThreadSafe(const CacheKey & key, const CacheValue & val) noexcept
{
std::lock_guard<std::mutex> lg(mut);
accessDirect(key,&val,1);
}
void flush()
{
try
{
for (CacheKey i=0;i<size;i++)
{
if (isEditedBuffer[i] == 1)
{
isEditedBuffer[i]=0;
auto oldKey = keyBuffer[i];
auto oldValue = valueBuffer[i];
saveData(oldKey,oldValue);
}
}
}catch(std::exception &ex){ std::cout<<ex.what()<<std::endl; }
}
CacheValue const accessDirect(const CacheKey & key,const CacheValue * value,
const bool opType = 0)
{
CacheKey tag = key & sizeM1;
if(keyBuffer[tag] == key)
{
if(opType == 1)
{
isEditedBuffer[tag]=1;
valueBuffer[tag]=*value;
}
return valueBuffer[tag];
}
else {
CacheValue oldValue = valueBuffer[tag];
CacheKey oldKey = keyBuffer[tag];
if(isEditedBuffer[tag] == 1)
{
if(opType==0)
{
isEditedBuffer[tag]=0;
}
saveData(oldKey,oldValue);
if(opType==0)
{
const CacheValue && loadedData = loadData(key);
valueBuffer[tag]=loadedData;
keyBuffer[tag]=key;
return loadedData;
}
else
{
valueBuffer[tag]=*value;
keyBuffer[tag]=key;
return *value;
}
}
else {
if(opType == 1)
{
isEditedBuffer[tag]=1;
}
if(opType == 0)
{
const CacheValue && loadedData = loadData(key);
valueBuffer[tag]=loadedData;
keyBuffer[tag]=key;
return loadedData;
}
else {
valueBuffer[tag]=*value;
keyBuffer[tag]=key;
return *value;
}
}
}
}
private:
const CacheKey size;
const CacheKey sizeM1;
std::mutex mut;
std::vector<CacheValue> valueBuffer;
std::vector<unsigned char> isEditedBuffer;
std::vector<CacheKey> keyBuffer;
const std::function<CacheValue(CacheKey)> loadData;
const std::function<void(CacheKey,CacheValue)> saveData;
};
#endif /* DIRECTMAPPEDCACHE_H_ */
From outside, it works nearly same as LRU equivalent. There are get and set methods, constructor takes similar parameters and it has a flush() method too.
By doing same micro-benchmarks on this cache, the timings are better.
Cache-miss test:
std::vector<int> test(10000);
for(int i=0;i<10000;i++)
test[i]=sin(i*3.14f);
DirectMappedCache<int,int> cache(100,[&](int key)
{ return test[key]; },[&](int key, int value){ test[key]=value; });
size_t s1=0;
for(int i=0;i<10;i++)
{
CpuBenchmarker bench;
for(int j=0;j<10000;j++)
s1+=cache.get(j);
}
std::cout<<"======"<<s1<<std::endl;
The output is as below:
101048 nanoseconds
99746 nanoseconds
100138 nanoseconds
100637 nanoseconds
101137 nanoseconds
104758 nanoseconds
101301 nanoseconds
99834 nanoseconds
100759 nanoseconds
329917 nanoseconds
100k nanoseconds per 10k iterations is 10 nanoseconds per cache-miss. This is partly due to being fitted inside a closer CPU cache to the core and having much less (and possibly vectorizable) latency access to backing store. There is no victim slot search, there is no map search. Without these, the compiler is possibly vectorizing the operation and having mostly cache misses benefits from this. 10 nano seconds per miss is equivalent to 100 million cache-miss lookups per second, to the backing-store (assuming backing store can fetch data that fast). Under real-world usage, it would be nearly the same performance of the backing-store. Probably a microsecond on a local web service, 100 microseconds for reading a file, a millisecond on a lock-guard synchronization, 10 milliseconds for copying 100MB data over pcie bridge, etc.
Cache-hit test (same code with cache size = dataset size):
80869 nanoseconds
80969 nanoseconds
80617 nanoseconds
80226 nanoseconds
80709 nanoseconds
80264 nanoseconds
80806 nanoseconds
80550 nanoseconds
79972 nanoseconds
80372 nanoseconds
At only 2 nanosecond difference per call from the cache-miss latency, it behaves like a vectorized multiplexer for the backing-store input. Part of the slowness comes from loop counter incrementing of benchmarking and condition checking to stop the for-loop.
8 nanosecond per cache.get(key) operation is for sequential iteration of array with 100% cache hit ratio. Performance changes the access pattern. When CPU is 3.6GHz instead of 2.1 GHz:
51439 nanoseconds
51087 nanoseconds
51026 nanoseconds
50527 nanoseconds
50970 nanoseconds
50819 nanoseconds
50623 nanoseconds
50655 nanoseconds
50666 nanoseconds
50767 nanoseconds
50% frequency increase results in 60% performance increase. On https://www.codechef.com/ide, same code outputs this:
36424 nanoseconds
50099 nanoseconds
35613 nanoseconds
35614 nanoseconds
35615 nanoseconds
35729 nanoseconds
35604 nanoseconds
35637 nanoseconds
35671 nanoseconds
35605 nanoseconds
3.5 nanoseconds per lookup is equivalent of 285 million lookups per second, on a server that is probably already busy compiling other clients codes & running them. A modern CPU at 5GHz frequency with at least two channel memory instead of one channel (as the test machine has) should have at least 50% to 100% more lookups per second, possibly surpassing 0.5 billion lookups per second.
Multi Level Cache
When two different type caches are connected one after another (one cache being the backing-store of the other), it makes a corner-case access-pattern for one cache be optimized out by the other.
For example, direct mapped cache fails on an access pattern of key = k%cacheSize (3,10003,20003,etc for 10k cache-size) and causes cache misses on all accesses after first one. When the second layer of caching is an LRU, these failures are intercepted and effectively cached.
Another example, an LRU cache fails on an access pattern of key = k*5 with cache size being smaller than dataset. This is effectively (but partially) optimized out by the direct mapped cache in front of the LRU. Because, the direct mapped cache has mapping as tag = key % size and when size is 5 the access pattern uses only 1 tag of the direct mapped cache (or only 1/stride_length chunk of whole cache). The other 4 tags stay untouched and keep their values for future cache-hits. Keeping first level cache content relatively untouched makes it possibly more performant than just single cache.
Low latency or vectorizability of direct mapped cache and the associativity (+cache hit ratio) of LRU cache gets the best of both worlds and creates a smoother access latency for various datasizes and access patterns.
For a single-threaded application, connecting two caches to make a read+write cache system is trivial:
std::vector<int> test(40000);
LruClockCache<int,int> cacheL2(10000,[&](const int key){
return test[key];
},[&](const int key, const int value){
test[key]=value;
});
DirectMappedCache<int,int> cacheL1(1000,[&](const int key){
return cacheL2.get(key);
},[&](const int key, const int value){
cacheL2.set(key,value);
});
This setup is inherently -coherent (on read+write operations) for single-threaded use without requirement of any synchronization. The only extra book-keeping required is to call cacheL1.flush() before cacheL2.flush() before closing the application or disconnecting the backing-store. Flush on L1 sends dirty data to L2. Flush on L2 sends dirty data to backing-store.
After choosing a proper size-ratio between the two caches, different accessing patterns can be benchmarked. In overall, random-key access is bad for many cache types except random-eviction caches.
