This article shows the code to create and train a model using PyTorch and then run model training on Azure ML. This will be followed by a brief demonstration to show that the trained model works as expected.
In this series, we work through several approaches to creating and using machine learning models in Python on Azure. The previous article used Visual Studio Code with Machine Learning extensions to train an XGBoost model on Azure. This article shows how to use GitHub Codespaces to work with Visual Studio Code using only a web browser. In addition, it shows how to automatically train the PyTorch model on Azure every time we commit changes to our repository. To achieve this, we use GitHub Actions.
You can find the sample code for this article on GitHub.
Prerequisites
To follow examples from this article, you need a web browser and access to an Azure subscription. If you don’t have a subscription, you can sign up for a free Azure account. In addition, to configure GitHub Actions that use Azure resources, you also require admin access to Azure AD assigned to your subscription.
Setting GitHub Codespaces
If you ever needed to access a fully-functional development environment without installing anything — for example, from a tablet — now you can. GitHub Codespaces provides access to an environment with Visual Studio Code in the cloud. Currently, it’s not enough to have a free GitHub account to use it, though. It requires the GitHub Team or Enterprise plan.
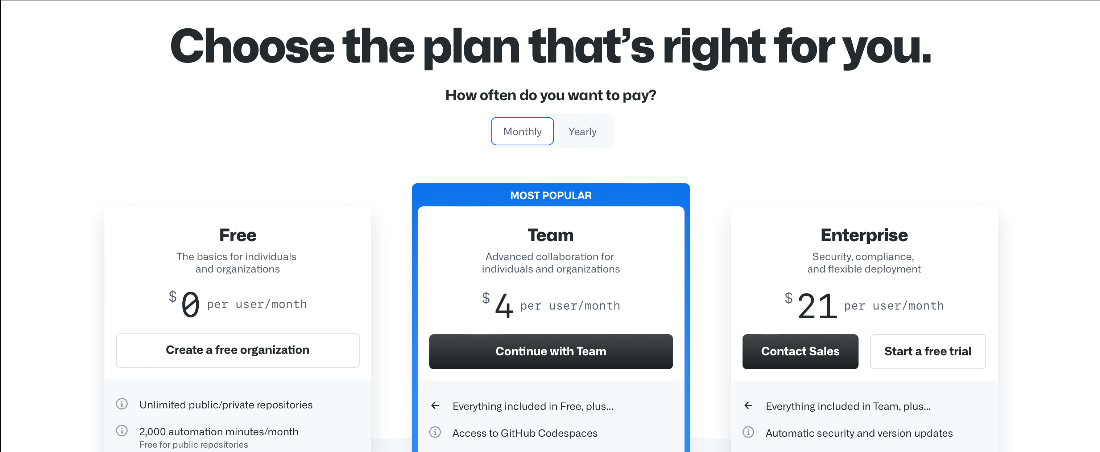
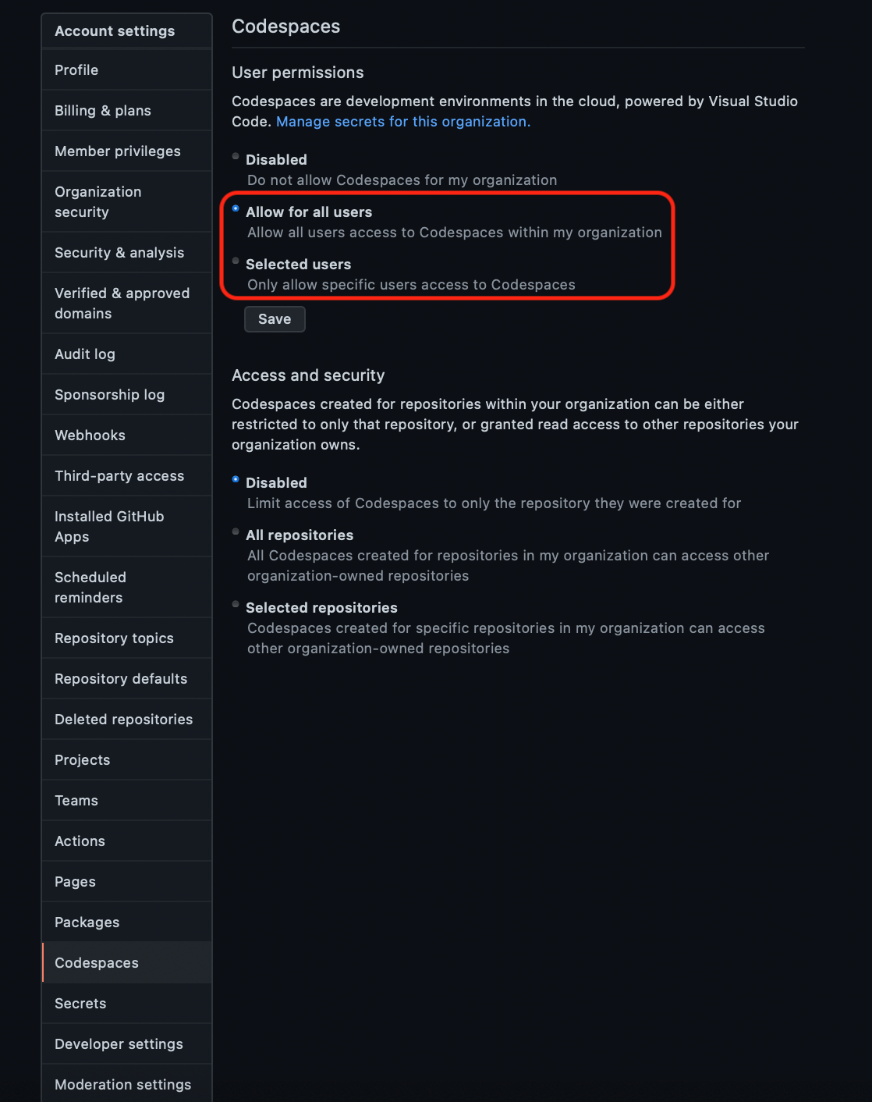
If you don’t yet have access to a GitHub Teams plan, you’ll need one to continue. To create it, click Continue with Team and provide your organization’s details, including payment details. You can use your regular GitHub login as a member name here. The team plan alone isn’t enough to use Codespaces, though. To activate this feature, you need to go to your organization’s settings, select Codespaces from the side menu, and enable it for all or selected users.
