Did you know that with just one extra line of code you can get an almost 50% boost in the performance of your deep learning model? We were able to see a jump from 30 FPS to 47 FPS when using the ONNX Tiny YOLOv2 object detection model on an i7 CPU1. It is nearly a 50% gain and it makes a substantial difference in the performance of your Deep Learning Models.
Now, you must be wondering how just one line of code can give you that extra performance boost you were looking for. The answer is quite simple: Intel® Distribution of OpenVINO™ toolkit. The Intel® Distribution of OpenVINO™ toolkit is a comprehensive toolkit for quickly developing applications and solutions that solve a variety of tasks including emulation of human vision, automatic speech recognition, natural language processing, recommendation systems, and many others. OpenVINO™ toolkit does all the magic to boost the performance of your Deep Learning models using the most advanced optimization techniques specifically optimized for Intel® hardware.
Now that you know what OpenVINO™ toolkit does you must be wondering how it ties up with popular AI frameworks like ONNX Runtime (RT). Developers, like yourself, can leverage the power of the Intel® Distribution of OpenVINO™ toolkit through ONNX Runtime by accelerating inference of ONNX models, which can be exported or converted from AI frameworks like TensorFlow, PyTorch, Keras, and much more. Intel and Microsoft collaborated to create OpenVINO™ Execution Provider for ONNX Runtime, which enables ONNX models to run inference using ONNXRuntime API’s with backed as OpenVINO™. With the OpenVINO™ Execution Provider, ONNX Runtime delivers better inferencing performance on the same hardware compared to the default Execution Provider on Intel® CPU, GPU, and VPU. Best of all you can get that performance gain you were looking for with just one additional line of code. We have seen a massive, improved performance using the OpenVINO™ Execution Provider on different workloads.
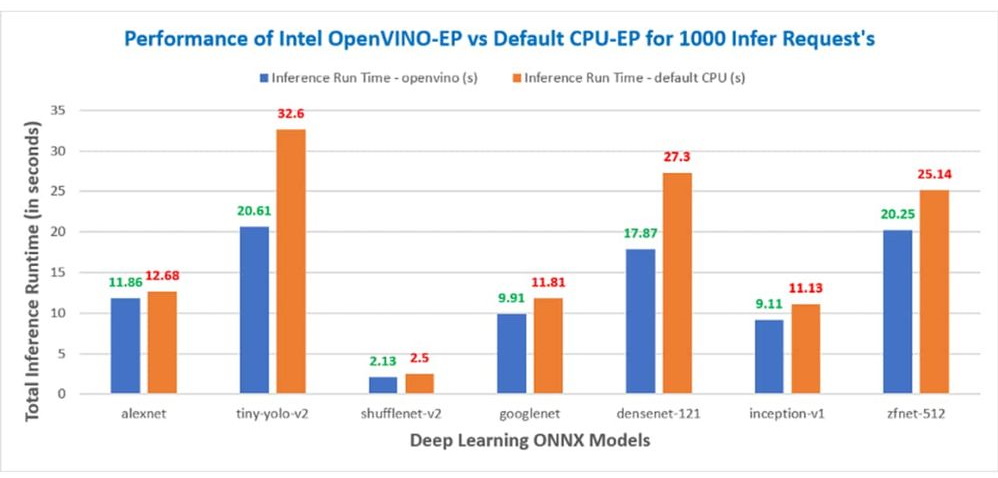
In Figure 1, you can see the performance boost we are getting with OpenVINO™ Execution Provider compared to Default CPU (MLAS). Shorter the inference time, better the performance.
Don’t have access to Intel® hardware? Intel offers a device sandbox, Intel® DevCloud, where you can develop, test, and run your workloads for free on a cluster of the latest Intel® hardware. Keep reading and check out some of the samples we have created using OpenVINO™ Execution Provider for ONNX RT, which can be found on Intel® DevCloud.
