This a Part 2 of a 3-part series of articles that demonstrate how to take AI models built using various Python AI frameworks and deploy and scale them using Azure ML Managed Endpoints. In this article, PyTorch model was trained to recognize handwritten digits. We use FastAPI with App Service, then Azure Machine Learning online endpoints.
Machine learning (ML) usually needs plenty of processing power. Although your Python ML project may exceed your current computer’s capabilities, you can use Azure to run ML workloads of almost any size.
In the first article of this three-part series, we published an XGBoost model trained to recognize handwritten digits from a well-known MNIST dataset. We used Azure App Service with Flask, then used machine learning online endpoints. In this tutorial, we’ll use another model from the previous series. The model is a little more demanding but allows us to explore slightly more advanced scenarios.
Our goal is to create custom Rest API services for real-time inference on machine learning models. We’ll start by publishing a PyTorch model using Python, FastAPI, and Azure App Service. Then, we'll use the same model to create an online endpoint, a relatively new Azure Machine Learning feature that's still in preview.
We use the Azure CLI to write easy-to-understand and repeatable scripts, which we can store and version with the rest of our code. Find the sample code, scripts, models, and a few test images in the dedicated GitHub repository.
Getting Started
To follow this article’s examples, you need Visual Studio Code, a recent Python version (3.7+), and Conda for Python package management. If you don’t have other preferences, begin with Miniconda and Python 3.9.
After installing Conda, create and activate a new environment:
$ conda create -n azureml python=3.9
$ conda activate azureml
Apart from Python and Conda, we’ll use Azure command-line tools in version 2.15.0 or newer, with the machine learning extension:
$ az extension add -n ml -y
Last but not least, sign up for a free Azure account if you don’t yet have one, and enjoy hundreds of dollars in credits and access to various services.
With all these resources in place, log in to your subscription.
$ az login
Then, set the following environment variables to use in scripts:
export AZURE_SUBSCRIPTION="<your-subscription-id>"
export RESOURCE_GROUP="azureml-rg"
export AML_WORKSPACE="demo-ws"
export LOCATION="westeurope"
If you haven’t followed examples from the previous series, you also need to create an Azure Machine Learning workspace:
$ az ml workspace create --name $AML_WORKSPACE --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP --location $LOCATION
We’re ready to start preparing the model for deployment.
Registering the Model
Because our model is small, we could bundle and deploy it with our application code, but it’s not the best practice. Real-life models can be very large, so we should be able to version our model independently from our code. We’ll use the Azure Machine Learning workspace’s built-in model registry.
In the second article of the previous series, we already saved our model to the registry. If you don’t have it there already, just run this command:
$ az ml model create --name "mnist-pt-model" --local-path "./mnist.pt_model"
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE
Creating the Model Inference Code
As in the previous article, the core part of our Rest API service is code to load the model and run inference on image data. We store the code in the inference_model.py file.
The file starts with imports:
import numpy as np
from PIL import Image
import torch
from torch.nn import functional as F
from torch import nn
Next, our model needs a class. It must be the same code we used for training.
class NetMNIST(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2,2))
x = F.max_pool2d(F.dropout(F.relu(self.conv2(x)), p=0.2), (2,2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, p=0.2, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
Now, we can add our InferenceModel class:
class InferenceModel():
def __init__(self, model_path):
is_cuda_available = torch.cuda.is_available()
self.device = torch.device("cuda" if is_cuda_available else "cpu")
self.model = NetMNIST().to(self.device)
self.model.load_state_dict(torch.load(model_path))
def _preprocess_image(self, image_bytes):
image = Image.open(image_bytes)
image = image.resize((28,28)).convert('L')
image_np = (255 - np.array(image.getdata())) / 255.0
return torch.tensor(image_np).float().to(self.device)
def predict(self, image_bytes):
image_data = self._preprocess_image(image_bytes)
with torch.no_grad():
prediction = self.model(image_data.reshape(-1,1,28,28)).cpu().numpy()
return np.argmax(prediction, axis=1)
As with our XGBoost model before, this file contains a single class, InferenceModel. The class has three methods: __init__, _preprocess_image, and predict.
The __init__ method loads the model from a file and stores it for later. It also detects if there’s a CUDA GPU available.
The _preprocess_image method resizes the image and converts it into a format acceptable to the model. It’s a single-channel 28x28 tensor with floats from the range of 0.0 to 1.0 for our PyTorch model. Note the inversion of the pixels' intensity. We do this because we plan to use our model on standard black-on-white images, while the MNIST training dataset has inverted, white-on-black values.
The final predict method runs inference on provided image data, using the detected device and loaded model.
Contrary to our training code in the previous series, we don't use a data loader. We feed image data directly to the model instead. A data loader allows processing batches of data. Our API handles a single image at a time, making a data loader redundant.