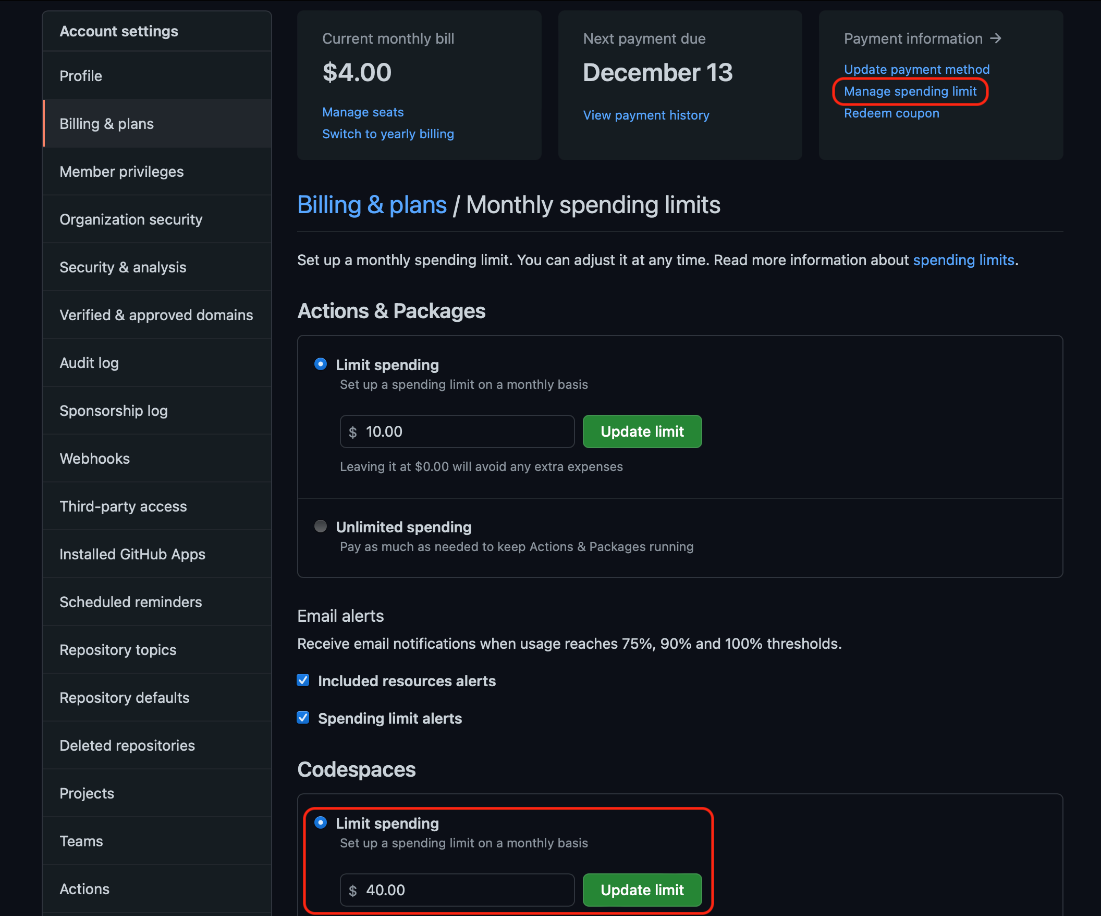
Additionally, you need to define the associated spending limit with any value above $0. To do so, select Billing & plans from the organization’s settings side menu, then Manage spending limit:
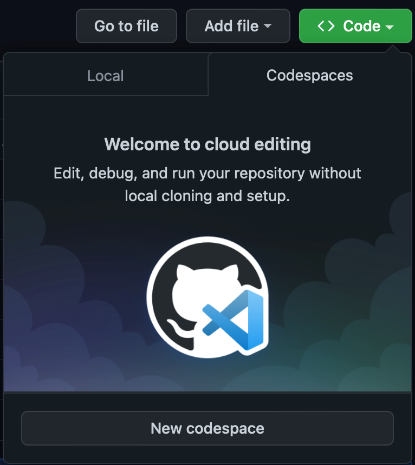
Finally, after these steps, you should have access to the new Codespaces tab on the Code menu of any of your organization’s repositories.
When you create a codespace, it’s always in a single repository. So, create one before you continue. You can use the provided sample code here, but make sure to copy its content to your repository’s root.
Now, when you click New codespace, you have the option to select the size of the virtual machine (VM) that runs in your environment:
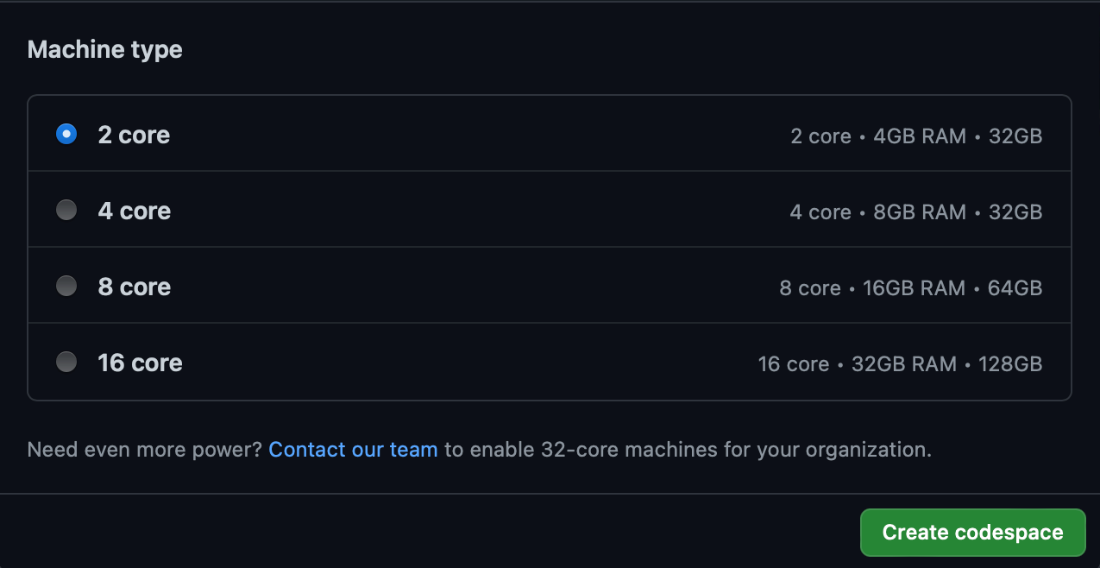
Typically for cloud resources, the more powerful the configuration, the more it costs for every hour of use. Because the plan is to delegate all actual work to Azure, the smallest two-core instance is acceptable.