Random-Key Pattern
- Random key generation disrupts CPU's pipelining for the cache access: average latency increases
- Random keys can have duplicates: cache-hit ratio may increase depending on chance
- Compiler is unable to vectorize an unknown pattern: average latency increases
- Non-sequential access doesn't re-use cache line of CPU: average latency increases
- Random key generation has its own latency: average latency increases
- Luckily RAM is Random Access Memory
Test codes:
std::vector<int> test(40000);
for(int i=0;i<40000;i++)
test[i]=sin(i*3.14f);
LruClockCache<int,int> cacheL2(10000,[&](const int key){ return test[key]; },
[&](const int key, const int value){ test[key]=value; });
DirectMappedCache<int,int> cacheL1(1000,[&](const int key){ return cacheL2.get(key); },
[&](const int key, const int value){ cacheL2.set(key,value); });
for(int i=0;i<10000;i++)
cacheL1.get(i);
std::cout<<"-----"<<std::endl;
size_t s1=0;
float smooth = 1.2f;
for(float scale=1.0001f;scale<180.0f;scale*=smooth)
{
if(scale>90.0f){ smooth=1.01f;}
if(scale>105.0f){ smooth=1.2f;}
const int n = scale * 100;
const int repeats = 1000000/n;
std::random_device rd;
std::mt19937 rng(rd());
std::uniform_real_distribution<float> rnd(0,n);
if(scale<1.003f)
{
CpuBenchmarker bench(n*sizeof(int)*repeats,"rnd(rng)",n*repeats);
for(int repeat=0;repeat<repeats;repeat++)
for(int j=0;j<n;j++)
{
s1+=rnd(rng);
}
}
{
CpuBenchmarker bench(n*sizeof(int)*repeats,"dataset N="+std::to_string(n),n*repeats);
for(int repeat=0;repeat<repeats;repeat++)
for(int j=0;j<n;j++)
{
s1+=cacheL1.get(rnd(rng));
}
}
}
std::cout<<"======"<<s1<<std::endl;
Output:
rnd(rng): 18200457 nanoseconds (bandwidth = 219.77 MB/s)
(throughput = 18.20 nanoseconds per iteration)
dataset N=100: 52300989 nanoseconds (bandwidth = 76.48 MB/s)
(throughput = 52.30 nanoseconds per iteration)
dataset N=120: 52082830 nanoseconds (bandwidth = 76.80 MB/s)
(throughput = 52.08 nanoseconds per iteration)
dataset N=144: 52181890 nanoseconds (bandwidth = 76.65 MB/s)
(throughput = 52.19 nanoseconds per iteration)
dataset N=172: 52853591 nanoseconds (bandwidth = 75.67 MB/s)
(throughput = 52.86 nanoseconds per iteration)
dataset N=207: 53201082 nanoseconds (bandwidth = 75.17 MB/s)
(throughput = 53.21 nanoseconds per iteration)
dataset N=248: 53568062 nanoseconds (bandwidth = 74.67 MB/s)
(throughput = 53.57 nanoseconds per iteration)
dataset N=298: 55443692 nanoseconds (bandwidth = 72.13 MB/s)
(throughput = 55.46 nanoseconds per iteration)
dataset N=358: 55607077 nanoseconds (bandwidth = 71.93 MB/s)
(throughput = 55.61 nanoseconds per iteration)
dataset N=430: 57725808 nanoseconds (bandwidth = 69.28 MB/s)
(throughput = 57.74 nanoseconds per iteration)
dataset N=516: 58905768 nanoseconds (bandwidth = 67.87 MB/s)
(throughput = 58.94 nanoseconds per iteration)
dataset N=619: 60888459 nanoseconds (bandwidth = 65.67 MB/s)
(throughput = 60.91 nanoseconds per iteration)
dataset N=743: 62053290 nanoseconds (bandwidth = 64.42 MB/s)
(throughput = 62.09 nanoseconds per iteration)
dataset N=891: 63346593 nanoseconds (bandwidth = 63.13 MB/s)
(throughput = 63.37 nanoseconds per iteration)
dataset N=1070: 64221898 nanoseconds (bandwidth = 62.25 MB/s)
(throughput = 64.26 nanoseconds per iteration)
dataset N=1284: 66012331 nanoseconds (bandwidth = 60.53 MB/s)
(throughput = 66.08 nanoseconds per iteration)
dataset N=1540: 67372349 nanoseconds (bandwidth = 59.34 MB/s)
(throughput = 67.41 nanoseconds per iteration)
dataset N=1849: 67558150 nanoseconds (bandwidth = 59.12 MB/s)
(throughput = 67.66 nanoseconds per iteration)
dataset N=2218: 71619432 nanoseconds (bandwidth = 55.74 MB/s)
(throughput = 71.76 nanoseconds per iteration)
dataset N=2662: 73942784 nanoseconds (bandwidth = 54.00 MB/s)
(throughput = 74.07 nanoseconds per iteration)
dataset N=3195: 76050286 nanoseconds (bandwidth = 52.43 MB/s)
(throughput = 76.29 nanoseconds per iteration)
dataset N=3834: 78384883 nanoseconds (bandwidth = 50.87 MB/s)
(throughput = 78.63 nanoseconds per iteration)
dataset N=4600: 81342232 nanoseconds (bandwidth = 49.09 MB/s)
(throughput = 81.49 nanoseconds per iteration)
dataset N=5521: 83421726 nanoseconds (bandwidth = 47.92 MB/s)
(throughput = 83.48 nanoseconds per iteration)
dataset N=6625: 85615888 nanoseconds (bandwidth = 46.43 MB/s)
(throughput = 86.15 nanoseconds per iteration)
dataset N=7950: 86101006 nanoseconds (bandwidth = 46.17 MB/s)
(throughput = 86.64 nanoseconds per iteration)
dataset N=9540: 88113967 nanoseconds (bandwidth = 45.04 MB/s)
(throughput = 88.81 nanoseconds per iteration)
dataset N=9635: 88369810 nanoseconds (bandwidth = 44.92 MB/s)
(throughput = 89.05 nanoseconds per iteration)
dataset N=9732: 88246496 nanoseconds (bandwidth = 45.00 MB/s)
(throughput = 88.90 nanoseconds per iteration)
dataset N=9829: 88797945 nanoseconds (bandwidth = 44.72 MB/s)
(throughput = 89.45 nanoseconds per iteration)
dataset N=9927: 88484586 nanoseconds (bandwidth = 44.88 MB/s)
(throughput = 89.14 nanoseconds per iteration)
dataset N=10027: 91343552 nanoseconds (bandwidth = 43.47 MB/s)
(throughput = 92.02 nanoseconds per iteration)
dataset N=10127: 96146837 nanoseconds (bandwidth = 41.29 MB/s)
(throughput = 96.88 nanoseconds per iteration)
dataset N=10228: 99899579 nanoseconds (bandwidth = 39.72 MB/s)
(throughput = 100.69 nanoseconds per iteration)
dataset N=10331: 102550351 nanoseconds (bandwidth = 38.68 MB/s)
(throughput = 103.40 nanoseconds per iteration)
dataset N=10434: 104217680 nanoseconds (bandwidth = 38.04 MB/s)
(throughput = 105.14 nanoseconds per iteration)
dataset N=10538: 106442779 nanoseconds (bandwidth = 37.22 MB/s)
(throughput = 107.46 nanoseconds per iteration)
dataset N=12646: 151418563 nanoseconds (bandwidth = 26.39 MB/s)
(throughput = 151.56 nanoseconds per iteration)
dataset N=15175: 184381479 nanoseconds (bandwidth = 21.40 MB/s)
(throughput = 186.93 nanoseconds per iteration)
======49931600
Against all the odds, it still managed to do ~34 milliseconds (52ms benchmark - 18ms random offset) which is equivalent of 29 M lookups per second and its on 2.1 GHz Fx8150 (expect 100+ M /s on new CPUs).
Quicksort Access Pattern
std::vector<int> test(40000);
for(int i=0;i<40000;i++)
test[i]=sin(i*3.14f);
LruClockCache<int,int> cacheL2(100000,[&](const int key){ return test[key]; },
[&](const int key, const int value){ test[key]=value; });
DirectMappedCache<int,int> cacheL1(10000,[&](const int key)
{ return cacheL2.get(key); },[&](const int key, const int value){ cacheL2.set(key,value); });
for(int i=0;i<10000;i++)
cacheL1.get(i);
std::cout<<"-----"<<std::endl;
size_t s1=0;
float smooth = 1.2f;
for(float scale=1.0001f;scale<180.0f;scale*=smooth)
{
if(scale>90.0f){ smooth=1.01f;}
if(scale>105.0f){ smooth=1.2f;}
const int n = scale * 100;
{
std::cout<<"--------------------------------------------------"<<std::endl;
CpuBenchmarker bench(n*sizeof(int),"quicksort N="+std::to_string(n),1);
ctrx=0;
quickSort(cacheL1,0,n-1);
std::cout<<"total get/set calls = "<<ctrx<<std::endl;
}
}
std::cout<<"======"<<s1<<std::endl;
The Quicksort codes do the sorting in-place and array access was replaced by cache access with the addition of get/set counter variable to know real number of operations. Bandwidth measurement is sorted elements per second, not accessed data. Latency measurement is quickSort function call timing, not per-item access. L1 size is 10k, L2 size is 100k elements.
The output is as follows:
--------------------------------------------------
total get/set calls = 25245
quicksort N=100: 283371 nanoseconds (bandwidth = 1.41 MB/s)
(throughput = 283371.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 36295
quicksort N=120: 400108 nanoseconds (bandwidth = 1.20 MB/s)
(throughput = 400108.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 52195
quicksort N=144: 596758 nanoseconds (bandwidth = 0.97 MB/s)
(throughput = 596758.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 74385
quicksort N=172: 857578 nanoseconds (bandwidth = 0.80 MB/s)
(throughput = 857578.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 107635
quicksort N=207: 1289555 nanoseconds (bandwidth = 0.64 MB/s)
(throughput = 1289555.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 154375
quicksort N=248: 1851512 nanoseconds (bandwidth = 0.54 MB/s)
(throughput = 1851512.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 222750
quicksort N=298: 2732207 nanoseconds (bandwidth = 0.44 MB/s)
(throughput = 2732207.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 321300
quicksort N=358: 4087281 nanoseconds (bandwidth = 0.35 MB/s)
(throughput = 4087281.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 463320
quicksort N=430: 5672015 nanoseconds (bandwidth = 0.30 MB/s)
(throughput = 5672015.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 666925
quicksort N=516: 8550306 nanoseconds (bandwidth = 0.24 MB/s)
(throughput = 8550306.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 959445
quicksort N=619: 12136510 nanoseconds (bandwidth = 0.20 MB/s)
(throughput = 12136510.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 1381975
quicksort N=743: 17599695 nanoseconds (bandwidth = 0.17 MB/s)
(throughput = 17599695.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 1986925
quicksort N=891: 25069224 nanoseconds (bandwidth = 0.14 MB/s)
(throughput = 25069224.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 2864920
quicksort N=1070: 36701579 nanoseconds (bandwidth = 0.12 MB/s)
(throughput = 36701579.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 4124845
quicksort N=1284: 52731251 nanoseconds (bandwidth = 0.10 MB/s)
(throughput = 52731251.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 5932845
quicksort N=1540: 76673623 nanoseconds (bandwidth = 0.08 MB/s)
(throughput = 76673623.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 8551620
quicksort N=1849: 109418022 nanoseconds (bandwidth = 0.07 MB/s)
(throughput = 109418022.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 12304350
quicksort N=2218: 156312967 nanoseconds (bandwidth = 0.06 MB/s)
(throughput = 156312967.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 17722260
quicksort N=2662: 225647562 nanoseconds (bandwidth = 0.05 MB/s)
(throughput = 225647562.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 25528045
quicksort N=3195: 326446975 nanoseconds (bandwidth = 0.04 MB/s)
(throughput = 326446975.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 36758470
quicksort N=3834: 469934209 nanoseconds (bandwidth = 0.03 MB/s)
(throughput = 469934209.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 52911495
quicksort N=4600: 678869539 nanoseconds (bandwidth = 0.03 MB/s)
(throughput = 678869539.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 76217400
quicksort N=5521: 980819568 nanoseconds (bandwidth = 0.02 MB/s)
(throughput = 980819568.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 109743120
quicksort N=6625: 1416697916 nanoseconds (bandwidth = 0.02 MB/s)
(throughput = 1416697916.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 158026120
quicksort N=7950: 2010299830 nanoseconds (bandwidth = 0.02 MB/s)
(throughput = 2010299830.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 227552845
quicksort N=9540: 2897904620 nanoseconds (bandwidth = 0.01 MB/s)
(throughput = 2897904620.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 232107145
quicksort N=9635: 2969687754 nanoseconds (bandwidth = 0.01 MB/s)
(throughput = 2969687754.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 236803885
quicksort N=9732: 3062550046 nanoseconds (bandwidth = 0.01 MB/s)
(throughput = 3062550046.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 241547670
quicksort N=9829: 3092673884 nanoseconds (bandwidth = 0.01 MB/s)
(throughput = 3092673884.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 246388135
quicksort N=9927: 3158007191 nanoseconds (bandwidth = 0.01 MB/s)
(throughput = 3158007191.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 251376885
quicksort N=10027: 3260430385 nanoseconds (bandwidth = 0.01 MB/s)
(throughput = 3260430385.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 256415635
quicksort N=10127: 3319869940 nanoseconds (bandwidth = 0.01 MB/s)
(throughput = 3319869940.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 261555525
quicksort N=10228: 3344205937 nanoseconds (bandwidth = 0.01 MB/s)
(throughput = 3344205937.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 266849725
quicksort N=10331: 3420943265 nanoseconds (bandwidth = 0.01 MB/s)
(throughput = 3420943265.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 272196970
quicksort N=10434: 3493719216 nanoseconds (bandwidth = 0.01 MB/s)
(throughput = 3493719216.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 277649950
quicksort N=10538: 3574425004 nanoseconds (bandwidth = 0.01 MB/s)
(throughput = 3574425004.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 399834900
quicksort N=12646: 5157410859 nanoseconds (bandwidth = 0.01 MB/s)
(throughput = 5157410859.00 nanoseconds per iteration)
--------------------------------------------------
total get/set calls = 575739495
quicksort N=15175: 7395595194 nanoseconds (bandwidth = 0.01 MB/s)
(throughput = 7395595194.00 nanoseconds per iteration)
======0
For N=100, 25245 get/set calls were made with 283 microseconds total latency. 11 nanoseconds per element access.
