A three-part series on OpenVINO™ Deep Learning Workbench
About the Series
- Learn how to convert, fine-tune, and package an inference-ready TensorFlow model, optimized for Intel® hardware, using nothing but a web browser. Every step happens in the cloud using OpenVINO™ Deep Learning Workbench and Intel® DevCloud for the Edge.
- Part One (you’re here!): We show you the Intel® deep learning inference tools and the basics of how they work.
- Part Two: We go through each step of importing, converting, and benchmarking a TensorFlow model using OpenVINO Deep Learning Workbench.
- Part Three: We show you how to change precision levels for increased performance and export a ready-to-run inference package with just a browser using OpenVINO Deep Learning Workbench.
Part One: Intel® Tools for Deep Learning Inference Deployment
Learn the basics of OpenVINO™ Deep Learning Workbench and Intel® DevCloud for the Edge
Pruning deep learning models, combining network layers, developing for multiple hardware targets—getting from a trained deep learning model to a ready-to-deploy inference model seems like a lot of work, which it can be if you hand code it.
With Intel® tools you can go from trained model to an optimized, packaged inference model entirely online without a single line of code. In this article, we’ll introduce you to the Intel® toolkits for deep learning deployments, including the Intel® Distribution of OpenVINO™ toolkit and Deep Learning Workbench. After that, we’ll get you signed up for a free Intel DevCloud for the Edge account so that you can start optimizing your own inference models.
What is a deep learning model and how do deployments work on Intel hardware?
Deep learning has two broad phases: training and inference. During training, computers build artificial neural network models by analyzing thousands of inputs—images, sentences, sounds—and guessing at their meaning. A feedback loop tells the machine if the guesses are right or wrong. This process repeats thousands of times, creating a multilayered network of algorithms. Once the network reaches its target accuracy, it can be frozen and exported as a trained model.
During deep learning inference, a device compares incoming data with a trained model and infers what the data means. For example, a smart camera compares video frames against a deep learning model for object detection. It then infers that one shape is a cat, another is a dog, a third is a car, and so on. During inference, the device isn’t learning; it’s recognizing and interpreting the data it receives.
There are many popular frameworks—like TensorFlow PyTorch, MXNet, PaddlePaddle—and a multitude of deep learning topologies and trained models. Each framework and model has its own syntax, layers, and algorithms. To run a deep learning model on an Intel® CPU, integrated GPU, or Intel® Movidius™ VPU we need to:
- Optimize the model so it runs as fast as possible
- Convert it into an intermediate file (IR file) that will run on any mix of Intel hardware
- Tune it so that it has the right balance of performance and accuracy
- Package it as a complete inference model that is ready for deployment
How do you do all that? Do you need a degree in data science? Nope. All you need is the OpenVINO Deep Learning Workbench.
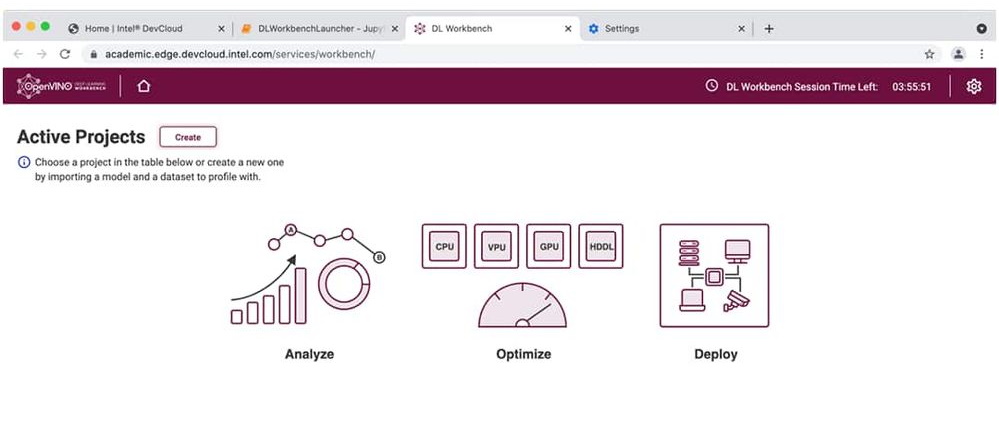
Optimize | Convert to IR file | Tune | Package and deploy
Deploying deep learning models with a browser: The OpenVINO Deep Learning Workbench
Deep Learning Workbench gives you access to the OpenVINO™ tool suite in a web-based interface, including the Model Downloader, Model Optimizer, Post-Training Optimization Tool, Accuracy Checker, and Benchmarking tools.
