This is Part 2 of a 3-part series that demonstrates how to use Azure Cognitive Services to build a universal translator that can take a recording of a person’s speech, convert it to text, translate it to another language, and then read it back using text-to-speech. This tutorial builds the first part of the API, exposing the /transcribe endpoint to convert an audio file into text.
The first part of this three-part series built a frontend web app for a universal translator. It exposed a wizard to record speech in the browser, transcribe it, translate it, then convert the resulting text back to audio.
However, the frontend web app doesn’t contain the logic required to process audio or text. A backend API, written in Java as an Azure function app, handles this logic.
This tutorial will build the first part of the API, exposing the /transcribe endpoint to convert an audio file into text.
Prerequisites
This tutorial requires the Azure functions runtime version 4 and GStreamer to convert WebM audio files for the Azure APIs to process. Also, our backend application requires installing the Java 11 JDK.
This application’s complete source code is available on GitHub, and the backend application is available as the Docker image: mcasperson/translator.
Creating a Speech Service
The Azure Speech service provides the ability to convert speech to text. The backend API will serve as a proxy between the frontend web app and the Azure speech service.
Microsoft’s documentation provides instructions on creating a speech service in Azure.
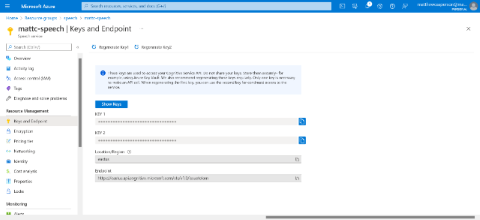
After creating the service, take note of the key. This key is needed to interact with the service from the application:
Bootstrapping the Backend Application
The Microsoft documentation provides instructions for creating the sample project that forms the base for this tutorial.
To create the sample application, run the following command. Note that it uses Java 11 instead of Java 8, which is the version the Microsoft documentation specifies:
mvn archetype:generate -DarchetypeGroupId=com.microsoft.azure
-DarchetypeArtifactId=azure-functions-archetype -DjavaVersion=11 –Ddocker
Adding Maven Dependencies
We need to add several additional dependencies to the pom.xml file for our application. These dependencies add the speech service SDK, an HTTP client, and some common utilities for working with files and text:
<dependency>
<groupId>com.microsoft.cognitiveservices.speech</groupId>
<artifactId>client-sdk</artifactId>
<version>1.19.0</version>
</dependency>
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.9.3</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.11.0</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-text</artifactId>
<version>1.9</version>
</dependency>
Working with Compressed Audio Files
The first challenge of transcribing audio files is that the Azure APIs only natively support WAV files. However, audio files recorded by a browser will almost certainly be in a compressed format like WebM.
Fortunately, the Azure SDK does allow converting compressed audio files using the GStreamer library. This is why GStreamer is one of our backend app’s prerequisites.
To use compressed audio files, we extend the PullAudioInputStreamCallback class to provide a reader that consumes a compressed audio file byte array with no additional processing. We do this using the ByteArrayReader class:
package com.matthewcasperson.azuretranslate.readers;
import com.microsoft.cognitiveservices.speech.audio.PullAudioInputStreamCallback;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
public class ByteArrayReader extends PullAudioInputStreamCallback {
private InputStream inputStream;
public ByteArrayReader(final byte[] data) {
inputStream = new ByteArrayInputStream(data);
}
@Override
public int read(final byte[] bytes) {
try {
return inputStream.read(bytes, 0, bytes.length);
} catch (final IOException e) {
e.printStackTrace();
}
return 0;
}
@Override
public void close() {
try {
inputStream.close();
} catch (final IOException e) {
e.printStackTrace();
}
}
}
Transcribing the Audio File
The TranscribeService class contains the logic to interact with the Azure speech service.
package com.matthewcasperson.azuretranslate.services;
import com.matthewcasperson.azuretranslate.readers.ByteArrayReader;
import com.microsoft.cognitiveservices.speech.SpeechRecognitionResult;
import com.microsoft.cognitiveservices.speech.SpeechRecognizer;
import com.microsoft.cognitiveservices.speech.audio.AudioConfig;
import com.microsoft.cognitiveservices.speech.audio.AudioStreamContainerFormat;
import com.microsoft.cognitiveservices.speech.audio.AudioStreamFormat;
import com.microsoft.cognitiveservices.speech.audio.PullAudioInputStream;
import com.microsoft.cognitiveservices.speech.translation.SpeechTranslationConfig;
import java.io.IOException;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class TranscribeService {
This class contains a single method called transcribe that takes the uploaded audio file as a byte array, and the audio’s language as a string:
public String transcribe(final byte[] file, final String language)
throws IOException, ExecutionException, InterruptedException {
The code creates a SpeechTranslationConfig object with the speech service key and region, both sourced from environment variables:
try {
try (SpeechTranslationConfig config = SpeechTranslationConfig.fromSubscription(
System.getenv("SPEECH_KEY"),
System.getenv("SPEECH_REGION"))) {
The code then defines the language that the audio file contains:
config.setSpeechRecognitionLanguage(language);
A PullAudioInputStream represents the audio stream to process. We pass it the reader created earlier, which serves as a simple wrapper around the uploaded byte array containing the audio file. The code sets the compressed format to ANY, allowing the GStreamer library to determine what audio file format the browser uploaded and convert it into the correct format:
final PullAudioInputStream pullAudio = PullAudioInputStream.create(
new ByteArrayReader(file),
AudioStreamFormat.getCompressedFormat(AudioStreamContainerFormat.ANY));
An AudioConfig represents the audio input configuration. In this case, it's to read the audio from a stream.
