This a Part 1 of a 3-part series of articles that demonstrate how to take AI models built using various Python AI frameworks and deploy and scale them using Azure ML Managed Endpoints. In this article, we publish an XGBoost model trained to recognize handwritten digits from a well-known MNIST dataset. We use Azure App Service with Flask, then use machine learning online endpoints.
Machine learning (ML), data science, and the Python language have gained popularity and relevance in the last few years. As of 2021, Python is more popular than well-established old-timers like Java, C#, and C++. It took first place on the TIOBE Index in November 2021, a step up from second place in September of the same year. Python was also the third-most-popular programming language in StackOverflow's 2021 Developer Survey.
Whenever you think about machine learning code, you most likely think in Python. You can run Python code on almost anything: PC, Mac, or Raspberry Pi, with an x86, x86-64, AMD64, or ARM/ARM64 processor, on a Windows, Linux, or macOS operating system.
Machine learning often requires significant processing power, which may exceed your current computer’s capabilities. Luckily this doesn’t matter, as long as you have access to the Internet and the cloud. Azure is a great place to run Python ML workloads of almost any size.
We used Python and Azure services to train a few machine learning models in a previous series. In this three-part series, we'll publish these models to Azure. We’ll deploy PyTorch and TensorFlow models later. But in this first article, we’ll demonstrate how to deploy an XGBoost model using managed endpoints.
Our goal is to create custom Rest API services for real-time inference on machine learning models. We’ll use models trained to recognize handwritten digits using a well-known MNIST dataset.
We'll start by publishing an XGBoost model using Python, Flask, and Azure App Service. Then, we'll use the same model to create an online endpoint, a relatively new Azure Machine Learning feature that’s still in preview.
We rely on Azure CLI to write easy-to-understand and repeatable scripts, which we can store and version with the rest of our code. Find this article’s sample code, scripts, models, and a few test images in the dedicated GitHub repository.
Getting Started
You need Visual Studio Code, a recent Python version (3.7+), and Conda for Python package management to follow this tutorial. If you don’t have other preferences, begin with Miniconda and Python 3.9.
After installing Conda, create and activate a new environment.
$ conda create -n azureml python=3.9
$ conda activate azureml
Apart from Python and Conda, we use Azure command-line tools in version 2.15.0 or newer with the machine learning extension:
$ az extension add -n ml -y
Last but not least, sign up for an Azure account if you don’t yet have one. You get free credits and access to many services.
With all these resources in place, log in to your subscription.
$ az login
Set the following environment variables to use in scripts:
export AZURE_SUBSCRIPTION="<your-subscription-id>"
export RESOURCE_GROUP="azureml-rg"
export AML_WORKSPACE="demo-ws"
export LOCATION="westeurope"
If you haven’t followed examples from the previous series, you also need to create an Azure Machine Learning workspace using this command:
$ az ml workspace create --name $AML_WORKSPACE --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP --location $LOCATION
Now, we’re ready to start preparing our model for deployment.
Registering the Model
Because our model is small, we could bundle and deploy it with our application code. That’s not the best practice, though. Real-life models can be pretty large. Multi megabytes — or even gigabytes — aren’t rare! Plus, we should version our model independently from our code.
So, we use the model registry built into the Azure Machine Learning workspace. We’ve already saved our model there in the first article of the previous series. If you haven’t, you can do it easily:
$ az ml model create --name "mnist-xgb-model" --local-path "./mnist.xgb_model"
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE
Note that we changed our model’s name from “mnist.xgb_model” to “mnist-xgb-model”. The model's name can’t contain periods.
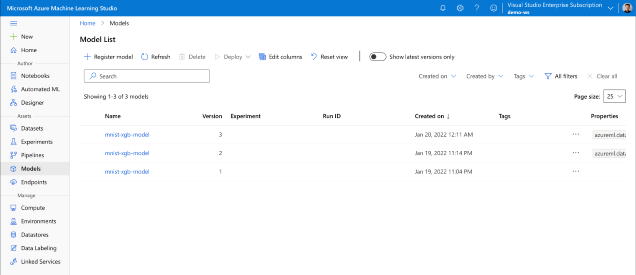
Each time you execute this command, it adds a new model version, regardless of whether or not you upload the same file.
