This is Part 1 of a 3-part series that demonstrates how to use Azure Cognitive Services to build a universal translator that can take a recording of a person’s speech, convert it to text, translate it to another language, and then read it back using text-to-speech. In this article, we begin by writing the web frontend with React, then hosting the code as an Azure static web application.
Star Trek fans are familiar with the idea of a universal translator. Intrepid heroes use these fictional devices to communicate with species across the galaxy, seamlessly translating one spoken language into another. No degree in exolinguistics is required.
Thanks to artificial intelligence (AI) advancements, developers can now build a universal translator. These applications can translate dozens, if not hundreds, of (Earth-based) languages, helping travelers and business contacts speak with almost anyone worldwide.
Developers can use many helpful Azure services to build translation capabilities into their applications, like Translator, Speech to Text and Text to Speech.
Follow this three-part series to build a simple universal translator web application. The application will use Azure services to transcribe a user’s browser-based recording, translate the text into another language, and convert that text into speech. The resulting tool demonstrates how easy it is to incorporate comprehensive translation services into your applications.
We’ll begin the series by writing the web frontend with React, then hosting the code as an Azure static web application.
Prerequisites
To follow along with this tutorial, you’ll need to install Node.js if you don’t have it already so you can build and test the application locally.
To see this application’s complete source code at any time, visit GitHub.
Building the React Template Application
Our web application builds on the standard React template. Create this template by running the following command:
npx create-react-app voice-recording
The command creates a new web application in the voice-recording directory. Enter the directory with the command:
cd voice-recording
Our application will use the Material UI library. Use the following command to add it to the project:
npm install --save @mui/material @emotion/react @emotion/styled @mui/icons-material
Our app will present the steps of recording a voice sample, transcribing it, translating it, then converting the text to speech as a wizard that the user clicks through. So, install another dependency to expose a wizard interface with the command:
npm install --save react-step-wizard
The final dependency is react-media-recorder, which provides a convenient way to interact with a microphone via the web browser. Install the dependency with this command:
npm install –save react-media-recorder
The framework is now in place to create the application. The next step is to build the wizard interface.
Extending the App Entry Point
The React template creates an App() function that serves as the application’s entry point.
Because multiple steps consume the collected data as the user progresses through the wizard, define all the application states at the top-level App() function. The code below shows the state hooks capturing the variables representing the various inputs that the wizard will collect:
function App() {
const [mediaBlob, setMediaBlob] = React.useState(null);
const [transcribedText, setTranscribedText] = React.useState("");
const [translatedText, setTranslatedText] = React.useState("");
const [sourceLanguage, setSourceLanguage] = React.useState("en-US");
const [targetLanguage, setTargetLanguage] = React.useState("de-DE");
const [config, setConfig] = React.useState(null);
Our web application must communicate with APIs hosted in different locations. For example, local development will target APIs hosted on localhost:7071, while the production build will access APIs exposed with the same hostname as the web application. So, we load a JSON file and capture the result in the config state variable:
useEffect(() => {
fetch('config.json', {
method: 'GET'
})
.then(response => response.json())
.then(data => setConfig(data))
.catch(() => window.alert("Failed to load settings"))
}, []);
Next, we’ll start building the HTML interface. An AppContext element wraps the interactive elements. This element exposes all the state variables defined earlier to each child element without including them repeatedly in each child’s properties:
return (
<div className="App">
<h1>Universal Translator</h1>
<AppContext.Provider value={{
mediaBlob,
setMediaBlob,
sourceLanguage,
setSourceLanguage,
targetLanguage,
setTargetLanguage,
transcribedText,
setTranscribedText,
translatedText,
setTranslatedText,
config
}}>
If the config file has been loaded, the app will display the StepWizard with the child elements that make up each step, like this:
{config != null && <StepWizard>
<Record/>
<Transcribe/>
<Translate/>
<Speak/>
</StepWizard>}
If the config file is still being loaded, the app will display a simple loading message:
{config == null &&
<h2>Loading Configuration</h2>}
</AppContext.Provider>
</div>
);
}
Then, the code exports the App function:
export default App;
Recording Speech Through the Browser
The first step in the wizard allows the user to record speech through the browser. The Record component exposes this step.