final AudioConfig audioConfig = AudioConfig.fromStreamInput(pullAudio);
The SpeechRecognizer class provides access to the speech recognition service.
final SpeechRecognizer reco = new SpeechRecognizer(config, audioConfig);
The application then requests converting the audio file into text. The resulting text returns the following:
final Future<SpeechRecognitionResult> task = reco.recognizeOnceAsync();
final SpeechRecognitionResult result = task.get();
return result.getText();
}
The code then logs and rethrows exceptions:
} catch (final Exception ex) {
System.out.println(ex);
throw ex;
}
}
}
Exposing the Azure Function HTTP Trigger
A method linked to an Azure function HTTP trigger exposes the TranscribeService class as an HTTP endpoint.
The Function class contains all the triggers for the project.
package com.matthewcasperson.azuretranslate;
import com.matthewcasperson.azuretranslate.services.TranscribeService;
import com.microsoft.azure.functions.ExecutionContext;
import com.microsoft.azure.functions.HttpMethod;
import com.microsoft.azure.functions.HttpRequestMessage;
import com.microsoft.azure.functions.HttpResponseMessage;
import com.microsoft.azure.functions.HttpStatus;
import com.microsoft.azure.functions.annotation.AuthorizationLevel;
import com.microsoft.azure.functions.annotation.FunctionName;
import com.microsoft.azure.functions.annotation.HttpTrigger;
import java.io.IOException;
import java.util.Optional;
import java.util.concurrent.ExecutionException;
public class Function {
Next, we define a static instance of the TranscribeService class:
private static final TranscribeService TRANSCRIBE_SERVICE = new TranscribeService();
The code annotates the transcribe method with @FunctionName to expose the function on the URL /api/transcribe, responding to HTTP POST requests and taking a byte array as the method body.
Note that when the app calls this endpoint, it must set the Content-Type header to application/octet-stream to ensure the Azure functions platform correctly serializes the request body as a byte array:
@FunctionName("transcribe")
public HttpResponseMessage transcribe(
@HttpTrigger(
name = "req",
methods = {HttpMethod.POST},
authLevel = AuthorizationLevel.ANONYMOUS)
HttpRequestMessage<Optional<byte[]>> request,
final ExecutionContext context) {
The function expects an audio file in the request body, so we need to validate the input to ensure the user provided the data:
if (request.getBody().isEmpty()) {
return request.createResponseBuilder(HttpStatus.BAD_REQUEST)
.body("The audio file must be in the body of the post.")
.build();
}
The app passes the audio file and language to the transcribe service. The resulting text returns to the caller:
try {
final String text = TRANSCRIBE_SERVICE.transcribe(
request.getBody().get(),
request.getQueryParameters().get("language"));
return request.createResponseBuilder(HttpStatus.OK).body(text).build();
Any exceptions will result in the caller receiving a 500 response code.
} catch (final IOException | ExecutionException | InterruptedException ex) {
return request.createResponseBuilder(HttpStatus.INTERNAL_SERVER_ERROR)
.body("There was an error transcribing the audio file.")
