As developers, we’ve continuously worked on dedicated architectures to accelerate our applications. Each device may require specific optimization procedures for top performance. This situation typically exposes us to various programming languages and vendor-specific libraries. As a result, developing applications across architectures is challenging.
But if we care about performance and efficiency, we need to regularly reuse our code on new hardware as it becomes available. We must ensure we don’t leave any transistors, resistors, or semiconductors behind.
To achieve high performance and efficiency, we need a unified and simplified programming model enabling us to select the optimal hardware for the task at hand. We need a high-level, open standard, heterogeneous programming language that’s both built on evolutions of standards and extensible. It must boost developer productivity while providing consistent performance across architectures. The oneAPI specification addresses these challenges.
The oneAPI specification includes Data Parallel C++ (DPC++), oneAPI’s implementation of the Khronos SYCL standard. It also includes specific libraries and a hardware abstraction layer. The oneAPI Technical Advisory Boards have been iteratively refining the oneAPI specification in line with industry standards. Additionally, Intel oneAPI toolkits provide implementations of the specification by providing compilers, optimized libraries, the Intel® DPC++ Compatibility Tool(DPCT), and advanced analysis and debug tools.
This article demonstrates how to migrate an existing Compute Unified Device Architecture (CUDA) application to SYCL using DPCT. We begin with a high-level overview of the SYCL specification and describe how the compatibility tool works. Then, we show how to migrate simple CUDA code to SYCL.
A hands-on demonstration using a Jupyter notebook will show the serial steps. The Jupyter notebook complements this article, allowing us to run the code described below and use it as a sandbox. The notebook also provides:
- The full CUDA implementation
- The resulting migrated SYCL code
- The version we manually optimize in this tutorial
First, let’s explore SYCL and the Intel DPC++ Compatibility Tool.
What is SYCL?
SYCL (pronounced sickle) is a royalty-free, open single-source C++ standard. It specifies an abstraction layer that allows programming on heterogeneous architectures.
The generic heterogeneous programming model follows International Standards Organization (ISO) C++ specifications. This standardization enables our code to run on multiple devices seamlessly.
Figure 1 – SYCL implementations available today
Imagine using an Nvidia graphics processing unit (GPU) to accelerate parts of our single-source C++ application. Nvidia provides, CUDA, a general-purpose parallel programming model to accelerate code on Nvidia GPUs.
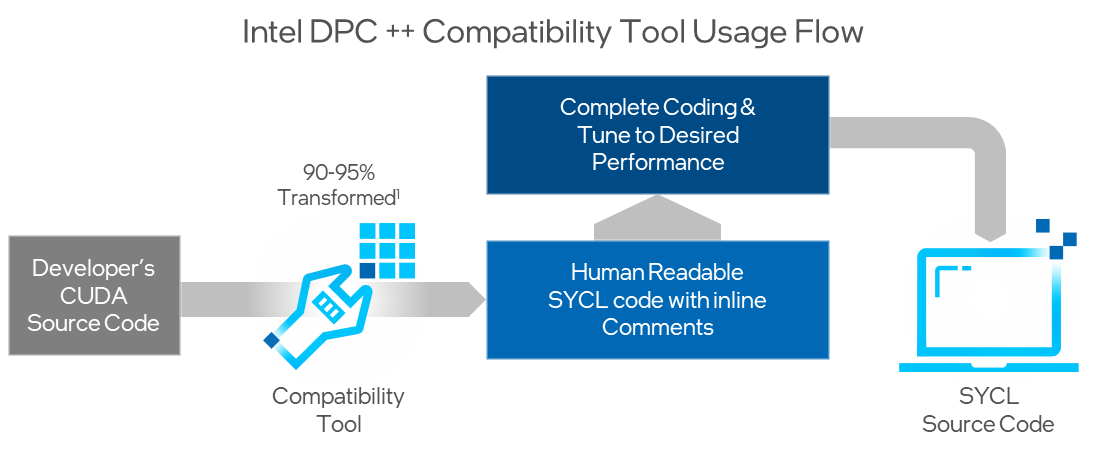
But what if we’d like to use another vendor’s GPU or a field-programmable gate array (FPGA) instead of Nvidia GPUs? We must migrate our CUDA code to the new architecture. This process could be tedious and time-consuming. However, we can migrate our code to SYCL with the help of the compatibility tool. It automatically converts 90-95% of our code on average, significantly increasing productivity.