When you log in to Azure Machine Learning Studio, it should list all the versions, like in this screenshot:
Building Model Inference Code
The core part of our Rest API service will be code to load the model and run inference on image data.
We save our code in the file inference_model.py:
import numpy
import xgboost as xgb
from PIL import Image
class InferenceModel():
def __init__(self, model_path):
self.model = xgb.XGBRFClassifier()
self.model.load_model(model_path)
def _preprocess_image(self, image_bytes):
image = Image.open(image_bytes)
image = image.resize((28,28)).convert('L')
image_np = (255 - numpy.array(image.getdata())) / 255.0
return image_np.reshape(1, -1)
def predict(self, image_bytes):
image_data = self._preprocess_image(image_bytes)
prediction = self.model.predict(image_data)
return prediction
This file contains a single class called InferenceModel with three methods: __init__, _preprocess_image, and predict. The __init__ method loads the model from the file and stores it for later use. The _preprocess_image method resizes and converts an image into the format the model expects. In our case, it’s a vector of 784 floats in the range of 0.0 to 1.0.
The predict method runs inference on the provided image data.
Creating Flask Service Code
Now that we have code to handle predictions, we can use it in our Rest API. First, we’ll create a customized Flask service to handle this job.
We start from imports in the new file, app.py:
import json
from flask import Flask, request
from inference_model import InferenceModel
from azureml.core.authentication import MsiAuthentication
from azureml.core import Workspace
from azureml.core.model import Model
We use the MsiAuthentication class for authentication when accessing our Azure Machine Learning workspace resources. The MsiAuthentication class relies on a managed identity in Azure Active Directory (AD). We assign a managed identity to an Azure resource, such as a virtual machine (VM) or App Service. Using managed identities frees us from maintaining credentials and secrets.
Next, we create a method to load our model from the Azure Machine Learning model registry:
def get_inference_model():
global model
if model == None:
auth = MsiAuthentication()
ws = Workspace(subscription_id="<your-subscription-id>",
resource_group="azureml-rg",
workspace_name="demo-ws",
auth=auth)
aml_model = Model(ws, 'mnist-xgb-model', version=1)
model_path = aml_model.download(target_dir='.', exist_ok=True)
model = InferenceModel(model_path)
return model
model = None
We use a global variable inside this method to ensure that the model loads only once.
To load the model, we use Azure ML Workspace and Model classes. Finally, we pass the downloaded model file path to the InferenceModel class.
With all these pieces in place, we can add code to serve our model using Flask:
app = Flask(__name__)
@app.route("/score", methods=['POST'])
def score():
image_data = request.files.get('image')
model = get_inference_model()
preds = model.predict(image_data)
return json.dumps({"preds": preds.tolist()})
After we declare our Flask application using the app variable, we define the route to the score method. This method reads the provided image, gets the inference model, and runs predictions. Finally, it returns prediction results as JSON.
Publishing the App Service with Python and Flask
We have almost all the code to run our REST API service on Azure using App Service with Python and Flask. The last file we need is requirements.txt, with the following content:
Flask==1.0.2
gunicorn==19.9.0
xgboost==1.5.0
pillow==8.3.2
numpy==1.19.5
scikit-learn==1.0.1
azureml-core==1.35.0
Now we can use the Azure CLI to publish our App Service application, using the following commands from the folder containing our files:
$ export APP_SERVICE_PLAN="<your-app-service-plan-name>"
$ export APP_NAME="<your-app-name>"
$ az webapp up --name $APP_NAME --plan $APP_SERVICE_PLAN --sku F1
--os-type Linux --runtime "python|3.8" --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP
Note that the APP_NAME value must be globally unique, as it will be part of the service URL.
This command creates an App Service plan and App Service, uploads our local files to Azure, and starts the application. It may take a while, though, and sometimes it can fail for no apparent reason. In rare cases, even when the deployment seems to complete successfully, the service doesn’t correctly recognize your code as a Flask application, making the service unusable.
