Take your screens to the next level with the techniques presented here, and present a fresh modern look to the users of your device.
Introduction
With most of the hobbyist IoT widgets out there, the screens look especially dated. There are blocky raster fonts, a conspicuous absence of images, and usually very few colors, or too many that don't mesh. Some of this is simply poor design, but most of it is due to limitations of existing graphics libraries - limitations GFX was in part designed to solve.
We'll be covering things other than those specific to GFX or even graphics generally. Professional apps are usually non-trivial, and the ESP32 WROVER - while powerful for an IoT MCU - is not exactly an ace performer in the big scheme of things. It's just a tiny little thing, and these apps tend to push the limits of what they are capable of. This can sometimes mean getting creative, and we cover some of that here.
Running this Mess
You'll need VS Code with Platform IO.
You'll need an ESP32 WROVER probably. I've tried to find other MCUs with comparable features, but I've come up empty so far. You might be able to get away with something like an RTL8720DN BW16-Kit with an external PSRAM chip wired up to the SPI bus, but it will be slower than the WROVER and in my experience, they are harder to find. I'm having one shipped to me out of Asia, and as of this writing, it's about 3 weeks away. I haven't tested GFX on one yet, but in theory, it will run on devices besides the ESP32. It's just that other MCUs don't typically have the necessary RAM and CPU power, especially of the ESP32 WROVER. You can get away with this on a WROOM, sort of but without the extra RAM, your mileage may vary. It will be anywhere from somewhat to a lot slower than it can be on a WROVER, particularly for drawing text.
You'll need a compatible display. I like the RA8875 hooked up to an 800x480 screen because of the size and resolution, and because it has touch, but you can get away with pretty much anything, even e-paper, although with e-paper you're generally dealing with monochrome or a handful of colors at most. The demo works with an ILI9341 or an RA8875, but you can use other drivers. There are many included with the GFX demo.
Lastly, you'll need GFX and the appropriate driver. The master project linked to at the top of the article includes GFX and two drivers while the GFX Demo link I just presented has more drivers.
We'll be exploring these techniques with the Arduino framework, although most of it is directly transferable to the ESP-IDF.
Note: Don't forget to upload the filesystem image before you attempt to use this. The assets must be available on the SPIFFS partition or nothing will work.
Creating Your Environment
Assuming a WROVER, you'll want your platformio.ini file to look something like this:
[env:Default]
platform = espressif32
board = node32s
board_build.partitions = no_ota.csv
framework = arduino
upload_speed = 921600
monitor_speed = 115200
build_unflags = -std=gnu++11
build_flags = -std=gnu++14
-DBOARD_HAS_PSRAM
-mfix-esp32-psram-cache-issue
I've found the board = node32s line tends to work with all ESP32 variants, while no_ota.csv (below) kills over the air update partition, giving you more SPIFFS and program space. The build flags are there so GFX will build properly, and so the framework will be aware of the extra PSRAM on the WROVER.
Here's the no_ota.csv file:
# Name, Type, SubType, Offset, Size, Flags
nvs, data, nvs, 0x9000, 0x5000,
otadata, data, ota, 0xe000, 0x2000,
app0, app, ota_0, 0x10000, 0x200000,
storage, data, spiffs, 0x210000,0x1F0000,
You can adjust the partition sizes to fit your specific needs, but this gives you more room.
Using GFX
You'll want to get up to speed using GFX and understanding the basics like draw sources and draw destinations, using rect16s vs srect16s, using bitmap<> templates etc. You can look at the demo code for plenty of examples, and this article for general coverage. I won't be covering the fundamentals here.
Choosing a "Theme" and Assets
With GFX, you can build your screens using True Type/Open Type fonts, JPEGs, and the full X11 color palette (or your own user defined colors).
Due to this, you're going to want to get a handle on the overall color scheme, any prominent logos or icons, and the set of fonts you intend to use.
Don't use assets like fonts that ship with your operating system, as in many cases those are copyrighted and restricted in terms of you using them in your own projects. I've had good luck finding fonts at Font Squirrel.
Don't go crazy with these assets, as you have limited space, and you have to choose what you display and when carefully so as not to bog down your device.
Generally, you'll want a minimalist appearance, particularly with one whose text does not frequently animate (aside from say a few fields once a second, or even one field 10 times a second)
Text is hungry, both in terms of RAM and flash space requirements, and in terms of CPU requirements. This is why I went out of my way to mention it above. If you're careful, and you design your screens well, you can work with an ESP32 to handle most real world scenarios, but you have to have forethought in your design. You have to be frugal in your use of text, and the frequency of your text draws.