Intel DPC++ Compatibility Tool
The Intel DPC++ Compatibility Tool (DPCT) assists developers in migrating existing CUDA to SYCL. It reduces migration time, generates human-readable code, and pinpoints parts of the code requiring manual intervention.
The compatibility tool provides a rich set of options to control the migration process. For instance, we can choose whether to use unified shared memory (USM) or buffers and accessors in the generated code.
We’ll observe DPCT in action next.
Example: Migrating Vector Addition CUDA to SYCL
To provide a practical overview of the migration process, this article uses a simple implementation of vector addition in CUDA. We take a closer look at the code that the compatibility tool generates. Mainly, we focus on the code sections where CUDA and SYCL differ the most.
We’ll be using the compatibility tool and the Intel® oneAPI DPC++/C++ Compiler from the Intel® oneAPI Base Toolkit for the task at hand. To install the toolkit, follow the oneAPI installation guide.
Use the following workflow to migrate your existing CUDA application successfully to SYCL:
- Use the intercept-build utility to intercept commands issued by the Makefile and save them in a JSON-format compilation database file. This step is optional for single-source projects.
- Migrate your CUDA code to SYCL using DPCT.
- Verify the generated code for correctness, and complete the migration manually if warning messages indicate this explicitly. Check the Intel DPC++ Compatibility Tool Developer Guide and Reference to fix the warnings.
- Compile the code using the Intel oneAPI DPC++/C++ Compiler, run the program, then check the output.
You can then use Intel’s oneAPI analysis and debug tools, including Intel® VTune Profiler, to optimize your code further.
Let’s take vector addition as an example. Vector addition involves adding the elements from vectors A and B into vector C. A CUDA kernel computes this as follows:
__global__ void vector_sum(const float *A, const float *B, float *C, const int num_elements){
int idx = blockDim.x * blockIdx.x + threadIdx.x;
if (idx < num_elements) C[idx] = A[idx] + B[idx];}
In CUDA, a group of threads is a thread block equivalent to a workgroup in SYCL. However, we compute thread indexing differently. In CUDA, we use built-in variables to identify a thread (see how we calculated the idx variable in the code above). Once migrated to SYCL, the same kernel looks as follows:
void vector_sum(const float *A, const float *B, float *C, const int num_elements, sycl::nd_item<3> item_ct1){
int idx = item_ct1.get_local_range().get(2) * item_ct1.get_group(2) + item_ct1.get_local_id(2);
if (idx < num_elements) C[idx] = A[idx] + B[idx];}
Like a CUDA thread, a work item in SYCL has a global identifier in a global space or a local identifier within a workgroup. We can get these identifiers from the nd_item variable. So, we no longer need to compute the global identifier explicitly.
However, this demonstration shows how we do it in SYCL, so we see the similarities to CUDA’s built-in variables. Notice that nd_items are three-dimensional because of the dim3 type in CUDA. In this context, we can make nd_items all one-dimensional. This action maps a work item to each element in the vector.
To run a CUDA kernel, we must set the block size and how many blocks we need. In SYCL, we must define the execution range. As the code below shows, we do this with an nd_range variable that combines the global range and local range. The global range represents the total number of work items, while the local range is the size of a workgroup.
We also must ensure that we don’t exceed our device workgroup’s maximum size, since doing so may trigger a DPCT1049 warning. We solve this challenge in the following code by setting the maximum block size that the device can handle. Check the Jupyter notebook to learn more.
const int num_elements = 512;
dpct::device_info prop;
dpct::dev_mgr::instance().get_device(0).get_device_info(prop);
const size_t max_block_size = prop.get_max_work_group_size();
const size_t block_size = std::min<size_t>(max_block_size, num_elements);
range<1> global_rng(num_elements);
range<1> local_rng(block_size);
nd_range<1> kernel_rng(global_rng, local_rng);
To invoke our SYCL kernel, we use a parallel_for and the execution range to submit the kernel to a queue. Each work item invokes the kernel once. We have the same number of work items for each vector element in this context. Let’s see how this looks:
dpct::get_default_queue().parallel_for(kernel_rng, [=](nd_item<1> item_ct1) {
vector_sum(d_A, d_B, d_C, num_elements, item_ct1);});
So far, we’ve explored how to implement and run a kernel. However, before running the kernel, we need to think about memory allocation and copy the data to the device.
