This a Part 3 of a 3-part series of articles that demonstrate how to take AI models built using various Python AI frameworks and deploy and scale them using Azure ML Managed Endpoints. In this article, we use online endpoints to publish a TensorFlow model. Then, we create an Azure Function as a public proxy to this endpoint. In addition, we explore configuration options for managed endpoints, such as autoscaling and the blue-green deployment concept.
Azure helps run machine learning (ML) workloads of almost any size, so your model is no longer limited by your computer’s processor. In the previous articles of this three-part series, we published XGBoost and PyTorch models using Azure App Service, Flask, FastAPI, and machine learning online endpoints. In this article, we'll continue with the last model from the previous series: a TensorFlow model.
Our goal is to create custom Rest API services for real-time inference on machine learning models. We’ll use models trained to recognize handwritten digits using a well-known MNIST dataset.
First, we'll publish a TensorFlow model using the Azure Machine Learning online endpoint. Then, we’ll create an Azure Function to act as a public proxy to our App Service, illustrating how you can consume online endpoints in your code.
We rely on the Azure CLI to write easy-to-understand and repeatable scripts, which we can store and version with the rest of our code. Find this article’s sample code, scripts, models, and a few test images in the dedicated GitHub repository.
Getting Started
To follow this article’s examples, you need Visual Studio Code, a recent Python version (3.7+), and Conda for Python package management. If you don’t have other preferences, begin with Miniconda and Python 3.9.
After installing Conda, create and activate a new environment:
$ conda create -n azureml python=3.9
$ conda activate azureml
Apart from Python and Conda, we use Azure command-line tools (azure-cli) in version 2.15.0 or newer, with the machine learning extension.
$ az extension add -n ml -y
Last but not least, sign up for a free Azure account if you don’t yet have one. Your new account includes free credits and access to various services.
With all these resources in place, log in to your subscription.
$ az login
Set the following environment variables, which we'll use in scripts:
export AZURE_SUBSCRIPTION="<your-subscription-id>"
export RESOURCE_GROUP="azureml-rg"
export AML_WORKSPACE="demo-ws"
export LOCATION="westeurope"
If you haven’t followed examples from the previous series, you also need to create an Azure Machine Learning workspace:
$ az ml workspace create --name $AML_WORKSPACE --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP --location $LOCATION
Now, we’re ready to start preparing for model deployment.
Registering the Model
To avoid binding and deploying our model with our application, we use the model registry built into the Azure Machine Learning workspace. If you’ve followed the third article in the previous series, your TensorFlow model may be there already. If not, use this command:
$ az ml model create --name "mnist-tf-model" --local-path "./mnist-tf-model.h5"
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE
Building the Model Inference Code
As in the previous articles, the core part of our service will be code to load the model and run inference on image data. We'll store the code in the endpoint-code/inference_model.py file:
import numpy as np
import tensorflow as tf
from PIL import Image
class InferenceModel():
def __init__(self, model_path):
self.model = tf.keras.models.load_model(model_path)
def _preprocess_image(self, image_bytes):
image = Image.open(image_bytes)
image = image.resize((28,28)).convert('L')
image_np = (255 - np.array(image.getdata())) / 255.0
return image_np.reshape(-1,28,28,1)
def predict(self, image_bytes):
image_data = self._preprocess_image(image_bytes)
prediction = self.model.predict(image_data)
return np.argmax(prediction, axis=1)
As in the previous articles in the series, this file contains a single class, InferenceModel, with three methods: __init__, _preprocess_image, and predict.
The __init__ method loads the model from a file and stores it for later.
The _preprocess_image method resizes the image and converts it into an acceptable format. Our TensorFlow model accepts a single-channel 28x28 tensor with floats in the range 0.0 to 1.0.
Notice the inversion of pixel intensity. We plan to use our model on standard black-on-white images, while the MNIST training dataset has inverted, white-on-black values.
The final predict method runs inference on provided image data.