JPEGs are loaded progressively due to memory constraints, so larger JPEGs will visibly load left to right top to bottom if loaded directly to the display device. It's best to use small JPEGs because of that. You cannot resize JPEGs with GFX so you must store them at the size you wish to display them, although GFX can crop.
Timing Your Code
You're almost certainly going to need to time parts of your code. If you're using delay(), you are interfering with the responsiveness of your application. Instead, consider using the following technique:
First, you declare an (often global) uint32_t timestamp for whatever it is you wish to time.
Second in some larger loop, you're trying to time something inside of (whether it's the loop() function, which you shouldn't use but we'll cover that later, or whether it's something else), you'll do something like the following:
if(millis() - timestamp >= 1000) {
timestamp = millis();
}
Instead of:
delay(1000);
The reason you want to do this is because delay() halts the current thread of execution, and your CPU could be using that time to do useful work instead of just waiting around. Many of the things we will be doing require you to keep a primary loop active and spinning, and sticking delay()s in it will cause your app to stutter.
The Stack Monster
In practice, the ESP32 isn't very generous with the stack space you get. You can configure it, but out of the box, you have to be very careful with how many and the sizes of your local variables and particularly arrays and structures.
I know everyone frowns on globals, but with IoT code don't. Globals are your friend here. Your app is never going to be large enough where you'll run into such bad globals pollution that you can't find your way around.
One particularly notorious offender in terms of stack size is the Arduino File object. The thing is huge! What I do, is I declare one globally, and then I simply use it in each of my functions as I need it, recycling it each time I need to open a file. I almost never need more than one file open at once so this works, but if I did, I'd just declare two file objects globally. You get the picture.
Don't Use the loop() Function!
Just don't. The issue is that on the ESP32's implementation of the Arduino framework, a second FreeRTOS "task" (read thread) is created with a miserly stack size, and loop() is run on that thread, so trying to do anything non-trivial inside loop() will probably blow up your stack and cause a reboot.
Instead, spin a while() loop inside setup() and just work with that. If anyone can tell me a good reason not to do things this way, you let me know. Otherwise, I will continue to recommend this in order to gain access to the primary thread's much more generous stack.
Dispatch Instead of Nesting
It might be tempting to call the render code from inside one screen to change to another screen in response to the user pressing a button, or perhaps even touching the screen. Don't. The stack monster will end up eating your code.
For example, don't do this:
static void screen_first_screen() {...
screen_second_screen();
}
The reason being is the stack burden. You'll have to hold the locals for both routines on the stack instead of just one at a time.
Instead, create a global that holds your current screen, and your old screen. Then in your main application loop - that is, the loop that you use instead of loop() you will use those variables to determine when to draw the next screen. It looks something like this:
enum struct screens {
initializing = 0,
start,
calibration1,
calibration2,
settings,
session1,
session2,
session3,
summary
};
static screens screen_current;
static screens screen_old;
In your application's main loop, you would have something like this:
if(screen_current!=screen_old) {
screen_old = screen_current;
switch(screen_current) {
case screens::initializing:
screen_current=screens::start;
break;
case screens::start:
screen_start();
break;
case screens::settings:
screen_settings();
break;
case screens::calibration1:
screen_calibration1();
break;
case screens::calibration2:
screen_calibration2();
break;
case screens::session1:
screen_session1();
break;
case screens::session2:
screen_session2();
break;
case screens::session3:
screen_session3();
break;
case screens::summary:
screen_summary();
break;
default:
break;
}
}
Each of the invoked routines above will render the given screen.
Any time you want to change screens, you simply set screen_current to your new screen, and then exit the current subroutine. The change will be picked up in the next iteration of your application's main loop.
If this seems like an unnecessary complication, it's not. This keeps your stack more shallow than it otherwise would be, because you're not chaining calls from one screen to the next. For most real world applications, this is critical.
Making the Most of Your Memory
In practice, you get about 300kB of usable SRAM upon boot on an ESP32. A WROVER gives you 4MB of PSRAM as well but with some strings - sometimes even more than that but that which you can't use under Arduino which limits you to the first 4MB of PSRAM.
To PSRAM or Not To PSRAM?