When in doubt, you can check deployment progress and logs in your application’s Deployment Center tab:
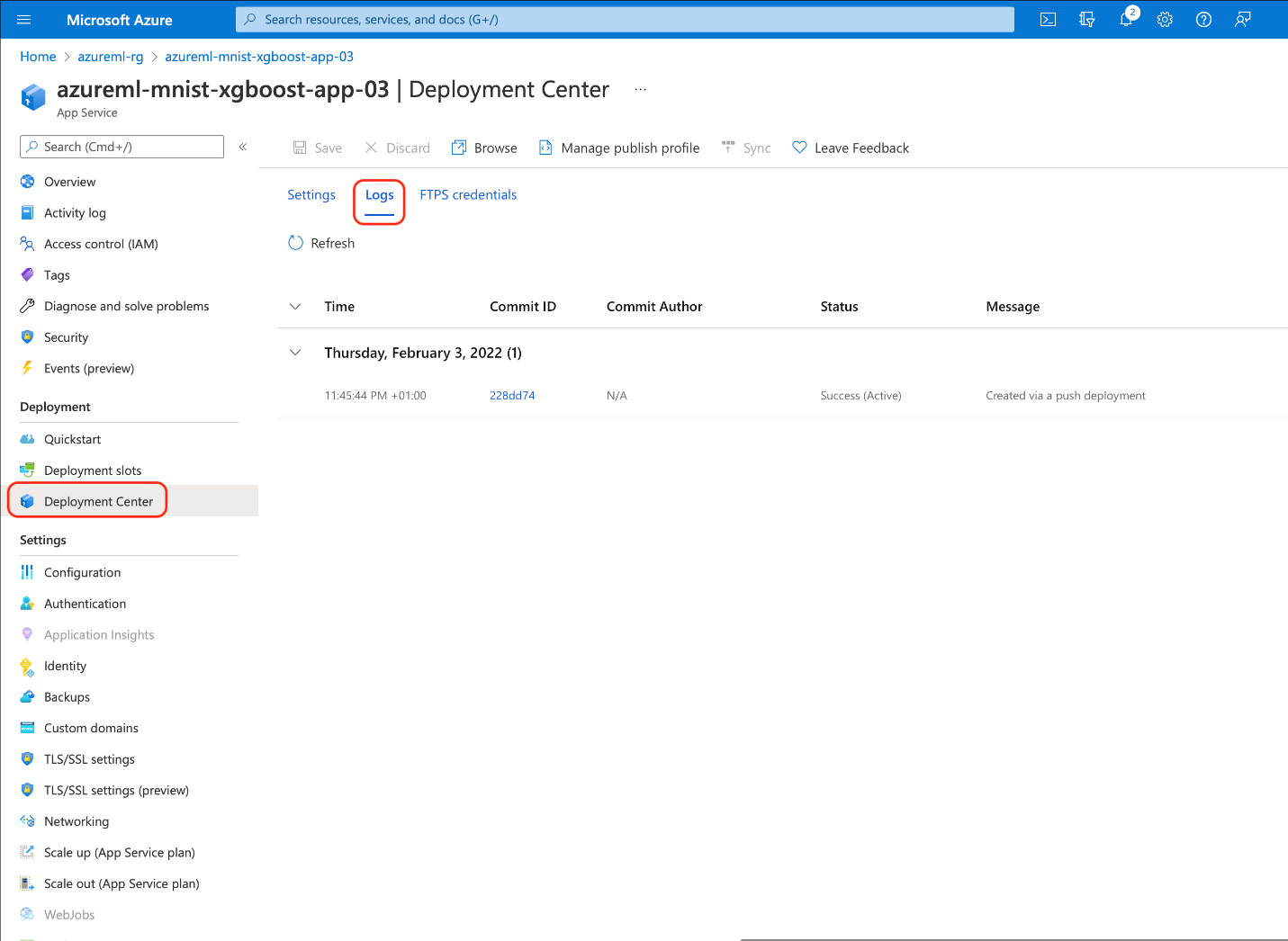
If there’s an issue, especially one that’s timeout-related, just retry the deployment step.
When the command completes, you should get JSON similar to this:
{
"URL": "http://<your-app-name>.azurewebsites.net",
"appserviceplan": "<your-app-service-plan-name>",
"location": "centralus",
"name": "<your-app-name>",
"os": "Linux",
"resourcegroup": "azureml-rg",
"runtime_version": "python|3.8",
"runtime_version_detected": "-",
"sku": "FREE",
"src_path": "<local-path-to-your-files>"
}
Remember the “URL” value. We’ll need it to call the service soon.
