In this article, we demonstrate how straightforward it is to develop an AI computer vision application for a portable Arm-powered device. We choose this solution for practicality since our driver distraction detection system must function autonomously in a driving car. We show that the application can run on the Arm-powered device in real-time mode, reaching about two FPS processing speed.
Introduction
When discussing computer vision (CV) based on artificial intelligence (AI) or deep learning (DL), we often imagine a powerful desktop machine or server processing images or videos. But sometimes, we need to run a complicated CV algorithm on a portable device.
For example, to create a computer system to prevent a driver from becoming distracted, the most practical solution is a stand-alone device with specialized software. A driver, fleet manager, or manufacturer could then place such a device into a vehicle to alert the driver when they are likely distracted.
So, can we run a complicated algorithm on portable Arm-powered devices? In this article, we will demonstrate how to create a distracted driver detector and show how to run it on a Raspberry Pi device. We will use Python to develop our program, OpenCV for the computer vision algorithms, and convolutional neural networks (CNN) to detect possible driver distraction.
Inventing the Algorithm
We will use a simple detection type that checks if eyes are closed for short intervals. We could characterize many other distraction symptoms, but this one is likely the most reliable.
Modern AI algorithms can complete this task with minimal effort. One approach uses a special CNN for detecting so-called facial landmarks. The image below features an extremely common 68-point facial landmarks diagram.
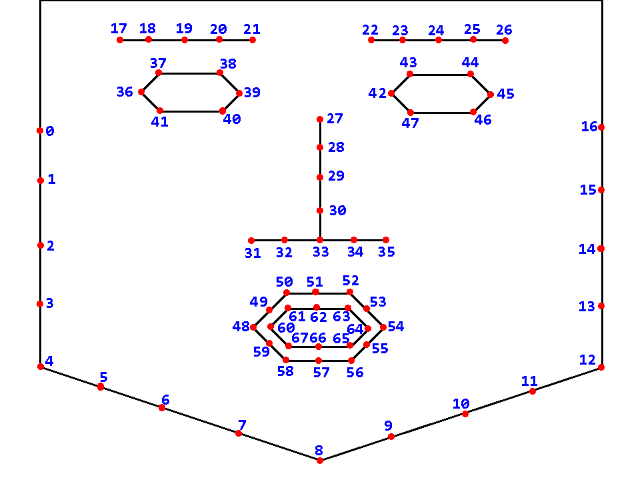
Using the eye point landmark coordinates, we can calculate the eye’s height-to-width ratio. When an eye is closed, this ratio is significantly lower. Through tracking this data, we can detect the moment of potential distraction.
A common approach to obtaining facial landmarks is detecting a face bounding box (a box around a face) and locating the landmark coordinates within it. Therefore, this algorithm requires two ingredients — a face detector and a landmark evaluator. We will use deep neural networks (DNN) for both subtasks. You can find the face detection TensorFlow model on GitLab. For a facial landmark evaluator, we will use this Caffe model.
Detecting Facial Landmarks
Let us start writing code for our facial landmarks detection algorithm. We begin with the face detector based on the DNN model.
class TF_FD:
def __init__(self, model, graph, min_size, min_confidence):
self.min_size = min_size
self.min_confidence = min_confidence
self.detector = cv2.dnn.readNetFromTensorflow(model, graph)
l_names = self.detector.getLayerNames()
if len(l_names)>0:
print('Face detector loaded:')
else:
print('Face detector loading FAILED')
def detect(self, frame):
width = frame.shape[1]
height = frame.shape[0]
inputBlob = cv2.dnn.blobFromImage(frame, 1.0, (300, 300), \
(104.0, 177.0, 123.0), True, False)
self.detector.setInput(inputBlob, 'data');
detection = self.detector.forward('detection_out');
n = detection.shape[2]
detected = []
for i in range(n):
conf = detection[0, 0, i, 2]
if conf >= self.min_confidence:
x1 = detection[0, 0, i, 3]
y1 = detection[0, 0, i, 4]
x2 = detection[0, 0, i, 5]
y2 = detection[0, 0, i, 6]
if Utils.point_is_out(x1,y1) or Utils.point_is_out(x2, y2):
continue
fw = (x2-x1)*width
fh = (y2-y1)*height
if (fw>=self.min_size) and (fh>=self.min_size):
r = (x1, y1, x2, y2)
d = (conf, r)
detected.append(d)
return detected
This simple class provides the constructor for loading a TensorFlow neural network from the specified model and graph files. The OpenCV framework’s cv2.dnn module delivers methods for loading DNN models of many popular formats. The constructor has two additional arguments: the minimum face size and minimum detection confidence.