Building the FastAPI Service Code
Now that we have the code to handle the predictions, we can use it in our Rest API service. Let’s create a custom Flask service to perform this job.
The new main.py file will contain all the service code, and the file structure will mirror the app.py file from the previous article:
from fastapi import FastAPI, File
from io import BytesIO
from inference_model import InferenceModel
from azureml.core.authentication import MsiAuthentication
from azureml.core import Workspace
from azureml.core.model import Model
def get_inference_model():
global model
if model == None:
auth = MsiAuthentication()
ws = Workspace(subscription_id="<your-subscription-id>",
resource_group="azureml-rg",
workspace_name="demo-ws",
auth=auth)
aml_model = Model(ws, 'mnist-pt-model', version=1)
model_path = aml_model.download(target_dir='.', exist_ok=True)
model = InferenceModel(model_path)
return model
app = FastAPI(title="PyTorch MNIST Service API", version="1.0")
@app.post("/score")
async def score(image: bytes = File(...)):
if not image:
return {"message": "No image_file"}
model = get_inference_model()
preds = model.predict(BytesIO(image))
return {"preds": str(preds)}
model = None
As before, we use the MsiAuthentication class for authentication to access resources from our Azure Machine Learning workspace. The MsiAuthentication class relies on a managed identity in Azure Active Directory. We assign a managed identity to an Azure resource, such as a virtual machine or App Service. Using managed identities frees us from maintaining any credentials or secrets.
The only change to the get_inference_model method from the previous article is the model name.
The last method, score, is responsible for running predictions. As with every API method in FastAPI, it needs to be asynchronous, hence the async keyword. Note that the File(…) statement in the score method declaration isn’t a placeholder.
Publishing the App Service with Python and FastAPI
We have almost all the code to run our REST API service on Azure using App Service with Python and FastAPI.
The last file we need is requirements.txt, with the following content:
fastapi
gunicorn
uvicorn
python-multipart==0.0.5
torch==1.9.0
pillow==8.3.2
azureml-defaults==1.35.0
This code doesn’t define explicit versions for fastapi, gunicorn, and uvicorn dependencies. It’s intentional, and we'll justify it before this section ends.
Now, we can use the Azure CLI to publish our App Service application using the following commands (from the folder containing our files):
$ APP_SERVICE_PLAN="<your-app-service-plan-name>"
$ APP_NAME="<your-app-name>"
$ az webapp up --name $APP_NAME --plan $APP_SERVICE_PLAN --sku B2 --os-type Linux
--runtime "python|3.7" --subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
Remember that the APP_NAME value must be globally unique, as it will be part of the service URL.
Publishing the application may take an extended time, though. In some not-so-rare cases, it may not end at all. This may be related to the size of installed dependencies. PyTorch alone takes over 1 GB, forcing the change of the service plan SKU from the free F1 tier (with 1 GB of RAM) to at least B2 (with 3.5 GB of RAM). Even then, random timeouts during the deployment have occurred, which led to a seemingly never-ending or failed deployment process.
Enforcing specific versions of dependencies further increases the probability of failed attempts. It may be related to conflicts with other packages from the default App Service image. Explicit versions in the requirements.txt file for some libraries have been removed to reduce these issues.
All that suggests that serving complex models using App Service deployments may not always be the best choice for production applications. Luckily, Azure provides us with many alternatives.
One is Web App for Containers. We have complete control over all dependencies using our own Docker container, limiting potential issues. We can also use Container Instances or AKS.
There’s a new option, though: managed online endpoints. We’ll use this later in this article.
For now, let’s go back to our App Service deployment. When our command completes, it should return JSON similar to the following:
{
"URL": "http://<your-app-name>.azurewebsites.net",
"appserviceplan": "<your-app-service-plan-name>",
"location": "westeurope",
"name": "<your-app-name>",
"os": "Linux",
"resourcegroup": "azureml-rg",
"runtime_version": "python|3.7",
"runtime_version_detected": "-",
"sku": "B2",
"src_path": "<local-path-to-your-files>"
}
Updating App Service Configuration for FastAPI
App Service automatically detects and handles Flask applications using default Gunicorn workers. However, this time we use FastAPI.
We need to explicitly set our application’s startup command using the following Azure CLI command:
$ az webapp config set --name $APP_NAME --startup-file "gunicorn --workers=2
--worker-class uvicorn.workers.UvicornWorker main:app" --resource-group $RESOURCE_GROUP
This command ensures using Gunicorn with Uvicorn workers, which are required to run our FastAPI service.
