With GitHub actions and CI/CD principles, we can build an efficient and reliable workflow for ongoing development, testing, and deployment of our simple pipeline.
Want to try it yourself? First, sign up for bit.io to get instant access to a free Postgres database. Then clone the GitHub repo and give it a try!
An Actionable Workflow
Pipeline maintenance can be tedious at best and error prone at worst. Once a pipeline is in service, it requires ongoing changes to fix bugs, add new required features, and keep up with evolving external data sources.
With each change, we have to complete a set of tasks including writing code, running tests, and updating output databases, all while managing software versions and task order-dependencies. Mix these factors together, and it’s easy to test the wrong software version or deploy the wrong changes into service.
Fortunately, we can build a change management workflow and add automation to reduce both the tedium and error propensity of making ongoing pipeline changes.
In this article, we’ll make a workflow that combines Continuous Integration/Continuous Deployment (CI/CD) principles with GitHub Actions automation to manage ongoing changes to our simple pipeline from parts one, two, and three. We’ll start with a brief introduction to GitHub Actions.
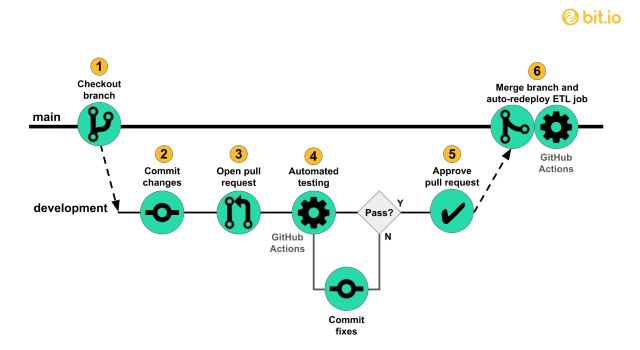
By combining CI/CD principles and automation with GitHub actions, we can enable both faster iterations and fewer errors during ongoing development. We will explain and then build this workflow for maintaining the simple pipeline.
What are GitHub Actions?
GitHub Actions are event-driven task automators for software development workflows. For example, GitHub actions can be used to execute a unit testing script (the automated task) on a development branch when a pull request is opened for submission to another branch (the driving event).
GitHub Actions are triggered by events. Common events include pushing commits, opening pull requests, or recurring cron schedules.
An event triggers a GitHub Actions workflow. Workflows can contain one or more jobs which are each a sequence of steps. The jobs can run in sequence or in parallel, but the steps within a job always run sequentially. In this article, each workflow has only one job.
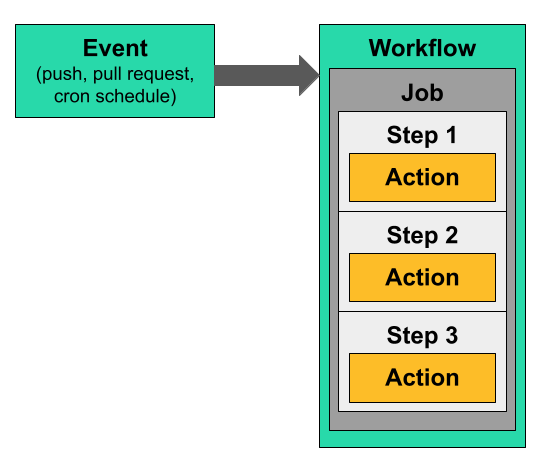
Actions are contained in steps, which run in sequence within a job, which is contained in a workflow that is triggered by an event.
Each job is executed by a specified runner, which is a compute environment on your own machine or on a machine hosted by GitHub. We will use a GitHub hosted runner in our implementation (free up to a usage limit, at the time of publication).
Each step contains an action, which can be a published unit of commands, such as “checkout a repo” or custom commands that are appropriate for the configured runner. For example, if a runner has Python installed and a script named hello_world.py, our step could run the custom command python hello_world.py.
Each GitHub Actions workflow is configured in a YAML file within the associated repo. The example below runs part of the simple pipeline every time new commits are pushed to our main branch on GitHub:
An example workflow that checks out a repo, installs dependencies, and runs the simple pipeline on just the New York Times cases and deaths dataset from Part 1.
At the workflow level, we specify a name, ETL Example, on Line 1, the driving event, on push to branch main, on lines 2–5, and a job on lines 7–28.
At the job level, we specify the latest GitHub-hosted Ubuntu runner on line 8. We also set up some environment variables for the runner on lines 10–12, including bit.io connection credentials that are stored as a secret on GitHub.
Within the job, we specify steps to:
- Checkout a repo.
- Set up Python.
- Install Python dependencies.
- Run a portion of the simple pipeline that loads the COVID cases and deaths to bit.io.
