This article shows the code to create and train a model using XGBoost and then run model training on Azure ML. This will be followed by a brief demonstration to show that the trained model works as expected.
It’s hard to miss the increasing popularity and prevalence of machine learning (ML) and data science. This trend was one of the biggest drivers of Python’s explosion in popularity. As of 2021, the Python language is officially more popular than well-established old-timers like Java, C#, or C++. It took first place in the TIOBE Index in November, and it was the third most popular programming language in Stack Overflow's 2021 Developer Survey. You most likely think of Python when you think about machine learning code.
You can run Python code on almost everything: PC, Mac, or Raspberry Pi, with x86, x86-64, AMD64, or ARM/ARM64 processors, and Windows, Linux, or macOS operating systems. However, machine learning often requires significant processing power, which may exceed the capabilities of whatever computer you have at a given moment. Azure is a great place to run Python-based ML workloads of almost any size.
In this three-part series, we’ll work through several approaches to creating and using machine learning models in Python on Azure. You can find the sample code for this article on GitHub.
We’ll begin by training and testing a model using the XGBoost library with Azure Machine Learning services. And, we’ll do (almost) everything without leaving Visual Studio Code to make things even more streamlined.
Problem and Dataset
This tutorial will use a well-known MNIST dataset to train the model to recognize handwritten digits. We won’t rely on a ready-to-use version of this dataset to be a little more relatable, even though it is available in many frameworks. Instead, we use it in a way that you can adapt to any image classification task of your choice.
Prerequisites
To follow the examples in this article, you need Visual Studio Code, a recent Python version, and Conda for Python package management. If you don’t have other preferences, start small with Miniconda and Python 3.9.
With Python and Conda installed, create and activate a new environment:
$ conda create -n azureml python=3.9
$ conda activate azureml
Additionally, you need an Azure subscription. Sign up for a free Azure account if you don’t yet have one.
Downloading an MNIST Dataset
Start by downloading the MNIST dataset from Microsoft’s Azure Open Datasets:
import os
import urllib.request
Then, save the code below in a file named download-dataset.py:
DATA_FOLDER = 'datasets/mnist-data'
DATASET_BASE_URL = 'https://azureopendatastorage.blob.core.windows.net/mnist/'
os.makedirs(DATA_FOLDER, exist_ok=True)
urllib.request.urlretrieve(
os.path.join(DATASET_BASE_URL, 'train-images-idx3-ubyte.gz'),
filename=os.path.join(DATA_FOLDER, 'train-images.gz'))
urllib.request.urlretrieve(
os.path.join(DATASET_BASE_URL, 'train-labels-idx1-ubyte.gz'),
filename=os.path.join(DATA_FOLDER, 'train-labels.gz'))
urllib.request.urlretrieve(
os.path.join(DATASET_BASE_URL, 't10k-images-idx3-ubyte.gz'),
filename=os.path.join(DATA_FOLDER, 'test-images.gz'))
urllib.request.urlretrieve(
os.path.join(DATASET_BASE_URL, 't10k-labels-idx1-ubyte.gz'),
filename=os.path.join(DATA_FOLDER, 'test-labels.gz'))
You can run the code using the following command:
$ python download-dataset.py
Preparing Visual Studio Code for ML
Azure Machine Learning is a collection of cloud services and tools for the end-to-end ML lifecycle. To make using it from Visual Studio Code easier, we can use a new dedicated extension.
First, click the extension icon in the Visual Studio Code sidebar.
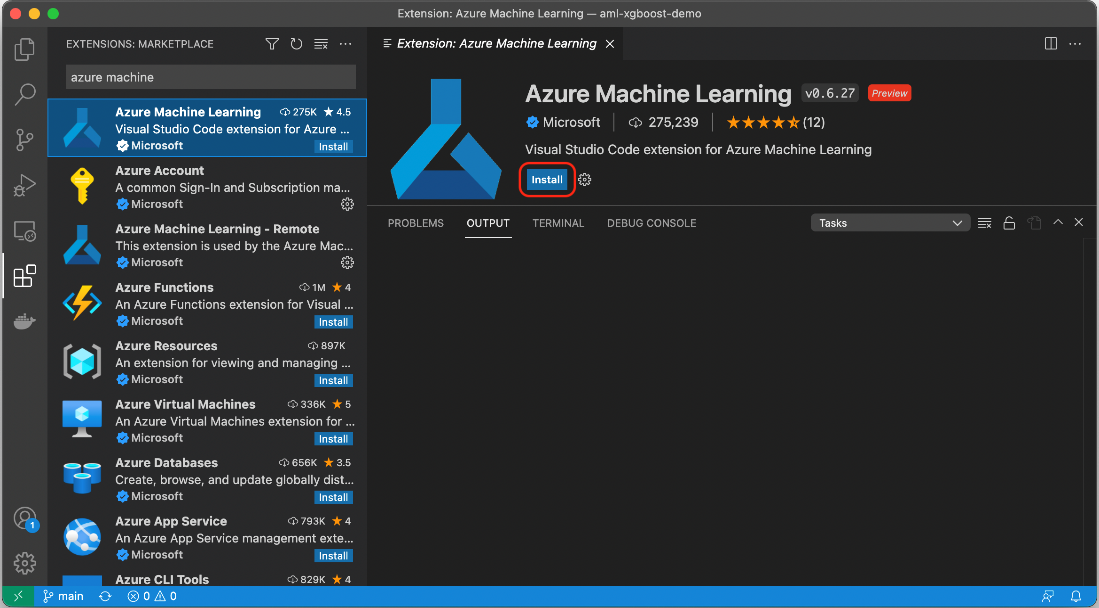
Now, search for and install the Azure Machine Learning extension.