Configuring the Codespace Environment
After selecting the Create codespace option, the new cloud environment should be available in just a few moments. It’s a fully functional Visual Studio Code with all the bells and whistles but available using a web browser.
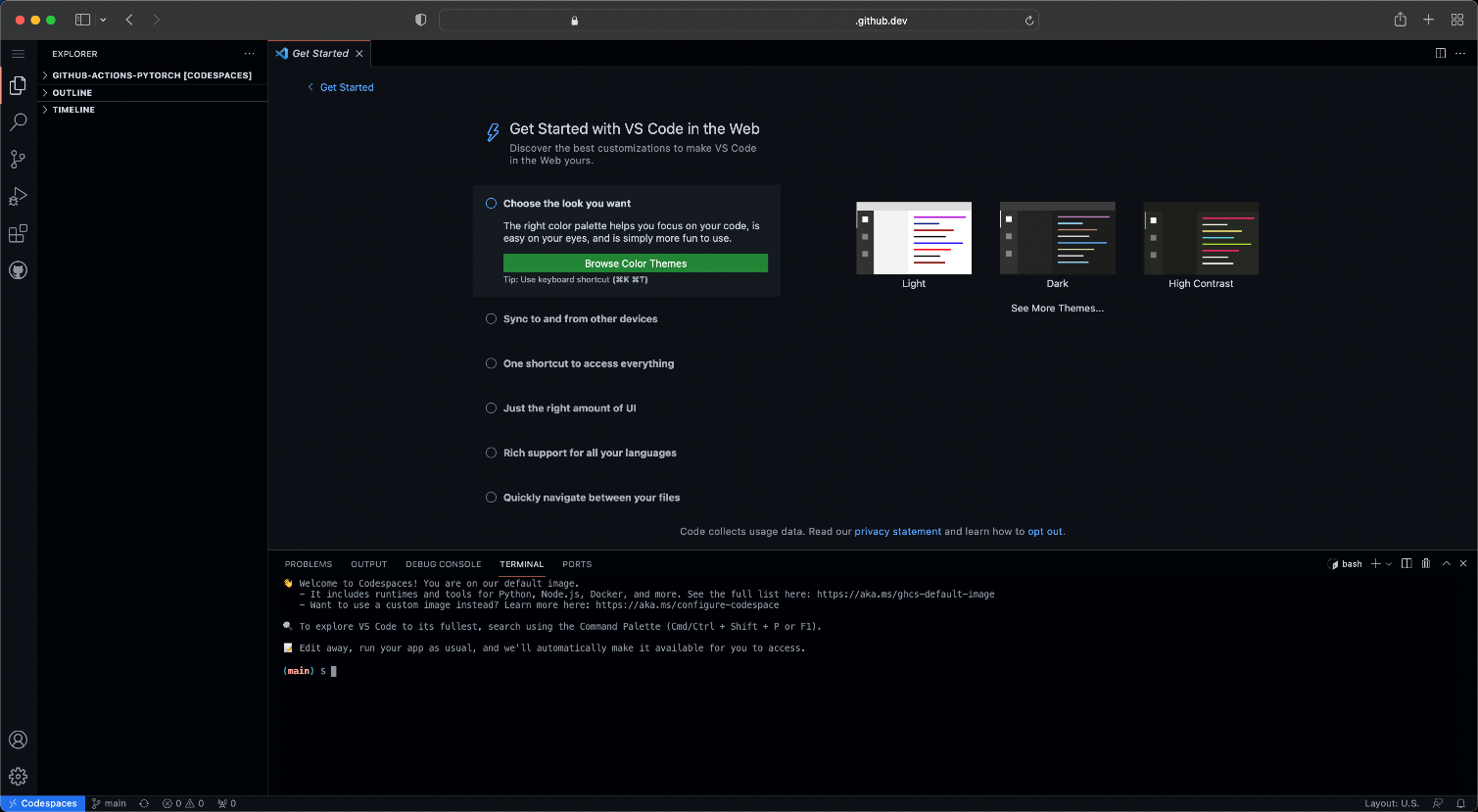
A whole array of new codespaces-related configuration options is available if needed. Just press the standard Visual Studio Code shortcut (Cmd/Ctrl+Shift+P), then start typing “Codespaces” to filter the options:
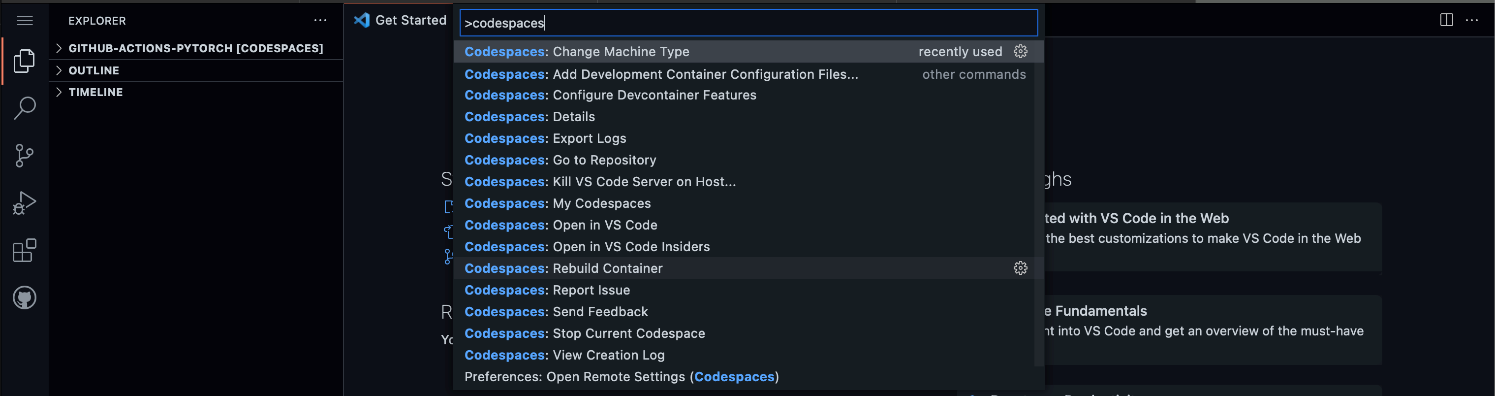
For example, to change the development environment, select Add Development Container Configuration Files and then one of the predefined templates.