The first two steps use actions from the GitHub Actions marketplace, a repository of actions published by other developers for generic operations, like checking out a repo to a runner. The later two steps use custom commands specified directly in the workflow file.
After committing the workflow file to the main branch of our repo and pushing to GitHub, the workflow runs as expected and reloads the New York Times dataset to bit.io. The screenshot below shows the workflow execution summary and logs within the GitHub console.
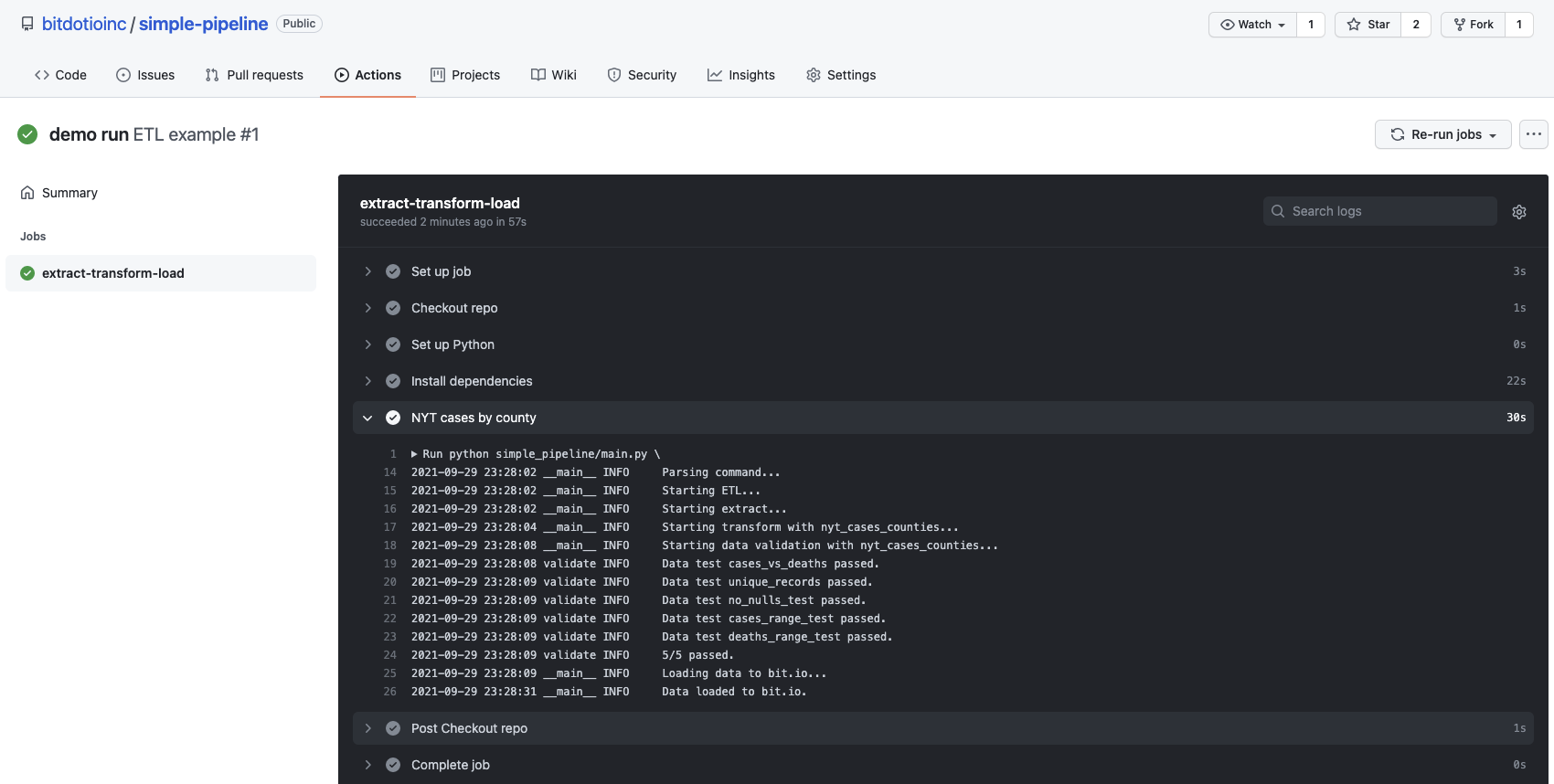
Screenshot of the “ETL example” workflow in the Actions tab of the GitHub console. Here, we can see that all steps completed successfully. We have also expanded the logs for the simple pipeline step.
This simple example illustrates the core concepts behind automation with GitHub actions but doesn’t yet help with our development workflow. However, before we build out an automated workflow, we also need to introduce some Continuous Integration/Continuous Deployment (CI/CD) concepts.
What is CI/CD?