.build();
}
}
}
Testing the API Locally
To enable cross-origin resource sharing (CORS), which allows a web application to contact the API on a different host or port, we copy the following JSON to the local.settings.json file:
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "",
"FUNCTIONS_WORKER_RUNTIME": "java"
},
"Host": {
"CORS": "*"
}
}
The speech service key and region must be exposed as environment variables. So, we run the following commands in PowerShell:
$env:SPEECH_KEY="your key goes here"
$env:SPEECH_REGION="your region goes here"
Alternatively, we can use the equivalent commands in Bash:
export SPEECH_KEY="your key goes here"
export SPEECH_REGION="your region goes here"
Now, to build the backend, run the following command:
mvn clean package
Then, we run this command to run the function locally:
mvn azure-functions:run
Then, start the frontend web application detailed in the previous article with the command:
npm start
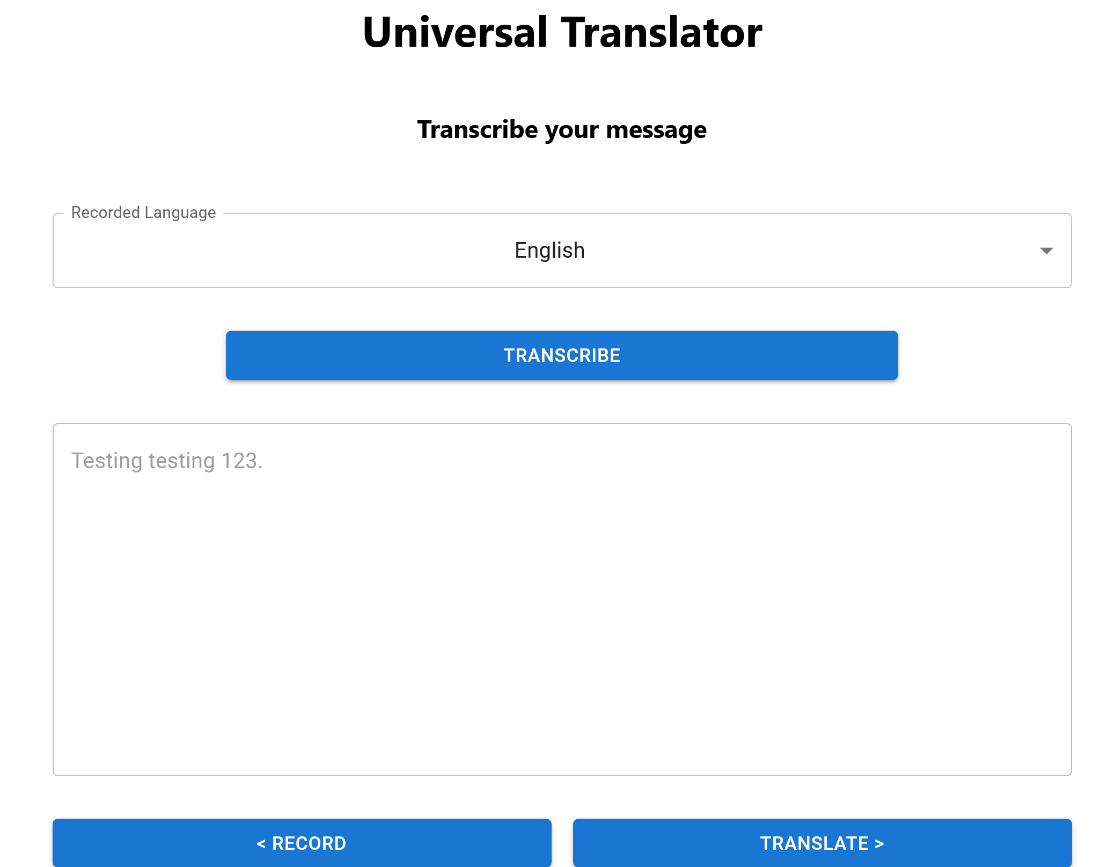
To test the application, open http://localhost:3000 and record some speech. Then, click the Translate > button to progress to the wizard’s next step. Select the audio’s language and click the Transcribe button.
Behind the scenes, the web app calls the backend API, which calls the Azure speech service to transcribe the audio file’s text. The application then prints the returned result in the text box.
Deploying the Backend App
Notice from the prerequisites section that the application requires GStreamer. This tool enables the application to convert the compressed audio saved by the browser to a format accepted by the Azure speech service.
The easiest way to bundle the application with external dependencies like GStreamer is to package them in a Docker image.
When creating the sample application, the tutorial also created a sample Dockerfile. So, add a new RUN command to the Dockerfile to install the GStreamer libraries. The complete Dockerfile is below:
ARG JAVA_VERSION=11
# This image additionally contains function core tools – useful when using custom extensions
#FROM mcr.microsoft.com/azure-functions/java:3.0-java$JAVA_VERSION-core-tools AS installer-env
FROM mcr.microsoft.com/azure-functions/java:3.0-java$JAVA_VERSION-build AS installer-env
COPY . /src/java-function-app
RUN cd /src/java-function-app && \
mkdir -p /home/site/wwwroot && \
mvn clean package && \
cd ./target/azure-functions/ && \
cd $(ls -d */|head -n 1) && \
cp -a . /home/site/wwwroot
# This image is ssh enabled
FROM mcr.microsoft.com/azure-functions/java:3.0-java$JAVA_VERSION-appservice
# This image isn't ssh enabled
#FROM mcr.microsoft.com/azure-functions/java:3.0-java$JAVA_VERSION
RUN apt update && \
apt install -y libgstreamer1.0-0 \
gstreamer1.0-plugins-base \
gstreamer1.0-plugins-good \
gstreamer1.0-plugins-bad \
gstreamer1.0-plugins-ugly && \
rm -rf /var/lib/apt/lists/*
ENV AzureWebJobsScriptRoot=/home/site/wwwroot \
AzureFunctionsJobHost__Logging__Console__IsEnabled=true
COPY --from=installer-env ["/home/site/wwwroot", "/home/site/wwwroot"]
We build this Docker image with the following command, replacing dockerhubuser with a Docker Hub user name:
docker build . -t dockerhubuser/translator
Then, we push the resulting image to Docker Hub with the command:
docker push dockerhubuser/translator
The Microsoft documentation provides instructions for deploying a custom Linux Docker image as an Azure function.