For N=15175, 575739495 get/set calls were made with 7.4 seconds total latency. 12.8 nanoseconds per element access. With 3.6 GHz instead of 2.1 GHz, performance becomes 7.5 nanoseconds per element access or 133 million get/set per second. Even in the 15k sized dataset, it sorts 10 kB worth of data per second (for 32bit integer values). With bigger type of values such as long strings, it becomes much more memory efficient and access latency becomes less important.
Strided Sequential Access Pattern
In theory, this should invalidate L1 all the time but stop at L2, mostly depending on stride size.
std::vector<int> test(4000000);
for(int i=0;i<4000000;i++)
test[i]=sin(i*3.14f);
LruClockCache<int,int> cacheL2(10000,[&](const int key){ return test[key]; },
[&](const int key, const int value){ test[key]=value; });
DirectMappedCache<int,int> cacheL1(1000,[&](const int key){ return cacheL2.get(key);
},[&](const int key, const int value){ cacheL2.set(key,value); });
for(int i=0;i<4000000;i++)
cacheL1.get(i);
std::cout<<"-----"<<std::endl;
size_t s1=0;
float smooth = 1.2f;
for(float scale=1.0001f;scale<180.0f;scale*=smooth)
{
if(scale>90.0f){ smooth=1.01f;}
if(scale>105.0f){ smooth=1.2f;}
const int n = scale * 100;
const int repeats = 1000;
{
CpuBenchmarker bench(n*sizeof(int)*repeats,"N="+std::to_string(n),n*repeats);
for(int repeat = 0; repeat<repeats; repeat++)
{
for(int i=0;i<n;i++)
{
s1+=cacheL1.get(i*100);
}
}
}
}
std::cout<<"======"<<s1<<std::endl;
The output is as follows:
N=100: 3694579 nanoseconds (bandwidth = 108.27 MB/s)
(throughput = 36.95 nanoseconds per iteration)
N=120: 5410847 nanoseconds (bandwidth = 88.71 MB/s)
(throughput = 45.09 nanoseconds per iteration)
N=144: 7500038 nanoseconds (bandwidth = 76.80 MB/s)
(throughput = 52.08 nanoseconds per iteration)
N=172: 9356409 nanoseconds (bandwidth = 73.53 MB/s)
(throughput = 54.40 nanoseconds per iteration)
N=207: 11756553 nanoseconds (bandwidth = 70.43 MB/s)
(throughput = 56.79 nanoseconds per iteration)
N=248: 14402026 nanoseconds (bandwidth = 68.88 MB/s)
(throughput = 58.07 nanoseconds per iteration)
N=298: 16514732 nanoseconds (bandwidth = 72.18 MB/s)
(throughput = 55.42 nanoseconds per iteration)
N=358: 20141895 nanoseconds (bandwidth = 71.10 MB/s)
(throughput = 56.26 nanoseconds per iteration)
N=430: 24245251 nanoseconds (bandwidth = 70.94 MB/s)
(throughput = 56.38 nanoseconds per iteration)
N=516: 28535297 nanoseconds (bandwidth = 72.33 MB/s)
(throughput = 55.30 nanoseconds per iteration)
N=619: 34730097 nanoseconds (bandwidth = 71.29 MB/s)
(throughput = 56.11 nanoseconds per iteration)
N=743: 41695556 nanoseconds (bandwidth = 71.28 MB/s)
(throughput = 56.12 nanoseconds per iteration)
N=891: 49929799 nanoseconds (bandwidth = 71.38 MB/s)
(throughput = 56.04 nanoseconds per iteration)
N=1070: 59782292 nanoseconds (bandwidth = 71.59 MB/s)
(throughput = 55.87 nanoseconds per iteration)
N=1284: 70488677 nanoseconds (bandwidth = 72.86 MB/s)
(throughput = 54.90 nanoseconds per iteration)
N=1540: 83974809 nanoseconds (bandwidth = 73.36 MB/s)
(throughput = 54.53 nanoseconds per iteration)
N=1849: 101579922 nanoseconds (bandwidth = 72.81 MB/s)
(throughput = 54.94 nanoseconds per iteration)
N=2218: 119347699 nanoseconds (bandwidth = 74.34 MB/s)
(throughput = 53.81 nanoseconds per iteration)
N=2662: 141495512 nanoseconds (bandwidth = 75.25 MB/s)
(throughput = 53.15 nanoseconds per iteration)
N=3195: 166500722 nanoseconds (bandwidth = 76.76 MB/s)
(throughput = 52.11 nanoseconds per iteration)
N=3834: 195072477 nanoseconds (bandwidth = 78.62 MB/s)
(throughput = 50.88 nanoseconds per iteration)
N=4600: 229180314 nanoseconds (bandwidth = 80.29 MB/s)
(throughput = 49.82 nanoseconds per iteration)
N=5521: 270186192 nanoseconds (bandwidth = 81.74 MB/s)
(throughput = 48.94 nanoseconds per iteration)
N=6625: 315055195 nanoseconds (bandwidth = 84.11 MB/s)
(throughput = 47.56 nanoseconds per iteration)
N=7950: 361494623 nanoseconds (bandwidth = 87.97 MB/s)
(throughput = 45.47 nanoseconds per iteration)
N=9540: 413941004 nanoseconds (bandwidth = 92.19 MB/s)
(throughput = 43.39 nanoseconds per iteration)
N=9635: 414901046 nanoseconds (bandwidth = 92.89 MB/s)
(throughput = 43.06 nanoseconds per iteration)
N=9732: 414661443 nanoseconds (bandwidth = 93.88 MB/s)
(throughput = 42.61 nanoseconds per iteration)
N=9829: 432962408 nanoseconds (bandwidth = 90.81 MB/s)
(throughput = 44.05 nanoseconds per iteration)
N=9927: 414821653 nanoseconds (bandwidth = 95.72 MB/s)
(throughput = 41.79 nanoseconds per iteration)
N=10027: 1515980500 nanoseconds (bandwidth = 26.46 MB/s)
(throughput = 151.19 nanoseconds per iteration)
N=10127: 1551122918 nanoseconds (bandwidth = 26.12 MB/s)
(throughput = 153.17 nanoseconds per iteration)
N=10228: 1568851575 nanoseconds (bandwidth = 26.08 MB/s)
(throughput = 153.39 nanoseconds per iteration)
N=10331: 1602725754 nanoseconds (bandwidth = 25.78 MB/s)
(throughput = 155.14 nanoseconds per iteration)
N=10434: 1623017665 nanoseconds (bandwidth = 25.72 MB/s)
(throughput = 155.55 nanoseconds per iteration)
N=10538: 1626828752 nanoseconds (bandwidth = 25.91 MB/s)
(throughput = 154.38 nanoseconds per iteration)
N=12646: 2059143192 nanoseconds (bandwidth = 24.57 MB/s)
(throughput = 162.83 nanoseconds per iteration)
N=15175: 2672005898 nanoseconds (bandwidth = 22.72 MB/s)
(throughput = 176.08 nanoseconds per iteration)
======29000
As expected, latencies started high and continued relatively steady until N=10000 which was size of L2 cache. The slight decrease on average latency until N=10000 was caused by increased iterations making a better measurement than just N=100 where 1000 repeats were not enough to fully stress the hardware.