When you have the extension installed and activated (this may require restarting Visual Studio Code), a new Azure icon appears in the sidebar.
Additionally, we need Azure command-line tools (azure-cli) with a version greater than or equal to 2.15.0, with its machine learning extension. At the time of writing, it’s version 2.0.2. To use the tools, enter the following:
$ az extension add -n ml -y
Preparing an Azure ML Workspace
Now we can start configuring our Azure resources. First, we need the Azure: Machine Learning workspace. Next, we create a dataset, a computing cluster to handle the work, and the training job within the workspace.
We use the installed Azure Machine Learning extension to start setting up Azure.
After signing in to an Azure account (or creating a new one), we see the name of our subscription and the option to create a (machine learning) workspace:
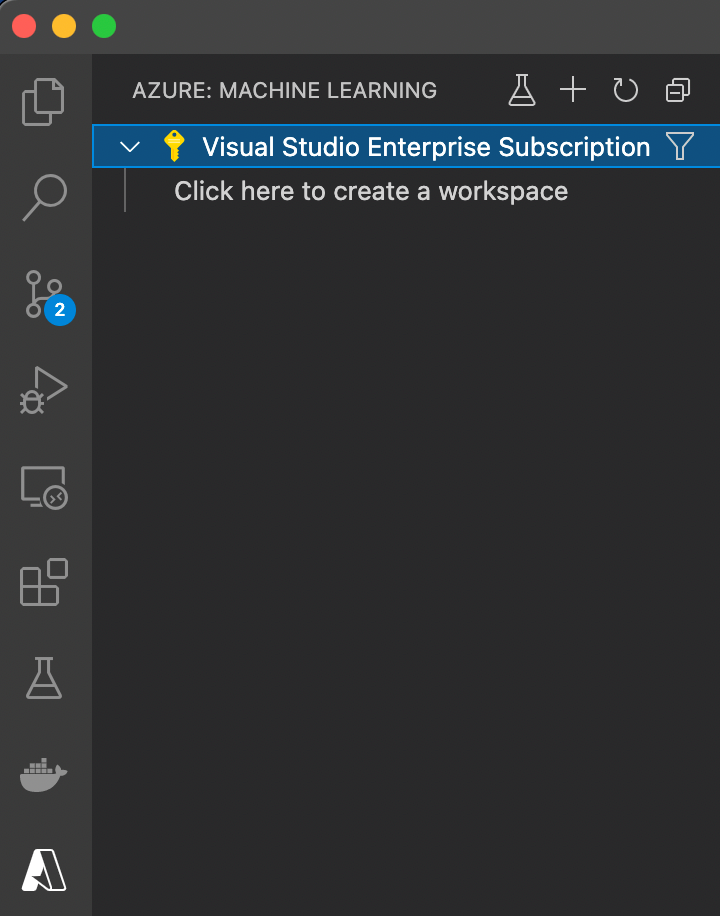
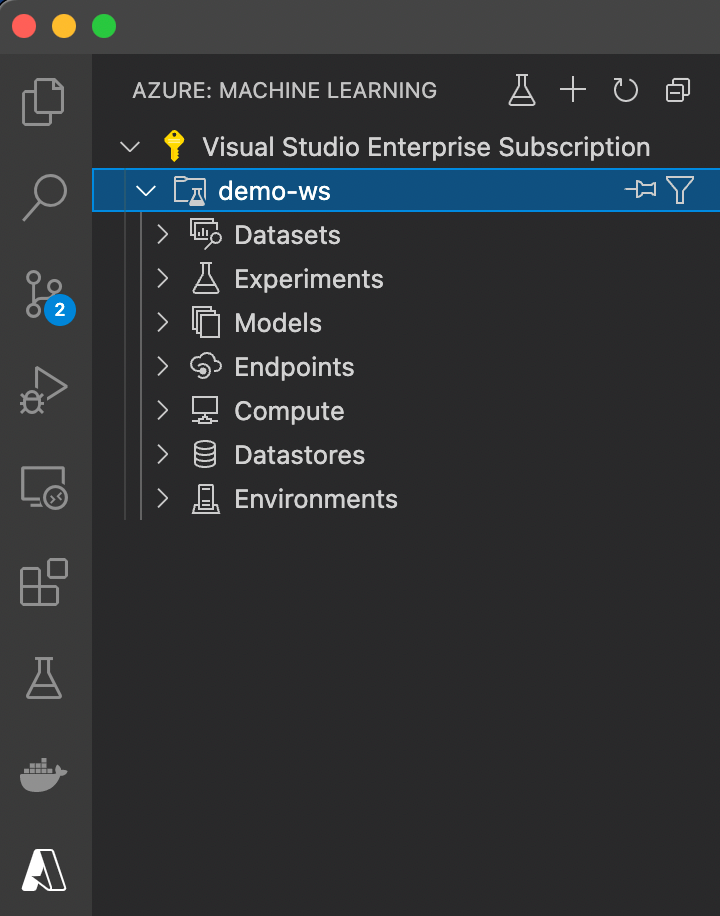
For this example, create a new workspace, named demo-ws, within a new resource group, called azureml-rg, in the location closest to you. Here, we’ve chosen Western Europe. After successful creation, the workspace should be visible just below our subscription:
The first time we attempt to do anything with the Azure Machine Learning extension, the Visual Studio Code asks us to select a default workspace:
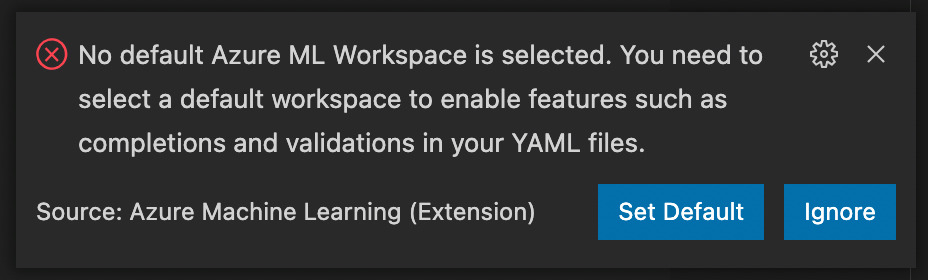
Don’t ignore the prompt. Most Machine Learning extension features won’t work without the default workspace, and we only sometimes get a meaningful error message. If you miss the prompt, you can always set the default workspace manually. One way to set the default is to use Cmd/Ctrl+Shift+P, then select the Azure ML: Set Default Workspace command:
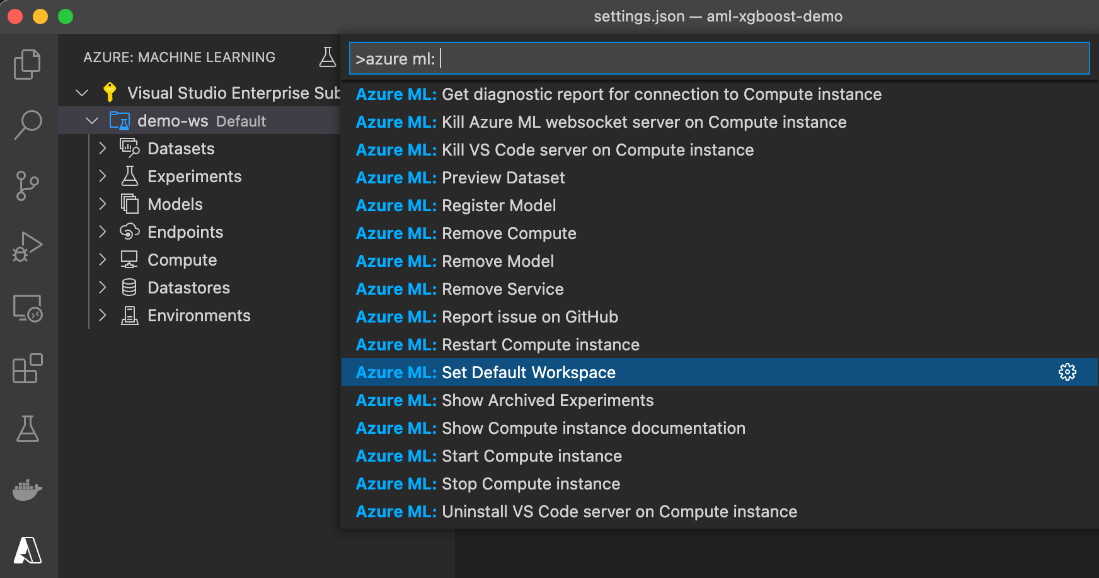
Alternatively, you can set the default workspace in the .vscode/settings.json file:
{
"azureML.defaultWorkspaceId": "/subscriptions/<your-subscription-id>
/resourceGroups/azureml-rg/providers/Microsoft.MachineLearningServices/workspaces/demo-ws"
}
In some cases, you may need to restart Visual Studio Code for this change to take effect (the extension is still in preview, after all).
When you have selected the default workspace, you can see it in the Azure: Machine Learning extension list:
Uploading a Dataset to the Machine Learning Workspace
Now we can start using our workspace. The first thing we need in any machine learning project is data. The preferred way of handling data in the Azure: Machine Learning workspace is registering it as a dataset.
Click the demo-ws workspace’s Datasets node using the Visual Studio Code extension, then click the plus sign (+). In response, the Azure Machine Learning extension generates a dataset definition template.