We start by defining constant values that the Media Recorder API uses to indicate a recording’s state:
const readyToRecordStates = ["stopped", "idle"];
const recordingStates = ["recording"];
const recordedStates = ["stopped"];
The Record function takes the standard parameters that the parent StepWizard passes:
export const Record = (params) => {
Then, the app accesses the shared context via useContext:
const appContext = React.useContext(AppContext);
The handleNext function progresses the wizard to the next step. It accepts a Blob URL that the media recorder created, saves the URL in the shared context, and calls the nextStep function passed into the params by the parent StepWizard element:
function handleNext(mediaBlobUrl) {
return () => {
appContext.setMediaBlob(mediaBlobUrl);
params.nextStep();
}
}
The record step creates a ReactMediaRecorder element. The render property takes a function that builds up the recording capture user interface (UI), and provides various parameters to control the recording process and query the recording status:
return (
<div>
<ReactMediaRecorder
audio={true}
video={false}
render={({status, startRecording, stopRecording, mediaBlobUrl}) => (
Then, we use the MUI grid layout to display buttons that start and stop recording:
<Grid
container
spacing={2}
rowGap={2}
justifyContent="center"
alignItems="center">
<Grid item xs={12}>
<h3>Record your message</h3>
</Grid>
<Grid item md={3} xs={0}/>
<Grid item md={3} xs={12}>
<Button
variant="contained"
className={"fullWidth"}
onClick={startRecording}
disabled={readyToRecordStates.indexOf(status) === -1}>
Start Recording
</Button>
</Grid>
<Grid item md={3} xs={12}>
<Button
variant="contained"
className={"fullWidth"}
onClick={stopRecording}
disabled={recordingStates.indexOf(status) === -1}>
Stop Recording
</Button>
</Grid>
<Grid item md={3} xs={0}/>
Then, we’ll want to add an audio playback element. This allows the user to replay their new recording:
<Grid item xs={12}>
<audio src={mediaBlobUrl} controls/>
</Grid>
The application then presents a button to progress to the wizard’s next step:
<Grid item md={3} xs={0}/>
<Grid item md={3} xs={12}>
<Button
variant="contained"
className={"fullWidth"}
onClick={handleNext(mediaBlobUrl)}
disabled={recordedStates.indexOf(status) === -1}>
Transcribe >
</Button>
</Grid>
</Grid>)}
/>
</div>
)
}
The screenshot below shows the result.
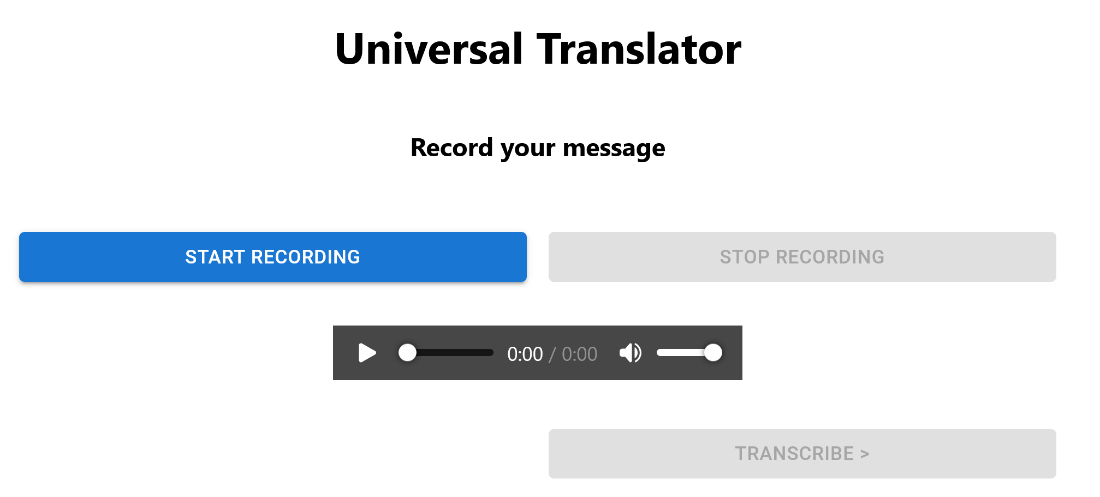
Transcribing the Recording
The second step is to transcribe the recorded audio into text. The Transcribe component does this. As before, the application exposes the common context by calling useContext:
export const Transcribe = (params) => {
const appContext = React.useContext(AppContext);
This component tracks the state of the backend API call in a variable called processing. In this tutorial, we’ll create the API later as an Azure function:
const [processing, setProcessing] = useState(false);
The next step displays a select list containing the list of languages captured in the recording. The function assigned to handleOutputLanguageChange responds to selection changes:
const handleOutputLanguageChange = (event) => {
appContext.setTranscribedText("");
appContext.setSourceLanguage(event.target.value);
};
The function assigned to transcribeText passes the audio recording to the backend API and receives the transcribed text in the response.