With Deep Learning Workbench, you can point and click your way from a trained model to a tested and tuned application package.
Who is Deep Learning Workbench for?
Besides you, you mean, right? We built Deep Learning Workbench and DevCloud for two basic types of developers: beginners, specifically beginners in AI deployment, and working professionals who need to get AI into production as quickly and painlessly as possible.
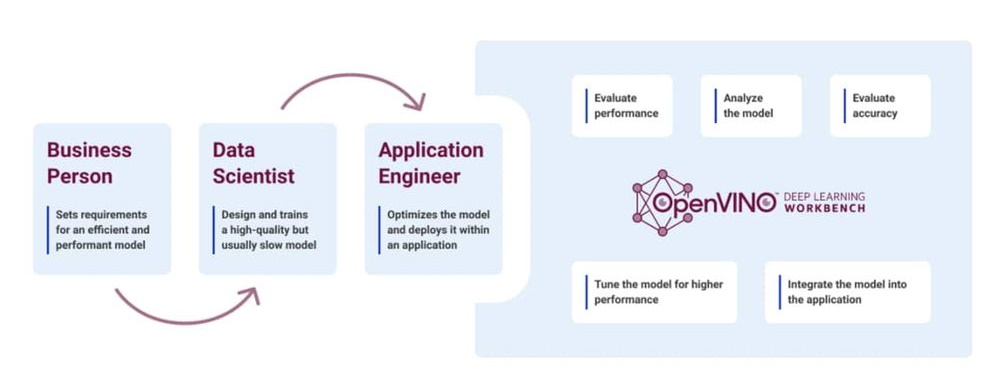
Deep Learning Workbench simplifies model import, tuning, and deployment.
If you’re a beginner
Sign up for DevCloud and play your way through the tutorials and reference implementations. Then, create your first optimized inference model with Deep Learning Workbench. You can experiment with different optimizations and see how your model runs on all kinds of different Intel hardware and accelerators.
If you’re a pro
Use DevCloud and Deep Learning Workbench to convert pretrained models then systematically benchmark, test, and tune. You can build production-ready deep learning inference applications that can run on any modern piece of Intel® silicon. You don’t have to buy bench hardware or be a data scientist to do it.
Test and tune on the latest Intel hardware—without buying any hardware!
You could run Deep Learning Workbench on your local machine, but that means you’ll only be able to test and deploy on your device. We have a better—and free—test bed for you: Intel DevCloud for the Edge.
DevCloud is an online sandbox where you can run Deep Learning Workbench in a JupyterLab environment on a range of Intel hardware all in one place.
Top five things you can do for free on Intel DevCloud for the Edge
- Learn about deep learning inference on Intel hardware.
- Explore deep learning inference middleware and reference applications.
- Create your own JupyterLab notebooks and build applications online with the Intel® Distribution of OpenVINO™ toolkit,.
- Test your applications on the latest Intel hardware, including machines from Intel’s ecosystem partners.
- Run OpenVINO Deep Learning Workbench and go from trained model to optimized, ready-to-deploy inference model with no code.
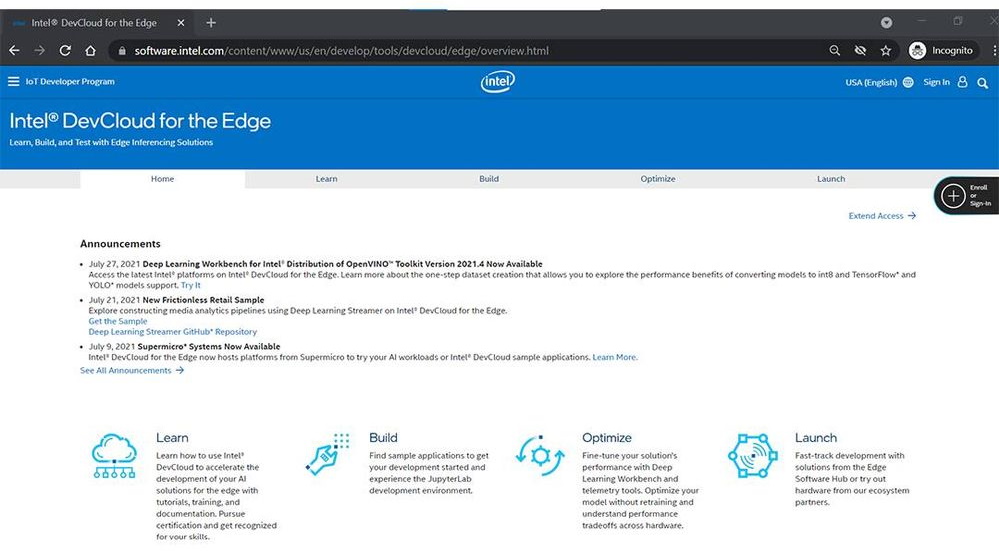
Get free access to Intel® hardware and Deep Learning Workbench on Intel® DevCloud for the Edge.