The main consideration is in order to use PSRAM, it has to be enabled as a #define which you usually establish using the -D compiler option by way of the build_flags setting in the platformio.ini:
-DBOARD_HAS_PSRAM
-mfix-esp32-psram-cache-issue
The first option establishes that define. The second option fixes an issue with PSRAM on the ESP32 and must always be included when BOARD_HAS_PSRAM is defined.
You'll also want to use ps_malloc() instead of malloc() to do allocations, though you can still free() those pointers.
Much of the time, you'll want to use PSRAM when you need heap. It's less likely to fall victim to crippling fragmentation due to its relative size, and SRAM can hold things like cached code and stack, while PSRAM cannot, so SRAM is precious.
Do not use PSRAM when you need to do DMA transfers from bitmaps to display devices using GFX. If you use draw::bitmap_async<>() directly to a display, it assumes the memory is DMA capable. PSRAM isn't.
Under Arduino, I will usually allocate bitmaps to PSRAM. Under the ESP-IDF, it depends on where that bitmap will be written to - if it will be written to a display device, it goes in SRAM.
Front Loading Assets Into PSRAM
This is the main way to get speed benefits from the WROVER over the WROOM. Essentially what you want to do is take your assets like JPGs and fonts - particularly True Type and Open Type fonts, and load the entire file stream into PSRAM, and then work from that.
For an open_font, it looks like this:
file = SPIFFS.open("/Libre.ttf","rb");
file_stream fs(file);
main_font_buffer_size = (size_t)fs.seek(0,seek_origin::end)+1;
fs.seek(0,seek_origin::start);
main_font_buffer = (uint8_t*)ps_malloc(main_font_buffer_size);
main_font_buffer_size = fs.read(main_font_buffer,main_font_buffer_size);
fs.close();
Above, main_font_buffer and main_font_buffer_size are global variables.
Any time you need to use the font, you can create it from the buffer:
open_font main_font;
const_buffer_stream cbs(
main_font_buffer,
main_font_buffer_size);
open_font::open(&cbs, &main_font);
This will make drawing text using this font orders of magnitude faster than drawing directly from SPIFFS like it normally would if you had simply loaded the font from a file stream. Without doing this, it's not really practical to use True Type on these devices, although you can kind of get away with it if you're willing to embed the TTF or OTF directly into your code as a C++ header file, which makes it faster, but still not as fast as PSRAM. This makes the WROOM a bit impractical for the vector font features of GFX, and it's the primary reason this article expects a WROVER.
You will reap some advantages from JPG loading as well, but not nearly as much, because the decompression still takes a significant percentage of the loading time. In practice, I usually don't front load my JPGs, but if they're small enough, I'll preload them onto bitmaps. We'll get to that, don't worry.
Pre-rendering to Bitmaps
What I mean by pre-rendering to bitmaps is creating bitmaps, drawing to them, and then writing the bitmap itself to the screen.
This is a critical part of creating a professional display because it helps prevent display flickering. You're effectively double buffering the specific portion of the display you intend to draw to.
This becomes even more important when writing text out so that the text can be anti-aliased. Unlike raster fonts, vector fonts are "smoothed" to eliminate the jagged appearance around the edges of curves and diagonals. However, in order to facilitate this, GFX needs to be able to alpha blend. That requires that the destination be able to be readable - that is, act as a draw source as well as a draw destination. Most display drivers for GFX cannot do this, meaning if you write the text directly to the display it will not be "smoothed" and it will appear jagged around the edges. Bitmaps can be both written and read, and can efficiently alpha blend, so they make the perfect destination for a vector font.
In addition, even when drawing from RAM, vector fonts take enough time to draw that it is better to draw them offscreen.
To do that, you'll need to measure the text, allocate the appropriate amount of memory, create the bitmap, fill it with the appropriate background color, then draw the text to it.
Once you have the bitmap, it's easy enough to draw::bitmap<>() to the display itself.