Creating the Online Endpoint Code
To create a managed online endpoint, we need to wrap our InferenceModel class with the endpoint's service code. We store it in the endpoint-code/aml-score.py file:
import os
import json
from inference_model import InferenceModel
from azureml.contrib.services.aml_request import rawhttp
from azureml.contrib.services.aml_response import AMLResponse
def init():
global model
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "mnist-tf-model.h5"
)
model = InferenceModel(model_path)
@rawhttp
def run(request):
if request.method != 'POST':
return AMLResponse(f"Unsupported verb: {request.method}", 400)
image_data = request.files['image']
preds = model.predict(image_data)
return AMLResponse(json.dumps({"preds": preds.tolist()}), 200)
Apart from the model's name (mnist-tf-model.h5), the rest of the code is the same as the previous two articles.
The code calls the first method, init, once, when the endpoint starts. It’s a great place to load our model. To do so, we use the AZUREML_MODEL_DIR environment variable, which indicates where our model files are stored.
The following run method is straightforward. First, we ensure that it only accepts POST requests. We retrieve an image from the request, then run and return predictions.
Note the @rawhttp decorator is required to access raw request data (binary image content in our case). The request parameter passed to the run method would be limited to the parsed JSON without the decorator.
Configuring the Online Endpoint
Apart from the code, we need three additional configuration files.
The first file, endpoint-code/aml-env.yml, stores the Conda environment definition:
channels:
- conda-forge
- defaults
dependencies:
- python=3.7.10
- pillow=8.3.2
- gunicorn=20.1.0
- numpy=1.19.5
- pip
- pip:
- h5py==3.1.0 # We need to use the same version we have used for training
- keras==2.6.0 # We need to add it manually,
- because a different (newer) version could be installed with the tensorflow otherwise!
- tensorflow==2.6.0
- azureml-defaults==1.35.0
- inference-schema[numpy-support]==1.3.0
Note that to load a trained model using Keras from H5 format, we need to use the identical versions of h5py, Keras, and TensorFlow libraries used during model training. That’s why we explicitly add all three to the YAML file. If not, some other versions would install as TensorFlow dependencies.
The remaining configuration files define the endpoint and endpoint's deployment and are equivalent to the files we introduced in the previous two articles:
File aml-endpoint.yml:
$schema: https:
name: mnisttfoep
auth_mode: key
File aml-endpoint-deployment.yml:
$schema: https:
name: blue
endpoint_name: mnisttfoep
model: azureml:mnist-tf-model:1
code_configuration:
code:
local_path: ./endpoint-code
scoring_script: aml-score.py
environment:
conda_file: ./endpoint-code/aml-env.yml
image: mcr.microsoft.com/azureml/minimal-ubuntu18.04-py37-cpu-inference:latest
instance_type: Standard_F2s_v2
instance_count: 1
Deploying the Online Endpoint
With all these files ready, we can start deployment. To do so, we use the same scripts we’ve used in the previous articles, starting from the endpoint:
$ ENDPOINT_NAME="<your-endpoint-name>"
$ az ml online-endpoint create -n $ENDPOINT_NAME -f aml-endpoint.yml
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE
Remember that the endpoint name will become part of the URL, so it must be globally unique.
Next, we can deploy our inference code:
$ az ml online-deployment create -n blue
--endpoint $ENDPOINT_NAME -f aml-endpoint-deployment.yml
--all-traffic --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP --workspace-name $AML_WORKSPACE
After a long time, the command should return confirmation that the deployment is complete and the endpoint is ready to use. Note that it takes a while to provision your VMs, download the base image, and set up your environment.
Then, type the following command to check endpoint logs:
$ az ml online-deployment get-logs -n blue --endpoint $ENDPOINT_NAME
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE
Testing the Online Endpoint
We use images from our sample code (test-images/d0.png to d9.png) to test our service.
Additionally, we need the endpoint URL and endpoint key. One way to obtain them is via Azure Machine Learning Studio, from the endpoint’s Consume tab.