Granting Permissions to the App Service Application
Our service will need to download a trained model from our Azure Machine Learning workspace. This action requires authorization, though. We use a managed identity to avoid credentials management.
Assigning a new managed identity to our application is simple. Add the following code:
$ az webapp identity assign --name $APP_NAME --resource-group $RESOURCE_GROUP
On completion, we should expect a JSON.
{
"principalId": "<new-principal-id>",
"tenantId": "<tenant-id>",
"type": "SystemAssigned",
"userAssignedIdentities": null
}
When we have the returned “<new-principal-id>” value, we can add the required permission.
$ az role assignment create --role reader --assignee <new-principal-id>
--scope /subscriptions/$AZURE_SUBSCRIPTION/resourceGroups/$RESOURCE_GROUP/providers/
Microsoft.MachineLearningServices/workspaces/$AML_WORKSPACE
The reader role should be enough for our purposes. If our application needs to create additional resources, we should use the contributor role instead.
Testing the Service
It wouldn’t be fun to use any images we have already used for training the model. So, let’s use a few new ones. You can find them in the sample code folder, in files test-images/d0.png to d9.png. They look like this:
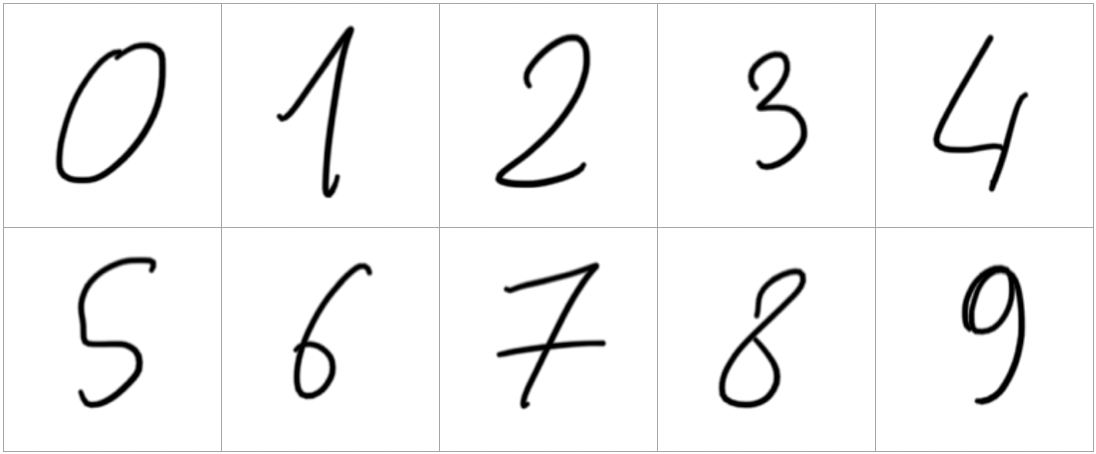
There are no strict requirements for these images. Our service’s code will rescale and convert them to the expected size and format.
We need to send POST requests to call our service. We can use either Postman or curl. We can execute our requests directly from the command line using curl:
$ curl -X POST -F 'image=@./test-images/d6.png' https://$APP_NAME.azurewebsites.net/score
If everything goes well, we can expect the following response:
{"preds": [6]}
Great! The answer seems to be correct in our simple XGBoost model. It won’t be the norm, though.