CI/CD is an abbreviation for Continuous Integration/Continuous Deployment (or Continuous Delivery). Much ink has been spilled defining the scope of each of these terms. We will prioritize basic concepts over comprehensive coverage, and show how we can apply those basics to our simple pipeline.
Continuous Integration (CI) refers to using automation to frequently build, test, and merge code changes to a branch in a shared repository. The basic motivation behind CI is pursuing faster developer iteration and deployment of changes compared to a process with larger, infrequent integration events where many changes, often from multiple developers, are de-conflicted and tested at the same time.
Continuous Deployment (CD) refers to using automation to frequently redeploy a software project. The basic motivation behind CD is freeing operations teams from executing time-consuming and error-prone manual deployment processes while getting changes out to users quickly. For our batch processing pipeline, deployment simply means re-running the pipeline to update the database when changes are pushed to main. This ensures the database always reflects the output of the latest pipeline version pushed to main.
CI/CD can be easier to explain with concrete examples. Let’s see how we can use GitHub Actions to incorporate CI/CD into our simple pipeline.
Pull Request Actions for CI
Continuous Integration involves automating the build and testing of code to enable frequent merges from development branches to a shared repository.
Developers submit changes for merging to a shared branch using pull requests, which can be used as events to trigger automated CI testing with GitHub Actions. If the automated tests pass, a reviewer can approve the pull request for merging. If the automated tests fail, the submitting developer can push fixes to the development branch, triggering the testing to automatically rerun (Steps 3–5 below).
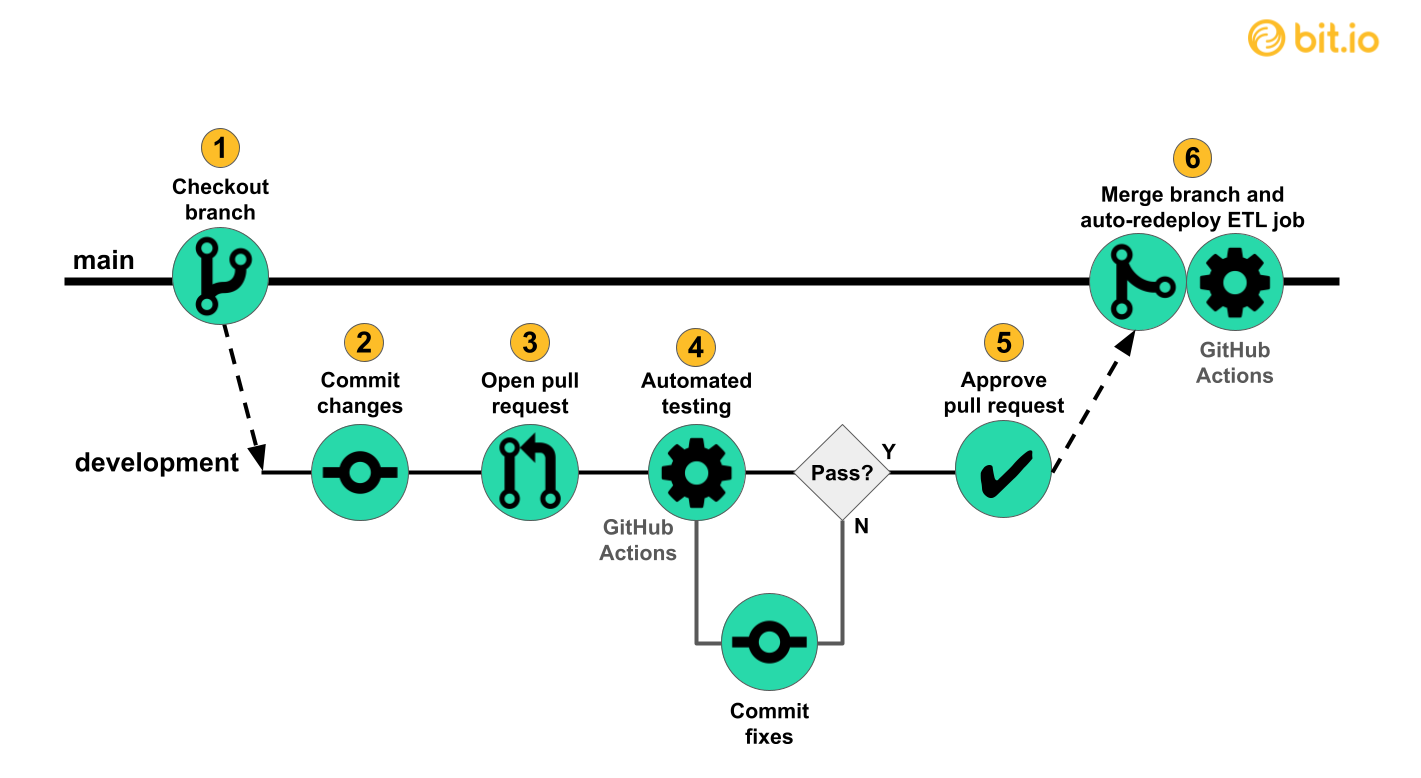
We illustrate CI practices by automatically testing our development branch pipeline using GitHub Actions (4) after opening a pull request (3) that submits changes to the main branch. In addition to running unit tests and data tests, the automated testing executes the entire development branch pipeline and loads the output into a development repo on bit.io, effectively an end-to-end integration test. After the tests are satisfied, a reviewer can approve the pull request (5) for merging.