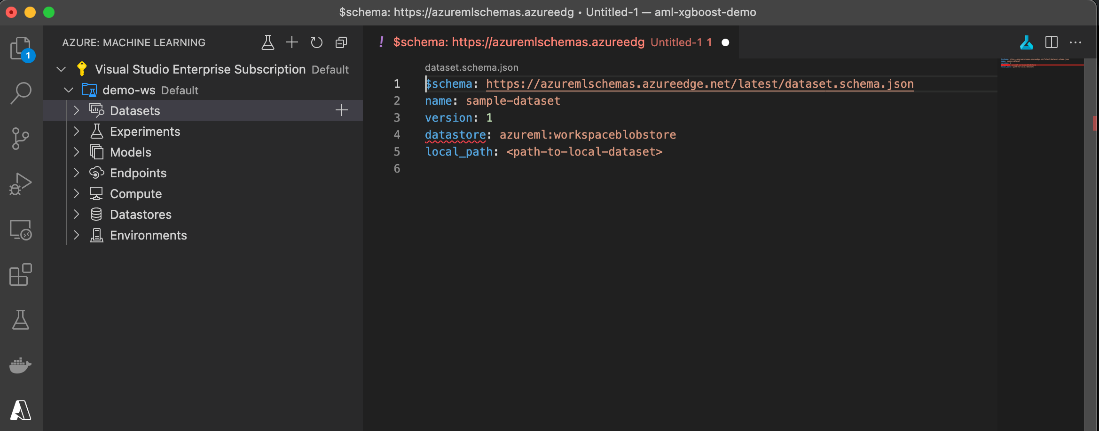
The automatically generated template isn’t compatible with the accepted schema, which no longer supports the datastore attribute. Unfortunately, we may need to face this when playing around with the preview code. However, we can easily create a proper dataset definition to upload our previously downloaded dataset files to Azure: Machine Learning.
The aml-mnist-dataset.yml file should contain the following:
$schema: https:
name: mnist-dataset
version: 1
local_path: datasets/mnist-data
Now, if we click the small icon in the upper right corner (in the red rectangle in the screenshot below), the Azure Machine Learning extension should automatically generate and execute the correct azure-cli command:
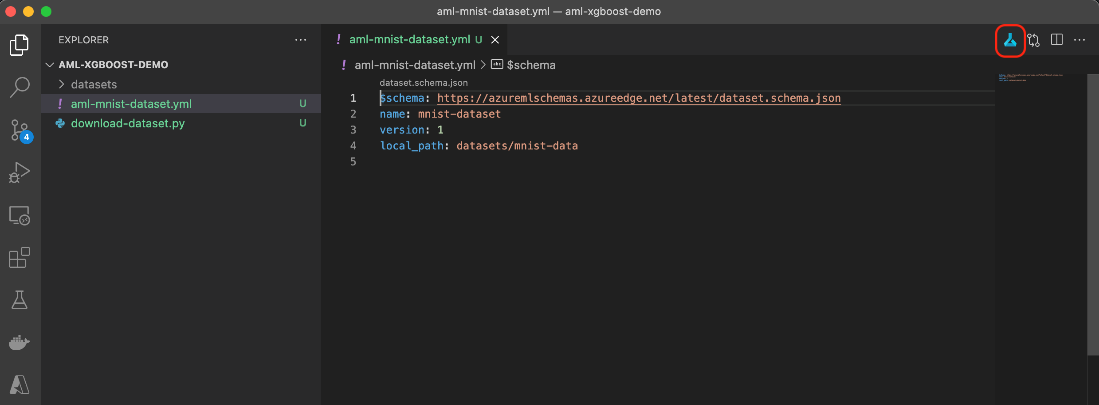
If it doesn’t work, ensure you have set the default Azure: Machine Learning workspace. The error message may be vague here. Alternatively, you can always use the Azure CLI directly:
$ export SUBSCRIPTION="<your-subscription-id>"
$ export GROUP="azureml-rg"
$ export WORKSPACE="demo-ws"
$ az ml dataset create --file aml-mnist-dataset.yml --subscription $SUBSCRIPTION
--resource-group $GROUP --workspace-name $WORKSPACE
Selecting a Computing Option
Apart from data, we need a computing resource to run our training code. If we expand the Compute node in our demo-ws workspace, we can see several options: compute instances, compute clusters, inference clusters, and attached computers.