- First, we allocate memory for the operand vectors in the host and initialize them.
- Then, we do the same on the device. CUDA uses the
cudaMalloc routine. By default, the DPCT migrates this routine to malloc_device, which uses unified shared memory (USM). - Now, we use the
memcpy command to copy the vectors from the host memory to the device.
After these steps, we run our kernel. Once the execution completes, we copy the result back to the host. We then check the result for correctness. Finally, we free the memory in the host and device by calling free and sycl::free, respectively.
Real-world Use Cases migrating CUDA Code to SYCL
Zuse Institute Berlin (ZIB) ported the tsunami simulation easyWave application from CUDA to SYCL efficiently using the DPC++ compatibility tool.1 Its results achieved strong performance across Intel CPU, GPU and FPGA architectures, and within 5% of CUDA performance on Nvidia P100.2 For more details see: ZIB: oneAPI case study with the tsunami simulation easyWave.
Stockholm University advanced GROMACS, a molecular dynamics package designed for simulations of proteins, lipids and nucleic acids used to design new drugs for breast cancer inhibitors, COVID-19, and more - using oneAPI together with SYCL to improve parallelization on heterogeneous architectures. oneAPI’s open and standards-based programming, support for OpenMP, and having a first-class OpenCL implementation helped this effort. The team ported GROMACS’ Nvidia CUDA code to SYCL using the DPC++ compatibility tool to create a new single, portable codebase that is cross-architecture-ready. This greatly streamlines development and provides flexibility for deployment in a multiarchitecture (CPUs and GPUs), multivendor environment. Learn more: Experiences with adding SYCL support to GROMACS.
Bittware used oneAPI to create a single code base to run on its FPGAs. This simplified design, testing and implementation so applications were up and running in a few days vs. weeks.
High Order Exhaustive Epistatis is a bioinformatics application with very high computational complexity that searches for correlations between genetic markers such as single-nucleotide polymorphisms (SNPs), single base changes in a DNA sequence that occur in at least 1% of a population, and phenotype (e.g. disease state). Finding new associations between genotype and phenotype can contribute to improved preventive care, personalized treatments, and development of better drugs for more conditions. Experts from INESC-ID Lisboa (Instituto de Engenharia de Sistemas e Computadores: Investigação e Desenvolvimento em Lisboa) used the DPC++ compatibility tool and Intel® DevCloud to migrate OpenMP and CUDA code to SYCL and is now running the code on Intel Iris Xe Max (discrete GPU).
Conclusion
Using Intel’s compatibility tool, we migrated existing CUDA to SYCL easily. Now, we can run our code on multiple devices seamlessly, crossing architecture and vendor boundaries.
This approach has made us more productive and enabled us to focus on our application’s performance. Imagine the time and effort it would take to migrate our code without DPCT.
Try the advanced analysis and debug tools in the toolkit today.
Resources
1Nvidia CUDA code was ported to Data Parallel C++ (DPC++), which is a SYCL implementation for oneAPI, in order to create new cross-architecture-ready code.
2For details see XPUG presentation: ZIB: oneAPI case study with the tsunami simulation EasyWave from CUDA to DPC++ and back to Nvidia GPUs and FPGAs – Configuration: Compute Domain: approx. 2000 x 1400 cells; 10 hours simulation time. Same code produces valid data on CPU, Intel GPUs, and FPGA. oneAPI performance evolution on DevCloud Coffee Lake Gen9.5 GT2 iGPU using code migrated from CUDA to Data Parallel C++ using the Intel® DPC++ Compatibility tool, build with open source Intel LLVM w/ CUDA support (contribution by Codeplay). Typical application run on Nvidia P100-SXM2-16GB shows migrated DPC++ code runs only 4% slower than CUDA code. Results: Same DPC++ code can target different platforms (almost) without modifications. • Performance is on par with architecture-specific CUDA code. For workloads and configurations visit www.Intel.com/PerformanceIndex. Results may vary. Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.