The class’s detect method receives one parameter, frame, which is an image or a video frame. The function creates a blob object (a special 4D array that we use as input data for the detector).
Note that we used some specific values for the parameters in our model’s blobFromImage function. If you use another face detection model, remember to change the values as needed.
Next, we run the detector calling the forward method and extract data (detection confidence and bounding boxes) for all faces satisfying our criteria (the minimum size and confidence).
We next develop the second class, the facial landmarks detector:
class CAFFE_FLD:
def __init__(self, model, proto):
self.detector = cv2.dnn.readNetFromCaffe(proto, model)
l_names = self.detector.getLayerNames()
if len(l_names)>0:
print('Face landmarks detector loaded:')
else:
print('Face landmarks detector loading FAILED')
def get_face_rect(self, frame, face):
width = frame.shape[1]
height = frame.shape[0]
(conf, rect) = face
(x1, y1, x2, y2) = rect
fw = (x2-x1)*width
fh = (y2-y1)*height
if fw>fh:
dx = (fw-fh)/(2*width)
x1 = x1+dx
x2 = x2-dx
else:
dy = (fh-fw)/(2*height)
y1 = y1+dy
y2 = y2-dy
x1 = Utils.fit(x1)
y1 = Utils.fit(y1)
x2 = Utils.fit(x2)
y2 = Utils.fit(y2)
rect = (x1, y1, x2, y2)
return rect
def get_frame_points(self, face_rect, face_points):
(x1, y1, x2, y2) = face_rect
fw = (x2-x1)
fh = (y2-y1)
n = len(face_points)
frame_points = []
for i in range(n):
v = face_points[i]
if (i % 2) == 0:
dv = x1
df = fw
else:
dv = y1
df = fh
v = dv+v*df
frame_points.append(v)
return frame_points
def get_face_image(self, frame, face):
width = frame.shape[1]
height = frame.shape[0]
(conf, rect) = face
(x1, y1, x2, y2) = rect
rect = self.get_face_rect(frame, face)
(xi1, yi1, xi2, yi2) = Utils.rect_to_abs(rect, width, height)
roi = frame[yi1:yi2, xi1:xi2]
gray = cv2.cvtColor(roi, cv2.COLOR_RGB2GRAY)
resized = cv2.resize(gray, (60, 60), 0.0, 0.0, interpolation=cv2.INTER_CUBIC)
return (rect, gray, resized)
def detect(self, f_img):
width = f_img.shape[1]
height = f_img.shape[0]
inputBlob = cv2.dnn.blobFromImage(f_img, 1/127.5, (60, 60), (127.5))
self.detector.setInput(inputBlob, 'data');
detection = self.detector.forward();
points = detection[0]
return points
This class also loads a DNN model on initialization, but it uses another function because this model is in Caffe’s specific format. The primary method, detect, again creates a blob and runs the neural network to get facial landmarks. In this case, the detect method receives not an entire frame but a specially processed part of the frame containing one face.
We can generate this “face image” using the get_face_image method, specially designed for this purpose. It finds the square box containing the face, crops it from the frame, converts the blue, green, red (BGR) data to a gray-scale image (because we have trained our DNN model on gray images), and resizes the image to 60x60 pixels using a high-quality interpolation method.
Running Landmark Detection on Raspberry Pi
Now that we have designed our face landmark detector, we should test it on an Arm-powered device to verify that it can run the algorithm with enough frames per second (FPS). We will perform tests on a Raspberry Pi 4 Model B device. We have installed the Python OpenCV framework on the device using pre-compiled binary packages. If you use another device, you should follow the suitable guides to install its packages.
In this article, we won’t use special AI frameworks, and the neural networks are processed without acceleration on GPU or TPU. So, all the ML workloads run only on the device’s CPU.