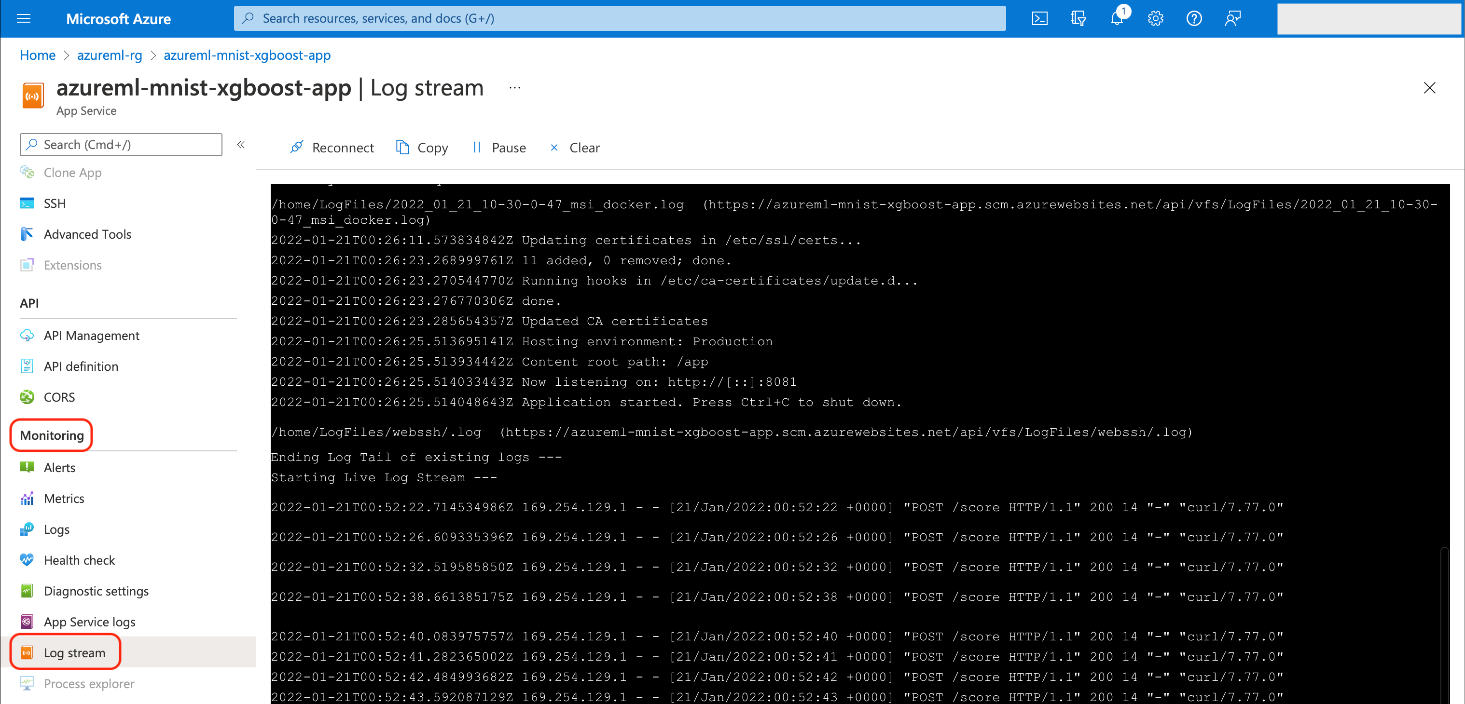
Checking the App Service Logs
If you encounter any issues, you may want to check your service logs. You can do so via the Azure portal Monitoring > Log stream tab:
Alternatively, you can access the logs using the Azure CLI:
$ az webapp log tail --name $APP_NAME --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP
Using Azure Machine Learning and Managed Endpoints
Publishing our model using a custom Flask application hosted as an Azure App Service is straightforward. By doing so, we can experience all standard App Service benefits, like manual or automated scaling, depending on the pricing tier.
Still, with an App Service solution, we need to write and maintain the code related to the model inference and the code responsible for serving it as a REST service, security, and other lower-level details.
One of the new alternatives available in Azure Machine Learning (still in preview) is the managed endpoints mechanism. We’ll create an online endpoint with our model in the following sections.
Creating the Online Endpoint Code
We’ll copy the same InferenceModel class from our Flask application into the inference_model.py file in the new folder endpoint-code.
As with the Flask app before, we need some code to define our service. We put the code in the endpoint-code/aml-score.py file. This time, we may rely on built-in Azure Machine Learning mechanisms:
import os
import json
from inference_model import InferenceModel
from azureml.contrib.services.aml_request import rawhttp
from azureml.contrib.services.aml_response import AMLResponse
def init():
global model
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "mnist.xgb_model"
)
model = InferenceModel(model_path)
@rawhttp
def run(request):
if request.method != 'POST':
return AMLResponse(f"Unsupported verb: {request.method}", 400)
image_data = request.files['image']
preds = model.predict(image_data)
return AMLResponse(json.dumps({"preds": preds.tolist()}), 200)
We need only two methods. The code calls the first one, init, once when the endpoint starts. It’s a great place to load our model. We use the AZUREML_MODEL_DIR environment variable to do so, which indicates our model files’ locations.