We can modify our example workflow file to implement this automated, pull-request-driven, testing. The file is getting longer, but only introduces a few new ideas:
- Line 3 — The driving event is now a pull request submitted to main, not a push.
- Line 12 — We are now loading into a development repo on bit.io, named “
simple_pipeline_dev”. We can run the development version of the pipeline end-to-end without impacting our published dataset in the main repo, “simple_pipeline”. - Lines 24–25 — Our suite of unit tests run on the code in the development branch.
- Lines 25–45 — We are now loading all three data sources from Part 1, instead of just one example.
- Lines 47–51 — We have added our post-load SQL job that runs on bit.io to update a reporting table showing California COVID cases and deaths, vaccinations, and population by county.
This workflow is now driven by pull requests, rather than pushes, to main and adds all three table loads as well as a post-load SQL job. Lines 24–25 show the key additional step that runs unit tests on the development branch code, while the data tests are integrated within the simple pipeline steps on lines 27–45. Finally, note that the loads and SQL job are all being applied to a separate development repo, “simple_pipeline_dev” so that the tests don’t interfere with the published dataset.
Now, when we open a pull request for submission to our main branch, the workflow runs automatically and displays the results of the “checks” as shown in the successful outcome screenshot below.
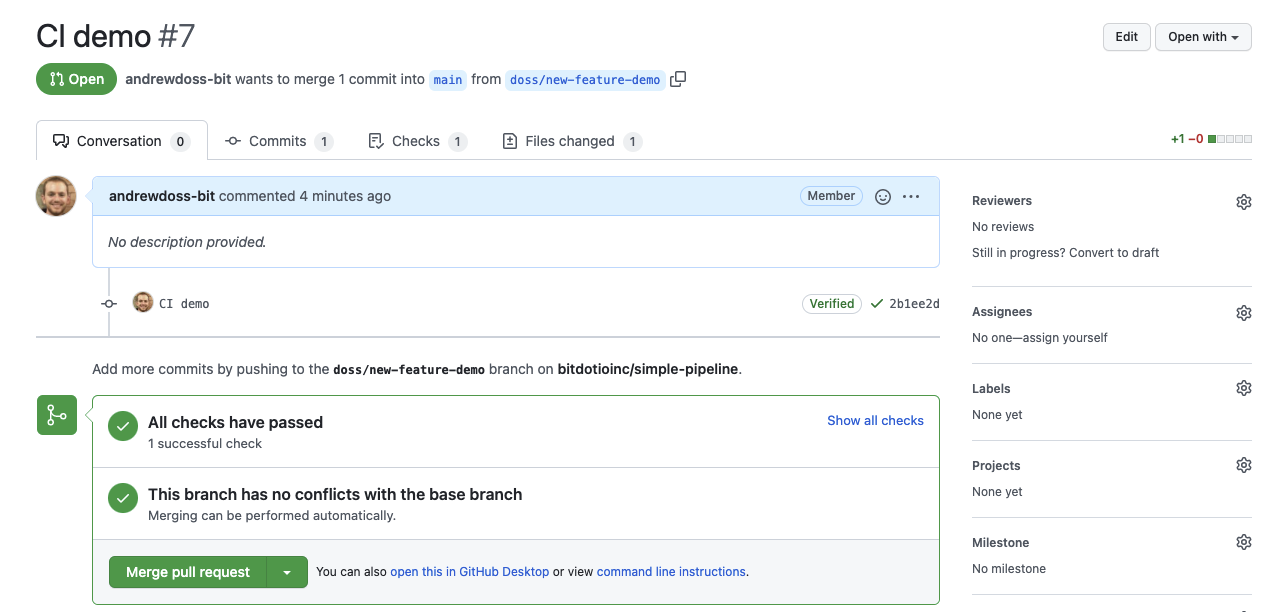
Below, we show the summary of the successful automated testing workflow driven by the pull request above. You can see the logs for the 7 unit test cases from Part 3, and that all unit tests passed before the pipeline ran.