For our purposes, the default environment contains everything we need (namely, the azure-cli and python 3.8), so we can skip this step. But we need a machine learning extension to azure-cli (still in preview). We can add it using the Azure CLI:
$ az extension add -n ml -y
Setting Up the Azure Machine Learning Workspace
If you haven’t followed the examples in the previous article in this series yet, you can do it now from your codespace. In any case, to continue, we need an Azure Machine Learning workspace.
We can configure the workspace following steps from the previous article, using the Azure Portal or using azure-cli in the codespace. Here, we use azure-cli, starting from the login to Azure:
$ az login —use-device-code
After following the instructions returned by the command to log in, we create the resource group and Azure Machine Learning workspace:
$ export SUBSCRIPTION="<your-subscription-id>"
$ export GROUP="azureml-rg"
$ export WORKSPACE="demo-ws"
$ export LOCATION="<your-location (e.g., westeurope)>"
$ az group create -n $GROUP -l $LOCATION
$ az ml workspace create --name $WORKSPACE --subscription $SUBSCRIPTION --resource-group $GROUP
Downloading an MNIST Dataset
Now we need to download the MNIST dataset using the code introduced in the previous article:
import os
import urllib.request
DATA_FOLDER = 'datasets/mnist-data'
DATASET_BASE_URL = 'https://azureopendatastorage.blob.core.windows.net/mnist/'
os.makedirs(DATA_FOLDER, exist_ok=True)
urllib.request.urlretrieve(
os.path.join(DATASET_BASE_URL, 'train-images-idx3-ubyte.gz'),
filename=os.path.join(DATA_FOLDER, 'train-images.gz'))
urllib.request.urlretrieve(
os.path.join(DATASET_BASE_URL, 'train-labels-idx1-ubyte.gz'),
filename=os.path.join(DATA_FOLDER, 'train-labels.gz'))
urllib.request.urlretrieve(
os.path.join(DATASET_BASE_URL, 't10k-images-idx3-ubyte.gz'),
filename=os.path.join(DATA_FOLDER, 'test-images.gz'))
urllib.request.urlretrieve(
os.path.join(DATASET_BASE_URL, 't10k-labels-idx1-ubyte.gz'),
filename=os.path.join(DATA_FOLDER, 'test-labels.gz'))
Now that we have this code in the download-dataset.py file, we can run it.
$ python download-dataset.py
Uploading our Dataset to the Azure Machine Learning Workspace
The preferred way of handling data in the Azure Machine Learning workspace is using a dataset. To create a dataset from the just-downloaded files, we prepare the aml-mnist-dataset.yml file with its definition:
$schema: https:
name: mnist-dataset
version: 1
local_path: datasets/mnist-data
Next, we create the dataset using azure-cli:
$ az ml dataset create --file aml-mnist-dataset.yml --subscription $SUBSCRIPTION
--resource-group $GROUP --workspace-name $WORKSPACE
Writing PyTorch Model Training Code
Now that we have registered the dataset in the Azure Machine Learning workspace, we can write code to train our model. We use the PyTorch framework and save all the code to the code/train/train.py file.
Let’s start with imports:
import os
import gzip
import struct
import numpy as np
import argparse
import mlflow
import torch
import torch.optim as optim
from torch.nn import functional as F
from torch import nn
from torchvision import transforms
from torch.utils.data import DataLoader
from azureml.core import Run
from azureml.core.model import Model
Next, we need the code to load, decode, normalize, and reshape the images from our dataset:
def load_dataset(dataset_path):
def unpack_mnist_data(filename: str, label=False):
with gzip.open(filename) as gz:
struct.unpack('I', gz.read(4))
n_items = struct.unpack('>I', gz.read(4))
if not label:
n_rows = struct.unpack('>I', gz.read(4))[0]
n_cols = struct.unpack('>I', gz.read(4))[0]
res = np.frombuffer(gz.read(n_items[0] * n_rows * n_cols), dtype=np.uint8)
res = res.reshape(n_items[0], n_rows * n_cols) / 255.0
else:
res = np.frombuffer(gz.read(n_items[0]), dtype=np.uint8)
res = res.reshape(-1)
return res
X_train = unpack_mnist_data(os.path.join(dataset_path, 'train-images.gz'), False)
y_train = unpack_mnist_data(os.path.join(dataset_path, 'train-labels.gz'), True)
X_test = unpack_mnist_data(os.path.join(dataset_path, 'test-images.gz'), False)
y_test = unpack_mnist_data(os.path.join(dataset_path, 'test-labels.gz'), True)
return X_train.reshape(-1,28,28,1), y_train, X_test.reshape(-1,28,28,1), y_test
Now, we can create a simple convolutional neural network (CNN) in PyTorch:
class NetMNIST(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2,2))
x = F.max_pool2d(F.dropout(F.relu(self.conv2(x)), p=0.2), (2,2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, p=0.2, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
PyTorch requires a custom dataset class to handle data loading. For this purpose, we create a class that supports both labeled data (for training) and unlabeled data (for inference):
class DatasetMnist(torch.utils.data.Dataset):
def __init__(self, X, y=None):
self.X, self.y = X,y
self.transform = transforms.Compose([
transforms.ToTensor()])
def __len__(self):
return len(self.X)
def __getitem__(self, index):
item = self.transform(self.X[index])
if self.y is None:
return item.float()
label = self.y[index]
return item.float(), np.long(label)
Now it’s time for training. We start with the method to train a single epoch. Note the use of MLflow logging here. It’s a recommended approach in Azure ML, and it works in the cloud or locally.