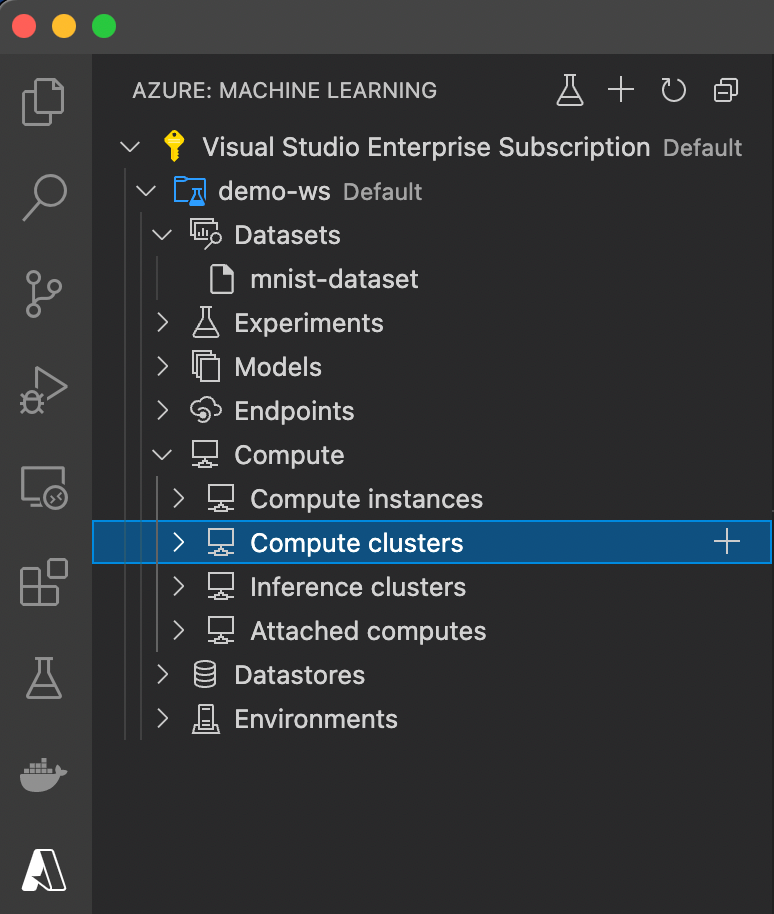
We use compute instances to run complete environments for experimentation — for example, with a Jupyter notebook in JupyterLab. We’ll use one in the third article of this series.
We can use inference clusters to handle predictions on trained and saved models. The attached computers allow using existing Azure resources instead of creating new ones. We don’t have any existing resources (VMs, HDInsight, Databricks, or Kubernetes clusters), so we’ll create a new compute cluster. Such clusters can scale up and down dynamically, depending on the current demand. It’s a helpful feature that lets us pay only for the computing resources we need.
If we click the plus sign (+) to the right of the Compute clusters node, we create a relatively short and not very helpful template:
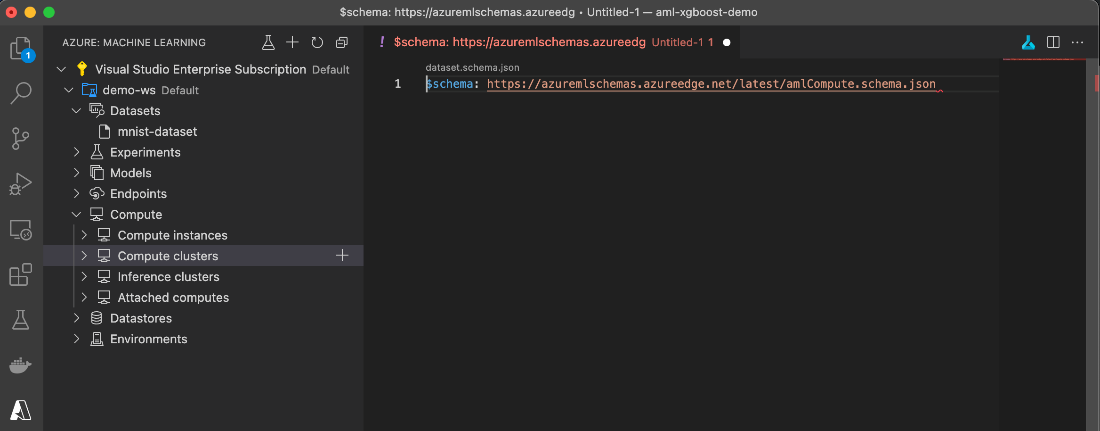
Luckily, a short study of the referenced JSON schema, together with the AmlCompute Class documentation, enables us to fill it:
$schema: https://azuremlschemas.azureedge.net/latest/compute.schema.json
name: ami-comp-cpu-01
type: amlcompute
size: Standard_DS3_v2
min_instances: 0
max_instances: 1
idle_time_before_scale_down: 3600
location: westeurope
You can select your values, such as name, size, number of instances, and so on. In the example above, we ensure that a single and relatively small virtual machine runs at most. It’s more than enough for our purposes, but you may need to choose something much more significant from the available sizes for larger models.
Like the dataset, if clicking the blue symbol in the upper-right corner doesn’t work, we can use the Azure CLI directly. If we’ve saved our compute definition to the aml-compute-cpu.yml file, the command should look like this:
$ az ml compute create --file aml-compute-cpu.yml --subscription $SUBSCRIPTION
--resource-group $GROUP --workspace-name $WORKSPACE
Don’t worry about Azure costs yet. As long as you’ve left the min_instances variable equal to 0, running this script creates only the compute definition, not the compute VM itself.
Preparing the Training Code
With our dataset and compute configured, we can finally prepare our training code. We store our training code in the code/train.py file.