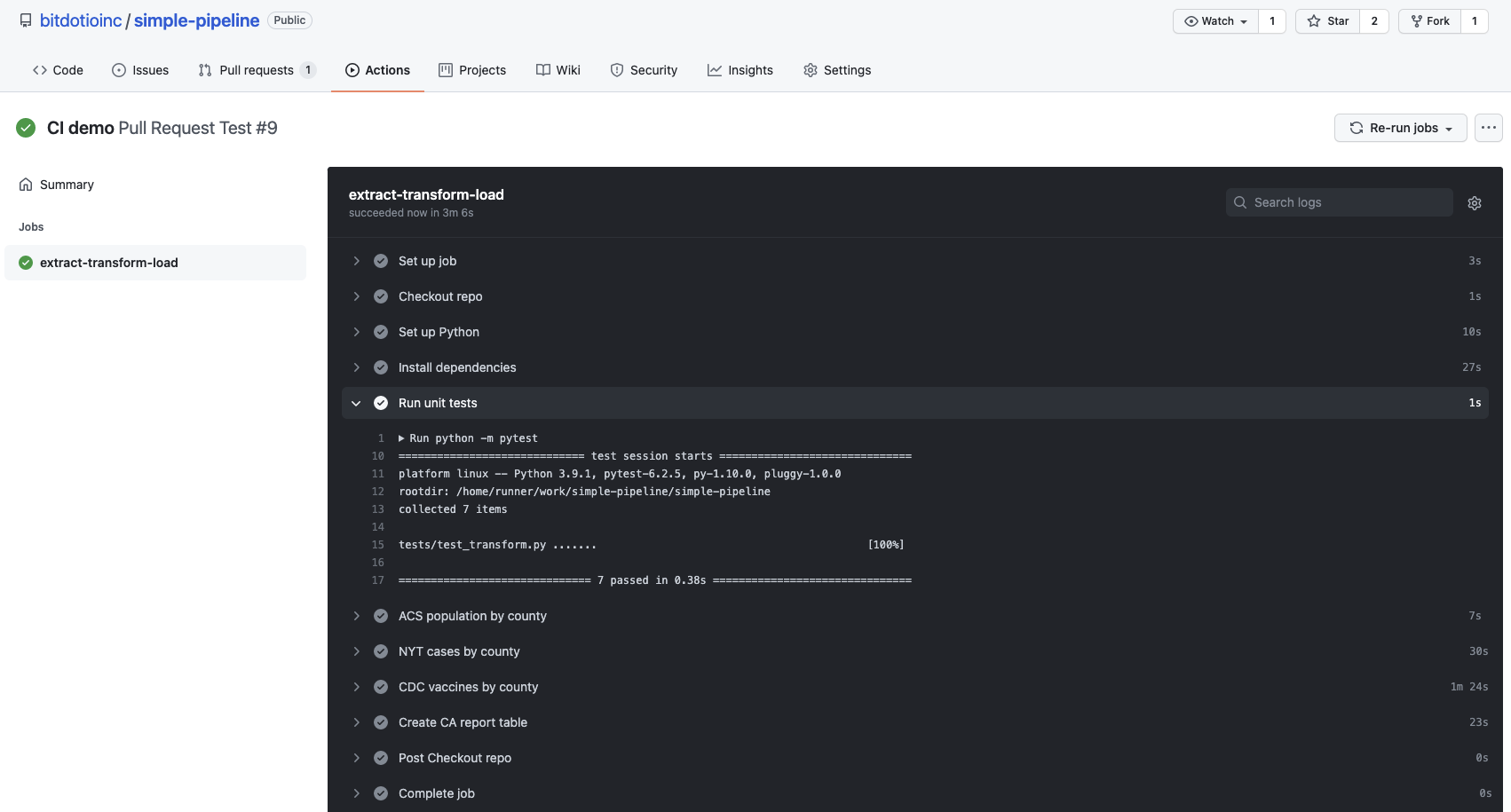
We can monitor the progress and outcome of the automated testing workflow in the Actions tab of the GitHub console. Here, we show the logs from the successful unit testing step that runs before the the pipeline loads data into the development repo on bit.io.