In addition to the app settings listed in Microsoft’s documentation, also set the SPEECH_KEY and SPEECH_REGION values. Replace yourresourcegroup, yourappname, yourspeechkey, and yourspeechregion with the appropriate values for the speech service instance:
az functionapp config appsettings set --name yourappname --resource-group yourresourcegroup
--settings "SPEECH_KEY=yourspeechkey"
az functionapp config appsettings set --name yourappname --resource-group yourresourcegroup
--settings "SPEECH_REGION=yourspeechregion"
Once deployed, the Azure function is available on its own domain name like https://yourappname.azurewebsites.net. This URL is acceptable, but it would be even better to expose the function app by the same hostname as the static web app. This approach would allow the static web app to interact with the functions using relative URLs rather than hardcoding external hostnames.
Use the bring your own function feature of static web apps to enable this URL function.
Bringing Your Own Function
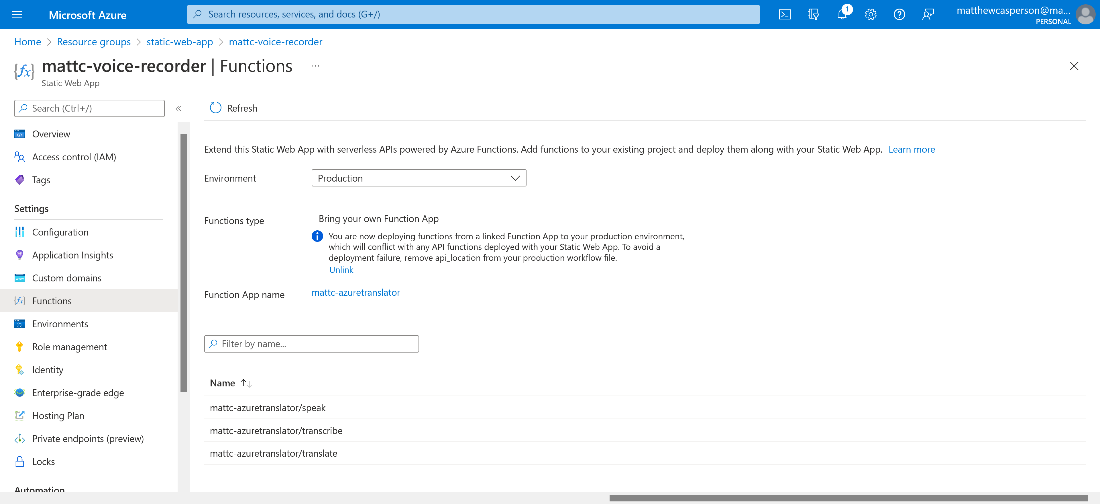
First, open the static website resource in Azure and select the Functions link in the left-hand menu.
The static web app doesn’t expose any functions. Setting the api_location property in the Azure/static-web-apps-deploy@v1 GitHub action step to an empty string enforces this.
Instead, we link an external function to the static web app. Click the Link to a Function app link, select the translator function, then click the Link button.
The external function is then linked to the static web app and exposed under the same hostname:
With the functions linked to the static app, now open the static app’s public URL, record an audio file, and transcribe it. The web app contacts the backend on the relative URL /app, now available thanks to the “bring your own function" feature.
Next Steps
This tutorial built on the first article’s base to expose an Azure function app, enabling transcribing an audio file using the Azure speech service.
Due to the dependencies on external libraries, the functions app is packaged as a Docker image. This approach makes it easy to distribute the code with the required libraries.
Finally, the Azure function app is linked to the static web app using the “bring your own function” feature to ensure the web app and function app share the same hostname.
There’s still some work left to do to finish the universal translator. The app must translate the transcribed text into a new language, then convert the translated text back to speech. Continue to the third and final article in this series to implement this logic.
To learn more about and view samples for the Microsoft Cognitive Services Speech SDK, check out Microsoft Cognitive Services Speech SDK Samples.