Typically, we start from imports:
import os
import argparse
import gzip
import struct
import mlflow
import numpy as np
from azureml.core import Run
from azureml.core.model import Model
import xgboost as xgb
from sklearn.metrics import accuracy_score
Then, we define helper methods to handle Azure: Machine Learning workspace and argument parsing. In our case, we have only a single argument, data, which contains the path to our dataset files:
def get_aml_workspace():
run = Run.get_context()
ws = run.experiment.workspace
return ws
def parse_arguments():
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, required=True)
args = parser.parse_known_args()[0]
return args
Now, we can define the dataset loading method. This method is dataset specific, and we mostly borrow it from the Azure Open Datasets example. You need to replace it when using your own data, of course.
def load_dataset(dataset_path):
def unpack_mnist_data(filename: str, label=False):
with gzip.open(filename) as gz:
struct.unpack('I', gz.read(4))
n_items = struct.unpack('>I', gz.read(4))
if not label:
n_rows = struct.unpack('>I', gz.read(4))[0]
n_cols = struct.unpack('>I', gz.read(4))[0]
res = np.frombuffer(gz.read(n_items[0] * n_rows * n_cols), dtype=np.uint8)
res = res.reshape(n_items[0], n_rows * n_cols) / 255.0
else:
res = np.frombuffer(gz.read(n_items[0]), dtype=np.uint8)
res = res.reshape(-1)
return res
X_train = unpack_mnist_data(os.path.join(dataset_path, 'train-images.gz'), False)
y_train = unpack_mnist_data(os.path.join(dataset_path, 'train-labels.gz'), True)
X_test = unpack_mnist_data(os.path.join(dataset_path, 'test-images.gz'), False)
y_test = unpack_mnist_data(os.path.join(dataset_path, 'test-labels.gz'), True)
return X_train, y_train, X_test, y_test
Next, we can add methods to train and save our model. To make the training shorter, we’ve reduced the values of the max_depth and n_estimators parameters. This reduction negatively impacts our model’s quality, of course, so feel free to experiment with these values if you’d prefer better results.
def create_model():
return xgb.XGBClassifier(use_label_encoder=False, max_depth=3, n_estimators=10)
def train_model(X, y, model_filename):
model = create_model()
model.fit(X, y, eval_metric='mlogloss', verbose=True)
model.save_model(model_filename)
After training, we evaluate the model using test data. The code below illustrates how to load and use our model for inference:
def evaluate_model(X, y, model_filename):
model = create_model()
model.load_model(model_filename)
preds = model.predict(X)
accscore = accuracy_score(y, preds)
mlflow.log_metric('accuracy', accscore)
Note the use of MLflow logging in the last statement. It is the recommended approach, and it allows using the same code in the cloud and local runs.
After training, we can register the model for future use:
def register_model(ws, model_filename):
model = Model.register(
workspace=ws,
model_name=model_filename,
model_path=model_filename
)
With all the pieces in place, we now put them together:
def main():
args = parse_arguments()
ws = get_aml_workspace()
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.start_run()
X_train, y_train, X_test, y_test = load_dataset(args.data)
model_filename = "mnist.xgb_model"
train_model(X_train, y_train, model_filename)
evaluate_model(X_test, y_test, model_filename)
register_model(ws, model_filename)
if __name__ == "__main__":
main()
Determining the Training Job’s Environment
We have our data, compute definition, and training code. To run the code, we must decide which environment to use. We can use a custom Conda environment or a Docker image. Alternatively, we can use one of Microsoft’s created and curated environments. In our case, we choose the latter.
If you decide to use a computing cluster with a GPU, remember to select an environment with GPU support and Nvidia CUDA drivers. If not, you’ll pay for the GPU time without being able to use it.
To start working on our training job definition, we click the Experiments node of the Visual Studio Code Machine Learning extension. Then we select the Command Job. It creates the following template:
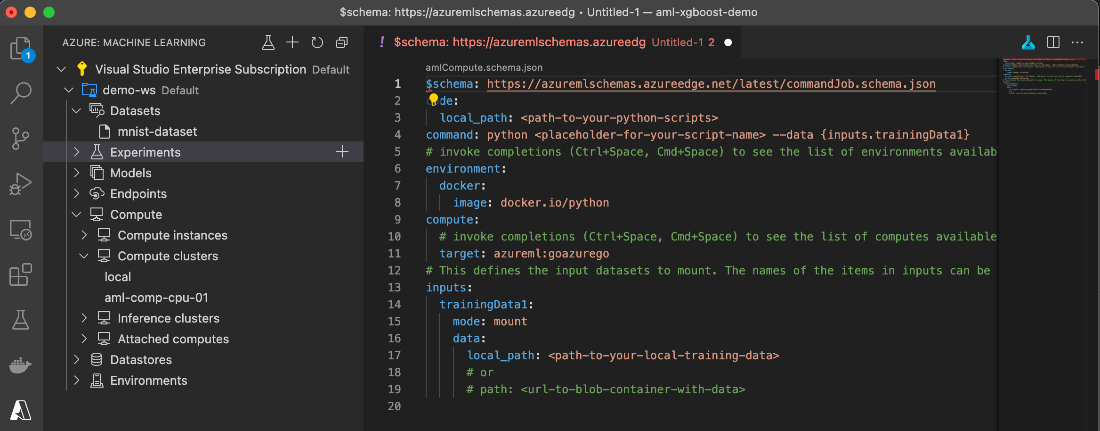
Apart from the Command Jobs, we can create a Sweep Job or Pipeline Job. Sweep Jobs automate an optimal hyperparameter search by running multiple experiments with various values from predefined ranges. The Pipeline Job allows us to create complex, multi-step experiments. In our case, a simple Command Job will do the trick.