def train_epoch(model, device, train_loader, optimizer, epoch):
model.train()
epoch_loss = 0.0
epoch_acc = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
_, preds = torch.max(output.data, 1)
epoch_acc += (preds == target).sum().item()
if batch_idx % 200 == 0 and batch_idx != 0:
print(f"[{epoch:2d}:{batch_idx:5d}] \tBatch loss: {loss.item():.5f}, \
Epoch loss: {epoch_loss:.5f}")
epoch_acc /= len(train_loader.dataset)
print(f"[{epoch:2d} EPOCH] \tLoss: {epoch_loss:.6f} \tAcc: {epoch_acc:.6f}")
mlflow.log_metrics({
'loss': epoch_loss,
'accuracy': epoch_acc})
Now we use this method to train all epochs and save the trained model:
def train_model(X, y, model_filename, epochs=5, batch_size=64):
RANDOM_SEED = 101
use_cuda = torch.cuda.is_available()
torch.manual_seed(RANDOM_SEED)
device = torch.device("cuda" if use_cuda else "cpu")
print(f"Device: {device}")
if use_cuda:
cuda_kwargs = {'num_workers': 1,
'pin_memory': True,
'shuffle': True}
else:
cuda_kwargs = {}
train_dataset = DatasetMnist(X, y)
train_loader = torch.utils.data.DataLoader(train_dataset, \
batch_size=batch_size, **cuda_kwargs)
model = NetMNIST().to(device)
optimizer = optim.Adam(model.parameters())
for epoch in range(1, epochs+1):
train_epoch(model, device, train_loader, optimizer, epoch)
torch.save(model.state_dict(), model_filename)
After training the model, we want to evaluate it on test data. The method below loads the previously saved model then uses it for predictions and compares results to known test labels:
def evaluate_model(X, y, model_filename, batch_size=64):
test_dataset = DatasetMnist(X)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
model = NetMNIST()
model.load_state_dict(torch.load(model_filename))
preds = []
with torch.no_grad():
for batch in test_loader:
batch_preds = model(batch).numpy()
preds.extend(np.argmax(batch_preds, axis=1))
accscore = (preds == y).sum().item()
accscore /= len(test_dataset)
mlflow.log_metric('test_accuracy', accscore)
We register the trained model in the Azure Machine Learning workspace:
def register_model(ws, model_filename):
model = Model.register(
workspace=ws,
model_name=model_filename,
model_path=model_filename,
model_framework=Model.Framework.PYTORCH,
model_framework_version=torch.__version__
)
The last two helper methods are to get the current Azure Machine Learning workspace and parse execution parameters. Here, we parse just one: data:
def get_aml_workspace():
run = Run.get_context()
ws = run.experiment.workspace
return ws
def parse_arguments():
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, required=True)
args = parser.parse_known_args()[0]
return args
Finally, we’re ready for our script’s primary method.
def main():
args = parse_arguments()
ws = get_aml_workspace()
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.start_run()
X_train, y_train, X_test, y_test = load_dataset(args.data)
model_filename = "mnist.pt_model"
train_model(X_train, y_train, model_filename)
evaluate_model(X_test, y_test, model_filename)
register_model(ws, model_filename)
if __name__ == "__main__":
main()
Note the MLflow related code. The mlflow.set_tracing_uri method ensures saving logged information in the Azure: Machine Learning workspace.
Introducing GitHub Actions
We have (almost) all the code we need to run the training locally. We want to use Azure for training, though. Also, we want the training to run automatically every time we push changes to our repository. We use GitHub Actions and azure-cli to achieve this. It’s worth pointing out that GitHub Actions aren’t directly related to the codespaces. You can use this mechanism in any GitHub repository, even with only a free account.
GitHub Actions allow us to create jobs that execute automatically — for example, a push to the repository, a pull request, and many other triggers. Following the convention-over-configuration approach, we define our actions in one or more YAML files located in the .github/workflows folder in our repository’s root folder.
Using GitHub Actions with Azure ML
While there’s a set of dedicated Azure Machine Learning tasks for GitHub Actions, such as aml-workspace, aml-compute, or aml-run, they’re currently marked as depreciated.
The recommended alternative is to use azure-cli instead, even though the azure-cli solution is still in preview. Still, a significant advantage of using azure-cli in GitHub Actions is that we can use the same scripts to run Azure ML tasks manually from the command line and automatically using GitHub Actions. With this in mind, we follow the azure-cli approach.
Defining Azure ML Jobs
To continue, we need to define the Azure ML jobs to set up compute resources and run the training. These jobs are practically identical, as was the case in the previous article.
The compute definition job in the aml-compute-cpu.yml file is as follows:
$schema: https:
name: aml-comp-cpu-01
type: amlcompute
size: Standard_D2_v2
min_instances: 0
max_instances: 1
idle_time_before_scale_down: 3600
location: westeurope
The training job in the aml-job-train.yml file is as follows:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code:
local_path: code/train
command: python train.py --data ${{inputs.mnist_data}}
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu:10
compute: azureml:aml-comp-cpu-01
environment_variables:
AZUREML_COMPUTE_USE_COMMON_RUNTIME: "false"
inputs:
mnist_data:
dataset: azureml:mnist-dataset:1
mode: ro_mount
experiment_name: pytorch-mnist-experiment
The most significant changes here are a different environment (with PyTorch installed) and a bigger compute size (the previous one wouldn’t fit the PyTorch environment). Considering the size of our tasks, we’re perfectly fine with CPU-only calculations. You may need to compute with a GPU for a more extensive dataset and model.
Note the MNIST dataset version. We use: inputs/mnist_data/dataset: azureml:mnist-dataset:1. You can remove the :1 suffix to use the most current version, or you can update this value when needed.