The following run method is pretty straightforward. First, we ensure that only the POST requests are accepted. Then the actual logic begins: We retrieve an image from the request, then run and return predictions.
Note the @rawhttp decorator. We require it to access raw request data (binary image content in our case). Without it, the request parameter passed to the run method would be limited to the parsed JSON.
Configuring the Online Endpoint
Apart from the code, we also need three configuration files. The first one, endpoint-code/aml-env.yml, stores the Conda environment definition:
channels:
- conda-forge
- defaults
dependencies:
- python=3.7.10
- numpy=1.19.5
- xgboost=1.5.0
- scikit-learn=1.0.1
- pillow=8.3.2
- pip
- pip:
- azureml-defaults==1.35.0
- inference-schema[numpy-support]==1.3.0
The following two contain configurations for the endpoint and its deployment.
The endpoint configuration file aml-endpoint.yml contains:
$schema: https:
name: mnistxgboep
auth_mode: key
Apart from the endpoint name, which we can change in the script anyway, this file contains only a single meaningful line. It sets auth_mode to key so that we use a randomly generated “secret” string as an authentication token when calling our endpoint.
The last file, aml-endpoint-deployment.yml, contains this code:
$schema: https:
name: blue
endpoint_name: mnistxgboep
model: azureml:mnist-xgb-model:1
code_configuration:
code:
local_path: ./endpoint-code
scoring_script: aml-score.py
environment:
conda_file: ./endpoint-code/aml-env.yml
image: mcr.microsoft.com/azureml/minimal-ubuntu18.04-py37-cpu-inference:latest
instance_type: Standard_F2s_v2
instance_count: 1
In the deployment configuration, we set essential details, such as model name and version. The code_configuration section indicates our endpoint’s path and its main script file. Note that you need to define the model version explicitly so the code automatically downloads and saves this exact model version to be ready for our service.
Next, we define a Docker image, Conda environment configuration file, VM instance size, and instances count.
Creating a Managed Online Endpoint
With all these files ready, we can start deployment. We start from the endpoint:
$ export ENDPOINT_NAME="<your-endpoint-name>"
$ az ml online-endpoint create -n $ENDPOINT_NAME -f aml-endpoint.yml
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE
As with the App Service application name before, the endpoint name must be unique per Azure region. It will become part of the URL formatted like this:
https://<your-endpoint-name>.<region-name>.inference.ml.azure.com/score
After creating the endpoint, we can finally deploy our inference code:
$ az ml online-deployment create -n blue
--endpoint $ENDPOINT_NAME -f aml-endpoint-deployment.yml
--all-traffic --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP --workspace-name $AML_WORKSPACE
After a long while, the command should return confirmation that the deployment is complete and the endpoint is ready to use. Now, we can check how it works.