We’ll do all tests using video files to ensure the experiments’ repeatability. The video is set in an office but imitates the scene when driving a car.
The following class runs facial landmark detection on a video file:
class VideoFLD:
def __init__(self, fd, fld):
self.fd = fd
self.fld = fld
def process(self, video):
frame_count = 0
detection_num = 0;
dt = 0
dt_l = 0
capture = cv2.VideoCapture(video)
img = None
dname = 'Arm-Powered Driver Distraction Detection'
cv2.namedWindow(dname, cv2.WINDOW_NORMAL)
cv2.resizeWindow(dname, 720, 720)
while(True):
(ret, frame) = capture.read()
if frame is None:
break
frame_count = frame_count+1
width = frame.shape[1]
height = frame.shape[0]
if not (width == height):
dx = int((width-height)/2)
frame = frame[0:height, dx:dx+height]
t1 = time.time()
faces = self.fd.detect(frame)
t2 = time.time()
dt = dt + (t2-t1)
f_count = len(faces)
detection_num += f_count
draw_points = []
if (f_count>0):
for (i, face) in enumerate(faces):
t1 = time.time()
(fi_rect, fi_gray, fi_resized) = self.fld.get_face_image(frame, face)
points = self.fld.detect(fi_resized)
frame_points = self.fld.get_frame_points(fi_rect, points)
t2 = time.time()
dt_l = dt_l + (t2-t1)
draw_points.append(frame_points)
if len(faces)>0:
Utils.draw_faces(faces, (255, 0, 0), 1, frame, True)
if len(draw_points)>0:
for (i, points) in enumerate(draw_points):
Utils.draw_points(points, (0, 0, 255), 1, frame)
cv2.imshow(dname,frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
capture.release()
cv2.destroyAllWindows()
fps = 0.0
if dt>0:
fps = frame_count/dt
fps_l = 0.0
if dt_l>0:
fps_l = detection_num/dt_l
return (detection_num, fps, fps_l)
Here, we use our face and landmark detectors to provide the primary function. We use the VideoCapture class from the OpenCV library to read frames from a video file and feed them to the detectors.
Now we can run the algorithm with the following code:
w_path = '/home/pi/Desktop/PI_DD'
n_path = os.path.join(w_path, 'net')
fd_model = os.path.join(n_path, 'opencv_face_detector_uint8.pb')
fd_graph = os.path.join(n_path, 'opencv_face_detector.pbtxt')
fd = TF_FD(fd_model, fd_graph, 30, 0.5)
fld_model = os.path.join(n_path, 'face_landmarks.caffemodel')
fld_proto = os.path.join(n_path, 'face_landmarks.prototxt')
fld = CAFFE_FLD(fld_model, fld_proto)
v_path = os.path.join(w_path, 'video')
v_name = 'v_1.mp4'
v_file = os.path.join(v_path, v_name)
vfld = VideoFLD(fd, fld)
(detection_num, fps, fps_l) = vfld.process(v_file)
print("Face detections: "+str(detection_num))
print("Detection FPS: "+str(fps))
print("Landmarks FPS: "+str(fps_l))
You can see the screened results in the following video:
Our facial landmark detection algorithm works well and locates the reference points with reasonable accuracy. It gave us a face detection speed of about 2 FPS and a landmark evaluation speed of about 60 FPS. That’s definitely usable, and not bad considering we’re only using the Pi’s CPU.
This speed should be sufficient for detecting closed eyes within one to three seconds, applicable in real situations of driver distraction. So, it should be good enough for our distraction detection task.
Implementing Driver Distraction Detection
We are only one step away from the completed algorithm of distracted driver detection: writing the algorithm for evaluating the eye’s height-to-width ratio and tracking it to evaluate the moment of possible distraction.
First, we add two simple methods to the CAFFE_FLD class:
def get_eye_points(self, face_points, eye_id):
i0 = 72
i1 = i0+12*(eye_id-1)
i2 = i1+12
eye_points = face_points[i1:i2]
return eye_points
def get_eye_ratio(self, eye):
n = int(len(eye)/2)
pts = np.array(eye, dtype=np.float32)
pts = pts.reshape([n, 2])
rect = cv2.minAreaRect(pts)
(w, h) = rect[1]
if (w>h):
ratio = h/w
else:
ratio = w/h
return ratio
The get_eye_points method extracts points of an eye from the array of 68 face landmarks. The get_eye_ratio method evaluates the eye’s height-to-width ratio.