Configuring a GitHub Service Principal
Executing any operation on Azure requires authorization. GitHub Actions aren’t exceptions. A service principal is the correct way of authorizing applications to use Azure resources. The following azure-cli command creates a new Azure service principal and returns its secret:
$ az ad sp create-for-rbac --name $AML_SP \
--role contributor \
--scopes /subscriptions/$SUBSCRIPTION/resourceGroups/$GROUP \
--sdk-auth
This command’s output should be a JSON with a schema like the following:
{
"clientId": "<GUID>",
"clientSecret": "<GUID>",
"subscriptionId": "<GUID>",
"tenantId": "<GUID>",
(...)
}
Remember this value. If you lose it, you must create a new secret. If the previous command has failed, ensure that you have administrator permissions for Azure AD assigned to your subscription. After success, we go back to our repository’s settings and add the returned JSON as an AZURE_CREDENTIALS secret:
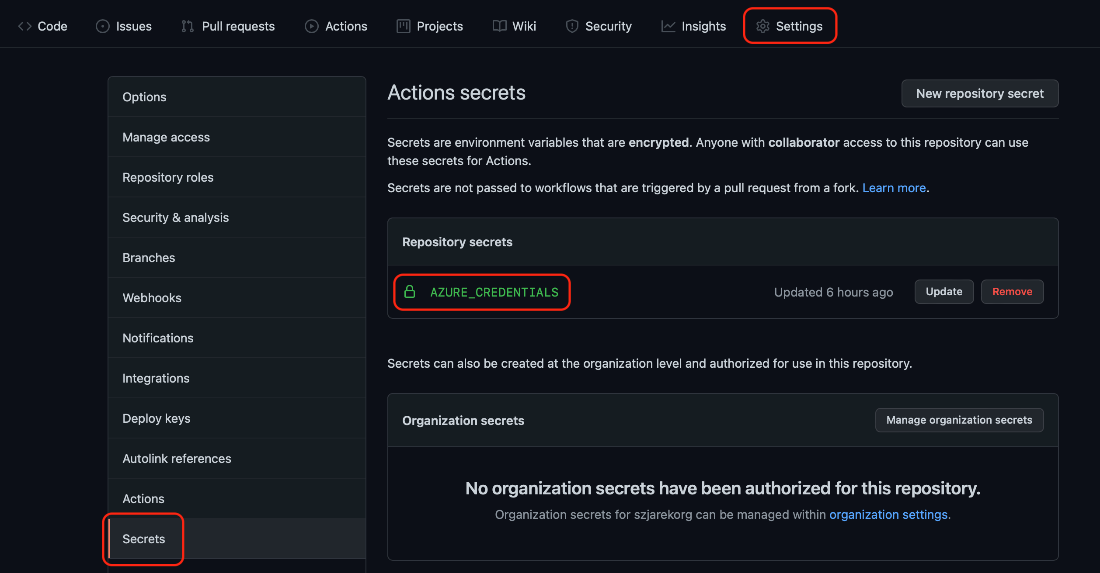
Now we can create a GitHub workflow for our training.
Using a GitHub Workflow for Model Training
Technically, we have two options for running azure-cli commands in GitHub Actions. First, we can run them directly using the workflow’s run step because azure-cli is available by default on GitHub workers. Alternatively, we can use a dedicated Azure CLI action. If you want to control the azure-cli version explicitly, you need to rely on the latter. This control may backfire, though.
We always need at least two actions to execute code on Azure. First is the Azure Login action, then the following step with actual logic. The issue is that while we can control the azure-cli version used by the Azure CLI action, we don’t have the option to do the same for the Azure Login action. It may lead to a situation where the fixed older azure-cli version becomes incompatible with the current Azure Login action. This situation is worth remembering, as it did happen not so long ago. In any case, you can always use Azure CLI.
The Azure CLI version of our training job definition looks like this:
on:
push:
branches: [ main ]
name: AzureMLTrain
jobs:
setup-aml-and-train:
runs-on: ubuntu-latest
env:
AZURE_SUBSCRIPTION: "<your-subscription-id>"
RESOURCE_GROUP: "azureml-rg"
AML_WORKSPACE: "demo-ws"
steps:
- name: Checkout Repository
id: checkout_repository
uses: actions/checkout@v2
- name: Azure Login
uses: azure/login@v1
with:
creds: ${{ secrets.AZURE_CREDENTIALS }}
allow-no-subscriptions: true
- name: Azure CLI script - Prepare and run MNIST Training on Azure ML
uses: azure/CLI@v1
with:
azcliversion: 2.30
inlineScript: |
az extension add -n ml -y
az ml compute create --file aml-compute-cpu.yml --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP --workspace-name $AML_WORKSPACE
az ml job create --file aml-job-train.yml --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP --workspace-name $AML_WORKSPACE
First, we define triggers for our job (push on the main branch), then we configure worker and environment variables. Finally, we define three steps to create and update the compute and run the training:
- Repository checkout
- Login to Azure
- Execution of the Azure ML sub-steps
Alternatively, you can achieve the same effect by replacing the azure/CLI@v1 step with the following set of “vanilla” run items:
- name: Add ML Extension To azure-cli
run: az extension add -n ml -y
- name: Create or Update AML Workspace Compute
run: az ml compute create --file aml-compute-cpu.yml --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP --workspace-name $AML_WORKSPACE
- name: Run Training on AML Workspace
run: az ml job create --file aml-job-train.yml --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP --workspace-name $AML_WORKSPACE
Triggering the GitHub Training Workflow
All we need to run the defined workflow is to commit and push our changes to the repository. Then, when we navigate to our repository’s Actions tab, we can monitor its execution progress:
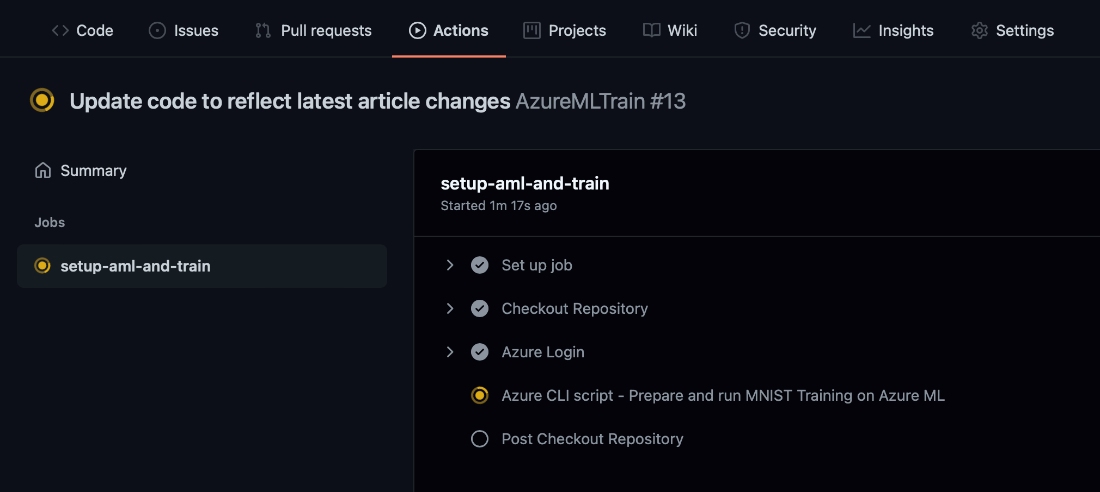
If everything goes well, the action initiates the training in our Azure: Machine Learning workspace. The GitHub workflow finishes immediately, while the Azure training continues.