I usually create a couple of functions to do it for me:
static void font_draw(
const char* text,
float scale,
ssize16 textsz,
point16 location,
const open_font& fnt,
typename tft_type::pixel_type color,
typename tft_type::pixel_type backcolor) {
srect16 r = textsz.bounds();
r=r.normalize();
using bmp_type = bitmap<typename tft_type::pixel_type>;
uint8_t* buf = (uint8_t*)ps_malloc(
bmp_type::sizeof_buffer((size16)r.dimensions()));
if(buf==nullptr) return;
bmp_type bmp((size16)textsz,buf);
bmp.fill(bmp.bounds(),backcolor);
draw::text(bmp,
(srect16){0,0,1000,1000},
{0,0},
text,
fnt,
scale,
color);
draw::bitmap(tft,
(srect16)bmp.bounds().offset(location.x,location.y),
bmp,
bmp.bounds());
free(buf);
}
static void font_draw(
const char* text,
float scale,
point16 location,
const open_font& fnt,
typename tft_type::pixel_type color,
typename tft_type::pixel_type backcolor) {
ssize16 sz = fnt.measure_text({1000,1000},{0,0},text,scale);
font_draw(text,scale,sz,location,fnt,color,backcolor);
}
The difference between the first one and the second one is the first one takes a pre-measured ssize16 that indicates the dimensions of the text, as given by measure_text(). That way, you can measure once, and draw repeatedly without remeasuring, or pre-measure in order to do things like right justify text.
Using All of Your CPU
The little ESP32 WROVER is a dual core device, with each core typically operating at 240MHz. While the secondary core is used primarily to run network communications, there is plenty of juice left over on that core to run your own code. To use this core, you'll need to create at least one additional thread.
Furthermore, you're going to run into situations eventually where you handle callbacks that are sourced on a thread other than the primary thread.
Due to these situations, a bit of threading infrastructure can really help your application, especially if it can keep the complexity of multithreading under control.
FreeRTOS Thread Pack
The ESP32 runs FreeRTOS, which is what it uses to manage its threads. Some time ago, I wrote a little header file that provides several useful threading constructs including a thread pool and a synchronization manager under FreeRTOS.
Synchronizing Callbacks Sourced From Other Threads
It's often not safe to simply handle a callback from the thread that sourced it because this often isn't the same thread as the main application thread. Therefore, attempts to read and write data on the primary thread from the secondary thread can lead to race conditions. To solve this, we are going to use an FRSynchronizationContext. It starts by declaring one in the global scope:
FRSynchronizationContext sync_ctx;
To make it work, you'll need to add a line to your main application loop, as well as inside any loop in your application where you want callbacks to keep being able to fire:
sync_ctx.processOne();
If you don't call this inside your loop, callbacks will not be fired as long as that loop is running. Well, technically they will be fired, but you'll not get notified that they were called until the next time you call the above method.
Now, inside your callbacks you do your work, but you do it from inside of a lambda:
sync_ctx.post([](void* state) {
}, my_state_to_pass);
Anything inside that lambda will be safely executed on the thread where sync_ctx.processOne() is called and will run on that destination stack. Due to that last bit, this is also a good way to execute stack heavy functions from secondary threads that don't have a large stack, though technically you're actually executing the code on the main thread, but it is in response to a trigger from the secondary thread.
Executing on the Secondary Core
I don't recommend using threads in these applications where you can avoid it. For starters, it adds complexity and complicates debugging. Secondly, it introduces additional overhead that can be avoided by using cooperative time slicing instead of pre-emptive time slicing.
That said, in order to take advantage of the secondary core, you must use a secondary thread. The FreeRTOS Thread Pack includes an easy way to queue up functions for execution on the second core.
In the Thread Pack, the FRThreadPool is an extremely lightweight thread pooler that allows you to easily dispatch code to execute on a waiting thread. What you'll do is you'll simply create one in the same function where you intend to use it, add a thread to it that runs on the second core, and then proceed to execute code in the pool. It works like this:
FRThreadPool pool;
pool.createThreadAffinity(
1 - xPortGetCoreID(),
1,
4000);
Now, we use queueUserWorkItem() to dispatch code to run in the pool:
pool.queueUserWorkItem([](void*state) {
}, my_state_to_pass);
It will be cleaned up when the method exits.
Remember you can use sync_ctx from before to synchronize any access to shared data from the second core.
Using TFT_eSPI
gfx_demo now has bindings for Bodmer's TFT_eSPI library - quite possibly the fastest graphics driver for Arduino - which can be used to increase your framerates and support additional displays. Using TFT_eSPI allows for additional display support and in some cases better framerates. The setup is a bit more complicated, in this case involving downloading and installing the library, which you'll want to do directly from GitHub rather than using the automatic library fetch feature of PlatformIO, and then you'll need to edit a header file to assign your pin numbers and select your actual display hardware. It also cannot be used to drive multiple displays, but you can use it alongside gfx_demo native drivers if you need to do that. If you want to use TFT_eSPI, follow below.