Alternatively, we can use the Azure portal and paste the startup command in the Startup Command field of General settings:
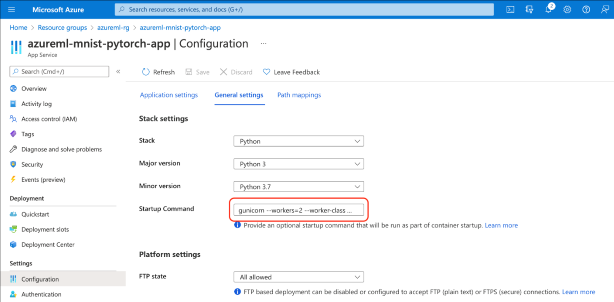
Granting Permissions to the App Service Application
We grant permissions the same way as for the XGBoost model. Our service must download a trained model from the Azure Machine Learning workspace, which requires authorization. We use managed identity to avoid credentials management.
Assigning a new managed identity to our application is simple. Enter the following:
$ az webapp identity assign --name $APP_NAME --resource-group $RESOURCE_GROUP
On completion, we should expect a JSON output:
{
"principalId": "<new-principal-id>",
"tenantId": "<tenant-id>",
"type": "SystemAssigned",
"userAssignedIdentities": null
}
Equipped with the returned <new-principal-id> value, we can add the required permission:
$ az role assignment create --role reader --assignee <new-principal-id>
--scope /subscriptions/$AZURE_SUBSCRIPTION/resourceGroups/$RESOURCE_GROUP/providers/
Microsoft.MachineLearningServices/workspaces/$AML_WORKSPACE
The reader role should be enough for our purposes. If our application needs to create additional resources, we should use the contributor role instead.
Testing the Service
We use images from our sample code (test-images/d0.png to d9.png) to test our service:
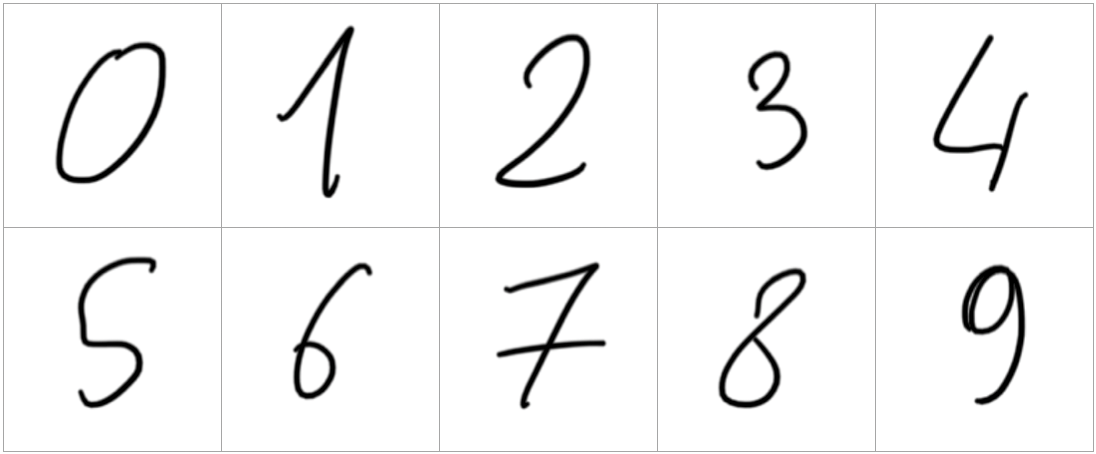
There are no strict requirements for these images. Our service’s code will rescale and convert the images to the expected size and format.
We need to send POST requests to call our service. We can use either Postman or curl. With curl, we can execute our requests directly from the command line.
$ curl -X POST -F 'image=@./test-images/d6.png' https://$APP_NAME.azurewebsites.net/score
If everything goes well, we should expect the following response:
{"preds": [6]}
The answer seems to be correct. Our PyTorch model should work much better than the simple XGBoost model from the previous article.
Checking the App Service Logs
If you encounter any issues, you may want to check your service logs. You can do so via the Azure portal Monitoring > Log stream tab.