To define our training, we fill the template with the following content:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code:
local_path: code/train
command: python train.py --data ${{inputs.mnist_data}}
environment: azureml:AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu:12
compute: azureml:aml-comp-cpu-01
inputs:
mnist_data:
dataset: azureml:mnist-dataset:1
mode: ro_mount
experiment_name: my-mnist-experiment
In the aml-job-train.yml file, we set the path to our training code and define the command to run it. We also select a curated environment to use: AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu:12, which has all the dependencies we need.
We select the compute definition we want to use and define the input parameters (inputs/mnist_data). Note the explicit version of the dataset. We use (inputs/mnist_data/dataset: azureml:mnist-dataset:1.) You can remove the :1 suffix to use the most current version or update this value when needed.
Now we’re ready to train!
Starting Model Training
As with all the steps before, to start the training, we can rely on the Visual Studio Code Machine Learning extension, or we can run the code using the Azure CLI directly:
$ az ml job create --file aml-job-train.yml --subscription $SUBSCRIPTION
--resource-group $GROUP --workspace-name $WORKSPACE
If we execute the job using the extension, in the logs we get the RunId (guid) and WebView URL in this format: https://ml.azure.com/runs/<run_id>?wsid=/subscriptions/<subscription_id>/resourcegroups/azureml-rg/workspaces/demo-ws.
Clicking this link takes us to our run within the ml.azure.com console:
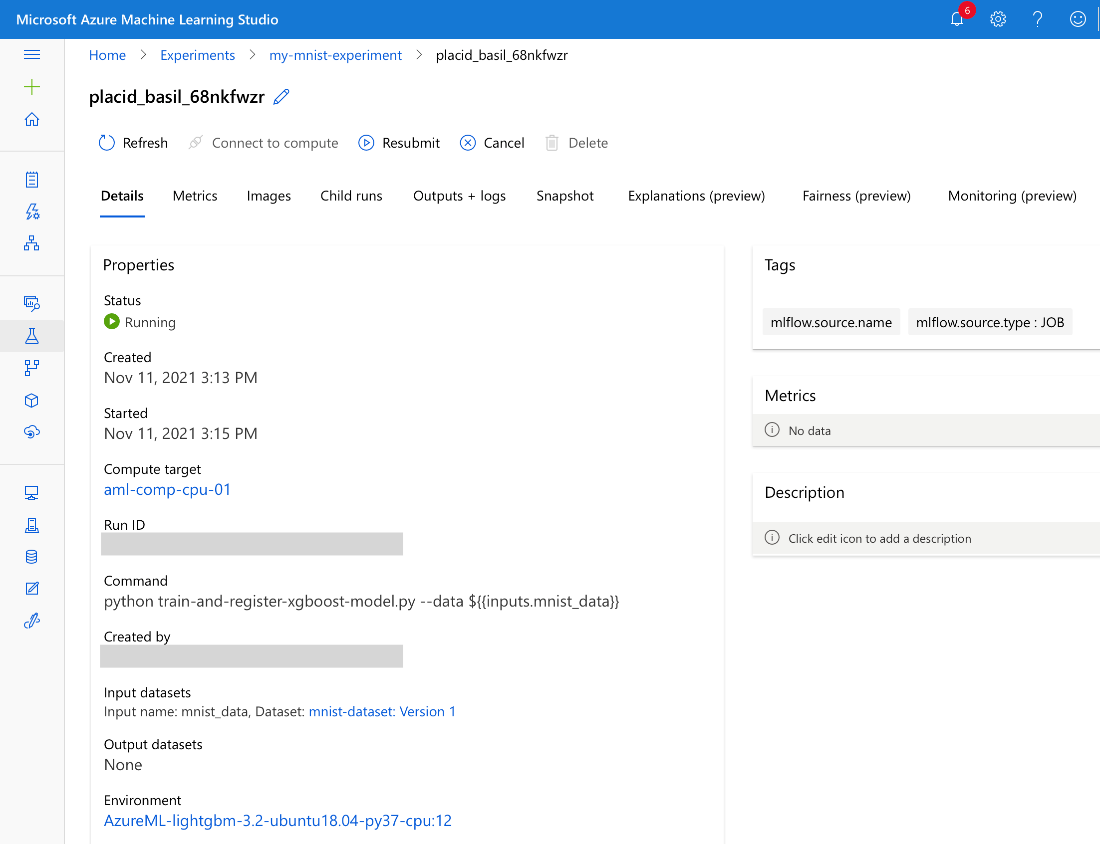
In our simple case, the training itself doesn’t take long. The longest time will most likely be preparing to compute. It could be much longer if we used a custom environment, though, as we would have to build its image before first use.