Also, we can obtain these values using the Azure CLI:
$ SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv
--query scoring_uri --resource-group $RESOURCE_GROUP --workspace $AML_WORKSPACE)
$ ENDPOINT_KEY=$(az ml online-endpoint get-credentials --name $ENDPOINT_NAME
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE -o tsv --query primaryKey)
After populating the SCORING_URI and ENDPOINT_KEY variables, we can call our service:
$ curl -X POST -F 'image=@./test-images/d8.png' -H
"Authorization: Bearer $ENDPOINT_KEY" $SCORING_URI
If everything went well, we should get the expected answer:
{"preds": [8]}
Scaling Managed Endpoints
One benefit of using the cloud instead of on-premises infrastructure is flexibility in scaling. The new Azure Machine Learning managed endpoints enable this flexibility and scaling.
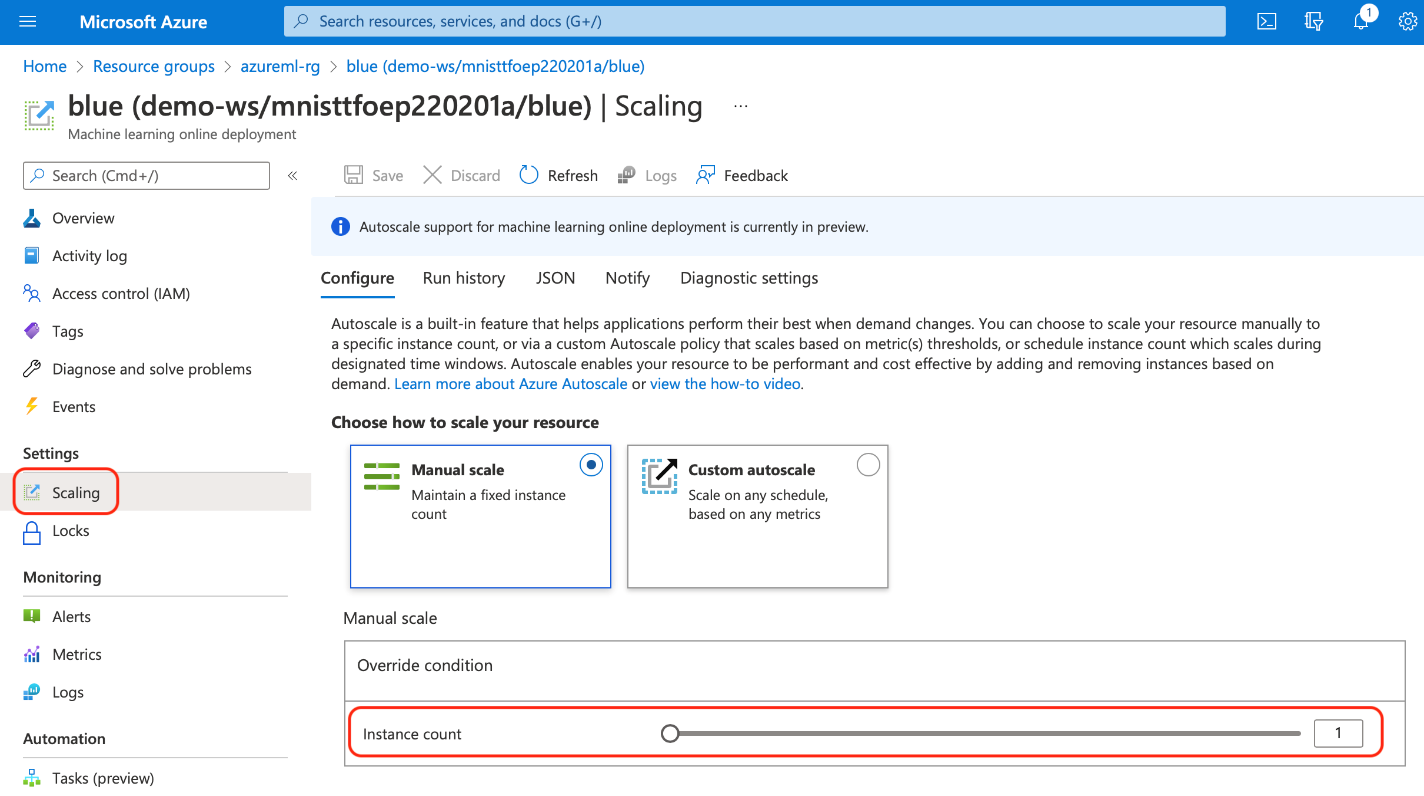
When we go to our deployment resource in the Azure portal, we can scale it manually or configure automatic scaling. We manually set our cluster size in Scaling > Configure like in the screenshot below:
We set scaling rules for automated scaling. For example, we can increase the number of instances by one when the CPU Memory Utilization metric exceeds 70 percent for more than 10 minutes, like in the screenshot below:

Using Blue-Green Deployments
Finally, let’s talk about why we have used blue as our deployment name. This name comes from blue-green deployment, where we deploy a new version of a system (green, for example) while the previous one (blue) is still running and available to users. After the green deployment finishes, we can switch all traffic from the old blue to the new green version. We can instantaneously reverse this traffic switch without a time-consuming rollback operation if there are any issues.