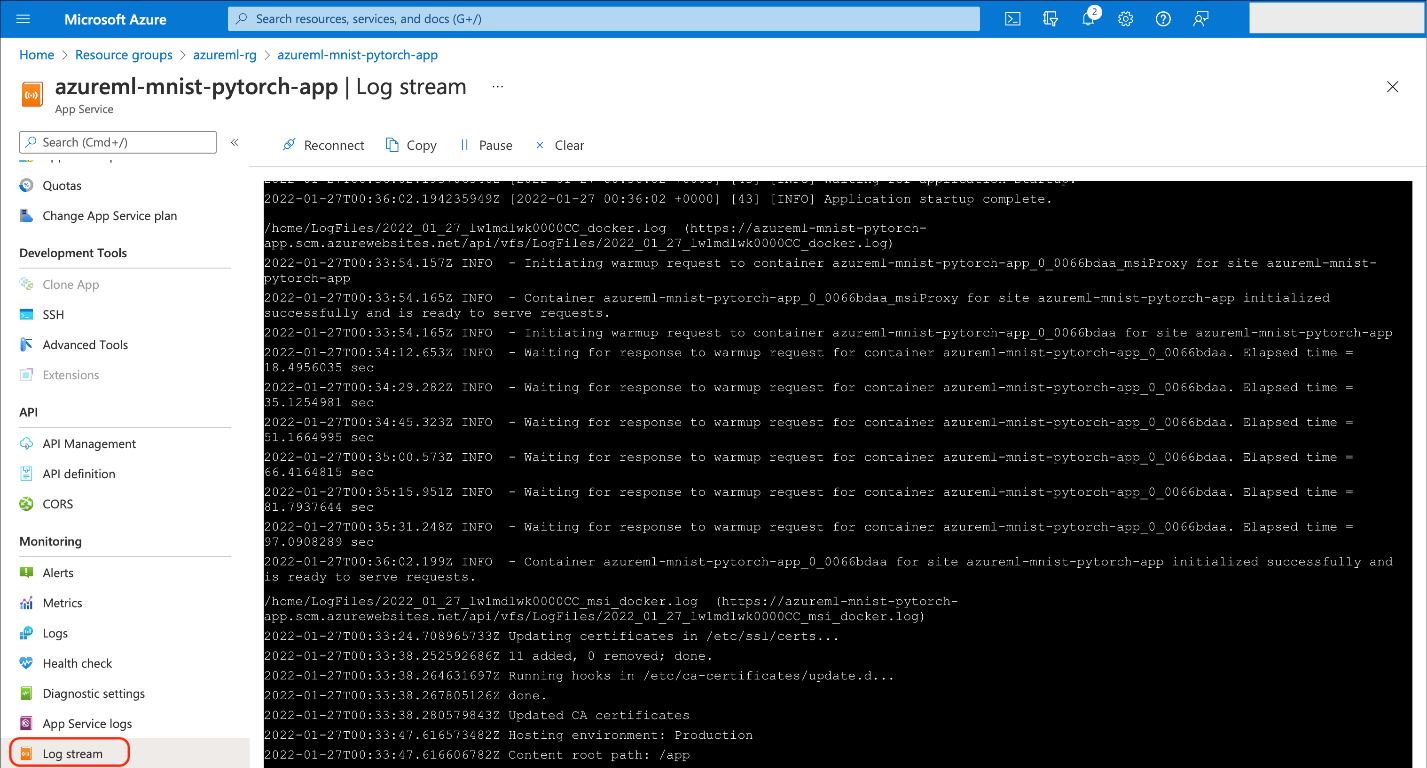
Alternatively, you can access the logs using the Azure CLI.
$ az webapp log tail --name $APP_NAME --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP
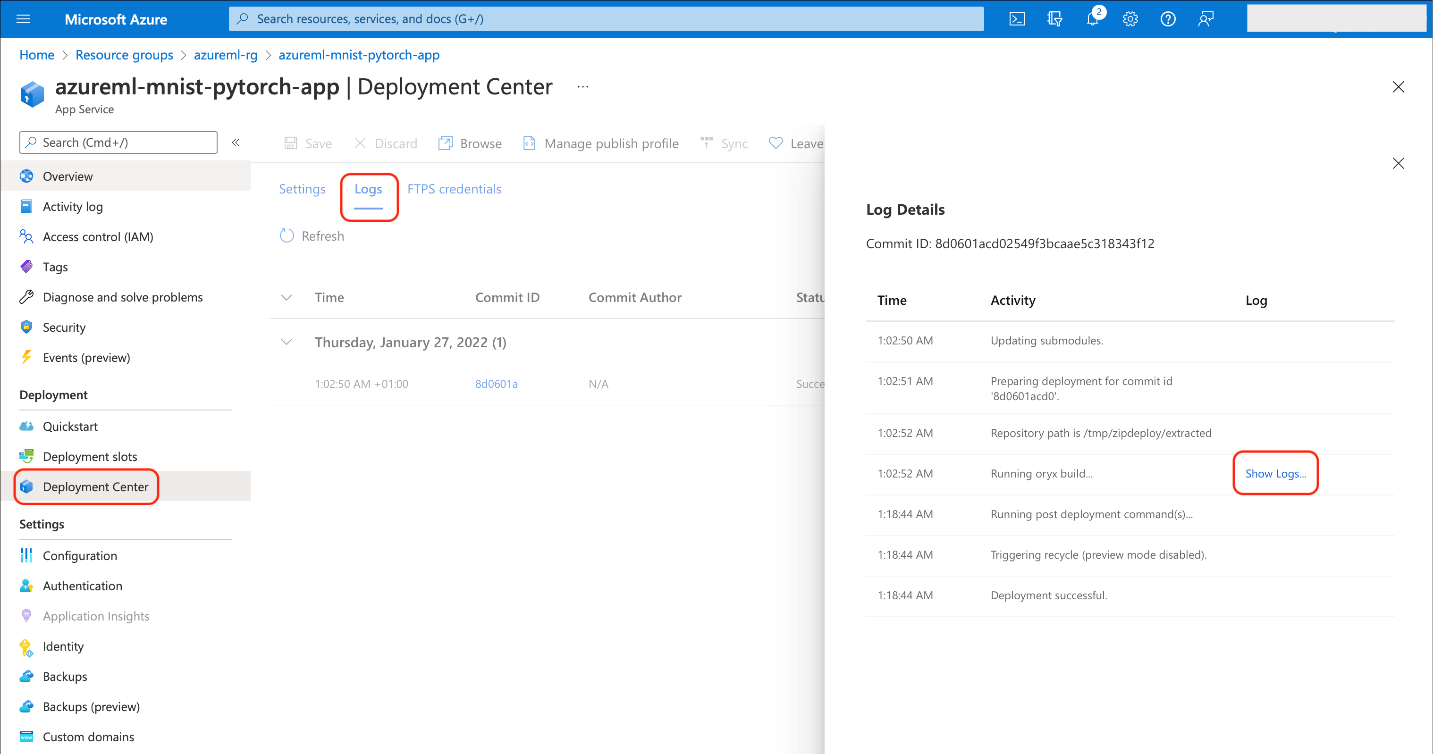
Be aware that only execution logs will be present. If there’s an issue with the deployment, try the Azure portal’s Deployment Center logs.
Using Azure Machine Learning and Managed Endpoints
Publishing our model using a custom Flask application hosted as an Azure App Service is straightforward. However, the more complex our environment is, the more issues we encounter during the setup. We can use the Web App for Containers or managed online endpoints (in preview) to avoid these setup issues. In the following sections, we’ll use endpoints.
Creating the Online Endpoint Code
Like the previous article, we’ll use the same InferenceModel class we created for our Flask application in the inference_model.py file, copied to the new folder, endpoint-code.
Because the InferenceModel class completely abstracts the model, our endpoint code in the file endpoint-code/aml-score.py can be almost exactly the same as the XGBoost model:
import os
import json
from inference_model import InferenceModel
from azureml.contrib.services.aml_request import rawhttp
from azureml.contrib.services.aml_response import AMLResponse
def init():
global model
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "mnist.pt_model"
)
model = InferenceModel(model_path)
@rawhttp
def run(request):
if request.method != 'POST':
return AMLResponse(f"Unsupported verb: {request.method}", 400)
image_data = request.files['image']
preds = model.predict(image_data)
return AMLResponse(json.dumps({"preds": preds.tolist()}), 200)
The only difference there is the model's name, mnist.pt_model.