Finally, we can check our development repo on bit.io and confirm that the datasets updated as expected:
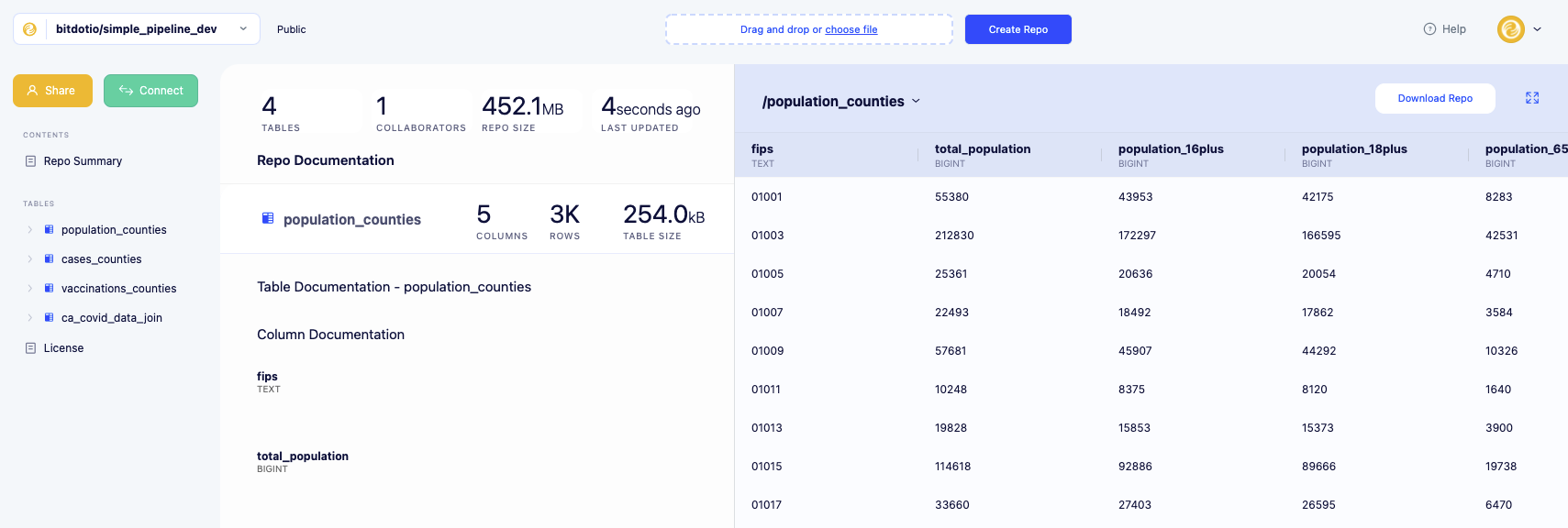
By checking the loaded tables and derived report in our development repo, “simple_pipeline_dev”, we can confirm that our development pipeline worked from end-to-end without interfering with the state of our main “simple_pipeline” repo.
If we are satisfied at this point, we can merge the changes to the main branch and move on to redeploying our main pipeline.
Push Actions for CD
Continuous Deployment refers to using automation to frequently redeploy a software project.
In our case, we can add a second GitHub Actions workflow that reruns our main pipeline and updates our main repo on bit.io every time we push new commits to the main branch. This saves time, gets our changes out to the published datasets more quickly, and ensures that the latest commit on our main branch is consistent with the state of our database.
This deployment workflow only requires a few changes from the pull request testing workflow:
- Line 5 — The driving event is now a push to the main branch (which includes merging a pull request).
- Line 12 — The data now loads to the main “
simple_pipeline” repo. - Line 22 — The units tests have been removed, as they already ran during the pull request integration testing.
Our second deployment workflow only requires a few changes from the pull request testing workflow. We’ve changed the driving event to a push to main, pointed the loads back to the main “simple_pipeline” repo, and dropped the unit tests that already ran during the pull request integration workflow.
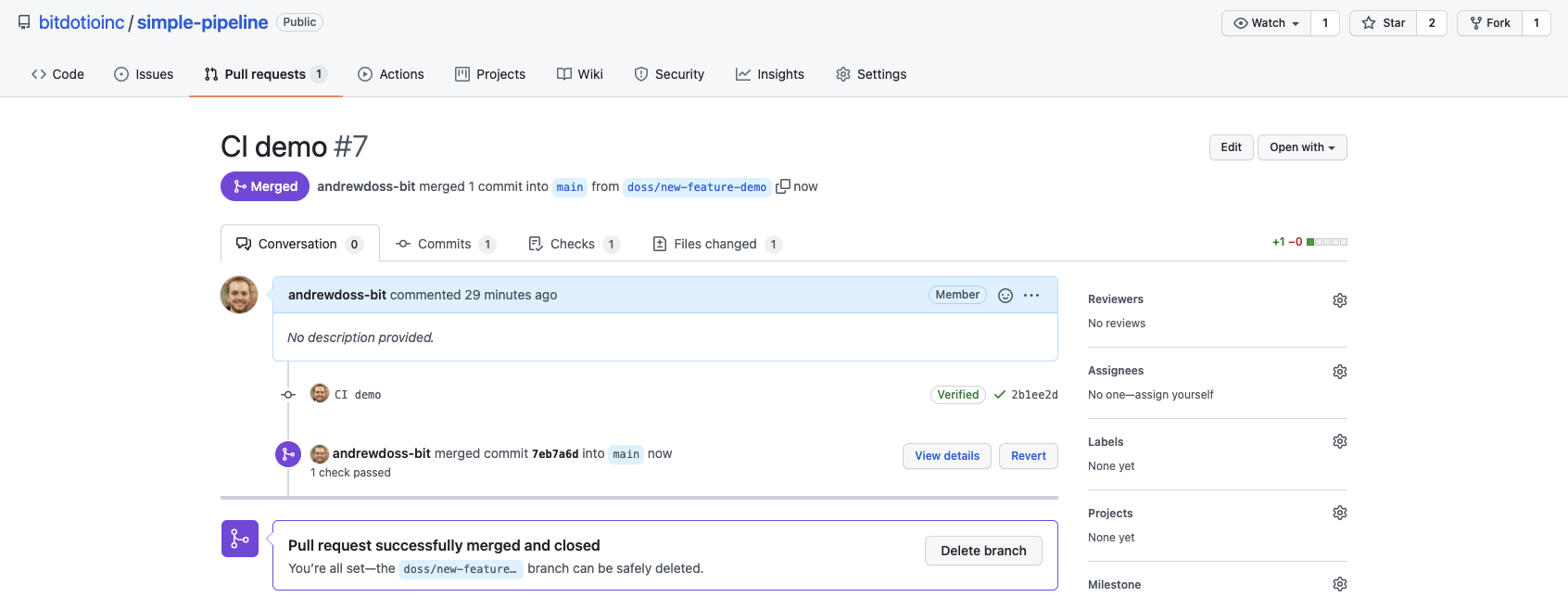
We merged the pull request after reviewing the changes and seeing that they passed the automated integration tests (typically, a developer who is not the change author would approve the pull request).
Below, we show the summary of the successful rerun of the main pipeline in the GitHub Actions console.
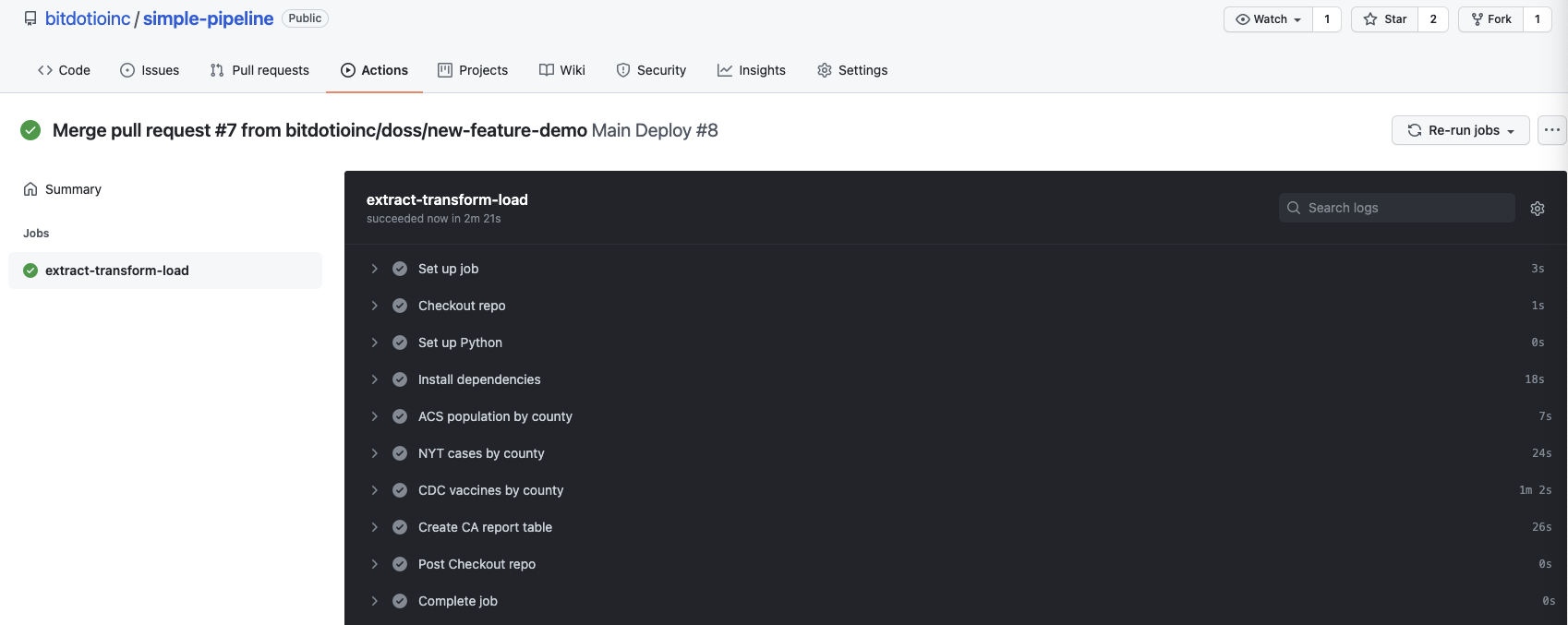
After merging the pull request, we triggered the Main Deploy workflow which successfully executed the updated pipeline and reloaded the data to the main “simple_pipeline” repo on bit.io.