The backend API exposes an endpoint called /transcribe that takes the binary audio data in the POST body and defines the language in a query parameter called language:
const transcribeText = async () => {
setProcessing(true);
appContext.setTranscribedText(null);
const audioBlob = await fetch(appContext.mediaBlob).then(r => r.blob());
fetch(appContext.config.translateService + "/transcribe?language=" +
appContext.sourceLanguage, {
method: 'POST',
body: audioBlob,
headers: {"Content-Type": "application/octet-stream"}
})
.then(response => response.text())
.then(data => appContext.setTranscribedText(data))
.catch(() => window.alert("Failed to transcribe message"))
.finally(() => setProcessing(false))
}
Next, we build the step UI using a grid layout:
return <div>
<Grid
container
spacing={2}
rowGap={2}
justifyContent="center"
alignItems="center">
<Grid item xs={12}>
<h3>Transcribe your message</h3>
</Grid>
<Grid item md={3} xs={0}/>
<Grid item md={6} xs={12}>
The list here shows a small sample of Azure-supported languages.
<FormControl fullWidth>
<InputLabel id="outputLanguage-label">Recorded Language</InputLabel>
<Select
labelId="outputLanguage-label"
value={appContext.sourceLanguage}
label="Recorded Language"
onChange={handleOutputLanguageChange}
>
<MenuItem value={"en-US"}>English</MenuItem>
<MenuItem value={"de-DE"}>German</MenuItem>
<MenuItem value={"ja-JP"}>Japanese</MenuItem>
</Select>
</FormControl>
</Grid>
<Grid item md={3} xs={0}/>
The Transcribe button initiates the call to the backend API:
<Grid item md={4} xs={0}/>
<Grid item md={4} xs={12}>
<Button
variant="contained"
className={"fullWidth"}
onClick={transcribeText}
disabled={processing}>
Transcribe
</Button>
</Grid>
<Grid item md={4} xs={0}/>
The resulting text below is displayed in a text box.
<Grid item md={3} xs={0}/>
<Grid item md={6} xs={12}>
<TextField
rows={10}
multiline={true}
fullWidth={true}
disabled={true}
value={appContext.transcribedText}
/>
</Grid>
<Grid item md={3} xs={0}/>
Then, we want to add back and forward buttons to help the user navigate the wizard.
<Grid item md={3} xs={0}/>
<Grid item md={3} xs={12}>
<Button
variant="contained"
className={"fullWidth"}
onClick={() => {
appContext.setTranscribedText("");
params.previousStep();
}}
disabled={processing}>
< Record
</Button>
</Grid>
<Grid item md={3} xs={12}>
<Button
variant="contained"
className={"fullWidth"}
onClick={() => params.nextStep()}
disabled={!appContext.transcribedText || processing}>
Translate >
</Button>
</Grid>
<Grid item md={3} xs={0}/>
</Grid>
</div>;
}
The screenshot below shows the transcribe step.