The rest remains the same. The code calls the first method, init, once when the endpoint starts. It’s a great place to load our model. We use the AZUREML_MODEL_DIR environment variable to do so, which indicates where our model files are.
The following run method is straightforward. First, we ensure that only the POST requests are accepted. Next, we retrieve an image from the request, then run and return predictions.
Note the @rawhttp decorator. It accesses raw request data, such as binary image content. Without it, the request parameter passed to the run method would be limited to the parsed JSON.
Configuring the Online Endpoint
Apart from the code, we also need three configuration files.
The first, endpoint-code/aml-env.yml, stores the Conda environment definition.
channels:
- pytorch
- conda-forge
- defaults
dependencies:
- python=3.7.10
- pytorch=1.9.0
- cpuonly # Replace with cudatoolkit to use GPU
- pillow=8.3.2
- gunicorn=20.1.0
- numpy=1.19.5
- pip:
- azureml-defaults==1.35.0
- inference-schema[numpy-support]==1.3.0
The following two files look the same as in the previous article. They contain configuration for the endpoint and its deployment.
The endpoint configuration file, aml-endpoint.yml, contains:
$schema: https:
name: mnistptoep
auth_mode: key
The last file, aml-endpoint-deployment.yml, contains:
$schema: https:
name: blue
endpoint_name: mnistptoep
model: azureml:mnist-pt-model:1
code_configuration:
code:
local_path: ./endpoint-code
scoring_script: aml-score.py
environment:
conda_file: ./endpoint-code/aml-env.yml
image: mcr.microsoft.com/azureml/minimal-ubuntu18.04-py37-cpu-inference:latest
instance_type: Standard_F2s_v2
instance_count: 1
You can use a custom image or one from Microsoft’s curated image catalogue. The list of available images is quite extensive, although there’s little reason to use most of them in our case. Regardless of which image you select, the code will still create a new Conda environment according to your specification.