Image Processing Pattern (Gaussian Blur)
- Tiled computing increases L1/L2 hit ratios: lowered latency
- Pattern is known in compile-time: lowered/hidden latency

int imageWidth, imageHeight, maxN;
double minR, maxR, minI, maxI;
imageWidth = 1024;
imageHeight = 1024;
maxN = 512;
minR = -1.5;
maxR = 0.7;
minI = -1.0;
maxI = 1.0;
size_t cacheScaling = 1;
for (int cacheScalingIter = 0; cacheScalingIter < 8; cacheScalingIter++)
{
cacheScaling *= 2;
const int L2size = 1024 * 128 * cacheScaling;
const int L1size = L2size / 4;
std::vector < int > backingStore(5000000);
auto L2 = LruClockCache< int, int >(L2size,
[ & ](int key) {
return backingStore[key];
},
[ & ](int key, int value) {
backingStore[key] = value;
});
auto L1 = DirectMappedCache< int, int >(L1size,
[ & ](int key) {
return L2.get(key);
},
[ & ](int key, int value) {
L2.set(key,value);
});
std::ofstream output("output_image_scaling" + std::to_string(cacheScaling) + ".ppm");
output << "P6" << std::endl;
output << imageWidth << " " << imageHeight << std::endl;
output << "255" << std::endl;
for (int i = 0; i < imageHeight; i++) {
for (int j = 0; j < imageWidth; j++) {
double cr = mapToReal(j, imageWidth, minR, maxR);
double ci = mapToImaginary(i, imageHeight, minI, maxI);
L1.set(i + j * imageWidth, findMandelbrot(cr, ci, maxN));
}
}
{
const int nGauss = 9;
const int GaussianBlurKernel[nGauss] = {
1, 2, 1,
2, 4, 2,
1, 2, 1
};
size_t nRepeats = 5;
size_t nReadsPerIter = nGauss;
size_t nWritesPerIter = 1;
size_t totalLookups = nRepeats * (imageHeight - 2) *
(imageWidth - 2) * (nReadsPerIter + nWritesPerIter);
CpuBenchmarker bench(totalLookups * sizeof(int),
"L1 tags = " + std::to_string(L1size) + " L2 tags=" +
std::to_string(L2size) + " performance", totalLookups);
for (size_t k = 0; k < nRepeats; k++) {
for (int tiley = 0; tiley < imageHeight/32; tiley++) {
for (int tilex = 0; tilex < imageWidth/32; tilex++) {
for (int jj = 0; jj < 32; jj++) {
for (int ii = 0; ii < 32; ii++) {
const int i = tilex * 32 + ii;
const int j = tiley * 32 + jj;
if (j >= 1 && j <= imageHeight - 2 && i >= 1 && i <= imageWidth - 2) {
unsigned int pixelAccumulator1 = 0;
unsigned int pixelAccumulator2 = 0;
unsigned int pixelAccumulator3 = 0;
pixelAccumulator1 += L1.get(i - 1 + (j - 1) * imageWidth) *
GaussianBlurKernel[-1 + 1 + (-1 + 1) * 3];
pixelAccumulator2 += L1.get(i + 0 + (j - 1) * imageWidth) *
GaussianBlurKernel[+0 + 1 + (-1 + 1) * 3];
pixelAccumulator3 += L1.get(i + 1 + (j - 1) * imageWidth) *
GaussianBlurKernel[+1 + 1 + (-1 + 1) * 3];
pixelAccumulator1 += L1.get(i - 1 + (j - 0) * imageWidth) *
GaussianBlurKernel[-1 + 1 + (-0 + 1) * 3];
pixelAccumulator2 += L1.get(i + 0 + (j - 0) * imageWidth) *
GaussianBlurKernel[+0 + 1 + (-0 + 1) * 3];
pixelAccumulator3 += L1.get(i + 1 + (j - 0) * imageWidth) *
GaussianBlurKernel[+1 + 1 + (-0 + 1) * 3];
pixelAccumulator1 += L1.get(i - 1 + (j + 1) * imageWidth) *
GaussianBlurKernel[-1 + 1 + (+1 + 1) * 3];
pixelAccumulator2 += L1.get(i + 0 + (j + 1) * imageWidth) *
GaussianBlurKernel[+0 + 1 + (+1 + 1) * 3];
pixelAccumulator3 += L1.get(i + 1 + (j + 1) * imageWidth) *
GaussianBlurKernel[+1 + 1 + (+1 + 1) * 3];
const int n = (pixelAccumulator1 + pixelAccumulator2 + pixelAccumulator3) >> 4;
L1.set(i + j * imageWidth, n);
}
}
}
}
}
}
}
for (int i = 0; i < imageHeight; i++) {
for (int j = 0; j < imageWidth; j++) {
int n = L1.get(i + j * imageWidth);
int r = ((int) sqrt(n) % 256);
int gr = (2 * n % 256);
int b = (n % 256);
output << (char) r << (char) gr << (char) b;
}
}
std::cout << "Finished!" << std::endl;
L1.flush();
output.flush();
}
The output is as shown below:

For every cache scaling in the outer for-loop, it produces the same image but using a bigger cache size than the last.
The console output for 3.6GHz FX8150:
L1 tags = 65536 L2 tags=262144 performance: 1051230942 nanoseconds
(bandwidth = 198.72 MB/s) (throughput = 20.13 nanoseconds per iteration)
Finished!
L1 tags = 131072 L2 tags=524288 performance: 983512878 nanoseconds
(bandwidth = 212.40 MB/s) (throughput = 18.83 nanoseconds per iteration)
Finished!
L1 tags = 262144 L2 tags=1048576 performance: 743200249 nanoseconds
(bandwidth = 281.08 MB/s) (throughput = 14.23 nanoseconds per iteration)
Finished!
L1 tags = 524288 L2 tags=2097152 performance: 608610176 nanoseconds
(bandwidth = 343.24 MB/s) (throughput = 11.65 nanoseconds per iteration)
Finished!
L1 tags = 1048576 L2 tags=4194304 performance: 97744550 nanoseconds
(bandwidth = 2137.17 MB/s) (throughput = 1.87 nanoseconds per iteration)
Finished!
L1 tags = 2097152 L2 tags=8388608 performance: 148706457 nanoseconds
(bandwidth = 1404.76 MB/s) (throughput = 2.85 nanoseconds per iteration)
Finished!
L1 tags = 4194304 L2 tags=16777216 performance: 97734293 nanoseconds
(bandwidth = 2137.40 MB/s) (throughput = 1.87 nanoseconds per iteration)
Finished!
L1 tags = 8388608 L2 tags=33554432 performance: 148821672 nanoseconds
(bandwidth = 1403.67 MB/s) (throughput = 2.85 nanoseconds per iteration)
Finished!
A good amount of re-use for a pixel also uses CPU's L1 cache efficiently. L1 latency of FX8150 is 4 cycles. 3.6GHz and 4 cycles means just about 1 nanosecond latency. For 1M direct-mapped cache size, it had 1.87 nanoseconds.
1.87 nanoseconds = 534 million lookups per second.
Readers may wonder where the title's 1 billion lookups per second is. To have a fully fledged multithreaded read+write cache, there has to be cache-coherency between all L1 and L2 caches. For now, the implementations support only single-level read+write multithreading or multi-level read-only multithreading, with use of class CacheThreader.h:
#ifndef CACHETHREADER_H_
#define CACHETHREADER_H_
#include<vector>
#include<memory>
#include<thread>
#include<atomic>
#include"DirectMappedCache.h"
#include"LruClockCache.h"
template<template<typename,typename, typename> class Cache,
typename CacheKey, typename CacheValue, typename CacheInternalCounterTypeInteger=size_t>
class CacheThreader
{
private:
std::shared_ptr<Cache<CacheKey,CacheValue,CacheInternalCounterTypeInteger>> LLC;
int nThreads;
std::vector<std::shared_ptr<LruClockCache<CacheKey,CacheValue,
CacheInternalCounterTypeInteger>>> L2;
std::vector<std::shared_ptr<DirectMappedCache<CacheKey,CacheValue>>> L1;
public:
CacheThreader(std::shared_ptr<Cache<CacheKey,CacheValue,
CacheInternalCounterTypeInteger>> cacheLLC, int sizeCacheL1,
int sizeCacheL2, int nThread=1)
{
LLC=cacheLLC;
nThreads = nThread;
for(int i=0;i<nThread;i++)
{
L2.push_back( std::make_shared<LruClockCache<CacheKey,
CacheValue,CacheInternalCounterTypeInteger>>(sizeCacheL2,[i,this](CacheKey key){
return this->LLC->getThreadSafe(key);
},[i,this](CacheKey key, CacheValue value){
this->LLC->setThreadSafe(key,value);
}));
L1.push_back( std::make_shared<DirectMappedCache<CacheKey,CacheValue>>
(sizeCacheL1,[i,this](CacheKey key){
return this->L2[i]->get(key);
},[i,this](CacheKey key, CacheValue value){
this->L2[i]->set(key,value);
}));
}
}
const CacheValue get(CacheKey key) const
{
return L1[0]->get(key);
}
void set(CacheKey key, CacheValue value) const
{
L1[0]->set(key,value);
}
void flush()
{
L1[0]->flush();
L2[0]->flush();
}
~CacheThreader(){ }
};
#endif /* CACHETHREADER_H_ */
How it works:
- Every thread in an app can instantiate its own
CacheThreader object. - Constructor takes a cache instance wrapped in
std::shared_ptr to be used as LLC (last level cache) for sharing between multiple threads. Since LLC is shared, only main thread should create it and share it with other threads. LLC implementation must have getThreadSafe and setThreadSafe methods. - Constructor adds an
L2 LRU approximation (LruClockCache) in front of LLC but only for its own thread (private cache). - Constructor adds another cache (
DirectMappedCache) in front of L2, as an L1 cache. - Each thread can directly operate on its own
L1 cache and all evictions propagate towards LLC. - Read-only access. Only
L1.get(key) calls are guaranteed to have coherency. - Useful for read-only databases, static world objects in games, anything that does not change.
auto LLC = std::make_shared<LruClockCache< int, int >>(L2size*4,
[ & ](int key) {
return backingStore[key];
},
[ & ](int key, int value) {
backingStore[key] = value;
});
auto L1L2LLC = CacheThreader<LruClockCache, int, int >(LLC,L1size,L2size);
CacheThreader constructor does all the necessary bindings between L1, L2 and LLC and calls getThreadSafe/setThreadSafe methods whenever eviction reaches LLC. Only LLC is required to access backing-store as it is the last level cache. Only to show the locking overhead (lock_guard) in C++, LruClockCache is chosen in the below example. Every thread locks whole LruClockCache instance when calling getThreadSafe. This is not the case in DirectMappedMultiThreadCache which makes locking on cache-item-level which reduces lock contention greatly.
