
Want to try it yourself? First, sign up for bit.io to get instant access to a free Postgres database. Then clone the GitHub repo and give it a try!
The problem
Public and private data sources are plentiful but also problematic:
- Source data may get updated frequently but require substantial preparation before use.
- Already-prepared secondary sources may exist but be stale and lack provenance.
- Multiple data sources with heterogeneous sources and formats may need to be integrated for a particular application.
Fortunately, there is a general computing pattern for mitigating these problems and getting data in the right location and format for use: "Extract, Transform, Load" (ETL).
ETL implementations vary in complexity and robustness, ranging from scheduling of simple Python and Postgres scripts on a single machine to industrial-strength compositions of Kubernetes Clusters, Apache Airflow, and Spark.
Here, we will walk through a simple Python and Postgres implementation that can get you started quickly. We will walk through key code snippets together, and the full implementation and documentation is available in this repo.
Extract, Transform, Load
According to Wikipedia:
Extract, Transform, Load (ETL) is the general procedure of copying data from one or more sources into a destination system which represents the data differently from the source(s) or in a different context than the source(s).
In other words — we use ETL to extract data from one or more sources so we can transform it into another representation that gets loaded to a separate destination.
Rather than give hypothetical examples, we’ll jump right into a demonstration with a real problem — keeping a clean dataset of US county-level COVID cases, deaths, and vaccinations up to date in a Postgres database. You can see the end product in our public Postgres database.
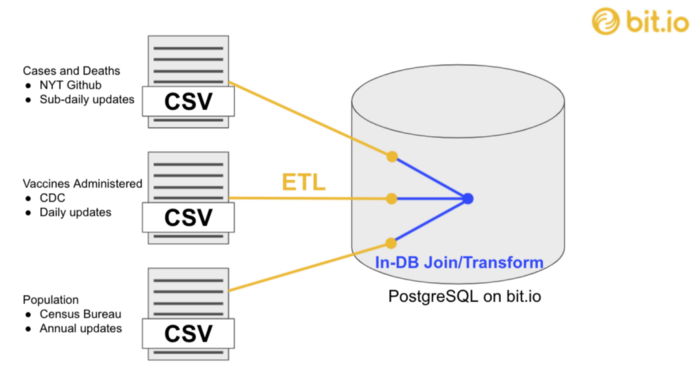
A scheduled ETL process helps us get prepared data into a common database where we can further join, transform, and access the data for particular use cases such as analytics and ML.
Extract
The first ETL step is extracting data from one or more sources into a format that we can use in the transform step. We will use pandas for the transform step, so our specific objective is to extract the source data into pandas DataFrames.
We will work with three data sources:
- The New York Times compilation of daily, county-level COVID cases and deaths (updated multiple times per day)
- CDC counts of vaccines administered per county (updated daily)
- US Census Bureau 5-Year American Community Survey estimates of county-level populations (updated annually)
The first two sources are accessible via direct CSV file download URLs. The census data is available manually through a web app or programmatically through an API. The census data is only updated annually, so we manually downloaded a CSV file to a local directory using the web app (the file is provided in the repo).
We used the code below to extract these two types of CSV file sources into pandas DataFrames. csv_from_get_request handles URL downloads using the Python requests package, and csv_from_local handles local CSV files.
1 """Provides extraction functions.
2 Currently only supports GET from URL or local file.
3 """
4
5 import io
6
7 import pandas as pd
8 import requests
9
10
11 def csv_from_get_request(url):
12 """Extracts a data text string accessible with a GET request.
13 Parameters
14 ----------
15 url : str
16 URL for the extraction endpoint, including any query string
17 Returns
18 ----------
19 DataFrame
20 """
21 r = requests.get(url, timeout=5)
22 data = r.content.decode('utf-8')
23 df = pd.read_csv(io.StringIO(data), low_memory=False)
24 return df
25
26
27 def csv_from_local(path):
28 """Extracts a csv from local filesystem.
29 Parameters
30 ----------
31 path : str
32 Returns
33 ----------
34 DataFrame
35 """
36 return pd.read_csv(path, low_memory=False)
With the data extracted into DataFrames, we’re ready to transform the data.
Transform
In the second step, we transform the pandas DataFrames from the extract step to output new DataFrames for the load step.
Data transformation is a broad process that can include handling missing values, enforcing types, filtering to a relevant subset, reshaping tables, computing derived variables and much more.
Compared to the extract and load steps, we are less likely to be able to reuse code for the entire transform step due to the particulars of each data source. However, we certainly can (and should) modularize and reuse common transformation operations where possible.
For this simple implementation, we define a single transformation function for each data source. Each function contains a short pandas script. Below, we show the transformation function for the NYT county-level COVID case and death data. The other data sources are handled similarly.
"""Provides optional transform functions for different data sources."""
import pandas as pd
def nyt_cases_counties(df)
df['date'] = pd.to_datetime(df['date'])
df['fips'] = df['fips'].astype(str).str.extract('(.*)\.', expand=False).str.zfill(5)
df = df.loc[df['state'] != 'Puerto Rico'].copy()
df['deaths'] = df['deaths'].astype(int)
return df
We are enforcing data types on lines 9 and 14, extracting standardized FIPS codes on line 11 to support joining on county to other data sources, and handling missing values by dropping Puerto Rico on line 13.
