Demand for high-performance deep learning (DL) training is accelerating with the growing number of applications and services based on image and gesture recognition in videos, speech recognition, natural language processing, recommendation systems, and more. The Habana® Gaudi® AI processor is designed to maximize training throughput and efficiency, while providing developers with optimized software and tools that scale to many workloads and systems. Habana Gaudi software was developed with the end user in mind, providing versatility and ease of programming to address the unique needs of users’ proprietary models, while allowing for a simple and seamless transition of their existing models to Gaudi. We want to get you started with Habana’s Gaudi HPU (Habana processor unit). There are many new and existing users who may have experience running workloads on a GPU or CPU, and the goal of this article is to take you through the process of migrating your existing AI workloads and models over to the Gaudi HPU. We’ll introduce you to the basics of the hardware architecture, the software stack, and the tools needed to get your models running on Gaudi.
Gaudi Architecture and Habana SynapseAI® Software Suite
We’ll start with an overview of the basic architecture. Gaudi is designed from the ground up to accelerate DL training workloads. Its heterogeneous architecture comprises a cluster of fully programmable Tensor Processing Cores (TPC) along with its associated development tools and libraries, plus a configurable Matrix Math engine.
The TPC is a VLIW SIMD processor with instruction set and hardware tailored for training workloads. It is programmable, providing the user with maximum flexibility to innovate, coupled with many workloadoriented features, such as:
- GEMM operation acceleration
- Tensor addressing
- Latency hiding capabilities
- Random number generation
- Advanced implementation of special functions
The TPC natively supports the following data types: FP32, BF16, INT32, INT16, INT8, UINT32, UINT16, and UINT8.
The Gaudi memory architecture includes on-die SRAM and local memories in each TPC. In addition, the chip package integrates four HBM devices, providing 32 GB of capacity and 1 TB/s bandwidth. The PCIe interface provides a host interface and supports both generation 3.0 and 4.0 modes.
Gaudi is the first DL training processor that has integrated RDMA over Converged Ethernet (RoCE v2) engines on-chip. With bi-directional throughput of up to 2 Tb/s, these engines play a critical role in the inter-processor communication needed during the training process. This native integration of RoCE allows customers to use the same scaling technology, both inside the server and rack (scale-up), as well as to scale across racks (scale-out). These can be connected directly between Gaudi processors, or through any number of standard Ethernet switches. Figure 1 shows the hardware block diagram:

Figure 1. Gaudi HPU block diagram
Designed to facilitate high-performance DL training on Habana’s Gaudi accelerators, the SynapseAI software suite enables efficient mapping of neural network topologies onto Gaudi hardware. The software stack includes Habana’s graph compiler and runtime, TPC kernel library, firmware and drivers, and developer tools such as the TPC SDK for custom kernel development and SynapseAI Profiler. SynapseAI is integrated with popular frameworks, TensorFlow and PyTorch, and performance-optimized for Gaudi. Figure 2 shows the components of the SynapseAI software suite. To easily integrate the SynapseAI software into your working environment, Habana provides a set of Docker images for TensorFlow and PyTorch that includes all the ingredients needed to create the environment to run your models. We’ll explore how to integrate these libraries into your models.
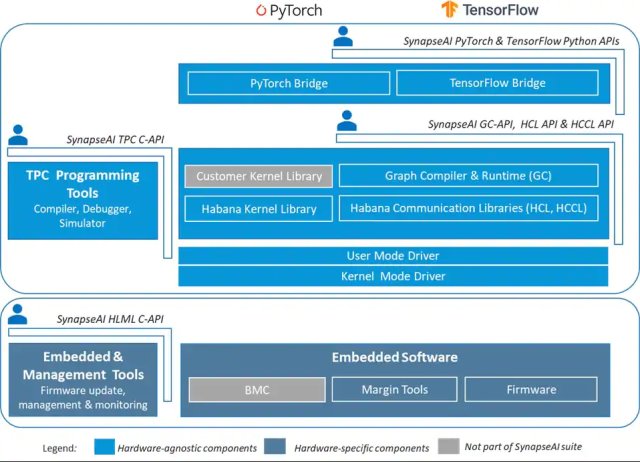
Figure 2. SynapseAI Software Stack
Setting up the Environment
In this section, we address how to set up the environment, and then add the simple steps needed to ensure that the Gaudi HPU is recognized by the framework and can start to execute ops in your model. In addition to the Docker images, Habana also has a set of reference models and examples in our ModelReferences GitHub repository that can be used as guides to add the proper components to your models.