Let’s get started—How to launch OpenVINO Deep Learning Workbench
If you don’t have an account yet, please sign up for DevCloud for the Edge by accepting Intel’s Terms and Conditions and Privacy Policy. Go ahead. It’s free, and it only takes a few minutes.\
Once you have an account, login.
Note: For best results, please use Google Chrome to access Intel DevCloud for the Edge.
Go to the Optimize tab and select Deep Learning Workbench.
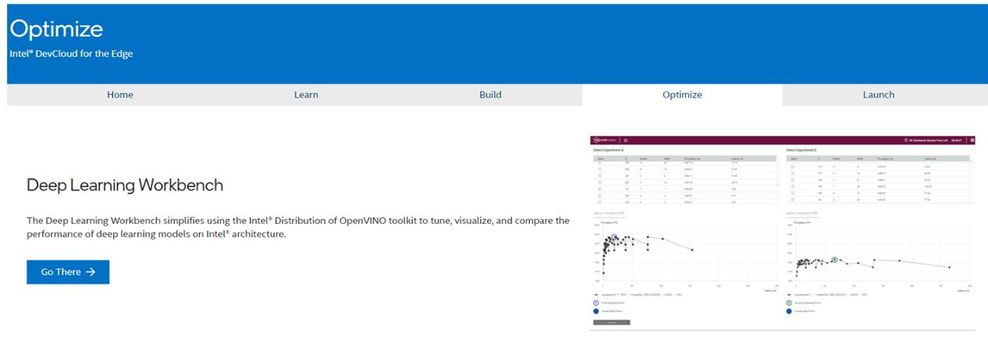
After log-in, launch Deep Learning Workbench from the Optimize tab.
A new notebook opens in JupyterLab with a single cell for you to run. Don’t worry! This is the only code you’ll see. Put your cursor in the cell and click the Run button in the menu bar. A Start button will appear below the cell. Click "Start Application" and you’re on your way.
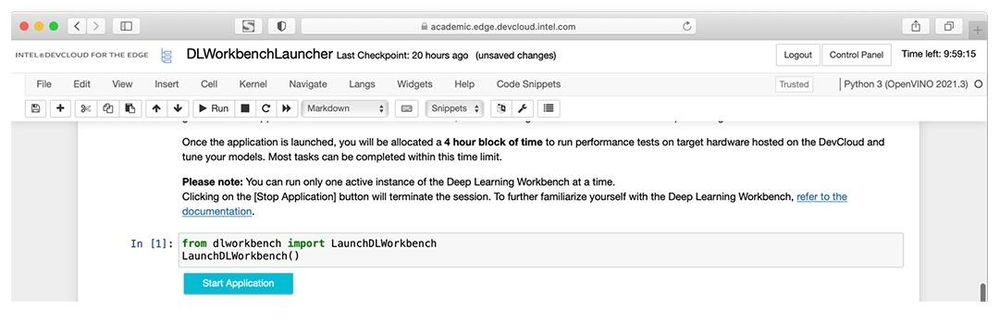
Once the launcher is running in JupyterLab, run the first cell, then click Start Application.
Next up - Part Two: Import, Convert, and Benchmark a TensorFlow* Model on Intel Hardware with OpenVINO™ Deep Learning Wo...
Part Three: Recalibrate Precision and Package Your TensorFlow Model for Deployment with OpenVINO™ Deep Learning Workbench
In our next post, we’ll show you how to create a new project and import and benchmark a TensorFlow model in six simple steps.
Learn more
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.