Gaussian blur read-only test (it does not produce the right output due to not writing to pixels) that does same work but on 8 threads using CacheThreader and a bit different hot spot:
PARALLEL_FOR(0,8,loop,
{
auto L1 = CacheThreader<LruClockCache, int, int >(LLC,L1size,L2size);
for (size_t k = 0; k < nRepeats; k++) {
for (int tiley = 0; tiley < imageHeight/32; tiley++) {
for (int tilex = 0; tilex < imageWidth/32; tilex++) {
for (int jj = 0; jj < 32; jj++) {
for (int ii = 0; ii < 32; ii++) {
const int i = tilex * 32 + ii;
const int j = tiley * 32 + jj;
if (j >= 1 && j <= imageHeight - 2 && i >= 1 && i <= imageWidth - 2) {
unsigned int pixelAccumulator1 = 0;
unsigned int pixelAccumulator2 = 0;
unsigned int pixelAccumulator3 = 0;
pixelAccumulator1 += L1.get(i - 1 + (j - 1) * imageWidth) *
GaussianBlurKernel[-1 + 1 + (-1 + 1) * 3];
pixelAccumulator2 += L1.get(i + 0 + (j - 1) * imageWidth) *
GaussianBlurKernel[+0 + 1 + (-1 + 1) * 3];
pixelAccumulator3 += L1.get(i + 1 + (j - 1) * imageWidth) *
GaussianBlurKernel[+1 + 1 + (-1 + 1) * 3];
pixelAccumulator1 += L1.get(i - 1 + (j - 0) * imageWidth) *
GaussianBlurKernel[-1 + 1 + (-0 + 1) * 3];
pixelAccumulator2 += L1.get(i + 0 + (j - 0) * imageWidth) *
GaussianBlurKernel[+0 + 1 + (-0 + 1) * 3];
pixelAccumulator3 += L1.get(i + 1 + (j - 0) * imageWidth) *
GaussianBlurKernel[+1 + 1 + (-0 + 1) * 3];
pixelAccumulator1 += L1.get(i - 1 + (j + 1) * imageWidth) *
GaussianBlurKernel[-1 + 1 + (+1 + 1) * 3];
pixelAccumulator2 += L1.get(i + 0 + (j + 1) * imageWidth) *
GaussianBlurKernel[+0 + 1 + (+1 + 1) * 3];
pixelAccumulator3 += L1.get(i + 1 + (j + 1) * imageWidth) *
GaussianBlurKernel[+1 + 1 + (+1 + 1) * 3];
const int n = (pixelAccumulator1 +
pixelAccumulator2 + pixelAccumulator3) >> 4;
L1.set(i + j * imageWidth, n);
}
}
}
}
}
}
});
Since there is no cache-coherency for multi-level multi-threading (yet), only read performance is measured instead of output quality. The source code is as below:
int imageWidth, imageHeight, maxN;
double minR, maxR, minI, maxI;
imageWidth = 256;
imageHeight = 256;
maxN = 512;
minR = -1.5;
maxR = 0.7;
minI = -1.0;
maxI = 1.0;
size_t cacheScaling = 1;
for (int cacheScalingIter = 0; cacheScalingIter < 8; cacheScalingIter++)
{
cacheScaling *= 2;
const int L2size = 1024 * 16 * cacheScaling;
const int L1size = L2size / 4;
std::vector < int > backingStore(5000000);
auto LLC = std::make_shared<LruClockCache< int, int >>(L2size*4,
[ & ](int key) {
return backingStore[key];
},
[ & ](int key, int value) {
backingStore[key] = value;
});
std::ofstream output("output_image_scaling" + std::to_string(cacheScaling) + ".ppm");
output << "P6" << std::endl;
output << imageWidth << " " << imageHeight << std::endl;
output << "255" << std::endl;
for (int i = 0; i < imageHeight; i++) {
for (int j = 0; j < imageWidth; j++) {
double cr = mapToReal(j, imageWidth, minR, maxR);
double ci = mapToImaginary(i, imageHeight, minI, maxI);
LLC->set(i + j * imageWidth, findMandelbrot(cr, ci, maxN));
}
}
{
const int nGauss = 9;
const int GaussianBlurKernel[nGauss] = {
1, 2, 1,
2, 4, 2,
1, 2, 1
};
size_t nRepeats = 5 + (cacheScalingIter * 400);
size_t nReadsPerIter = nGauss;
size_t nWritesPerIter = 1;
size_t totalLookups = nRepeats * (imageHeight - 2) *
(imageWidth - 2) * (nReadsPerIter + nWritesPerIter);
CpuBenchmarker bench(totalLookups*8 * sizeof(int),
"L1 tags = " + std::to_string(L1size) + " L2 tags=" +
std::to_string(L2size) + " performance", totalLookups*8);
PARALLEL_FOR(0,8,loop,
{
auto L1 = CacheThreader<LruClockCache, int, int >(LLC,L1size,L2size);
for (size_t k = 0; k < nRepeats; k++) {
for (int tiley = 0; tiley < imageHeight/32; tiley++) {
for (int tilex = 0; tilex < imageWidth/32; tilex++) {
for (int jj = 0; jj < 32; jj++) {
for (int ii = 0; ii < 32; ii++) {
const int i = tilex * 32 + ii;
const int j = tiley * 32 + jj;
if (j >= 1 && j <= imageHeight - 2 && i >= 1 &&
i <= imageWidth - 2) {
unsigned int pixelAccumulator1 = 0;
unsigned int pixelAccumulator2 = 0;
unsigned int pixelAccumulator3 = 0;
pixelAccumulator1 += L1.get(i - 1 + (j - 1) * imageWidth) *
GaussianBlurKernel[-1 + 1 + (-1 + 1) * 3];
pixelAccumulator2 += L1.get(i + 0 + (j - 1) * imageWidth) *
GaussianBlurKernel[+0 + 1 + (-1 + 1) * 3];
pixelAccumulator3 += L1.get(i + 1 + (j - 1) * imageWidth) *
GaussianBlurKernel[+1 + 1 + (-1 + 1) * 3];
pixelAccumulator1 += L1.get(i - 1 + (j - 0) * imageWidth) *
GaussianBlurKernel[-1 + 1 + (-0 + 1) * 3];
pixelAccumulator2 += L1.get(i + 0 + (j - 0) * imageWidth) *
GaussianBlurKernel[+0 + 1 + (-0 + 1) * 3];
pixelAccumulator3 += L1.get(i + 1 + (j - 0) * imageWidth) *
GaussianBlurKernel[+1 + 1 + (-0 + 1) * 3];
pixelAccumulator1 += L1.get(i - 1 + (j + 1) * imageWidth) *
GaussianBlurKernel[-1 + 1 + (+1 + 1) * 3];
pixelAccumulator2 += L1.get(i + 0 + (j + 1) * imageWidth) *
GaussianBlurKernel[+0 + 1 + (+1 + 1) * 3];
pixelAccumulator3 += L1.get(i + 1 + (j + 1) * imageWidth) *
GaussianBlurKernel[+1 + 1 + (+1 + 1) * 3];
const int n = (pixelAccumulator1 + pixelAccumulator2 +
pixelAccumulator3) >> 4;
L1.set(i + j * imageWidth, n);
}
}
}
}
}
}
L1.flush();
});
}
for (int i = 0; i < imageHeight; i++) {
for (int j = 0; j < imageWidth; j++) {
int n = LLC->get(i + j * imageWidth);
int r = ((int) sqrt(n) % 256);
int gr = (2 * n % 256);
int b = (n % 256);
output << (char) r << (char) gr << (char) b;
}
}
std::cout << "Finished!" << std::endl;
LLC->flush();
output.flush();
}
The console output is as below:
L1 tags = 8192 L2 tags=32768 performance: 4519806245 nanoseconds
(bandwidth = 22.84 MB/s) (throughput = 175.14 nanoseconds per iteration)
Finished!
L1 tags = 16384 L2 tags=65536 performance: 3086661771 nanoseconds
(bandwidth = 2708.84 MB/s) (throughput = 1.48 nanoseconds per iteration)
Finished!
L1 tags = 32768 L2 tags=131072 performance: 6959029488 nanoseconds
(bandwidth = 2388.17 MB/s) (throughput = 1.67 nanoseconds per iteration)
Finished!
L1 tags = 65536 L2 tags=262144 performance: 2885031311 nanoseconds
(bandwidth = 8622.91 MB/s) (throughput = 0.46 nanoseconds per iteration)
Finished!
L1 tags = 131072 L2 tags=524288 performance: 3514979863 nanoseconds
(bandwidth = 9426.92 MB/s) (throughput = 0.42 nanoseconds per iteration)
Finished!
L1 tags = 262144 L2 tags=1048576 performance: 4235796489 nanoseconds
(bandwidth = 9772.30 MB/s) (throughput = 0.41 nanoseconds per iteration)
Finished!
L1 tags = 524288 L2 tags=2097152 performance: 4981730617 nanoseconds
(bandwidth = 9966.72 MB/s) (throughput = 0.40 nanoseconds per iteration)
Finished!
L1 tags = 1048576 L2 tags=4194304 performance: 5783022399 nanoseconds
(bandwidth = 10013.72 MB/s) (throughput = 0.40 nanoseconds per iteration)
Finished!
0.4 nanoseconds per iteration (2.5 billion lookups per second) with 8 threads points to 3.2 nanoseconds average access latency per thread. When L1/L2 caches are smaller than dataset (256x256 image), the lock contention on single entry point of LLC causes 175 nanosecond on 8 threads or 1400 nanoseconds per thread. This is the cost of synchronization on only single data.
Running the same code but with DirectMappedMultiThreadCache.h as LLC (just replacing type of object with DirectMappedMultiThreadCache) and reducing cache size by 4 times:
L1 tags = 512 L2 tags=2048 performance: 254857624 nanoseconds
(bandwidth = 405.03 MB/s) (throughput = 9.88 nanoseconds per iteration)
Finished!
L1 tags = 1024 L2 tags=4096 performance: 18364903435 nanoseconds
(bandwidth = 455.29 MB/s) (throughput = 8.79 nanoseconds per iteration)
Finished!
L1 tags = 2048 L2 tags=8192 performance: 32524791168 nanoseconds
(bandwidth = 510.97 MB/s) (throughput = 7.83 nanoseconds per iteration)
Finished!
L1 tags = 4096 L2 tags=16384 performance: 39102175517 nanoseconds
(bandwidth = 636.21 MB/s) (throughput = 6.29 nanoseconds per iteration)
Finished!