Monitoring Training on Machine Learning
We launch Microsoft Azure Machine Learning Studio to monitor the training.
If we’re too fast, we may need to wait until our compute’s VM is ready.
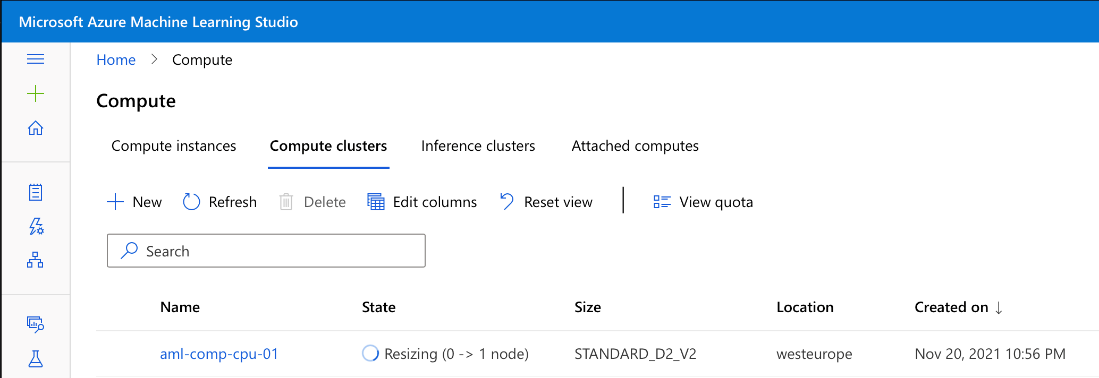
Then, we can monitor the training’s progress.
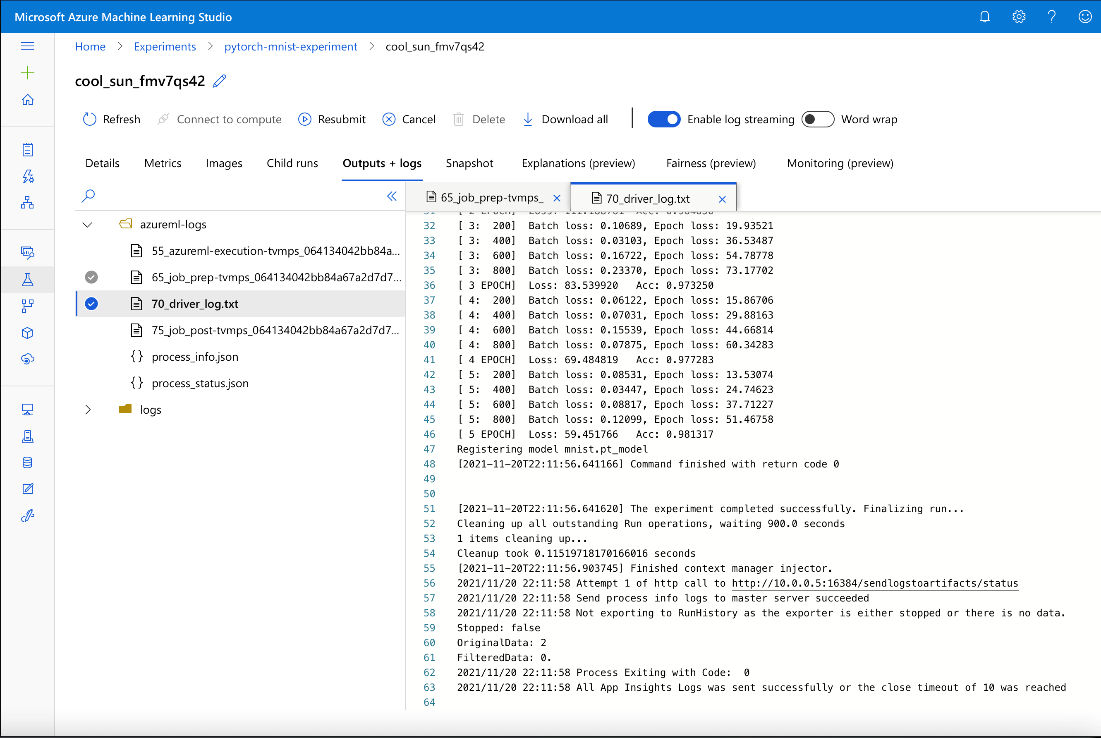
Note that depending on the rollout in your Azure region, Azure might use a different ML runtime to run your training (with a different log file structure). If you prefer the old one, ensure that you have the following lines in your training job definition file, aml-job-train.yml:
environment_variables:
AZUREML_COMPUTE_USE_COMMON_RUNTIME: "false"
Apart from raw logs, we can also observe metrics and other information logged by MLflow, both during and after completed training:
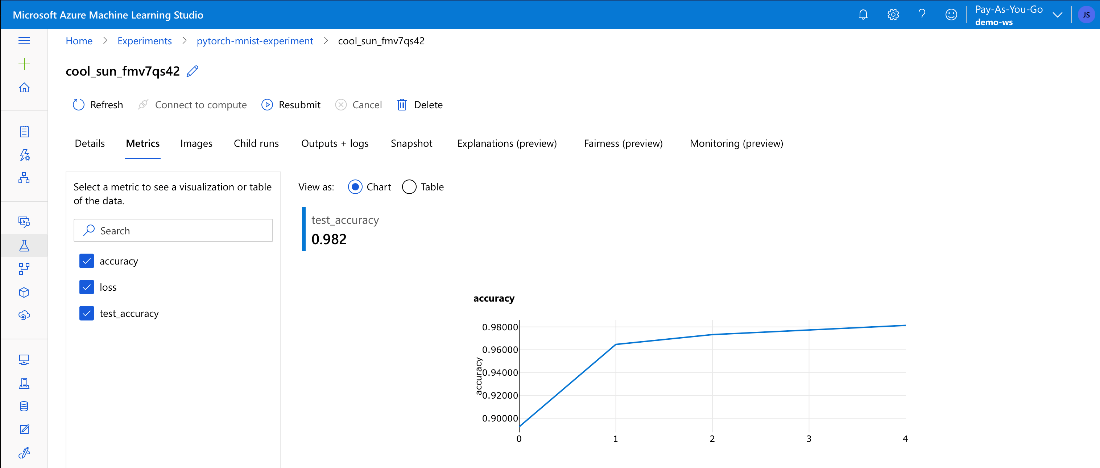
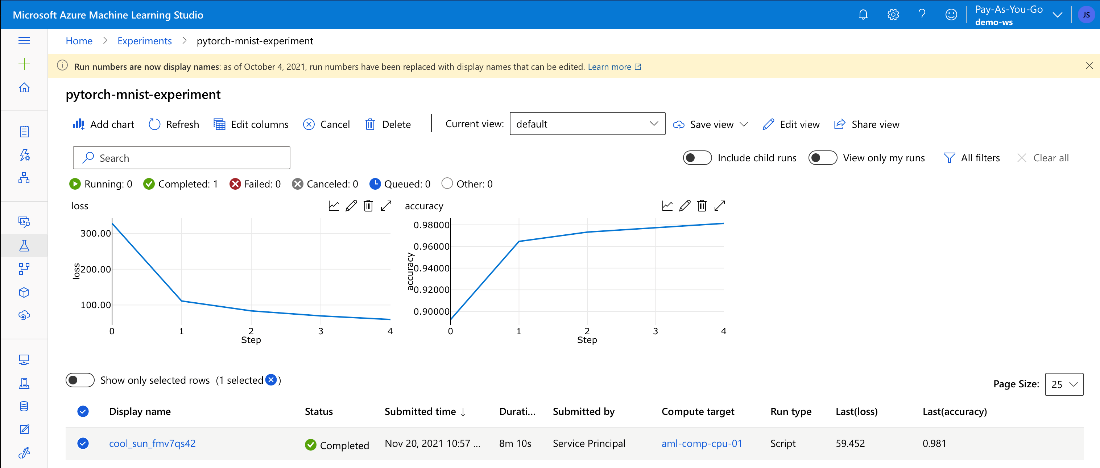
Great! As we can see, our accuracy achieved 98 percent.
Cleaning Up Resources on Azure and GitHub
To avoid paying for unused resources, we must stop or delete them. The safest solution is to remove the whole resource group. If we want to keep our data and history, we should at least stop all the compute clusters we aren’t using anymore. Don’t worry if you forget about it, though. Our current configuration decommissions them automatically after an hour of inactivity.