All these changes are hidden from service callers. The callers continuously use the same URL and may not be aware of any changes.
An evolution of this technique is called canary release. The main difference is that, contrary to the blue-green deployment, we don’t switch all traffic from one version to the other at once in the canary release. Instead, we shift traffic gradually. We can use a similar mechanism for A/B testing, where we want to test a new service on a small number of requests (for example, five percent).
Managed endpoints natively support all these approaches. To add a new deployment, we just need to call our az ml online-deployment create command, providing a new name, green for example:
$ az ml online-deployment create -n green
--endpoint $ENDPOINT_NAME -f aml-endpoint-deployment.yml --all-traffic
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE

Note that as long as we use the --all-traffic attribute there, all traffic targeting our endpoint will automatically redirect to the new, green version as soon as the operation completes. In practice, it means blue-green deployment.
If we prefer a canary release instead, we can set the traffic split after the deployment finishes.
The main downside of this approach is increased Azure resource use. During and directly after each release, used and not used yet VM instances will affect Azure vCPU quotas and generated costs. You can limit this effect using a canary release as long as you continuously scale your deployments to match your current traffic allocation.
Accessing the Online Endpoint from an Azure Function
In a real-life production system, like a web application, you most likely won’t expose online endpoints directly to public clients. Usually, the endpoints sit as microservices behind a firewall, and other services use them. In this last part of the article, we'll create a simple Azure Function application to consume the online endpoint and act as its public proxy.
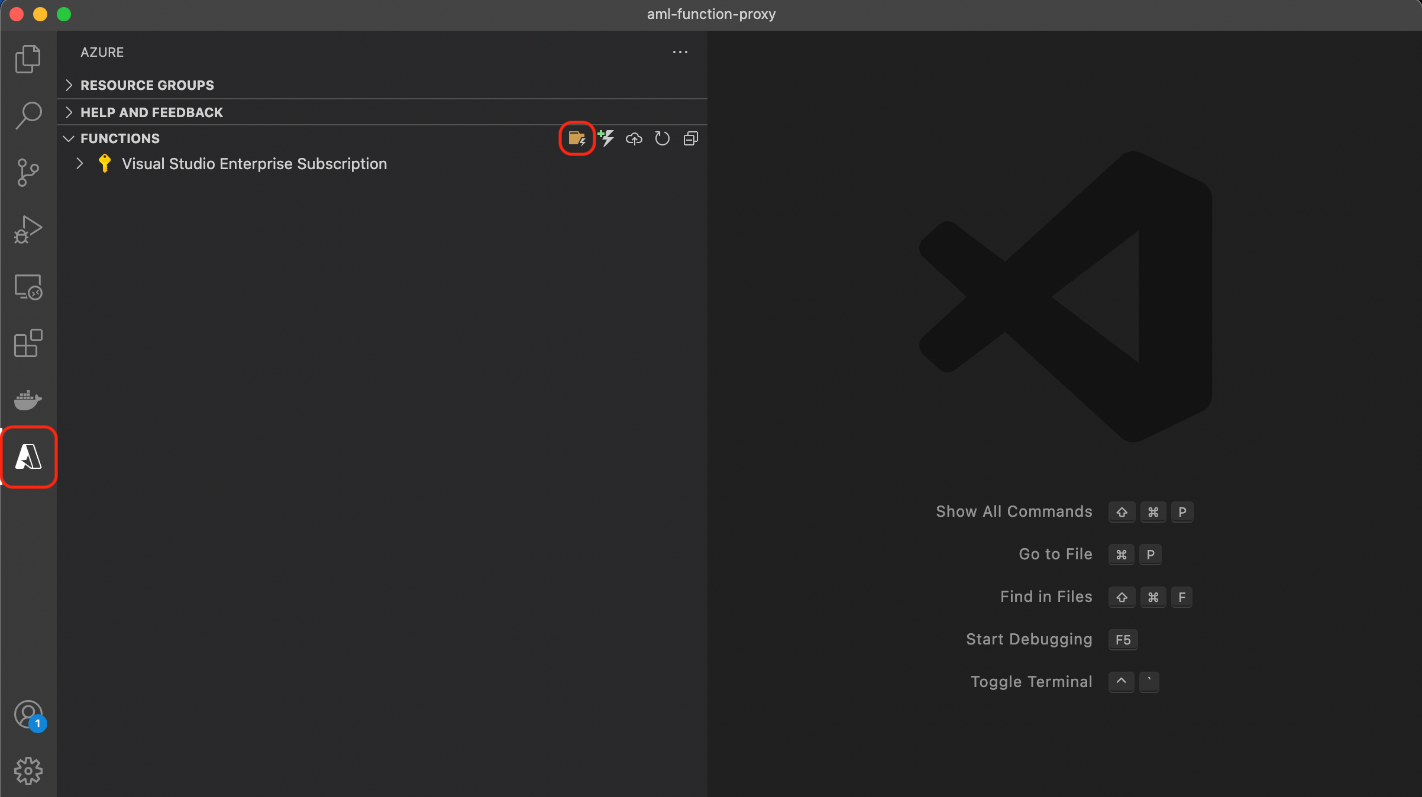
We’ll use Visual Studio Code with an Azure Functions extension:

After installing the extension, we need to select the Azure tab, then click the New Project icon within the Functions section:
Next, we select a folder for our project, programming language, function template, first function name, and finally, the function's authorization level.
We select the Python language, an HTTP Trigger template named AmlMnistHttpTrigger, and the Anonymous authorization level.
In just a moment, our function will fill with sample code.

Now, all we need to do is to add one import and replace the contents of the __init__.py file:
import requests
import azure.functions as func
def main(req: func.HttpRequest) -> func.HttpResponse:
image_file = req.files['image']
files = { "image": image_file }
url = '<your-endpoint-uri>'
api_key = '<your-api-key>'
headers = {'Authorization':('Bearer '+ api_key)}
response = requests.post(url, files=files, headers=headers)
return func.HttpResponse(response.content, status_code=response.status_code)</your-api-key></your-endpoint-uri>
The primary method’s logic is simple here. First, it extracts the image file from the request, then it creates and executes the request to our managed endpoint URL, passing both image and header with the api_key value. Both URL and api_key are the same values we used with curl before.
This example is simplified to make it easy to understand. In practice, you should change at least two things. First, you shouldn’t include the api_key value directly in your code. Instead, consider using Key Vault or a similar mechanism to store your secrets. Second, you may need some exception handling and logging.
To make our function work, we also need to update the requirements.txt file in our function application folder by adding the requests library:
azure-functions
requests
Now that we have the code, we can publish our function by selecting Deploy to Function App.

After selecting a globally unique name for our Azure function, runtime stack (Python 3.9, for example), and location, the deployment process starts in the background. When deployment completes, the URL to our new trigger will be visible at the end of the output log.