We need to include generic components in our environment, even if they’re already present in the image. We might use azureml-inference-server-http (from azureml-defaults) and gunicorn, for example.
Still, if you require some system-level dependencies not included in your Conda environment (such as Open MPI or CUDA drivers), you’ll most likely find what you need there. In our case, the selected minimal image is enough.
Note that while Microsoft recommends always using the latest image tag, you may consider using a fixed value for maximum reproducibility in some cases. You can find all available tags for a given image using the following URL template:
https://mcr.microsoft.com/v2/<namespace>/<repository>/tags/list
For example, this URL:
https://mcr.microsoft.com/v2/azureml/minimal-ubuntu18.04-py37-cpu-inference/tags/list
returns:

The screenshot shows that there are multiple versions per month, so the image is updated frequently.
Creating the Managed Online Endpoint
With all these files ready, we can start deployment. We start from the endpoint:
$ ENDPOINT_NAME="<your-endpoint-name>"
$ az ml online-endpoint create -n $ENDPOINT_NAME -f aml-endpoint.yml
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE
As with the App Service application name before, the endpoint name must be unique per Azure region, as it will become a part of the URL, formatted like this:
https://<your-endpoint-name>.<region-name>.inference.ml.azure.com/score
Now that we’ve created the endpoint, we can finally deploy our inference code:
$ az ml online-deployment create -n blue
--endpoint $ENDPOINT_NAME -f aml-endpoint-deployment.yml
--all-traffic --subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE
After a long while, the command should return confirmation that the deployment is complete and the endpoint is ready to use. It takes time to provision your VMs, download the base image, and set up your environment.
To check the endpoint logs, type:
$ az ml online-deployment get-logs -n blue --endpoint $ENDPOINT_NAME
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE
The output should be similar to the following screenshot:
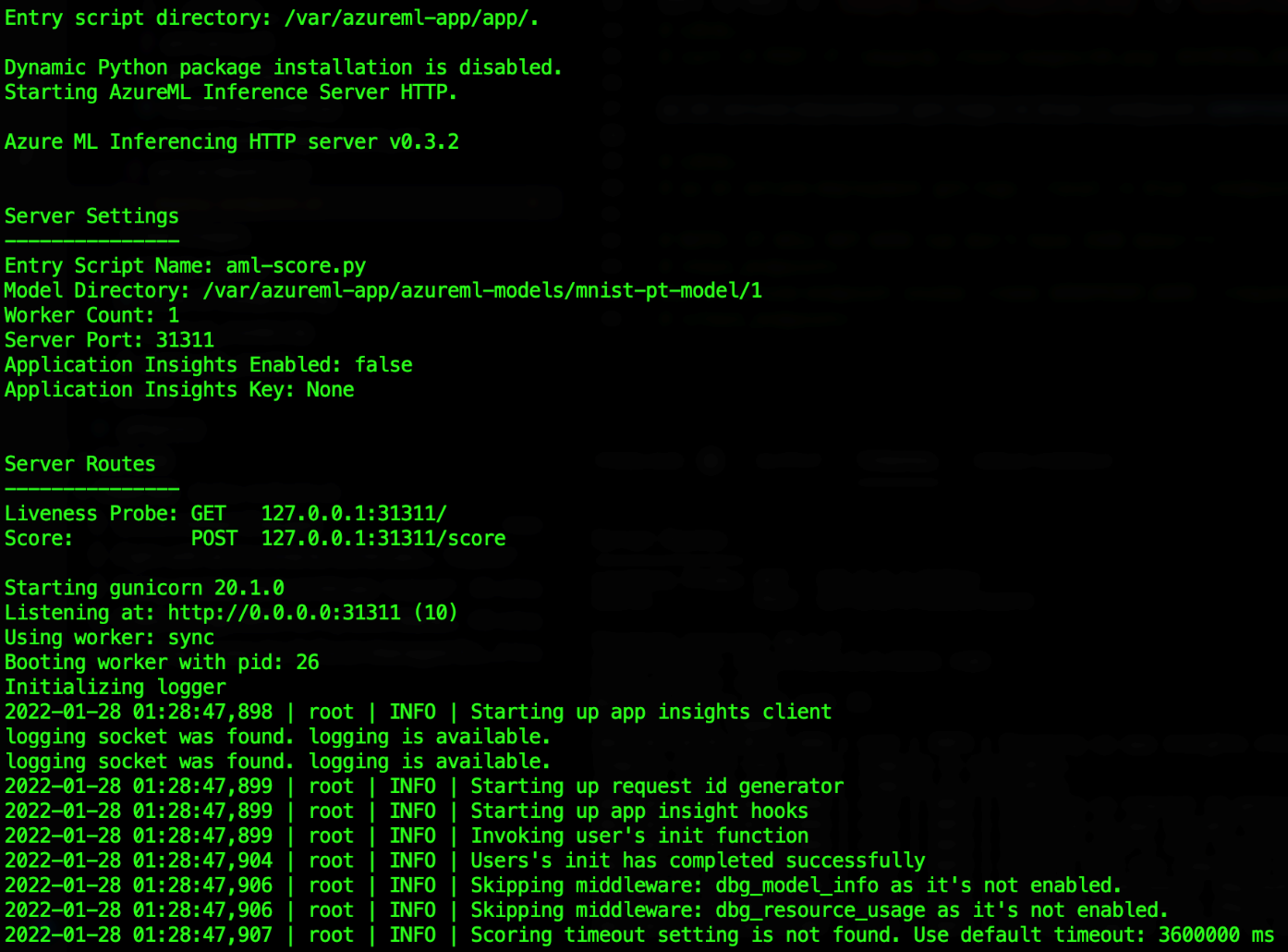
Testing the Online Endpoint
We need three things to call our endpoint: the endpoint URL, an endpoint key, and a sample image. We’ve used sample images already, so we need only the URL and key.