As promised earlier, we can also monitor our job’s progress without leaving Visual Studio Code. For example, logs are accessible directly from the studio under the Experiments node:
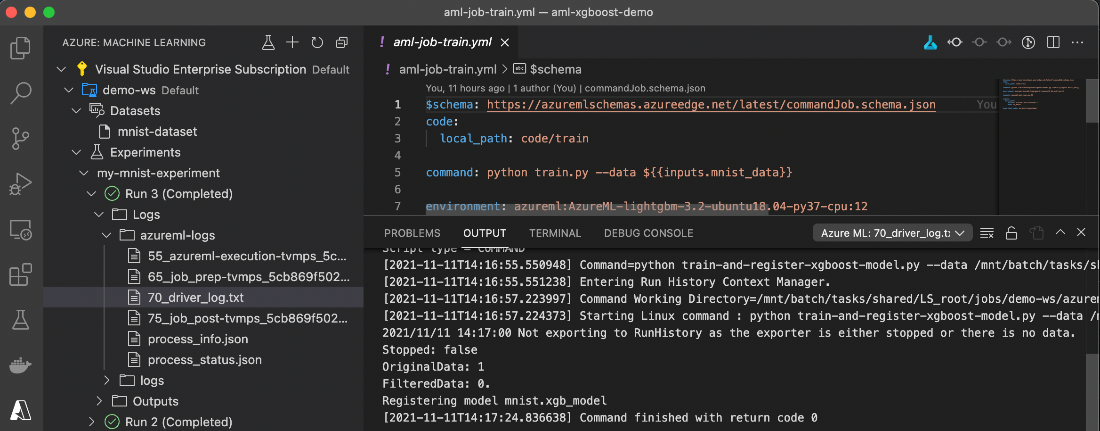
If you’re new to Azure Machine Learning, the number of log files may be confusing. If everything goes well, the most important file is 70_driver_log.txt. It includes all the logs, console outputs, and errors generated by the training code running in the compute instance.
Note that depending on the rollout in your Azure region, you may have to use a different Azure ML runtime with a different log file structure to handle your training. If you prefer the old one, make sure that you add the following lines to your training job definition:
environment_variables:
AZUREML_COMPUTE_USE_COMMON_RUNTIME: "false"
When the training job completes, we should see the newly registered model, or model version, after each run:
Let's go back to the Microsoft Azure Machine Learning Studio web portal. We can check additional details, including our model’s accuracy on the test dataset, logged at the end of the training:
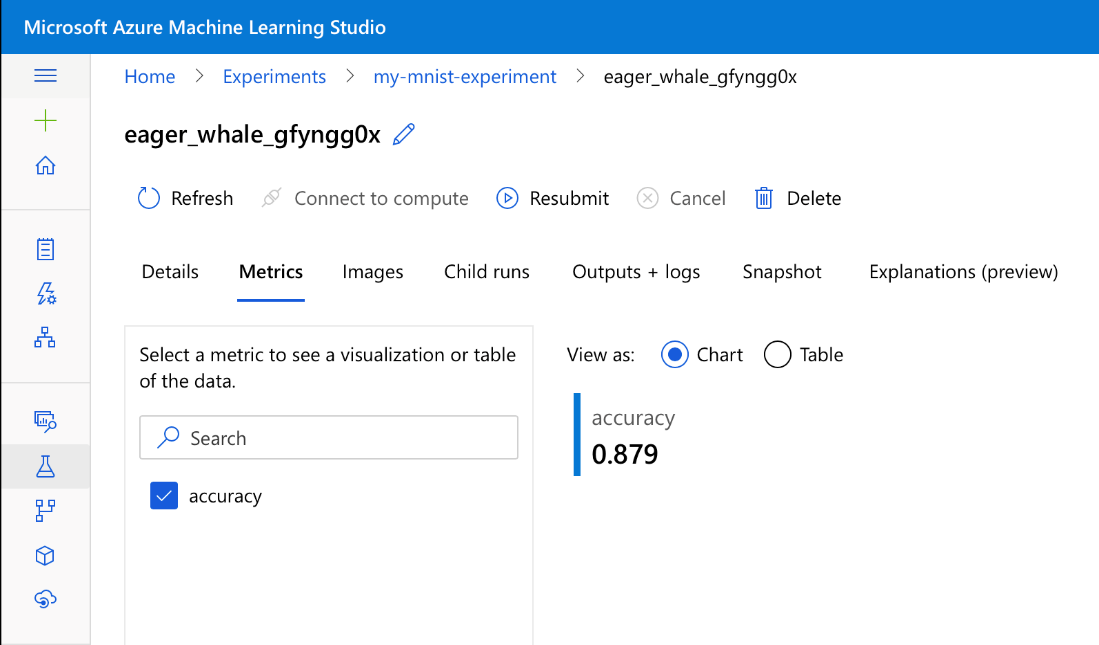
The results are not bad, but far from state-of-the-art results, which would be 1.0. Let’s remember that we have used a simple model with a restricted configuration, though. We’re sure you can improve it significantly without much effort!
Next Steps
This article has shown how to train the XGBoost model to recognize handwritten digits using the Azure cloud without leaving Visual Studio Code. If you replace the MNIST dataset with other images, you can use this approach to train for any image classification tasks. However, the XGBoost model may not be the best model to do it.
The following article shows you how to do something similar with a custom PyTorch model, even if you don’t have Visual Studio Code.
To learn everything you need to get started with Azure Machine Learning, check out Quickstart: Create workspace resources.