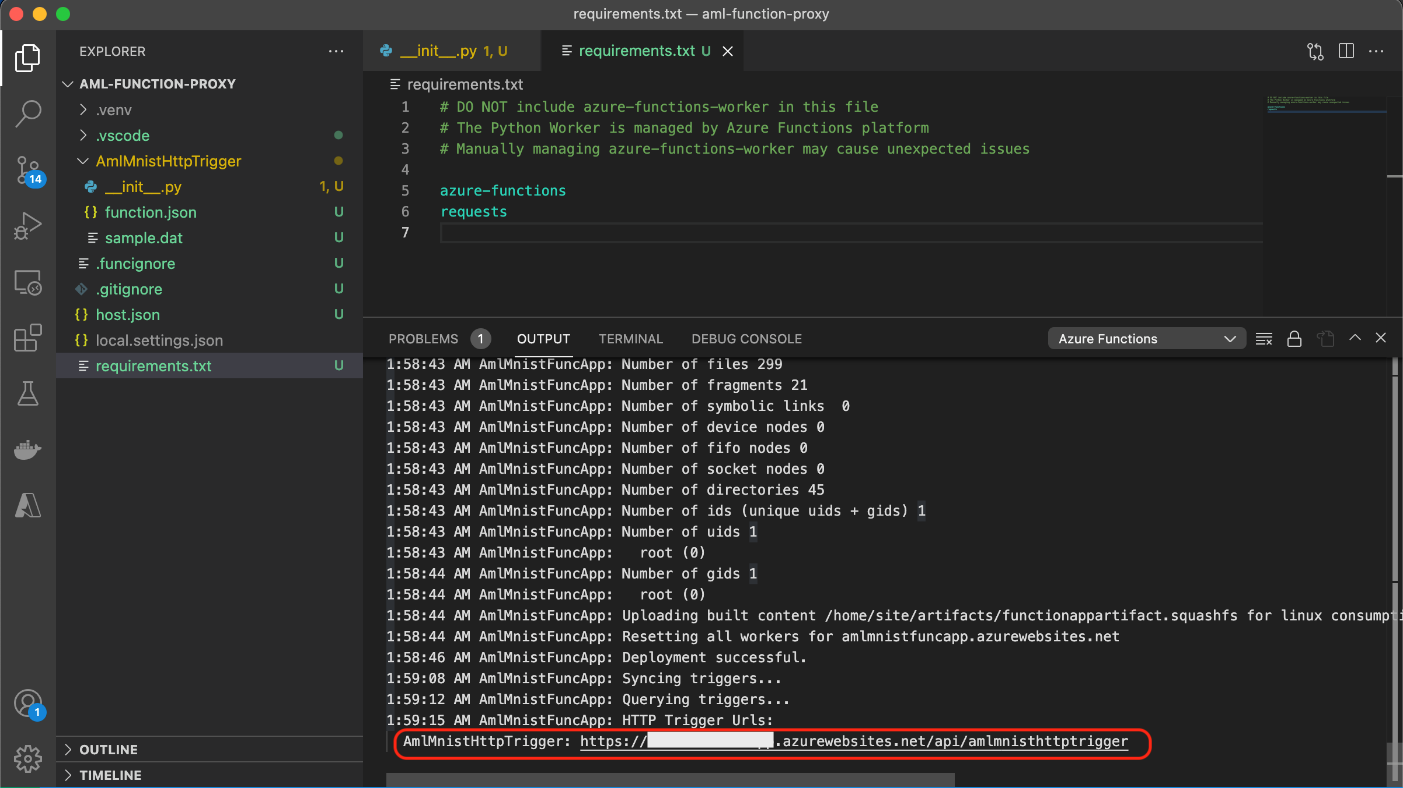
We can also examine our function and get its URL using the Azure portal. In Code + Test, select Get function URL.