Testing the Online Endpoint
We need the endpoint URL, the endpoint key, and a sample image to call our endpoint. We already used sample images, so we need only the endpoint URL and key. One way to obtain them is via Azure Machine Learning Studio, from the endpoint’s Consume tab:
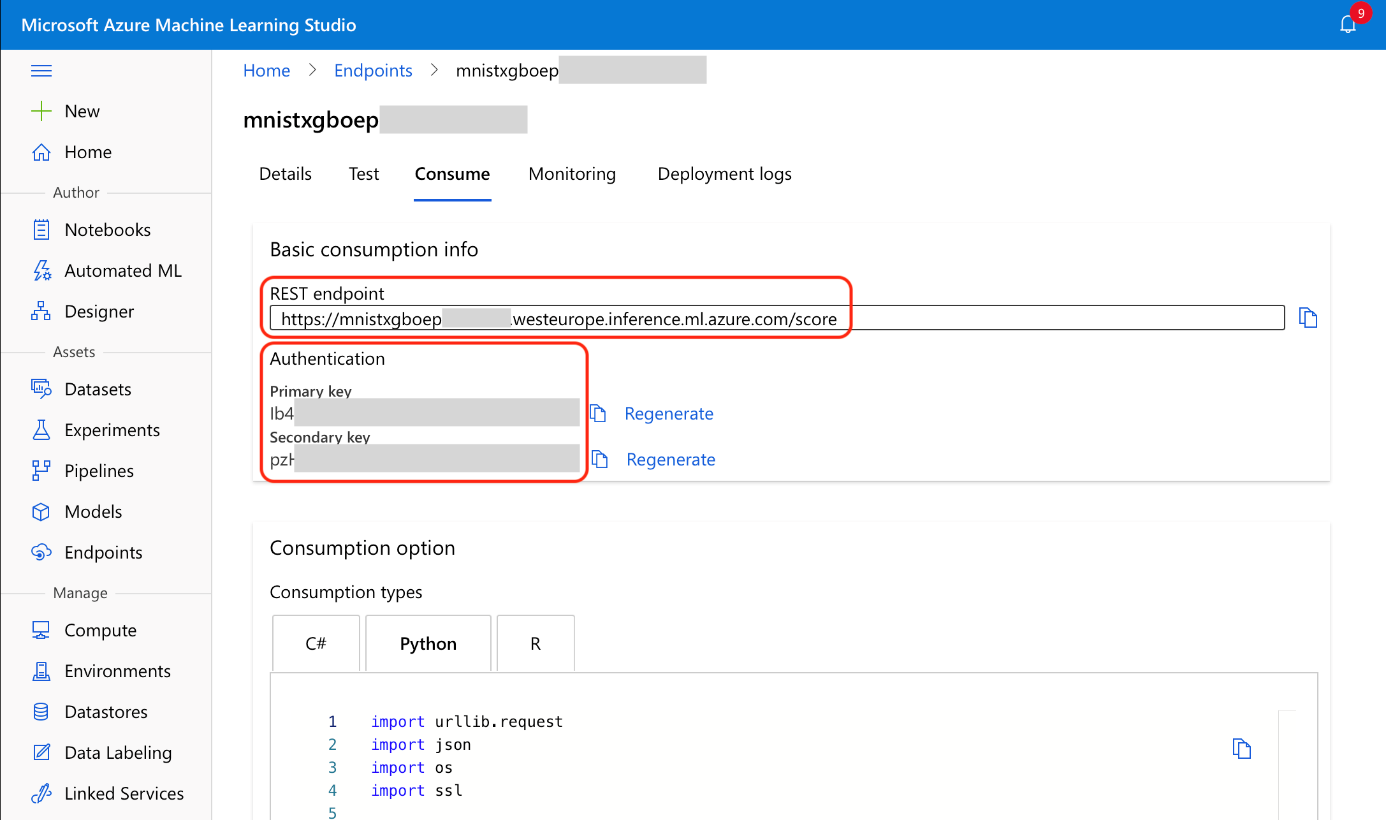
As (almost) always, we can also obtain these values using the Azure CLI:
$ SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv
--query scoring_uri --resource-group $RESOURCE_GROUP --workspace $AML_WORKSPACE)
$ ENDPOINT_KEY=$(az ml online-endpoint get-credentials --name $ENDPOINT_NAME
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE -o tsv --query primaryKey)
Regardless, with the SCORING_URI and ENDPOINT_KEY variables populated, we can call our service:
$ curl -X POST -F 'image=@./test-images/d6.png'
-H "Authorization: Bearer $ENDPOINT_KEY" $SCORING_URI
If everything went well, we should get the same answer as from our Flask application:
{"preds": [6]}
Deleting Azure Resources
You can delete all the resources you no longer need to reduce Azure charges. Remember the App Service plans and managed endpoints in particular (although we have used a free App Service plan in this example).
Next Steps
We have successfully published an XGBoost model trained to recognize handwritten digits, using Flask with App Service, and managed online endpoints. The following article is similar, but instead of XGBoost, we'll use PyTorch, and instead of Flask, we'll use FastAPI. Additionally, we'll skim pretty quickly through the FastAPI code to focus on a few additional managed online endpoint features.
Continue to part two of this series to learn how to deploy and scale PyTorch models.
To learn how to use an online endpoint (preview) to deploy a machine learning model, check out Deploy and score a machine learning model by using an online endpoint.