To recap and further explain:
- Download the TFT_eSPI source from github
- Copy it to your project's "lib" folder under your PlatformIO project
- Edit User_Setup.h to assign your pins and choose your hardware.
- Copy gfx_tft_espi.hpp from gfx_demo/src/arduino/drivers and put it in your project's "src" folder.
One you've edited User_Setup.h to select your pins and hardware, you need to also include gfx_cpp14.hpp and then gfx_tft_espi.hpp. Finally, you'll instantiate TFT_eSPI and then gfx_tft_espi, which you then bind to it:
#include <User_Setup.h>
#include <TFT_eSPI.h>
#include <gfx_cpp14.hpp>
#include "gfx_tft_espi.hpp"
...
using namespace gfx;
using namespace arduino;
using tft_type = gfx_tft_espi<true>;
using tft_color = color<typename tft_type::pixel_type>;
TFT_eSPI tft_espi = TFT_eSPI();
tft_type tft(tft_espi);
You can then use GFX with the tft draw destination, and you can also use the tft_espi global to drive TFT_eSPI natively. You can use both alongside each other, if needed.
You'll note that we passed true as the single template argument to gfx_tft_espi. This enables reading from the display, allowing for the display to be used as a draw source, and enabling alpha blending on it. Not all hardware supports this and so it is off by default.
The second parameter (not used here) indicates that the platform supports asynchronous DMA transfers natively. TFT_eSPI must support it for your platform and hardware, since the Arduino framework doesn't natively. If it doesn't and you try to force it, you'll get a linking error in TFT_eSPI. The default for the Async parameter depends on your platform, so generally you don't need to set it yourself. It should be noted that there is an open issue here regarding the interface to TFT_eSPI's DMA code and so currently the async support is disabled in gfx_tft_espi. It is however, simply masked off and can be enabled as soon as Bodmer updates his code. Due to this, I would assume asynchronous support, and use the XXXX_async() calls on draw because they just revert to synchronous calls but will become asynchronous once this issue is resolved.
Screens Demo
The included screens demo is a small example demonstrating most of the techniques in the article. There is only one screen in order to keep it easy, but I dropped the dispatching code in there anyway so you can add screens. The main reason there are no screen is I didn't want to force you to wire up a way to input a screen change.
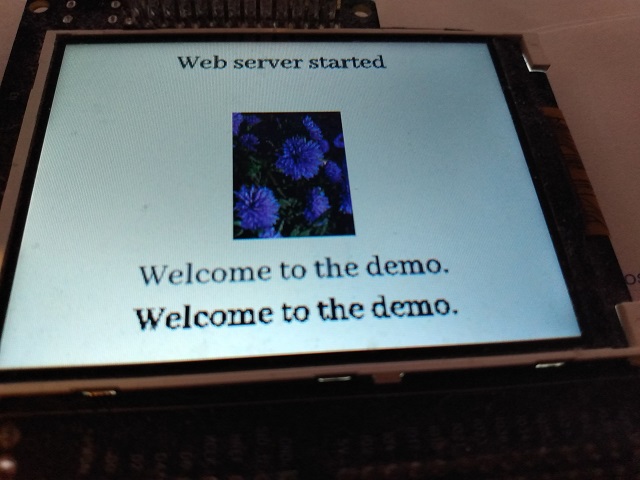
In this demo, we display some text and a JPG, and on the welcome screen we spin up a web server that displays the requested URL for a brief time on the display whenever you navigate to it with your browser.
The web server uses me-no-dev's ESPAsyncWebServer offering. I've included it directly in the project due to PlatformIO choking on it when included via the repository. It sources callbacks when HTTP requests are made. In those callbacks, we use sync_ctx to update the display since it's not safe to do that from a secondary thread.
At the end of the welcome screen, we just sit and spin on a while(true) loop looking for w3svc_last_url_ts to timeout so we can clear the last URL from the display.
For a real world app, you'd exit this routine (and that loop) on some sort of condition after setting screen_current to whatever your new destination screen is.
You'll note that "Welcome to the demo." appears twice. The lower copy is not anti-aliased or "smoothed", the idea being to show you the difference between drawing to an intermediary bitmap where smoothing can happen and drawing directly to the display where it cannot.
History
- 27th November, 2021 - Initial submission