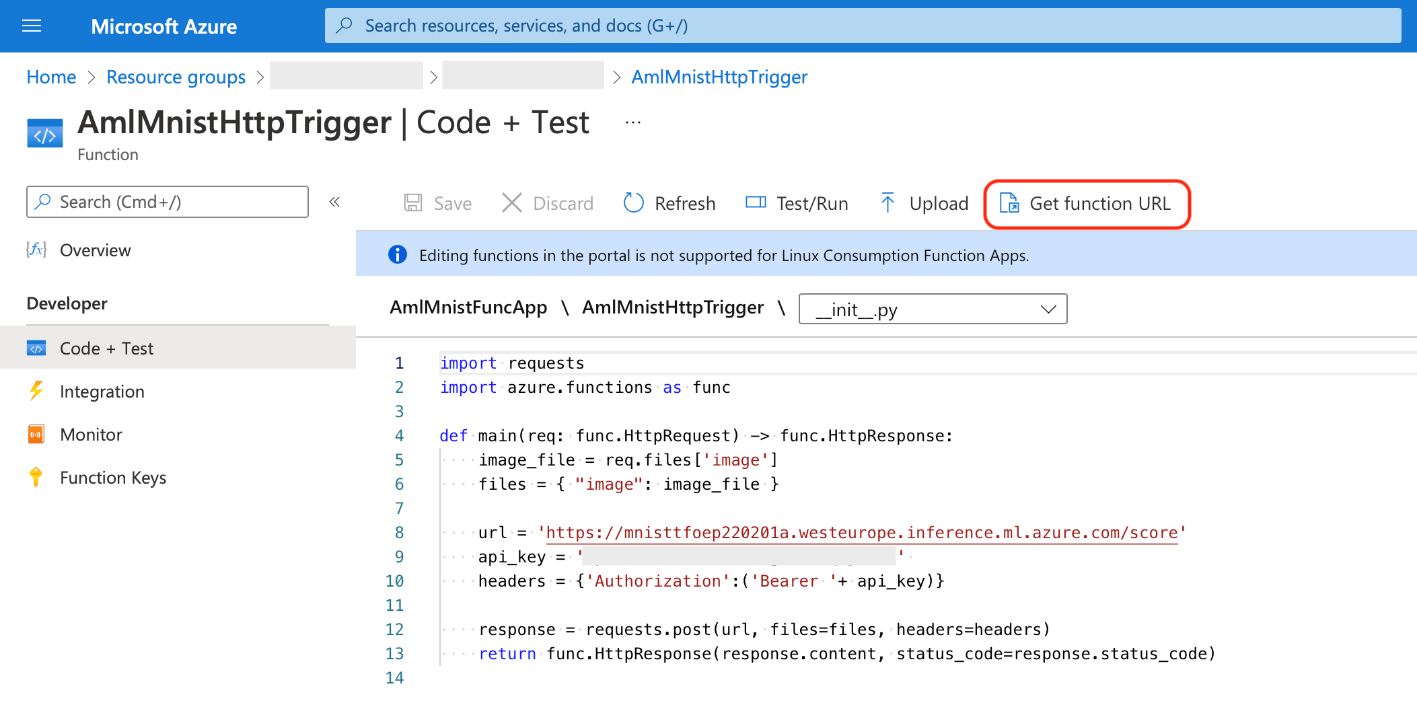
Now, we can call our function:
$ curl -X POST -F 'image=@test-images/d4.png' <your-function-url>
And that’s it! Because our function accepts anonymous callers, we don’t need to pass any authorization token with the request.
Deleting Azure Resources
Delete all the resources you don't need anymore to reduce Azure charges. In particular, remember the managed endpoint(s) and Azure Functions. You may have created Azure Functions in a dedicated resource group with the function app’s name.
Next Steps
We published a TensorFlow model trained to recognize handwritten digits in this article. First, we used Azure Machine Learning online endpoints and explained basic related scaling and deployment options. Next, we demonstrated how to call this endpoint from your code, using a simple Azure Function as an example.
It’s straightforward to deploy an XGBoost, PyTorch, or TensorFlow model using Azure. Plus, you access unlimited scaling with all the processing power you need to run your model.
Now that you know how easy it is, sign up and use Azure to deploy your own machine learning models. No ops team is required.
To learn how to use an online endpoint (preview) to deploy a machine learning model, check out Deploy and score a machine learning model by using an online endpoint.