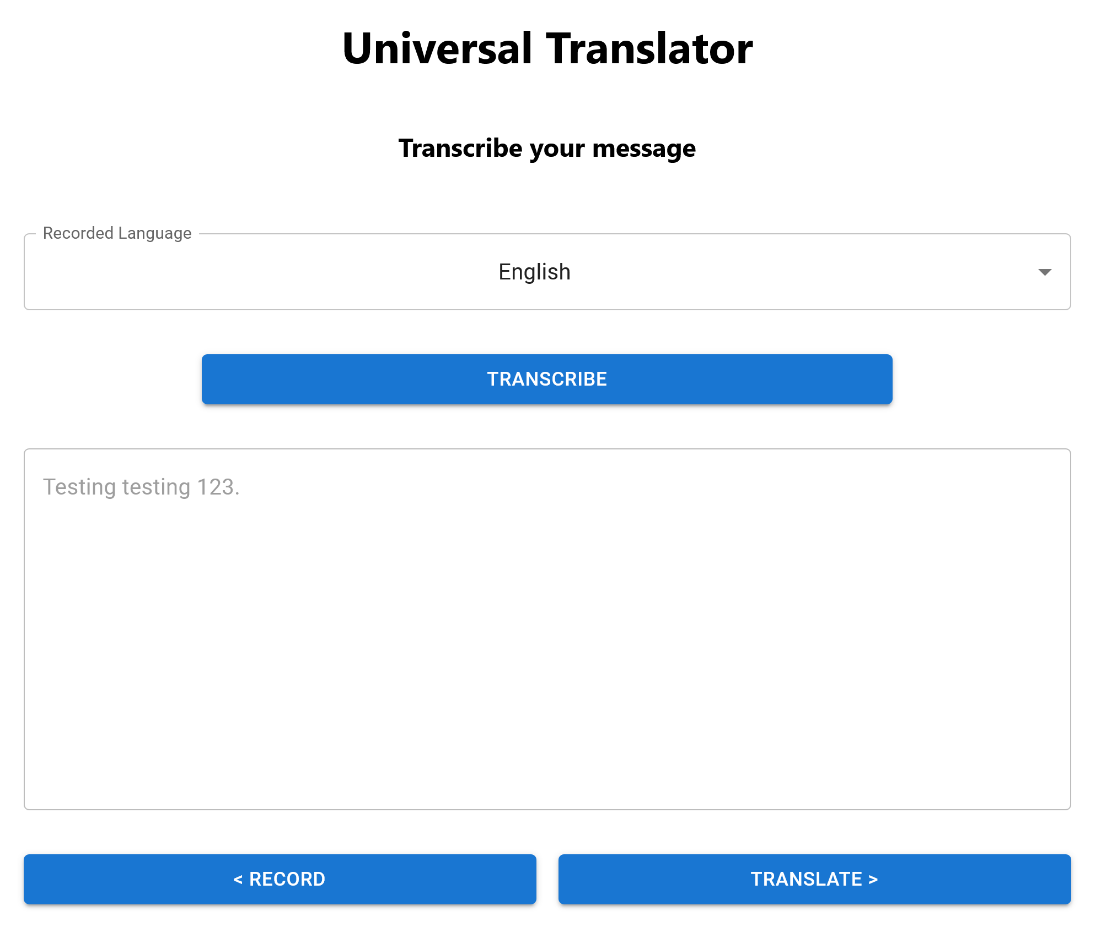
Translating the Message
The third step is translating the message into a new language. The Translate component defines this step. Like all steps, it accesses the global state via useContext:
export const Translate = (params) => {
const appContext = React.useContext(AppContext);
We use the processing variable to track the backend API call’s state:
const [processing, setProcessing] = useState(false);
const handleOutputLanguageChange = (event) => {
appContext.setTranslatedText("");
appContext.setTargetLanguage(event.target.value);
};
The function assigned to translateText calls the backend API on the /translate endpoint and captures the response in the global context:
const translateText = async () => {
setProcessing(true);
fetch(appContext.config.translateService + "/translate?sourceLanguage=" +
appContext.sourceLanguage + "&targetLanguage=" + appContext.targetLanguage, {
method: 'POST',
body: appContext.transcribedText,
headers: {"Content-Type": "text/plain"}
})
.then(response => response.json())
.then(data => appContext.setTranslatedText(data[0].translations[0].text))
.catch(() => window.alert("Failed to translate message"))
.finally(() => setProcessing(false))
}
The UI should look familiar by now. Like all steps, a grid-based layout displays the individual elements. In this case, it’s a select list displaying languages to translate the text into, a button to initiate the translation, a text box to display the translated result, and buttons to move back and forth in the wizard:
return <div>
<Grid
container
spacing={2}
rowGap={2}
justifyContent="center"
alignItems="center">
<Grid item xs={12}>
<h3>Translate your message</h3>
</Grid>
<Grid item md={3} xs={0}/>
<Grid md={6} xs={12}>
<FormControl fullWidth>
<InputLabel id="outputLanguage-label">Translated Language</InputLabel>
<Select
labelId="outputLanguage-label"
value={appContext.targetLanguage}
label="Translated Language"
onChange={handleOutputLanguageChange}
>
<MenuItem value={"en-US"}>English</MenuItem>
<MenuItem value={"de-DE"}>German</MenuItem>
<MenuItem value={"ja-JP"}>Japanese</MenuItem>
</Select>
</FormControl>
</Grid>
<Grid item md={3} xs={0}/>
<Grid item md={4} xs={0}/>
<Grid item md={4} xs={12}>
<Button
variant="contained"
className={"fullWidth"}
onClick={translateText}>
Translate
</Button>
</Grid>
<Grid item md={4} xs={0}/>
<Grid item md={3} xs={0}/>
<Grid item md={6} xs={12}>
<TextField
rows={10}
multiline={true}
fullWidth={true}
disabled={true}
value={appContext.translatedText}
/>
</Grid>
<Grid item md={3} xs={0}/>
<Grid item md={3} xs={0}/>
<Grid item md={3} xs={12}>
<Button
variant="contained"
className={"fullWidth"}
onClick={() => {
appContext.setTranslatedText("");
params.previousStep();
}}
disabled={processing}>