One way to obtain them is via Azure Machine Learning Studio, from the endpoint’s Consume tab.
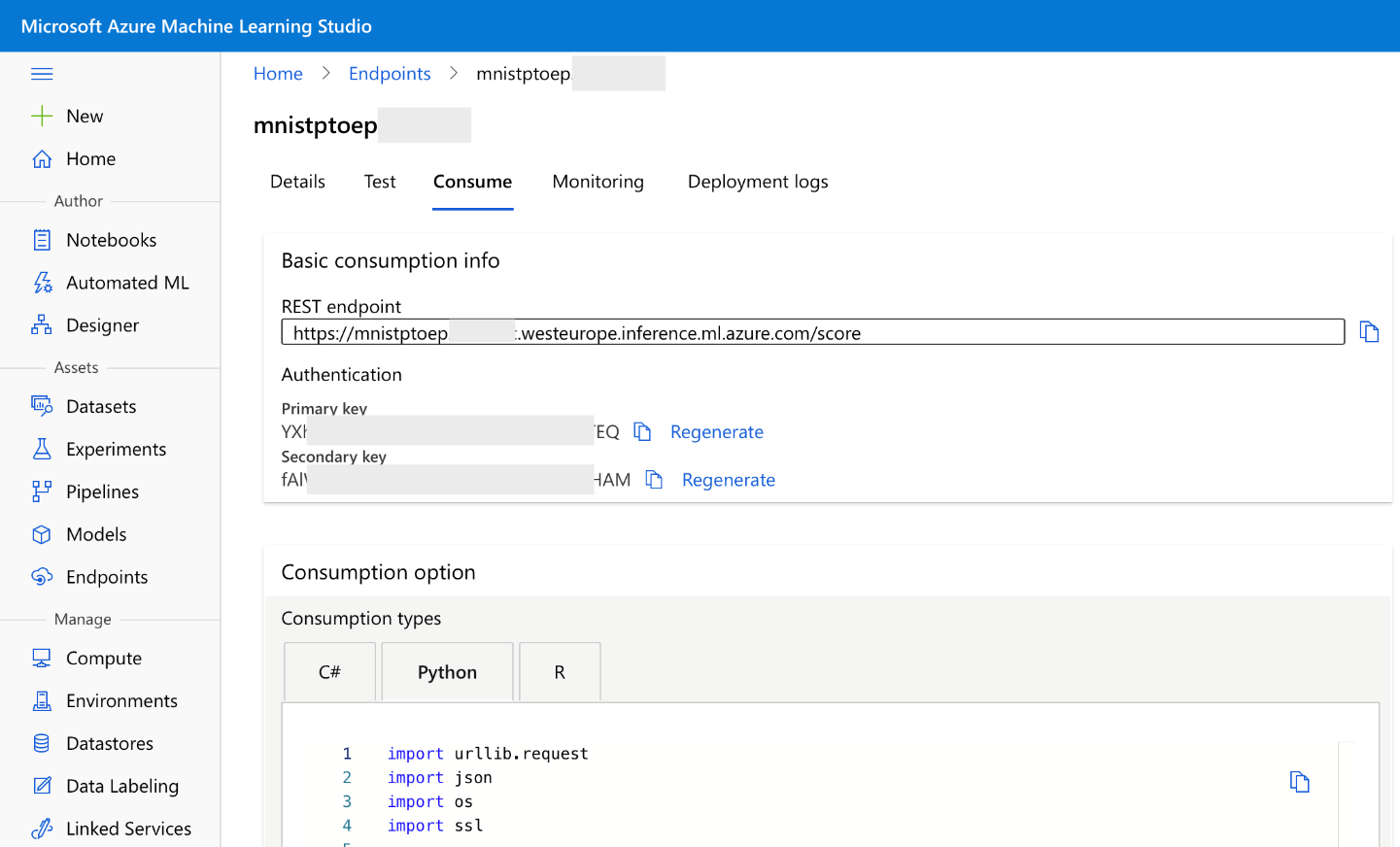
We can also obtain these values using the Azure CLI:
$ SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv
--query scoring_uri --resource-group $RESOURCE_GROUP --workspace $AML_WORKSPACE)
$ ENDPOINT_KEY=$(az ml online-endpoint get-credentials --name $ENDPOINT_NAME
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE -o tsv --query primaryKey)
Now that the SCORING_URI and ENDPOINT_KEY variables are populated, we can call our service.