Now we can write the code to track the ratio value and detect moments of possible distraction.
class DERD:
def __init__(self, ratio_thresh, delta_time, eyes=2):
self.ratio_thresh = ratio_thresh
self.delta_time = delta_time
self.eyes = eyes
self.eye_closed_time = 0.0
self.last_time = 0.0
def start(self, time):
self.eye_closed_time = 0.0
self.last_time = time
def detect(self, eye1_ratio, eye2_ratio, time):
dt = time - self.last_time
distraction = False
d1 = (eye1_ratio<self.ratio_thresh)
d2 = (eye2_ratio<self.ratio_thresh)
if self.eyes == 2:
d = d1 and d2
else:
d = d1 or d2
if d:
self.eye_closed_time += dt
else:
self.eye_closed_time -= dt
if self.eye_closed_time<0.0:
self.eye_closed_time = 0.0
print('Eye 1: '+str(eye1_ratio))
print('Eye 2: '+str(eye2_ratio))
print('Eye closed time = '+str(self.eye_closed_time))
if self.eye_closed_time>=self.delta_time:
distraction = True
self.start(time)
self.last_time = time
return distraction
The ratio_thresh argument is the minimum value of the height-to-width ratio to assume the eye is closed. The delta_time parameter denotes how long the eye must be closed to decide whether a distraction occurred. The eyes parameter determines whether one or both eyes must be closed to consider this a distraction.
Finally, we slightly modified our video detector to include this distraction detection algorithm in the code and generate an alarm when a detection happens.
class VideoDDD:
def __init__(self, fd, fld, eye_ratio_thresh=0.2, eyes=2, delta_time=2.0):
self.fd = fd
self.fld = fld
self.derd = DERD(eye_ratio_thresh, delta_time, eyes)
def process(self, video):
frame_count = 0
detection_num = 0;
dt = 0
dt_l = 0
capture = cv2.VideoCapture(video)
img = None
dname = 'Arm-Powered Driver Distraction Detection'
cv2.namedWindow(dname, cv2.WINDOW_NORMAL)
cv2.resizeWindow(dname, 720, 720)
delta = 0.040
dd_time = -1000
draw_points = []
faces = []
while(True):
frame_t1 = time.time()
(ret, frame) = capture.read()
if frame is None:
break
frame_count = frame_count+1
frame_time = (frame_count-1)*delta
if frame_count==1:
self.derd.start(frame_time)
width = frame.shape[1]
height = frame.shape[0]
if not (width == height):
dx = int((width-height)/2)
frame = frame[0:height, dx:dx+height]
f_count = 0
if (frame_count % 10) == 0:
faces = []
draw_points = []
t1 = time.time()
faces = self.fd.detect(frame)
t2 = time.time()
dt = dt + (t2-t1)
f_count = len(faces)
detection_num += 1
distraction = False
if (f_count>0):
face = faces[0]
t1 = time.time()
(fi_rect, fi_gray, fi_resized) = self.fld.get_face_image(frame, face)
points = self.fld.detect(fi_resized)
frame_points = self.fld.get_frame_points(fi_rect, points)
t2 = time.time()
dt_l = dt_l + (t2-t1)
draw_points.append(frame_points)
eye1 = self.fld.get_eye_points(frame_points, 1)
eye2 = self.fld.get_eye_points(frame_points, 2)
r1 = self.fld.get_eye_ratio(eye1)
r2 = self.fld.get_eye_ratio(eye2)
distraction = self.derd.detect(r1, r2, frame_time)
if len(faces)>0:
Utils.draw_faces(faces, (255, 0, 0), 1, frame, True)
if len(draw_points)>0:
for (i, points) in enumerate(draw_points):
Utils.draw_points(points, (0, 0, 255), 1, frame)
if distraction:
dd_time = frame_time
if dd_time>0:
text = "ALARM! DRIVER DISTRACTION"
xd1 = 10
yd1 = 50
cv2.putText(frame, text, (xd1, yd1), \
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 1, cv2.LINE_AA)
if (frame_time-dd_time)>1.0:
dd_time = -1000
cv2.imshow(dname,frame)
frame_t2 = time.time()
frame_dt = frame_t2 - frame_t1
if frame_dt<delta:
frame_dt = delta-frame_dt
time.sleep(frame_dt)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
capture.release()
cv2.destroyAllWindows()
fps = 0.0
if dt>0:
fps = detection_num/dt
fps_l = 0.0
if dt_l>0:
fps_l = detection_num/dt_l
return (detection_num, fps, fps_l)
In addition to using the DERD class, we slightly changed the frame processing algorithm. We added a timestamp comparison of frames to estimate time intervals of possible distraction. Also, we now process only every tenth frame to imitate the near real-time processing.