< Transcribe
</Button>
</Grid>
<Grid item md={3} xs={12}>
<Button
variant="contained"
className={"fullWidth"}
onClick={() => params.nextStep()}
disabled={!appContext.translatedText || processing}>
Speak >
</Button>
</Grid>
<Grid item md={3} xs={0}/>
</Grid>
</div>;
}
Converting the Text to Speech
The final step is to convert the translated text back into speech. The Speak component implements this:
export const Speak = (params) => {
const appContext = React.useContext(AppContext);
Two state variables capture the backend API call’s state and the location of the Blob holding the audio file returned by the API:
const [processing, setProcessing] = useState(false);
const [audioBlob, setAudioBlob] = useState(null);
The function assigned to convertText calls the backend API, passes the translated text, and saves the returned audio file:
const convertText = async () => {
setProcessing(true);
setAudioBlob(null);
fetch(appContext.config.translateService + "/speak?targetLanguage=" +
appContext.targetLanguage, {
method: 'POST',
body: appContext.translatedText,
headers: {"Content-Type": "text/plain"}
})
.then(response => response.blob())
.then(blob => {
const objectURL = URL.createObjectURL(blob);
setAudioBlob(objectURL);
})
.catch(() => window.alert("Failed to convert message to speech"))
.finally(() => {
setProcessing(false);
})
}
Meanwhile, the UI is another grid-based layout. It defines a button to initiate the text processing, an audio player element to play the resulting audio file in the browser, and a button to move back through the wizard:
return <div>
<Grid
container
spacing={2}
rowGap={2}
justifyContent="center"
alignItems="center">
<Grid item xs={12}>
<h3>Convert your message to speech</h3>
</Grid>
<Grid item md={4} xs={0}/>
<Grid item md={4} xs={12}>
<Button
variant="contained"
className={"fullWidth"}
disabled={processing}
onClick={convertText}>
Speak
</Button>
</Grid>
<Grid item md={4} xs={0}/>
<Grid item md={4} xs={0}/>
<Grid item md={4} xs={12}>
{audioBlob &&
<audio controls="controls" src={audioBlob} type="audio/wav"/>}
</Grid>
<Grid item md={4} xs={0}/>
<Grid item md={3} xs={0}/>
<Grid item md={3} xs={12}>
<Button
variant="contained"
className={"fullWidth"}
onClick={() => {
setAudioBlob(null);
params.previousStep()
}}
disabled={processing}>
< Translate
</Button>
</Grid>
<Grid item md={6} xs={0}/>
</Grid>
</div>;
}
Making the Configuration File
As we noted earlier, a JSON configuration file saved in public/config.json defines the backend API’s URL. This file contains a single property called translateService that defines the API URL.
This value is the URL exposed by a local development instance of an Azure Functions project by default. The next part of this article series will create this project.