$ curl -X POST -F 'image=@./test-images/d5.png' -H
"Authorization: Bearer $ENDPOINT_KEY" $SCORING_URI
If everything went well, we should get the same answer as from our Flask application:
{"preds": [5]}
Deploying Locally
A neat feature of managed endpoints is the option to deploy them on your computer using your local Docker instance. It can help when debugging deployment issues, as it gives you full access to the Docker logs and the created container.
Simply add --local parameter to the az ml online-endpoint commands to use this feature. For example, the following commands will create a local version of your endpoint:
$ az ml online-endpoint create --local -n $ENDPOINT_NAME -f aml-endpoint.yml
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE
$ az ml online-deployment create --local -n blue
--endpoint $ENDPOINT_NAME -f aml-endpoint-deployment.yml
--all-traffic --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP --workspace-name $AML_WORKSPACE
Most, if not all, az ml online-endpoint / online-deployment subcommands support the --local flag. For example, this is how you can call your local endpoint URI and check its logs:
$ LOCAL_SCORING_URI=$(az ml online-endpoint show --local -n $ENDPOINT_NAME -o tsv
--query scoring_uri --resource-group $RESOURCE_GROUP --workspace $AML_WORKSPACE)
$ curl -X POST -F 'image=@./test-images/d5.png' $LOCAL_SCORING_URI
$ az ml online-deployment get-logs --local -n blue --endpoint $ENDPOINT_NAME
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE
We don't need API_KEY here because local deployments don't require authentication.
There’s more, though. After the local deployment completes, you have full access to the corresponding Docker image and container. For example:
$ docker images

$ docker ps

By default, the image name matches the $ENDPOINT_NAME value, and the tag equals deployment name (blue, in our example).
You can create and run your own containers for the image or attach the image to existing containers as you would normally. For example, you can attach an image to a running container and list available Conda environments inside:
$ docker exec -it <container-id> bash
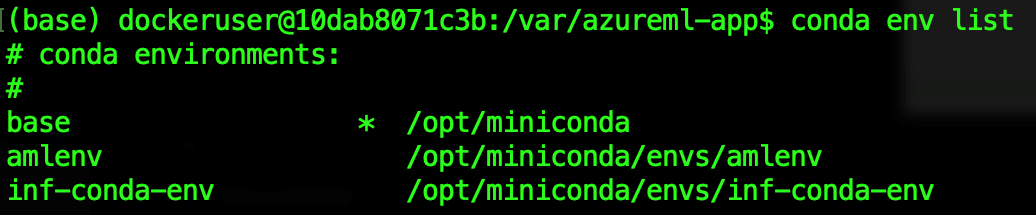
The amlenv is the default Azure Machine Learning environment included in the base image. We create the inf-conda-env environment using our YAML configuration.
When an endpoint starts, it doesn’t explicitly select the active environment. It adds each environment’s binary path to the PATH environment variable instead. It initially adds the inf-conda-env, so it first considers binaries from your custom environment.
When the endpoint starts, it executes the azureml-inference-server-http command. If it doesn't exist in the custom inf-conda-env environment, the version from the default amlenv runs. In this way, it determines the executing Conda environment implicitly.
Deleting Azure Resources
You can delete all resources you don't need anymore to reduce Azure charges. Remember App Service plans and managed endpoints in particular.
Next Steps
We published a PyTorch model trained to recognize handwritten digits in this article. We used FastAPI with App Service, then Azure Machine Learning online endpoints.
In the third and final article of the series, we'll use online endpoints to publish a TensorFlow model. Then, we’ll create an Azure Function as a public proxy to this endpoint. In addition, we’ll explore configuration options for managed endpoints, such as autoscaling and the blue-green deployment concept.
Continue to the following article to publish a TensorFlow model.
To learn how to use an online endpoint (preview) to deploy a machine learning model, check out Deploy and score a machine learning model by using an online endpoint.