L1 tags = 8192 L2 tags=32768 performance: 53978929784 nanoseconds
(bandwidth = 613.86 MB/s) (throughput = 6.52 nanoseconds per iteration)
Finished!
L1 tags = 16384 L2 tags=65536 performance: 17846742945 nanoseconds
(bandwidth = 2319.38 MB/s) (throughput = 1.72 nanoseconds per iteration)
Finished!
L1 tags = 32768 L2 tags=131072 performance: 28040567180 nanoseconds
(bandwidth = 1770.70 MB/s) (throughput = 2.26 nanoseconds per iteration)
Finished!
L1 tags = 65536 L2 tags=262144 performance: 5105202102 nanoseconds
(bandwidth = 11343.25 MB/s) (throughput = 0.35 nanoseconds per iteration)
Finished!
Distributing locking to whole array of cache tags made it much faster to access to cache even when L1&L2 were very small compared to dataset (256x256 = 65536 pixels) and last iteration had 2.8 billion lookups per second. But, is direct mapped cache as an LLC good enough for high cache-hit-ratio? To test this, simply two atomic counters are added to cache-miss functions and compared to number of all reads:
read hit ratio=98.5571%
L1 tags = 512 L2 tags=2048 performance: 802570239 nanoseconds
(bandwidth = 128.62 MB/s) (throughput = 31.10 nanoseconds per iteration)
Finished!
read hit ratio=98.59%
L1 tags = 1024 L2 tags=4096 performance: 66764400442 nanoseconds
(bandwidth = 125.24 MB/s) (throughput = 31.94 nanoseconds per iteration)
Finished!
...
With same Gaussian Blur algorithm and LRU approximation, hit-ratio increases by only 0.03% and per-access latency increases by 130 nanoseconds. This may or may not give a boost of performance depending on latency of backing-store. For a very slow backing-store, LRU can tolerate higher access latency while direct mapped cache can actually wait more than LRU for the backing-store due to extra misses. This would depend on access pattern too. Every 1% higher cache-hit translates to 100% higher performance on some access patterns. But some of those anti-patterns of direct mapped cache is filtered by middle later LRU so it becomes easier for the LLC scenario.
Multithreaded direct-mapped cache is compatible with LruClockCache to be used as LLC of CacheThreader and be used alone for multi-threaded apps with fast-enough backing-stores (to tolerate lower hit-ratios) (source code):
#ifndef DIRECTMAPPEDMULTITHREADCACHE_H_
#define DIRECTMAPPEDMULTITHREADCACHE_H_
#include<vector>
#include<functional>
#include<mutex>
template< typename CacheKey, typename CacheValue, typename InternalKeyTypeInteger=size_t>
class DirectMappedMultiThreadCache
{
public:
DirectMappedMultiThreadCache(InternalKeyTypeInteger numElements,
const std::function<CacheValue(CacheKey)> & readMiss,
const std::function<void(CacheKey,CacheValue)> &
writeMiss):size(numElements),sizeM1(numElements-1),
loadData(readMiss),saveData(writeMiss)
{
mut = std::vector<std::mutex>(numElements);
for(InternalKeyTypeInteger i=0;i<numElements;i++)
{
valueBuffer.push_back(CacheValue());
isEditedBuffer.push_back(0);
keyBuffer.push_back(CacheKey());
}
}
inline
const CacheValue get(const CacheKey & key) noexcept
{
return accessDirect(key,nullptr);
}
inline
const std::vector<CacheValue> getMultiple(const std::vector<CacheKey> & key) noexcept
{
const int n = key.size();
std::vector<CacheValue> result(n);
for(int i=0;i<n;i++)
{
result[i]=accessDirect(key[i],nullptr);
}
return result;
}
inline
const CacheValue getThreadSafe(const CacheKey & key) noexcept
{
return accessDirectLocked(key,nullptr);
}
inline
void set(const CacheKey & key, const CacheValue & val) noexcept
{
accessDirect(key,&val,1);
}
inline
void setThreadSafe(const CacheKey & key, const CacheValue & val) noexcept
{
accessDirectLocked(key,&val,1);
}
void flush()
{
try
{
for (CacheKey i=0;i<size;i++)
{
if (isEditedBuffer[i] == 1)
{
isEditedBuffer[i]=0;
auto oldKey = keyBuffer[i];
auto oldValue = valueBuffer[i];
saveData(oldKey,oldValue);
}
}
}catch(std::exception &ex){ std::cout<<ex.what()<<std::endl; }
}
CacheValue const accessDirectLocked(const CacheKey & key,
const CacheValue * value, const bool opType = 0)
{
InternalKeyTypeInteger tag = key & sizeM1;
std::lock_guard<std::mutex> lg(mut[tag]);
if(keyBuffer[tag] == key)
{
if(opType == 1)
{
isEditedBuffer[tag]=1;
valueBuffer[tag]=*value;
}
return valueBuffer[tag];
}
else {
CacheValue oldValue = valueBuffer[tag];
CacheKey oldKey = keyBuffer[tag];
if(isEditedBuffer[tag] == 1)
{
if(opType==0)
{
isEditedBuffer[tag]=0;
}
saveData(oldKey,oldValue);
if(opType==0)
{
const CacheValue && loadedData = loadData(key);
valueBuffer[tag]=loadedData;
keyBuffer[tag]=key;
return loadedData;
}
else
{
valueBuffer[tag]=*value;
keyBuffer[tag]=key;
return *value;
}
}
else {
if(opType == 1)
{
isEditedBuffer[tag]=1;
}
if(opType == 0)
{
const CacheValue && loadedData = loadData(key);
valueBuffer[tag]=loadedData;
keyBuffer[tag]=key;
return loadedData;
}
else {
valueBuffer[tag]=*value;
keyBuffer[tag]=key;
return *value;
}
}
}
}
CacheValue const accessDirect(const CacheKey & key,const CacheValue * value,
const bool opType = 0)
{
InternalKeyTypeInteger tag = key & sizeM1;
if(keyBuffer[tag] == key)
{
if(opType == 1)
{
isEditedBuffer[tag]=1;
valueBuffer[tag]=*value;
}
return valueBuffer[tag];
}
else {
CacheValue oldValue = valueBuffer[tag];
CacheKey oldKey = keyBuffer[tag];
if(isEditedBuffer[tag] == 1)
{
if(opType==0)
{
isEditedBuffer[tag]=0;
}
saveData(oldKey,oldValue);
if(opType==0)
{
const CacheValue && loadedData = loadData(key);
valueBuffer[tag]=loadedData;
keyBuffer[tag]=key;
return loadedData;
}
else
{
valueBuffer[tag]=*value;
keyBuffer[tag]=key;
return *value;
}
}
else {
if(opType == 1)
{
isEditedBuffer[tag]=1;
}
if(opType == 0)
{
const CacheValue && loadedData = loadData(key);
valueBuffer[tag]=loadedData;
keyBuffer[tag]=key;
return loadedData;
}
else {
valueBuffer[tag]=*value;
keyBuffer[tag]=key;
return *value;
}
}
}
}
private:
const CacheKey size;
const CacheKey sizeM1;
std::vector<std::mutex> mut;
std::vector<CacheValue> valueBuffer;
std::vector<unsigned char> isEditedBuffer;
std::vector<CacheKey> keyBuffer;
const std::function<CacheValue(CacheKey)> loadData;
const std::function<void(CacheKey,CacheValue)> saveData;
};
#endif /* DIRECTMAPPEDMULTITHREADCACHE_H_ */
N Way Set Associative Multi-Thread Cache
N-way set associative cache is a middle point between a direct-mapped cache and a fully-associated (LRU) cache. It has multi-thread scalability of direct-mapped cache and is close to cache-hit-ratio characteristics of LRU cache (source). When used alone, it has cache-coherency. This makes writes+reads be visible between all accesses through getThreadSafe/setThreadSafe methods (for single thread, only set/get is enough).
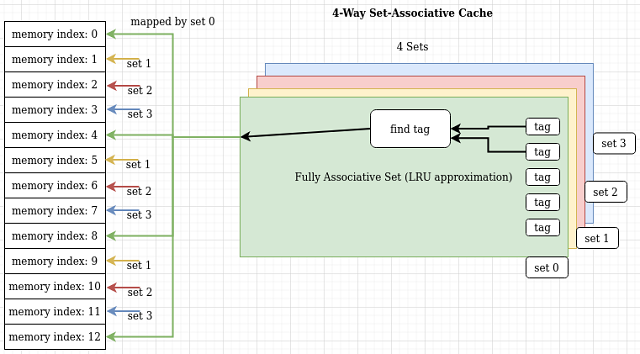
#ifndef NWAYSETASSOCIATIVEMULTITHREADCACHE_H_
#define NWAYSETASSOCIATIVEMULTITHREADCACHE_H_
#include<vector>
#include<memory>
#include<functional>
#include"LruClockCache.h"
template<typename CacheKey, typename CacheValue, typename CacheHandInteger=size_t>
class NWaySetAssociativeMultiThreadCache
{
public:
NWaySetAssociativeMultiThreadCache(size_t numberOfSets, size_t numberOfTagsPerLRU,
const std::function<CacheValue(CacheKey)> & readMiss,
const std::function<void(CacheKey,CacheValue)> &
writeMiss):numSet(numberOfSets),numSetM1(numberOfSets-1),
numTag(numberOfTagsPerLRU)
{
for(CacheHandInteger i=0;i<numSet;i++)
{
sets.push_back(std::make_shared<LruClockCache<CacheKey,
CacheValue,CacheHandInteger>>(numTag,readMiss,writeMiss));
}
}
const CacheValue get(CacheKey key) const noexcept
{
CacheHandInteger set = key & numSetM1;
return sets[set]->get(key);
}
void set(CacheKey key, CacheValue value) const noexcept
{
CacheHandInteger set = key & numSetM1;
sets[set]->set(key,value);
}
const CacheValue getThreadSafe(CacheKey key) const noexcept
{
CacheHandInteger set = key & numSetM1;
return sets[set]->getThreadSafe(key);
}
void setThreadSafe(CacheKey key, CacheValue value) const noexcept
{
CacheHandInteger set = key & numSetM1;
sets[set]->setThreadSafe(key,value);
}
void flush()
{
for(CacheHandInteger i=0;i<numSet;i++)
{
sets[i]->flush();
}
}
private:
const CacheHandInteger numSet;
const CacheHandInteger numSetM1;
const CacheHandInteger numTag;
std::vector<std::shared_ptr<LruClockCache<CacheKey,CacheValue,CacheHandInteger>>> sets;
};
#endif /* NWAYSETASSOCIATIVEMULTITHREADCACHE_H_ */
Since this is made of multiple LRU-approximation instances, its random-access and sequential-access performances are same (not as good as 5x sequential access performance of DirectMappedMultiThreadCache) and is higher than 70M cache-hit lookups per second for 3.6GHz FX8150 while retaining better cache-hit-ratio than direct-mapped version. For a Minecraft world with a player creating & destroying blocks in 3-dimensions, this would mean supporting 60 frames per second performance when visible world size is 200x20x200 blocks.