{
"translateService": "http://localhost:7071/api"
}
Building and Publishing the Web Application
The React application is purely frontend code, so it's ideal for hosting as an Azure Static Web App. Microsoft's documentation provides detailed instructions on creating a new static web app.
The only change from the Microsoft tutorial is that our app will use GitHub Actions to deploy the code instead of having the web app consume changes from Git. To use GitHub Actions, set the Source to Other.
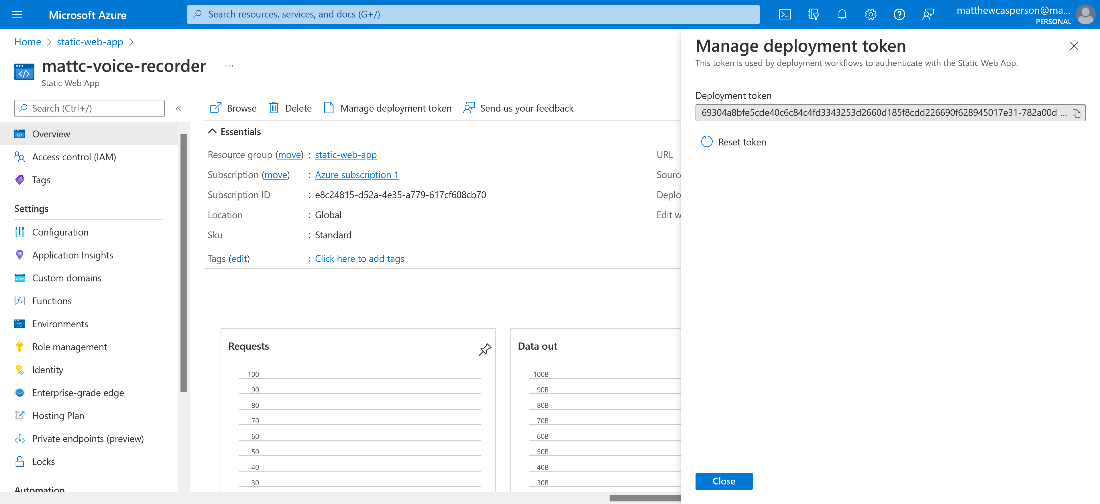
Once the web app is created, take note of the deployment token. We want to display this token by clicking the Manage deployment token button:
To publish the web app from GitHub, add the following workflow file to .github/workflows/node.yaml:
name: Node.js Build
'on':
workflow_dispatch: {}
push: {}
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v1
with:
fetch-depth: '0'
- uses: actions/setup-node@v2
with:
node-version: lts
This code updates the config file to reflect the backend API’s URL when published to Azure. As we’ll demonstrate in the next article of this series, the backend API links to the static web app via the bring your own function feature. This feature ensures the backend API and frontend web application share the same hostname. So, the frontend code can access the backend API from the relative path /api:
- name: Update config.json
run: |-
echo "`jq '.translateService="/api"' public/config.json`" > public/config.json
Azure provides a GitHub Action called Azure/static-web-apps-deploy@v1 to build and deploy the web app. Note the azure_static_web_apps_api_token property, which is a secret containing the deployment token exposed by the static web app:
- name: Build And Deploy
id: builddeploy
uses: Azure/static-web-apps-deploy@v1
with:
azure_static_web_apps_api_token: ${{ secrets.AZURE_STATIC_WEB_APPS_API_TOKEN }}
repo_token: ${{ secrets.GITHUB_TOKEN }}
action: 'upload'
app_location: '/'
api_location: ''
With this workflow in place, GitHub builds and publishes the web app with each commit to the Git repo, creating a continuous integration and continuous deployment (CI/CD) pipeline.
The web app allows users to record and play speech without the backend API. However, the first request to the backend API will fail because it doesn’t exist yet. The next part of this tutorial series will create the initial backend API endpoints.
Next Steps
This tutorial built the web application exposing a wizard-style process for recording speech in the browser, transcribing it, translating it, and converting the result back to voice. It also established a CI/CD pipeline with GitHub actions to deploy the code as an Azure static web app.
The result is a complete web application, but it lacks the backend API required to complete the wizard. Continue to part two of this three-part series to build the initial backend API and publish it as an Azure function app.
To learn more about the Speech service and browse the API references, check out our Speech service documentation.