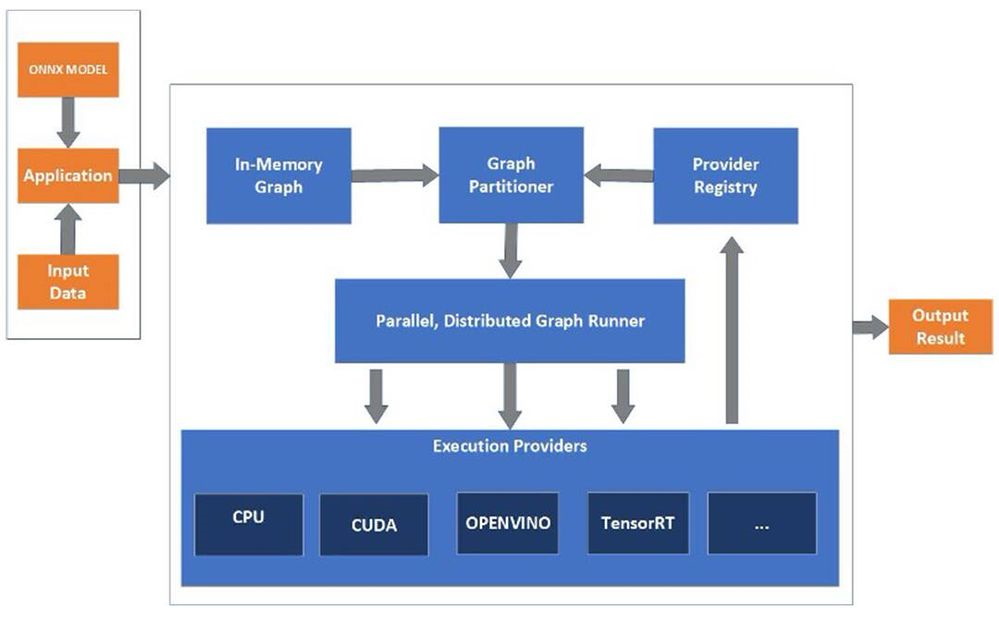
In Figure 2, you can see the architecture diagram for OpenVINO™ Execution Provider for ONNXRuntime. For more details, you can refer to the OpenVINO™ Execution Provider documentation.
Samples
To showcase what you can do with the OpenVINO™ Execution Provider for ONNX Runtime, we have created few samples that are hosted on Intel® DevCloud which showcase the performance boost you’re looking for with just one additional line of code.
This code snippet shows a line of code you must add to get a performance boost. It simply sets OpenVINO™ as the execution provider for inference of our deep learning models and the specific Intel® hardware/accelerator we want to run the inference on.

Cleanroom Sample
This particular sample is about object detection with an ONNX Tiny Yolo V2 model using ONNX Runtime with OpenVINO™ toolkit as an execution provider. It improves the performance of the model by processing every frame in the video while maintaining accuracy.
Cleanroom Sample
CPP Sample
The CPP sample uses a public SqueezeNet Deep Learning ONNX Model from the ONNX Model Zoo. The sample involves processing an image with ONNX Runtime with OpenVINO™ Execution Provider to run inference on various Intel® hardware devices.
Image classification with Squeezenet in CPP
What you need to do now
Notices & Disclaimers
Performance varies by use, configuration, and other factors. Learn more at www.Intel.com/PerformanceIndex.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software, or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
References
1. Processor: Intel(R) Core(TM) i7-7700T CPU @ 2.90GHz, Core(s) per socket: 4, Thread(s) per core: 2
Graphics: Intel HD Graphics 630, clock: 33MHz
Memory: 8192 MB, Type: DDR4
Bios Version: V2RMAR17, Vendor: American Megatrends Inc.
OS: Name: Ubuntu, Version: 18.04.5 LTS
System Information: Manufacturer: iEi, Mfr. No: TANK-870AI-i7/8G/2A-R11, Product Name: SER0, Version: V1.0
Microcode: 0xde
Framework configuration: ONNXRuntime 1.7.0, OpenVINO™ 2021.3 Binary Release, Build Type: Release Mode
Application configuration: ONNXRuntime Python API, EP: OpenVINO™, Default CPU, Input: Video file
Application Metric: Frames per second (FPS): (1.0 / Time Taken to run one ONNXRuntime session)
Test Date: May 14, 2021
Tested by: Intel®
2. Processor: Intel(R) Core(TM) i7-7700T CPU @ 2.90GHz, Core(s) per socket: 4, Thread(s) per core: 2
Graphics: Intel HD Graphics 630, clock: 33MHz
Memory: 8192 MB, Type: DDR4
Bios Version: V2RMAR17, Vendor: American Megatrends Inc.
OS: Name: Ubuntu, Version: 18.04.5 LTS
System Information: Manufacturer: iEi, Mfr. No: TANK-870AI-i7/8G/2A-R11, Product Name: SER0, Version: V1.0
Microcode: 0xde
Framework configuration: ONNXRuntime 1.7.0, OpenVINO™ 2021.3 Binary Release, Build Type: Release Mode
compiler version: gcc version: 7.5.0
Application configuration: onnxruntime_perf_test, No.of Infer Request's: 1000, EP: OpenVINO™,
Number of sessions: 1
Test Date: May 14, 2021
Tested by: Intel®