Achieving Multi-Threaded Cache-Coherence On Two-Level Cache
To have proper ordering and visibility of data between threads, caches either need invalidation or single-point of entrance per key or single-point of entry per cache layer. Hardware world may have efficient pipelines between caches and single-cycle operations in parallel to maintain coherence but in software there is no shortcut between threads. The data, somehow, has to become explicit for a thread, then computed on it and finally become available to another thread. This is generally a bottleneck when multiple threads try to access same critical section of code. For worst case scenarios like this, the accesses are effectively serialized and become possibly slower than running the same code on single thread. To overcome this issue, accesses can be serialized on a different level of communication where exclusive access per thread is dispersed on a wider area than just 1 item. Producer - consumer pattern partially solves this problem.
In a producer - consumer problem, one or more threads produce data and push it to a queue and one or more consumers pop the data from queue and process it. For inherently active cache coherence, only a single consumer thread is given permission to access the cache (or multi-level cache) and is given serialized get/set stream from multiple producer threads. The serialization synchronization is made only on per-thread instead of per-item. This separates per-key lock-contention from the clients.
Implementation of single consumer - multiple producer cache coherence is relatively easier than implementation of hardware-like cache invalidation technologies. The below image depicts how the source code of AsyncCache works:
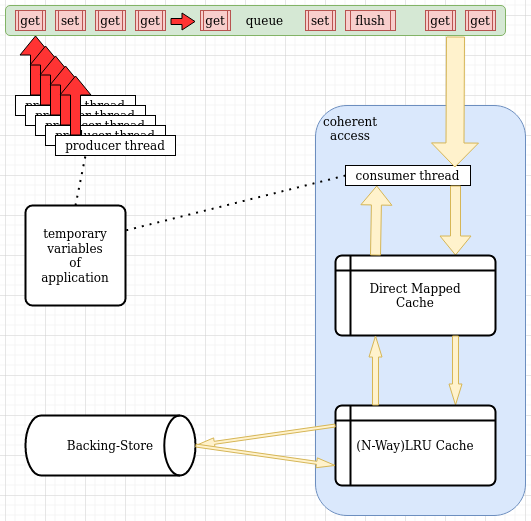
When a thread calls a getAsync / setAsync method of AsyncCache, it adds the get/set command to a dedicated queue of a slot by locking the selected slot. Then the dedicated queue is swapped with an internal-queue of consumer thread again by locking the selected slot. Then the consumer thread directly reads from its own queue without locking. This effectively reduces locking contention by the ratio of number of commands pushed per thread until consumer visits same producer thread's private queue. If a thread pushes 100 command items into its own queue, then the producer thread locks/unlocks for 100 times possibly without even contending with consumer thread. Then the consumer locks-unlocks same slot only for 2 times maximum, 1 for getting the queue, 1 for answering a barrier call (so that an awaiting producer thread can continue). The more keys requested per thread, the closer the performance to the lockless+waitless single-thread cache which is about 75 million lookups per second.
With the efficient producer-consumer model for coherent caching, the fairness between producer threads is maintained in chunks of commands. Ideally, all threads would have fully interleaved queue entrance but due to performance optimizations, the commands are received in chunks. This makes direct thread-to-thread communication inefficient for popular schemes such as:
setAsync(100,..) from thread-1getAsync(100,..) from thread-2, in a spin-wait loop
Here, thread-1's setAsync command and thread-2's getAsync command can be found in same chunk-cycle of consumer thread but if their chunk-processing order is opposite, then always thread-2 is processed first, then thread-1 second. This causes repeated use case inefficient due to forcing thread-2 check the value always 2 times at least. This is one of many latency contributions coming from the "throughput" optimization (with multiple threads):
- The data passes through
thread-1's slot lock to enter private-queue of thread 1. - The data is taken by consumer thread by an extra lock on the same slot.
- Processed data travels inside cache within cache's own latency.
- Result is stored either on the variable pointer given by
thread-1 or on the cache/backing-store. - Consumer thread signals the slot is now barrier-free (completed reads/writes) by another locking on slot.
- (optionally all the other commands issued in the queue by N-2 other threads).
- Asynchronously to the
thread-1: Thread-2 locks its own slot and emplaces its own get command. - Data is taken by consumer thread again, after locking another time on that slot.
- Processed data travels inside cache within cache's own latency.
- Consumer thread signals the barrier by another lock.
- Finally, thread-2 gets the result, after its own slot lock.
At least 7 mutex locks (lock_guard to be specific) and 2 cache accesses (latency depends on locality of reference) are made. This is at least several microseconds of latency if there is only single element to be accessed at a time. But on a massively-parallel system where many items are requested in-flight, this happens tens or hundreds of times at the same time and the resulting average latency (inverse-throughput, not real latency) becomes 12-13 nanoseconds per get/set call.
If the access pattern does not require chain set-->get operations, then the real latency per get or per set is half of the above list. Making 1000 get/set requests and 1 barrier call per producer thread results in 1000 locking with maximum 2 contentions per thread and only 2 consumer thread locking operations with maximum 2 contention. Then a CPU with 8 threads can have 8 locks at a time at best. This makes similar throughput to a single-thread lock contention performance per thread and the consumer thread becomes the bottleneck as it has to do the book-keeping such as swapping queues, selecting command logic and doing 1-2 locking per chunk.
Another way of maintaining coherence is sharding. With sharding, locking is made per-key or per-set instead of slot/thread:
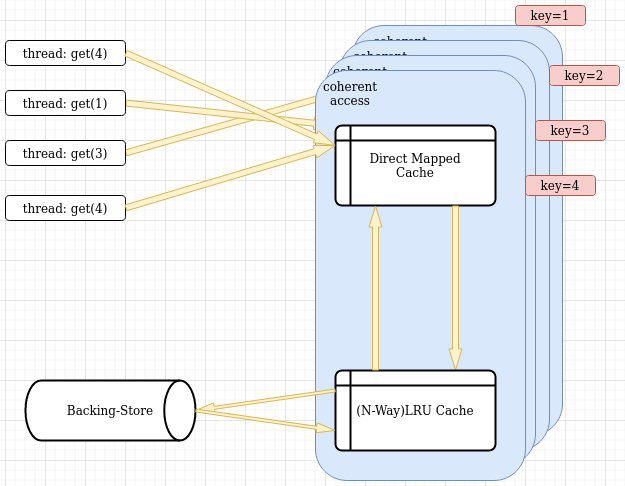
(Image showing the key-based locking-contention for get(4) method call from two threads)
Per-key locking has downside of very high locking contention when all threads access same key. On the other hand, a dispersed access pattern between all threads becomes fully parallel and the real latency per key access becomes much better than producer-consumer version. A 128 core CPU may have 128 best-case parallelism, possibly surpassing producer-consumer model's performance many times over with sharding, but is also much worse when all 128 threads access same key. The main advantage of sharding is its applicability. A sharded cache just works even with another sharded cache on top of it, as a multi level cache. The source code of MultiLevelCache has an implementation of sharding on multi-level cache. Direct mapped cache is given sharded key-access and n-way set-associative cache is given sharded set-access. Both are connected to each other in a simple & thread-safe way. Any two threads accessing same key (or same set in L1--cache-miss) makes lock-contention. But is easy to read, implement, scale on more cores of CPU. This way of coherence only needs to evade same-key accesses from multiple threads at the same time.
Usage of MultiLevelCache class:
std::vector<int> data(1024*1024);
MultiLevelCache<int,int> cache(L1tags,L2sets,L2tagsPerSet,
[&](int key){ return data[key]; },
[&](int key, int value){ data[key]=value;}
);
#pragma omp parallel for
for(int i=0;i<1000;i++)
cache.setThreadSafe(i,0);
cache.flush();
The for loop in this example makes 1000-way parallelism as long as there are enough CPU cores and L1 tags or 8-way parallelism for FX8150 CPU.
Usage of AsyncCache class:
std::vector<int> data(1000000);
AsyncCache<int,int> cache(L1tags,L2sets,L2tagsPerSet,
[&](int key){ return data[key]; },
[&](int key, int value){ data[key]=value; }
);
int val;
int slot = cache.setAsync(5,100);
cache.getAsync(5,&val,slot);
computeStuff();
std::cout<<data[5]<<" "<<val<<std::endl;
cache.barrier(slot);
std::cout<<data[5]<<" "<<val<<std::endl;
cache.flush();
std::cout<<data[5]<<" "<<val<<std::endl;
2D/3D Direct Mapped Cache
Plain direct mapped cache's tag collisions make it hard to have a good cache-hit-ratio on many patterns. But it can be optimized for specific scenarios. On image processing and 2D matrix-matrix multiplication algorithms, iterating on a dimension makes more tag collisions (hence the cache misses) than the other dimension. Having a 2D/3D tag array and independently mapping on each dimension makes it retain some of cache contents during tiled-processing of images. For matrices, this is equivalent to multiplying submatrices.
From the source code of multi-dimensional direct mapped cache, there is only a slight difference in mapping calculation:
CacheKey tagX = keyX & sizeXM1;
CacheKey tagY = keyY & sizeYM1;
Same computation but on two dimensions, for 2D tag array. Its hit-ratio characteristics was visually tested on a Minecraft-like game engine which translates into higher performance that was benchmarked in a terrain-generator engine.