Now we can run the completed driver distraction detection algorithm with the following code:
w_path = '/home/pi/Desktop/PI_DD'
n_path = os.path.join(w_path, 'net')
fd_model = os.path.join(n_path, 'opencv_face_detector_uint8.pb')
fd_graph = os.path.join(n_path, 'opencv_face_detector.pbtxt')
fd = TF_FD(fd_model, fd_graph, 30, 0.5)
fld_model = os.path.join(n_path, 'face_landmarks.caffemodel')
fld_proto = os.path.join(n_path, 'face_landmarks.prototxt')
fld = CAFFE_FLD(fld_model, fld_proto)
v_path = os.path.join(w_path, 'video')
v_name = 'v_1.mp4'
v_file = os.path.join(v_path, v_name)
vddd = VideoDDD(fd, fld, 0.3, 1, 2.0)
(detection_num, fps, fps_l) = vddd.process(v_file)
print("Face detections: "+str(detection_num))
print("Detection FPS: "+str(fps))
print("Landmarks FPS: "+str(fps_l))
You can see that the algorithm correctly handles the situation when the eyes appear to be closed during a long enough time interval and generates the alarm.
This helps us catch one cause of driver distraction — when a driver is looking down at a mobile device in their lap, our drowsiness detector identifies them as distracted because it only see their eyelids. As jurisdictions around the world ban mobile device use while driving, drivers have tried to adapt by holding their devices out of sight. But our distraction detector will catch them by detecting when their eyes don’t appear to be fully open.
Conveniently, this algorithm can also work to detect driver drowsiness. Our device should raise the alarm whether a driver's eyes merely appear closed because they are looking down at a mobile device, or they actually are closed because the driver is drowsy or asleep.
The algorithm also correctly handles the situation when the eyes are closed for a short time interval (for example, a driver blinks) or the head is slightly turned for a short time.
Next Steps
We’ve implemented one driver distraction algorithm using facial landmarks - but we could add others! For example, we might want to detect when a driver's head is turned by measuring the angle of the lines between nose landmarks. We might also check if a driver's mouth appears to be opening and closing by comparing the distance between upper and lower mouth landmarks over time. If they are, it likely means the driver is talking or eating while driving.
To take things even further, we might consider upgrading to an ML model that can do iris detection, and try to determine when a driver's eyes aren't looking at the road.
In this article, we demonstrated how straightforward it is to develop an AI computer vision application for a portable Arm-powered device. We chose this solution for practicality since our driver distraction detection system must function autonomously in a driving car. We showed that the application could run on the Arm-powered device in real-time mode, reaching about two FPS processing speed.
Nevertheless, we can still investigate many aspects to improve this driver distraction detection system. For instance, can we increase the FPS? To answer this, we should pay attention to the application’s slowest part — face detection with the TensorFlow neural network. Can we improve this model’s performance? Yes. We can use Arm’s Arm NN library, which they specially developed to accelerate processing DNN models on Arm-powered devices.
With the Arm NN library, we also could run the NN model on connected GPU or NPU units to achieve near real-time speed. This would give us more flexibility to invent advanced algorithms of driver distraction detection or to use other face detection DNN models, like the BlazeFace neural model.
Other improvements to our solution might involve generating new distraction criteria. For example, we can infer that drivers are likely distracted if their eyes or head are directed elsewhere for more than a determined time interval.
We hope these ideas have piqued your interest. We encourage you to expand on this solution or create your own portable AI solutions on Arm-powered devices.
History
- 7th February, 2022: Initial version