Finally, we can check our main repo on bit.io and confirm that the datasets updated as expected:
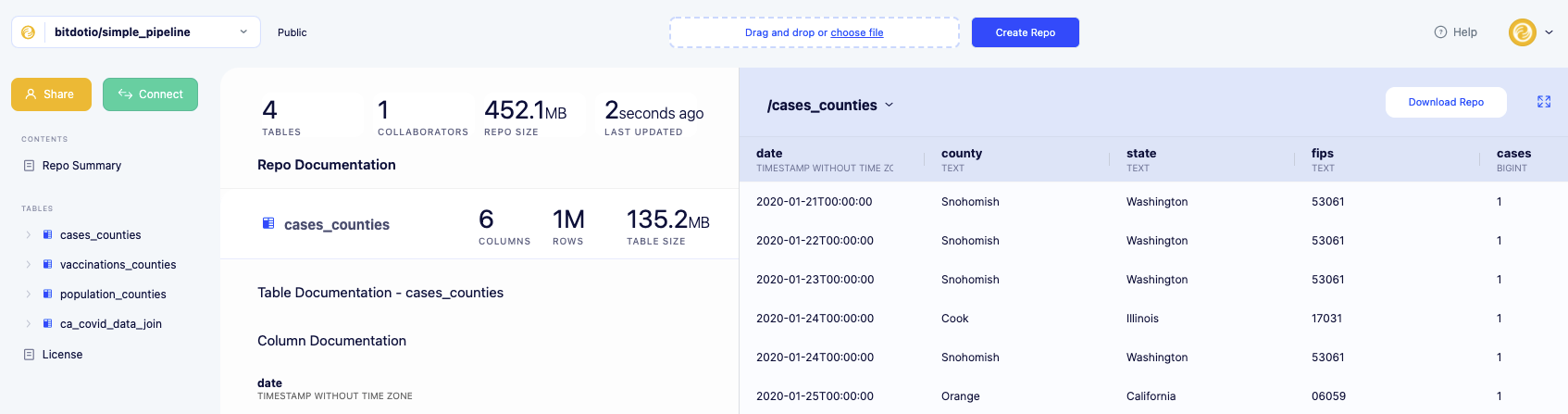
By checking the loaded tables and derived report in our main repo, “simple_pipeline”, we can confirm that our development pipeline worked from end-to-end without interfering with the state of our main “simple_pipeline” repo.
Conclusions
That’s it! We’ve built an automated workflow with CI/CD features that manages our steps for making ongoing pipeline changes. You may have noticed some details that we haven’t handled yet, for example, managing parallel changes from multiple developers and enforcing reviewers. However, the concepts we used here can be applied to build more sophisticated workflows that handle those and other details.
A final detail — you can also use the main deployment workflow to schedule a daily re-run of the pipeline by adding a cron schedule event alongside the existing push event driver. However, GitHub-hosted Actions aren’t intended for general post-deployment compute service, so you may want to consider either using the workflow to update a scheduled job on your own machine or run the recurring pipeline on your own GitHub Actions host.
If you haven’t yet, we invite you to sign up for bit.io to get instant access to a free, private Postgres database, clone the GitHub repo, and give it a try on a dataset that you need!
Interested in future Inner Join publications and related bit.io data content? Please consider subscribing to our weekly newsletter.
Appendix
Series Overview
This article is part of a four-part series on making a simple, yet effective, ETL pipeline. We minimize the use of ETL tools and frameworks to keep the implementation simple and the focus on fundamental concepts. Each part introduces a new concept along the way to building the full pipeline located in this repo.
- Part 1: The ETL Pattern
- Part 2: Automating ETL
- Part 3: Testing ETL
- Part 4: CI/CI with GitHub Actions
Additional Considerations
This series aims to illustrate the ETL pattern with a simple, usable implementation. To maintain that focus, some details have been left to this appendix.
- Best practices — This series glosses over some important practices for making robust production pipelines: staging tables, incremental loads, containerization/dependency management, event messaging/alerting, error handling, parallel processing, configuration files, data modeling, and more. There are great resources available for learning to add these best practices to your pipelines.
- ETL vs. ELT vs. ETLT — The ETL pattern can have a connotation of one bespoke ETL process loading an exact table for each end use case. In a modern data environment, a lot of transformation work happens post-load inside a data warehouse. This leads to the term “ELT” or the unwieldy “ETLT”. Put simply, you may want to keep pre-load transformations light (if at all) to enable iteration on transformations within the data warehouse.
Keep Reading
We’ve written a whole series on ETL pipelines! Check them out here:
Core Concepts and Key Skills
Focus on Automation
ETL In Action