Multi-dimensional direct-mapped cache works worse than normal direct mapped cache when accessing pattern is single dimensional but becomes orders of magnitude better in a tiled-access pattern when indexed backing-store is many times bigger than cache size. Having a 100000x100000 matrix makes 100% cache miss on a 100000 sized direct mapped cache during tiled-processing of a 16x16 region. Using a 16x16 2D direct mapped cache (just 256 sized) increases cache hit ratio to at least 50% or more depending on re-use ratio of elements.
When Not to Use a Custom Cache
There are cases when a system function easily surpasses the performance of a custom algorithm. One example is accessing a big file through a mmap region and not caring if whole RAM is used. The mmap function uses system-specific caches and compiler's features (CPU caches, vectorization, paged access, etc.) and it is nearly as fast as using simple variables in C++. No custom cache will beat its performance. Here is a comparison in random-access pattern with an N-way Set-Associative Cache:
int fd = open("output_image_scaling256.ppm", O_RDONLY);
struct stat file_info;
fstat (fd, &file_info);
char * mmap_addr = (char *) mmap(NULL, file_info.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
auto cacheLLC = std::make_shared<NWaySetAssociativeMultiThreadCache<size_t,char>>(128,
[&](const size_t & key){
return mmap_addr[key];
},
[&](size_t key, char value){ }
);
const int datasetSize = file_info.st_size/10;
const int numThread = 8;
const int numAccess = 1000000;
const int numRepeat = 200;
std::random_device rd;
std::mt19937 rng(rd());
std::uniform_real_distribution<float> rnd(0,datasetSize);
std::vector<int> r(20000000);
for(int i=0;i<datasetSize;i++)
r[i]=rnd(rng);
std::string result;
for(int j=0;j<5;j++)
{
{
CpuBenchmarker bench(numAccess*numThread*numRepeat,
"mmap",numAccess*numThread*numRepeat);
#pragma omp parallel for
for(int ii=0;ii<numThread;ii++)
{
size_t ct=0;
for(int j=0;j<numRepeat;j++)
for(int i=0;i<numAccess;i++)
{
ct += mmap_addr[r[i]];
}
result += std::to_string(ct)+" ";
}
}
{
CpuBenchmarker bench(numAccess*numThread*numRepeat,"cached mmap",
numAccess*numThread*numRepeat);
#pragma omp parallel for
for(int ii=0;ii<numThread;ii++)
{
size_t ct2=0;
CacheThreader<NWaySetAssociativeMultiThreadCache,size_t,char>
cache(cacheLLC,1024*1024,1024*1024*2);
for(int j=0;j<numRepeat;j++)
for(int i=0;i<numAccess;i++)
{
ct2 += cache.get(r[i]);
}
result += std::to_string(ct2)+" ";
}
}
}
std::cout<<result<<std::endl;
munmap (mmap_addr, file_info.st_size);
close (fd);
This code snippet compares direct mmapped region access versus cached mmapped access and the result is mmap wins by a far margin, as expected:
mmap: 452761856 nanoseconds (bandwidth = 3533.87 MB/s)
(throughput = 0.28 nanoseconds per iteration)
cached mmap: 3127557924 nanoseconds (bandwidth = 511.58 MB/s)
(throughput = 1.95 nanoseconds per iteration)
mmap: 478753028 nanoseconds (bandwidth = 3342.02 MB/s)
(throughput = 0.30 nanoseconds per iteration)
cached mmap: 3022541644 nanoseconds (bandwidth = 529.36 MB/s)
(throughput = 1.89 nanoseconds per iteration)
mmap: 441924232 nanoseconds (bandwidth = 3620.53 MB/s)
(throughput = 0.28 nanoseconds per iteration)
cached mmap: 2937497135 nanoseconds (bandwidth = 544.68 MB/s)
(throughput = 1.84 nanoseconds per iteration)
mmap: 423980321 nanoseconds (bandwidth = 3773.76 MB/s)
(throughput = 0.26 nanoseconds per iteration)
cached mmap: 2905986572 nanoseconds (bandwidth = 550.59 MB/s)
(throughput = 1.82 nanoseconds per iteration)
mmap: 493596405 nanoseconds (bandwidth = 3241.51 MB/s)
(throughput = 0.31 nanoseconds per iteration)
cached mmap: 2911731956 nanoseconds (bandwidth = 549.50 MB/s)
(throughput = 1.82 nanoseconds per iteration)
The mmap is at least 6 times faster, despite the 550 M random-lookups per second performance of custom cache. Hardware cache nearly always wins against software-side cache as the software version always depends on the hardware. But there is a catch. Mmap RAM usage is controlled by OS. If whole RAM is not to be used for file caching, then it can be limited by a custom cache, like the N-way Set-Associated multi thread cache instance in the code snippet.
Another case when there is no need for caching is, not re-using accessed elements. Simply parsing a file once, iterating an array once, anything that costs less than allocating a custom cache does not require a cache. One example of high re-use ratio is matrix-matrix multiplication. Every element in matrix is accessed for N times which makes bigger matrices have better re-use ratios. When computed with tiled-multiplication, it works even better for caching.
Sometimes, even just using a temporary variable works good. Then there is no need to add latency by an unnecessary cache layer (unless number of temporary variables can grow in future, bigger than RAM).
Sometimes, a backing store is so slow (website resources) that using a C++-optimized cache is an overkill. Using a JavaScript-based cache implementation works fast enough for caching video chunks, HTML pages and CSS files.
Sometimes, the data is so sensitive that it should be protected against timing-attacks. For such issues, any source of deterministic time-variation should be elliminated. LRU and all other time-saving algorithms are susceptible to such attacks and even random-eviction is not a real solution besides just making it harder to hack.
When to Use a Custom Cache
- Having enough data re-use ratio for items from a slow-enough backing-store that makes it slower than accessing RAM
- Requirement of limiting RAM usage for a big dataset
- For learning purposes
- Requirement of stability in access timing (when accessing X region of data store is slower than Y region)
- Memorization of medium-latency (~20 nanoseconds to a microsecond) tasks with limited memory budgets such as zooming-back to a previous frame in a mandelbrot-set generator or moving inside Minecraft world or accelerating access to an in-memory database
A video demonstrating 160x performance gain by caching, on a procedural terrain generation application despite the issues in usage pattern:
- Cache was not used everywhere the same data needed. Only on rendering part and it had only 1 as re-use ratio on each terrain-generation. This made CPU cache not effective enough.
- Data type was double precision float and it had certain bandwidth toll on single-channel memory computer when data was not re-used.
- Index (key) calculations had extra latency on top of
cache.get() calls
Effect Of CPU Caches
Since software cache's tags/slots/sets are kept in memory, they are cached by CPU. It is important to use the cache in as many places as possible to stop CPU caches being thrashed. For extra performance, cache output for some elements can be stored in a temporary variable but storing 50% - 100% of whole cache content in an array causes CPU cache to evict software cache to serve the temporary array. Then the next time the software cache is used, it comes from next level of CPU cache or even RAM.
Additionally, using very big software cache is not good for CPU caches. Anything that traverses whole cache content (of 100MB, 500MB, etc. sized) also evicts all elements from CPU cache. This makes it much slower unless there are enough memory accesses in-flight.
If size of software cache is bigger than RAM, it causes an increase on swap-file usage and if an element to be accessed from software cache is inside swap-file (not RAM, by OS choice), then a cache-hit becomes worse than a cache-miss because getting the data has to evict something else to the swap-file and that evicted data could be the next element in the cache that would be a cache-hit. Then it causes a chain cache-miss reaction on the swap-file which is very unfortunate for an app that requires performance stability.
For a better optimization, L1 software cache can be sized to fit CPU L1 cache, L2 software cache can be sized to fit CPU L2 cache and LLC software cache can be sized to fit CPU LLC. This can potentially make less cache contention on CPU side due to not mixing different software caches in L1 CPU cache.
To get the most performance out of a cache, the user should think about CPU's capabilities such as prefetching, SIMD computing and similar features. If each elements are accessed only to be grouped into vectors of 8 elements, then the cache should be used to gather them in groups and serve CPU SIMD architecture better.
Points of Interest
With low latency access, the multi-threaded read-only direct-mapped cache could be used to read static world data from game folder and distributed to threads of game logic to update graphics or other game states without depending on HDD/SSD/procedural_generation_computation 100% of the time. Even with a lone DirectMappedMultiThreadCache instance shared with all threads, it should decrease number of HDD accesses several times at least.
With LRU caching, also fast databases like Redis could be cached on client-side without requiring extra setup on Redis side.
With value types much bigger than an int, memory efficiency would be maxed with relatively few iterations. For example, a virtual memory paging simulation application can cache the pages (of 4kB,64kB,1MB each) before directly writing/reading files on disks (or video-memory if it is a video-memory backed RAMDISK).
With any unknown pattern of access (like accessing database as soon as a client requests), performance per thread drops. This may be further optimized by pooling the requests for an interval and computing them all at once.
In future, read+write capability for a multi-level cache can be implemented by atomic access to "isEdited" fields of each private cache's tags similar to what CPU caches are doing. But this could decrease overall performance per thread and scaling. Also other topologies like " DirectMappedMultiThreadedCache in front of LruClockCache using only setThreadSafe and getThreadSafe methods" can be tested for scaling.
History
- 11th October, 2021
- Started article with basic microbenchmarking and tested on various access patterns
- 15th October, 2021
- Added N-way set-associative cache for multithreaded cache-coherence
- Added an example case about when not to use a custom cache while showing the performance of n-way set-associative cache
- 17th October, 2021
- Added video on "when to use a cache" section.
- Fixed video error, added description for video
- Added effect of CPU caches section
- 29th October, 2021
- Added multi-level cache-coherency implementation by producer-consumer model
- Added multi-level cache-coherency implementation by binding two coherent sharded caches together
- Added 2D/3D direct mapped cache implementation
- Added images (to: "clock second chance algorithm", "achieving cache coherence on two level cache", "direct mapped cache", "multi level cache", "image processing (gaussian blur)", "n-way set-associative multi-thread cache" sections)