In addition to Azure resources, we also need to stop GitHub’s codespace instances. We can do this after selecting Manage all on the Code tab:
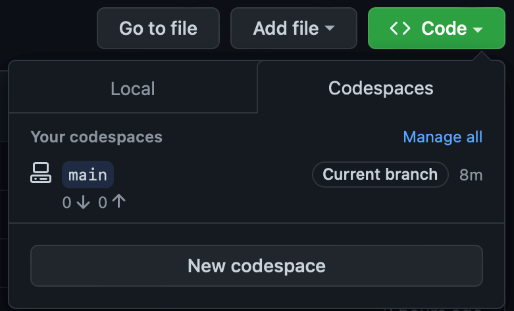
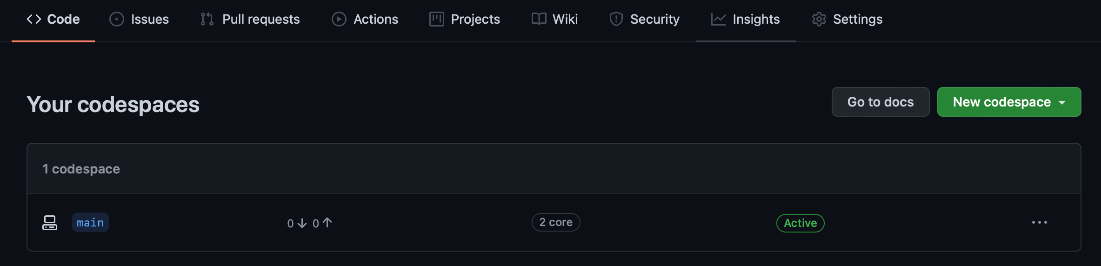
We must click the ellipsis (…) and the stop code space option for each active codespace instance.
Next Steps
This article has shown how to automatically train the PyTorch model using GitHub codespaces, Actions, and the Azure cloud. With little effort, you should be able to adapt this approach to any image classification task.
We started with the model training code in this and the previous article. A research and experimentation phase usually precedes this step in real-life ML projects. One of the most popular sets of tools supporting such kind of work is Jupyter notebooks and JupyterLab. The following article shows how to run notebooks using the Azure ML workspace.
To learn everything you need to get started with Azure Machine Learning, check out Quickstart: Create workspace resources.