With the data transformed into new DataFrames, we’re ready to load to a database.
Load
In the final ETL step, we load the transformed DataFrames into a common destination where they will be ready for analytics, ML, and other use cases. In this simple implementation, we will use a PostgreSQL database on bit.io.
bit.io is the easiest way to instantly create a standards-compliant Postgres database and load your data into one place (and it’s free for most hobby-scale use cases). You simply sign up (no credit card required), follow the prompts to "create a repo" (your own private database), then follow the "connecting to bit.io" docs to get a Postgres connection string for your new database.
After signing up, you can create a private PostgreSQL database in seconds and retrieve a connection string for SQLAlchemy
Note: You can use the following code with any Postgres database, but you will be on your own for database setup and connection.
With our destination established, we’re ready to walk through the code for the load step. This step requires more boilerplate than the others to handle interactions with the database. However, unlike the transform step, this code can generally be reused for every pandas-to-Postgres ETL process.
The primary function in the load step is to_table. This function takes in the DataFrame (df) from the transform step, a fully-qualified destination table name (examples in the next section), and a Postgres connection string pg_conn_string.
Lines 18–12 validate the connection string, parse the schema (bit.io "repo") and table from the fully-qualified table name, and create a SQLAlchemy engine. The engine is an object that manages connections to the Postgres database for both custom SQL and the pandas SQL API.
Lines 24–28 check if the table already exists (truncated helper _table_exists). If the table already exists, we use SQLAlchemy to execute _truncate table (another truncated helper) which clears all existing data from the table to prepare for a fresh load.
Finally, in lines 30–39, we open another SQLAlchemy connection and use the pandas API to load the DataFrame to Postgres with a fast custom insert method _psql_insert_copy.
1 """Load pandas DataFrames to PostgreSQL on bit.io"""
2
3 from sqlalchemy import create_engine
4
5 def to_table(df, destination, pg_conn_string):
6 """
7 Loads a pandas DataFrame to a bit.io database.
8 Parameters
9 ----------
10 df : pandas.DataFrame
11 destination : str
12 Fully qualified bit.io PostgreSQL table name.
13 pg_conn_string : str
14 A bit.io PostgreSQL connection string including credentials.
15 """
16
17 if pg_conn_string is None:
18 raise ValueError("You must specify a PG connection string.")
19 schema, table = destination.split(".")
20 engine = create_engine(pg_conn_string)
21
22
23 if _table_exists(engine, schema, table):
24 _truncate_table(engine, schema, table)
25 if_exists = 'append'
26 else:
27 if_exists = 'fail'
28
29 with engine.connect() as conn:
30
31 conn.execute("SET statement_timeout = 600000;")
32 df.to_sql(
33 table,
34 conn,
35 schema,
36 if_exists=if_exists,
37 index=False,
38 method=_psql_insert_copy)
39
40
41
42
43
44
Note: we overwrite the entire table here instead of using incremental loads for the sake of simplicity and because some of these historical datasets get both updated and appended. Implementing incremental loads would be more efficient at the expense of slightly more complexity.
Putting the pieces together
That’s it! We have all three ETL steps down. It’s time to put them together as a scheduled process.
We walk through those next steps in Making a Simple Data Pipeline Part 2: Automating ETL.
If you’d like to try this out right away, the full implementation of this simple approach, including scheduling, is available in this repo.
Interested in future Inner Join publications and related bit.io data content? Please consider subscribing to our weekly newsletter.
Appendix
Series overview
This article is part of a four-part series on making a simple, yet effective, ETL pipeline. We minimize the use of ETL tools and frameworks to keep the implementation simple and the focus on fundamental concepts. Each part introduces a new concept along the way to building the full pipeline located in this repo.
- Part 1: The ETL Pattern
- Part 2: Automating ETL
- Part 3: Testing ETL
- Part 4: CI/CI with GitHub Actions
Additional considerations
This series aims to illustrate the ETL pattern with a simple, usable implementation. To maintain that focus, some details have been left to this appendix.
- Best practices — this series glosses over some important practices for making robust production pipelines: staging tables, incremental loads, containerization/dependency management, event messaging/alerting, error handling, parallel processing, configuration files, data modeling, and more. There are great resources available for learning to add these best practices to your pipelines.
- ETL vs. ELT vs. ETLT — the ETL pattern can have a connotation of one bespoke ETL process loading an exact table for each end use case. In a modern data environment, a lot of transformation work happens post-load inside a data warehouse. This leads to the term "ELT" or the unwieldy "ETLT". Put simply, you may want to keep pre-load transformations light (if at all) to enable iteration on transformations within the data warehouse.
Keep Reading
We’ve written a whole series on ETL pipelines! Check them out here:
Core Concepts and Key Skills
Focus on Automation
ETL In Action