The first step to getting started is to ensure you have a full build environment, which includes the Habana driver, SynapseAI software stack, and framework. In most cases, the best way to ensure that this full environment is created is to use the pre-built Docker images provided by Habana, which are available in our Software Vault. These Docker images contain both single-node and scale-out binaries and do not require additional installation steps. If you are using Gaudi in a cloud-based environment, be sure to select a Habana Gaudi image provided by your cloud service provider that contains the full driver and associated framework. For those who need to perform an installation of the full driver and SynapseAI software stack independently (as an on-premise installation), you can refer to the dedicated Setup and Install GitHub repository for detailed instructions. The second step is to load the Habana libraries and target the Gaudi HPU device. We’ll explain how to do this for both TensorFlow and PyTorch in the next section
Getting Started with TensorFlow
For TensorFlow, Habana integrates the TensorFlow framework with SynapseAI in a plugin using tf.load_library and tf.load_op_library calling library modules and custom ops/kernels. The framework integration includes three main components:
- SynapseAI helpers
- Device
- Graph passes
The TensorFlow framework controls most of the objects required for graph build or graph execution. SynapseAI allows users to create, compile, and launch graphs on the device. The Graph passes library optimizes the TensorFlow graph with operations of Pattern Matching, Marking, Segmentation, and Encapsulation (PAMSEN). It is designed to manipulate the TensorFlow graph to fully utilize Gaudi’s hardware resources. Given a collection of graph nodes that have implementations for Gaudi, PAMSEN tries to merge as many graph nodes as possible while maintaining graph correctness. By preserving graph semantics and automatically discovering subgraphs that can be fused into one entity, PAMSEN delivers performance that should be on par with (or better than) native TensorFlow.
To prepare your model, you must load the Habana module libraries. Call load_habana_module() located under library_loader.py. This function loads the Habana libraries needed to use Gaudi HPU at the TensorFlow level:
import tensorflow as tf
from habana_frameworks.tensorflow import load_habana_module
load_habana_module()
tf.compat.v1.disable_eager_execution()
There are some specific requirements when running legacy (TF1.x) models, and the requirements differ when using Horovod for multicard and multinode training. If you are running TF2.x models on a single card, the last statement is not needed.
Once loaded, the Gaudi HPU is registered in TensorFlow and prioritized over CPU. This means that when a given op is available for both CPU and the Gaudi HPU, the op is assigned to the Gaudi HPU. After the initial model migration is completed using the steps above, you can start to look at integration of Habana ops and custom TensorFlow ops as defined in the habana_ops object. It can be imported with the command: from habana_frameworks.tensorflow import habana_ops. It should only be used after load_habana_module() is called. The custom ops are used for pattern matching to standard TensorFlow ops. When the model is ported to the Gaudi HPU, the software stack decides which ops are placed on the CPU and which are placed on the Gaudi HPU. The optimization pass automatically places unsupported ops on the CPU.
Once these steps are completed in your model, you will be able to run it on a Gaudi HPU instance. Below is a simple example showing how an MNIST model is enabled for Gaudi. (The minimal changes required are highlighted in bold.):
import tensorflow as tf
from TensorFlow.common.library_loader import load_habana_module
load_habana_module()
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(10),
])
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
model.compile(optimizer=optimizer, loss=loss, metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5, batch_size=128)
model.evaluate(x_test, y_test)
Getting Started with PyTorch
The PyTorch Habana bridge interfaces between the framework and SynapseAI software stack to drive the execution of deep learning models on the Habana Gaudi device (Figure 3). The installation package provided by Habana comes with modifications on top of the standard PyTorch release and are included in the Docker images provided by Habana. The customized framework from this installed package needs to be used to integrate PyTorch with the Habana bridge. In this case, you will modify the PyTorch deep learning model training scripts by loading the PyTorch Habana plugin library and import habana_frameworks.torch.core module to integrate with Habana Bridge.
Execution of PyTorch models on the Gaudi HPU has two main modes that are supported by Habana PyTorch:
- Eager mode – op-by-op execution as defined in standard PyTorch eager mode scripts.
- Lazy mode – deferred execution of graphs, comprised of ops delivered from script Op by Op like Eager mode. It gives the Eager mode experience with performance on Gaudi.
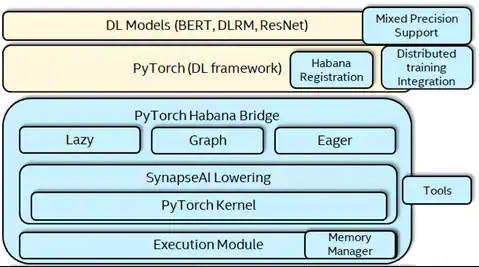
Figure 3. PyTorch Habana Full Stack Architecture
In general, it is recommended that initial model development should be run in Eager mode to establish functionality, then run in Lazy mode for best performance. This can be selected by setting a runtime flag (as shown in step 5 below).
The following set of code additions are required to run a model on Habana. The following steps cover Eager and Lazy modes of execution.
1. Load the Habana PyTorch Plugin Library, libhabana_pytorch_plugin.so.
import torch
from habana_frameworks.torch.utils.library_loader import load_habana_module
load_habana_module()
2. Target the Gaudi HPU device:
device = torch.device("hpu")
3. Move the model to the device:
model.to(device)
4. Import the Habana Torch Library:
import habana_frameworks.torch.core as htcore
5. Enable Lazy execution mode by setting the environment variable shown below. Do not set this environment variable if you want to execute your code in Eager mode:
os.environ["PT_HPU_LAZY_MODE"] = "1"
6. In Lazy mode, execution is triggered wherever data is read back to the host from the Habana device. For example, execution is triggered if you are running a topology and getting loss value into the host from the device with loss.item(). Adding a mark_step() in the code is another way to trigger execution:
htcore.mark_step()
The placement of mark_step() is required at the following points in a training script:
- Right after
optimizer.step() to cleanly demarcate training iterations, - Between
loss.backward and optimizer.step() if the optimizer being used is a Habana custom optimizer.
When the model is ported to run on Gaudi HPU, the software stack decides which ops are placed on CPU and which are placed on the HPU. This decision is based on whether the op is registered with PyTorch with HPU as the backend. Execution of an op automatically falls back to the host CPU if the op is not registered with its backend as an HPU.
Habana provides its own implementation of some complex PyTorch ops customized for Habana devices. In a given model, replacing these complex ops with custom Habana versions will give better performance.
The following is a list of custom optimizers currently supported on Habana devices:
Conclusion
The goal of this article was to take you through the process of migrating your existing deep learning models over to Gaudi and show the basic steps to get your model ready to run. Please keep watching the main website, Habana.ai, for product launch announcements and sign up to our interest list to get notified of upcoming activities.
Useful Resources
- Developer site is the best place to get started. This will have pointers to our models, documentation, and other resources.
- Habana Documentation has all the detailed collateral, especially the Migration Guide.
- Habana Vault is the place to download the latest drivers and Docker images.
- User Forum is the place for community discussion of all things related to Habana and Gaudi.
Sign up for future issues of The Parallel Universe 6.

